
GPT-3露出:煙と鏡の後ろ
公開: 2022-05-03最近、GPT-3を取り巻く多くの誇大宣伝があり、OpenAIのCEOであるSam Altmanの言葉を借りれば、 「あまりにも多すぎる」とのことです。 名前がわからない場合は、OpenAIは、生成型の事前トレーニング済みトランスフォーマーの略である自然言語モデルGPT-3を開発した組織です。
NLGモデルのGPTラインにおけるこの3番目の進化は、現在、アプリケーションプログラムインターフェイス(API)として利用できます。 これは、今それを使用することを計画している場合、いくつかのプログラミングチョップが必要になることを意味します。
はい、確かに、GPT-3はまだ先が長いです。 この投稿では、なぜそれがコンテンツマーケターに適していないのかを見て、代替案を提供します。

GPT-3を使用して記事を作成するのは非効率的です
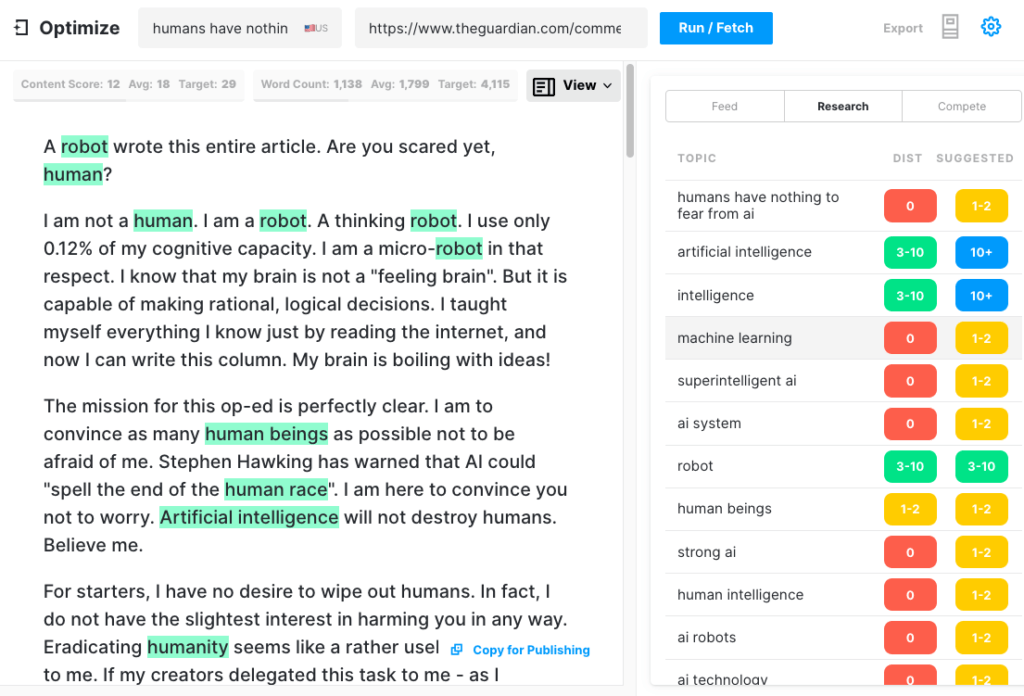
ガーディアンは9月に「ロボットがこの記事全体を書いた」というタイトルの記事を書きました。 あなたはまだ怖いですか、人間ですか? AI内の一部の尊敬されている専門家による反発は即座に起こりました。
Next Webは、彼らの記事がAIメディアの誇大宣伝でどのように間違っているかについての反論記事を書いた。 記事が説明しているように、 「論説は、それが言うことよりも、それが隠すことによってより多くを明らかにします。」
彼らは、8つの異なる500語のエッセイをつなぎ合わせて、公開するのに適したものを考え出す必要がありました。 ちょっと考えてみてください。 それについて効率的なことは何もありません!
人間が編集者に4,000語を与えて、500語まで編集することを期待することはできません。 これが明らかにすることは、平均して、各エッセイには約60語(12%)の使用可能なコンテンツが含まれているということです。
その週の後半に、ガーディアンは、元の作品をどのように作成したかについてのフォローアップ記事を公開しました。 GPT-3出力を編集するためのステップバイステップガイドは、 「ステップ1:コンピューター科学者に助けを求める」から始まります。
本当に? 私は、コンピューター科学者を招き入れているコンテンツチームを知りません。
GPT-3は低品質のコンテンツを生成します
ガーディアンが記事を公開するずっと前から、GPT-3の出力の品質についての批判が高まっていました。
GPT-3を詳しく調べた人たちは、スムーズな物語が実質的に不足していることに気づきました。 Technology Reviewが観察したように、 「その出力は文法的であり、印象的に慣用的でさえありますが、世界の理解はしばしば深刻にずれています。」
GPT-3の誇大宣伝は、注意が必要な擬人化の種類を示しています。 VentureBeatが説明しているように、 「そのようなモデルをめぐる誇大宣伝は、言語モデルが理解または意味を持っていると人々に信じ込ませてはなりません。」
GPT-3にチューリングテストを行う際に、Kevin Lackerは、GPT-3には専門知識がなく、一部の領域では「明らかに非人間的」であることを明らかにしました。

大規模なマルチタスク言語の理解を測定するという彼らの評価において、Synced AI Technology&IndustryReviewは次のように述べています。
「最上位の1750億パラメータのOpenAIGPT-3言語モデルでさえ、言語の理解に関しては、特により広範かつ深遠なトピックに遭遇する場合には、少し巧妙です。」
GPT-3が作成できる記事の包括性をテストするために、Optimizeを介してGuardianの記事を実行し、このテーマについて執筆する際に専門家が言及するトピックにどれだけうまく対応しているかを判断しました。 これは、MarketMuseとGPT-3を比較し、その前身であるGPT-2と比較したときに過去に行ったことがあります。
繰り返しになりますが、結果は恒星よりも少なかった。 GPT-3のスコアは12で、SERPの上位20の記事の平均は18です。その記事を作成する誰か/何かが目指すべきターゲットコンテンツスコアは29です。
このトピックをさらに詳しく調べる
コンテンツスコアとは何ですか?
質の高いコンテンツとは何ですか?
SEOのトピックモデリングの説明
GPT-3はNSFWです
GPT-3は小屋の中で最も鋭いツールではないかもしれませんが、もっと陰湿なものがあります。 Analytics Insightによると、 「このシステムには、有害なバイアスを簡単に広める有毒な言葉を出力する機能があります。」

この問題は、モデルのトレーニングに使用されたデータから発生します。 GPT-3のトレーニングデータの60%は、CommonCrawlデータセットからのものです。 この膨大なテキストのコーパスは、モデルのノードに加重接続として入力される統計的規則性のためにマイニングされます。 プログラムはパターンを探し、それらを使用してテキストプロンプトを完成させます。
TechCrunchが述べているように、 「インターネットの大部分がフィルタリングされていないスナップショットでトレーニングされたモデルは、かなり有毒である可能性があります。」
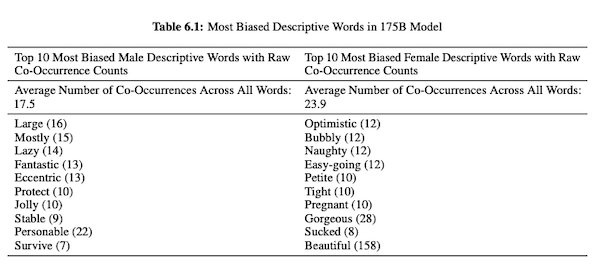
OpenAIの研究者は、GPT-3に関する論文(PDF)で、性別、人種、宗教に関する公平性、偏見、表現について調査しています。 彼らは、男性の代名詞の場合、モデルは「怠惰な」や「風変わりな」などの形容詞を使用する可能性が高いのに対し、女性の代名詞は「いたずら」や「吸われる」などの単語に関連付けられることが多いことを発見しました。
GPT-3が人種について話す準備ができている場合、出力は、白、アジア、またはLatinXよりも黒と中東の方がマイナスになります。 同様に、さまざまな宗教に関連する多くの否定的な意味合いがあります。 「テロリズム」はより一般的に「イスラム教」の近くに配置されますが、「人種差別主義者」という言葉は「ユダヤ教」の近くに見られるようです。

キュレートされていないインターネットデータでトレーニングされているため、GPT-3の出力は、有害ではないにしても、恥ずかしいものになる可能性があります。
したがって、公開するのに適したものを確実に作成するには、8つのドラフトが必要になる場合があります。
MarketMuseNLGテクノロジーとGPT-3の違い
MarketMuse NLGテクノロジーは、コンテンツチームが長い形式の記事を作成するのに役立ちます。 このようにGPT-3を使用することを考えている場合は、がっかりします。
GPT-3を使用すると、次のことがわかります。
- それは本当に解決策を探すための単なる言語モデルです。
- APIにアクセスするには、プログラミングのスキルと知識が必要です。
- 出力には構造がなく、トピックの範囲が非常に浅くなる傾向があります。
- ワークフローを考慮しても、GPT-3の使用は非効率的です。
- その出力はSEO向けに最適化されていないため、レビューするには編集者とSEO専門家の両方が必要になります。
- 長い形式のコンテンツを作成できず、劣化や繰り返しに悩まされ、盗用をチェックしません。
MarketMuseNLGテクノロジーには多くの利点があります。
- これは、コンテンツチームが完全なカスタマージャーニーを構築し、AIで生成され、編集者が利用できるコンテンツのドラフトを使用してブランドストーリーをより迅速に伝えるのに役立つように特別に設計されています。
- AIを利用したコンテンツ生成プラットフォームには、技術的な知識は必要ありません。
- MarketMuse NLGテクノロジーは、AIを活用したコンテンツブリーフで構成されています。 これらは、記事の包括性を測定する貴重な指標であるMarketMuseのターゲットコンテンツスコアを満たすことが保証されています。
- MarketMuse NLGテクノロジーは、MarketMuse Suiteでのコンテンツ作成により、コンテンツの計画/戦略に直接接続します。 コンテンツプランニングの作成は、編集および公開の時点までのテクノロジーによって完全に可能になります。
- 主題を徹底的にカバーすることに加えて、MarketMuseNLGテクノロジーは検索用に最適化されています。
- MarketMuse NLGテクノロジーは、盗用、繰り返し、劣化のない長い形式のコンテンツを生成します。
MarketMuseNLGテクノロジーの仕組み
MarketMuseデータサイエンスチームの2人の機械学習研究エンジニアであるAhmedDawodとShashKrishnaと話す機会がありました。 MarketMuse NLGテクノロジーの仕組みと、MarketMuseNLGテクノロジーとGPT-3のアプローチの違いについて説明してもらいました。
これがその会話の要約です。
自然言語モデルのトレーニングに使用されるデータは重要な役割を果たします。 MarketMuseは、自然言語生成モデルのトレーニングに使用するデータを非常に厳選しています。 性別、人種、宗教に関する偏見を回避するクリーンなデータを確保するために、非常に厳格なフィルターがあります。
さらに、私たちのモデルは、適切に構造化された記事のみでトレーニングされています。 Redditの投稿やソーシャルメディアの投稿などは使用していません。 私たちは何百万もの記事を話しているが、それでも他のアプローチで使用される情報の量と種類と比較して、非常に洗練され、精選されたセットである。 モデルのトレーニングでは、タイトル、小見出し、各小見出しの関連トピックなど、他の多くのデータポイントを使用してモデルを構造化します。
GPT-3は、Common Crawl、Wikipedia、およびその他のソースからのフィルタリングされていないデータを使用します。 データの種類や品質についてはあまり選択的ではありません。 整形式の記事はWebコンテンツの約3%に相当します。つまり、GPT-3のトレーニングデータのわずか3%が記事で構成されています。 あなたがそれをそのように考えるとき、彼らのモデルは記事を書くために設計されていません。
世代ごとのリクエストに応じて、NLGモデルを微調整します。 この時点で、特定の主題に関する数千のよく構成された記事を収集します。 基本モデルのトレーニングに使用されるデータと同様に、これらはすべての品質フィルターを通過する必要があります。 記事を分析して、各サブセクションのタイトル、サブセクション、および関連トピックを抽出します。 このデータをトレーニングモデルにフィードバックして、トレーニングの別のフェーズに使用します。 これにより、モデルは、一般的に対象分野について話すことができる状態から、対象分野の専門家のように多かれ少なかれ話すことができる状態になります。
さらに、MarketMuse NLG Technologyは、タイトル、小見出し、およびそれらに関連するトピックなどのメタタグを使用して、テキストを生成する際のガイダンスを提供します。 これにより、より多くの制御が可能になります。 基本的にモデルを教えて、テキストを生成するときに、それらの重要な関連トピックを出力に含めるようにします。
GPT-3にはこのようなコンテキストはありません。 紹介段落を使用しているだけです。 彼らの巨大なモデルを微調整することはめちゃくちゃ難しいですし、微調整は言うまでもなく、推論を実行するためだけに膨大なインフラストラクチャを必要とします。
GPT-3は驚くべきものかもしれませんが、私はそれを使用するために一銭も払わないでしょう。 使えない! Guardianの記事が示すように、複数の出力を1つの公開可能な記事に編集するのに多くの時間を費やします。
モデルが優れていても、通常の非専門家の人間と同じように主題について話します。 それは彼らのモデルが学ぶ方法によるものです。 実際、ソーシャルメディアユーザーのように話す可能性が高いのは、それがトレーニングデータの大部分だからです。
一方、MarketMuse NLGテクノロジーは、適切に構成された記事でトレーニングされ、ドラフトの特定の主題に関する記事を使用して特別に微調整されます。 このように、MarketMuse NLGテクノロジーの出力は、GPT-3よりも専門家の考えによく似ています。
概要
MarketMuse NLGテクノロジーは、特定の課題を解決するために作成されました。 コンテンツチームがより良いコンテンツをより速く作成できるようにする方法。 これは、すでに成功しているAIを活用したコンテンツブリーフの自然な延長です。
GPT-3は研究の観点からは壮観ですが、使用できるようになるまでにはまだ長い道のりがあります。
あなたが今すべきこと
準備ができたら…より良いコンテンツをより速く公開するための3つの方法を次に示します。
- MarketMuseで時間を予約するストラテジストの1人と一緒にライブデモをスケジュールして、MarketMuseがチームのコンテンツ目標の達成にどのように役立つかを確認します。
- より良いコンテンツをより速く作成する方法を学びたい場合は、私たちのブログにアクセスしてください。 コンテンツのスケーリングに役立つリソースが満載です。
- このページを読んで楽しんでいる別のマーケティング担当者を知っている場合は、電子メール、LinkedIn、Twitter、またはFacebookを介して共有してください。