
Canonical タグとは何か、いつ使用するか
公開: 2022-11-03rel="canonical" とも呼ばれる canonical タグは、どの URL がコンテンツのプライマリ バージョンまたは「マスター コピー」であるかを検索エンジンに伝える HTML タグです。 これらの単純なタグを使用すると、サイト所有者は、Google が検索結果に表示する優先ページとして指定する URL を 1 つ提案できます。 Canonical タグは、コンテンツの重複によって発生する SEO の問題も防ぎます。
これらの単純な HTML リンク要素は、サイトの SEO において重要な役割を果たします。 使い方も簡単ですが、正しく使用しないと機能しません。 canonical タグに慣れていない場合、この記事は、canonical タグを使用する方法、タイミング、理由、および canonical タグの問題を回避する方法を学ぶのに役立ちます。
Canonical タグとは何ですか?
canonical タグは、ページのヘッダーまたは <head> に挿入される HTML リンク要素です。 これらのタグは検索エンジンによって開発され、2009 年に公開されました。これらは、検索エンジンがサイト所有者と協力して検索結果の品質を向上させた素晴らしい例の 1 つです。
Canonical タグは、検索エンジンに次のいずれかを伝えます。
- ページ上のそのコンテンツは、プライマリ バージョンと見なされるページに加えて、別のページの複製です。
- 複数の URL を持つ 1 つのページの場合、タグは Googlebot または Bing bot に正確にどの URL がインデックスに登録するのに適しているかを伝えます。
このタグは、重複ページではなくプライマリ ページをインデックスに登録するようにクローラーに指示します。 正規 URL は、検索エンジンが検索エンジンの結果に表示する必要があるページを Google に示します。このタグは、プライマリ バージョンがオーガニック検索の可視性を受け取るべきものであることを検索エンジンに伝えます。
インデックスに登録する URL を Google に指示することはできますが、 Google が推奨事項に従わない場合があることに注意してください。
正規タグは次のようになります。
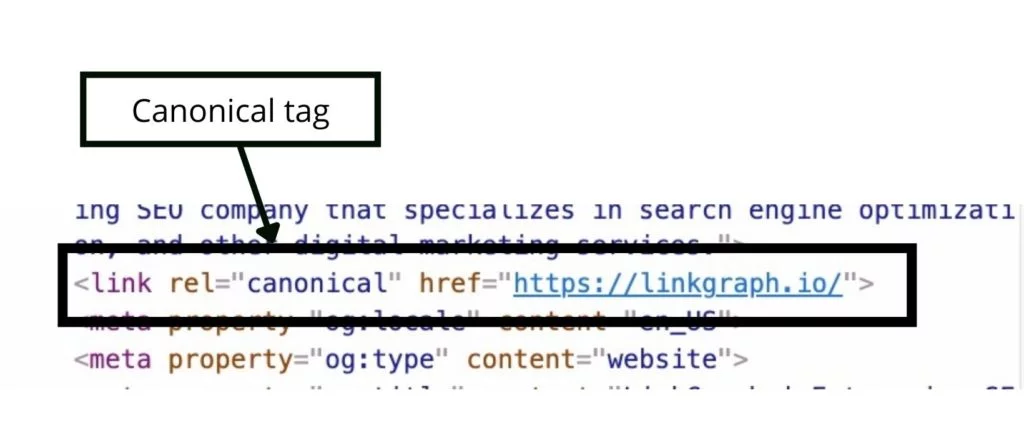
または
<link rel= “canonical” href= “ https://example.com “ />
Canonical タグの構成要素は何ですか?
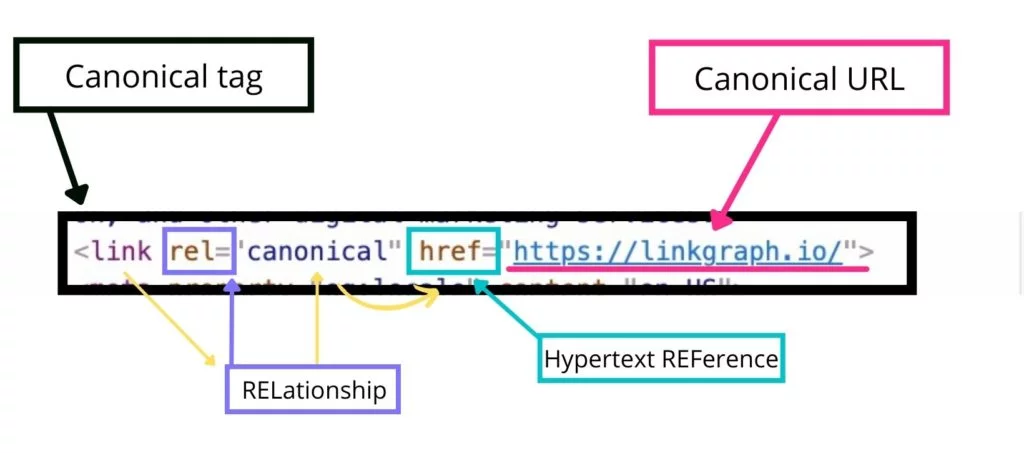
canonical タグは、canonical link 要素とも呼ばれます。これは、この独自の HTML コードのより直感的なラベルです。 なんで? 正規タグは正規リンクを提供し、ページとリンクの間の関係を定義するためです。
HTML では、 relは、ページとリンクされたリソースの間に関係があることを Googlebot に伝えます。 この場合、リレーションシップは、 href属性の後に表示される正規ページを識別します (href はハイパーテキストの REFerence です)。
正規 URL とは
正規 URL は、サイトの所有者が検索エンジンにコンテンツのプライマリ ソースとして認識してもらいたい Web ページのプライマリ バージョンです。 正規 URL は、Web クローラーがコンテンツの正しいソースとしてインデックスを作成する Web ページです。 リンク要素のこの部分は、href="canonicalURL" の後に表示されます。
Canonical タグは Canonical URL と同じですか?

canonical URL は canonical タグ内に表示されます。 canonical URL は、canonical タグ内のハイパーリンク参照要素です。 これは、ソース コンテンツの正規バージョンと見なされる正確な URL を示します。
正規化が重要な理由
e コマース サイトや広告収入を生み出すサイトに関しては、検索エンジンの結果ページ (SERP) に最適な URL を表示するあらゆる機会を確実に利用する必要があります。 正規化は、どのサイトをインデックスに登録する必要があるかを Google に伝えることで、まさにこれを行います。 サイトをより細かく制御できるだけでなく、ユーザーを最も価値の高いページに誘導することもできます。
自己参照正規タグを使用する必要がありますか?
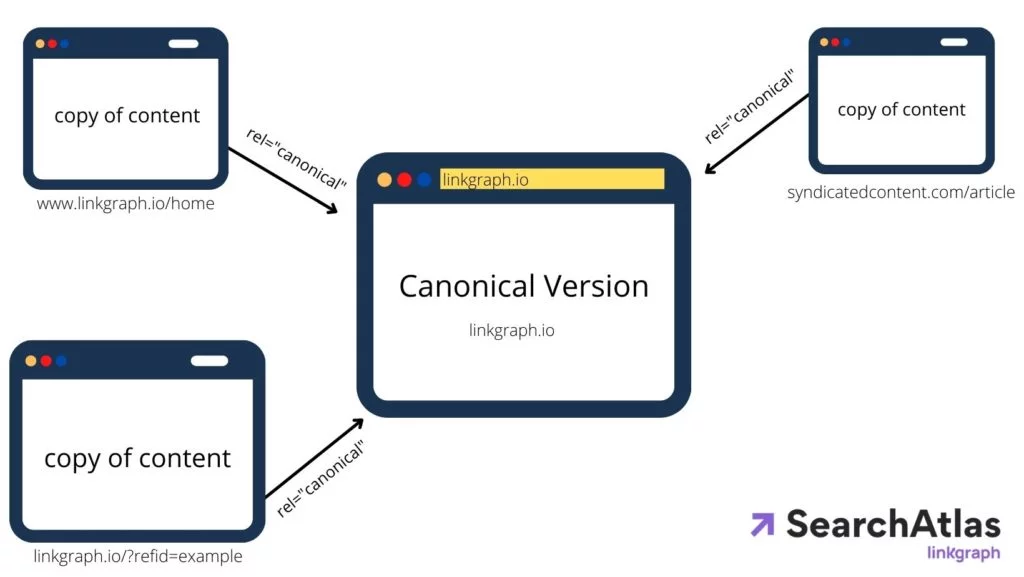
ユニークに見える Web ページでも、さまざまな URL で見つけることができます。 例えば:

これらの URL はそれぞれ同じホームページを表示しますが、技術的にはそれぞれが独自の URL です。 これにより、サード パーティの Web サイトにコンテンツが重複している場合と同じ問題が発生する可能性があります。 linkgraph.io に canonical タグがないと、検索エンジンのアルゴリズムは、検索者に表示する優先 URL を判断できません。
検索エンジンをさらに混乱させるのは、動的ページにさまざまなタグがあり、それぞれに独自の URL があることです。 WordPress のようなコンテンツ管理システム (CMS) も、多くの場合、タグを Web ページに自動的に埋め込みます。 そのため、基本的なページでさえ、多数の URL で終わることになり、それぞれが検索エンジンによって完全にインデックス可能になります。
したがって、最善の策は、正規 URL のヘッダー内にも正規タグを配置することです。
Canonical タグによるデータ収集と分析の合理化
さらに、検索メトリクスを追跡しているので、同じ URL の下にある 1 つのページのすべてのオーガニック検索をコンパイルしたいと考えています。 canonical タグにより、指定したページのみが検索結果の指標を受け取るようになります。
シンジケート化されたコンテンツとの SEO 競合を防止する
多くの Web サイトは、コンテンツ シンジケーションを通じてバックリンクを構築しています。 ただし、コンテンツの作成は、タイムリーで費用のかかる投資になる可能性があります。 シンジケート関係を通じて、サードパーティのサイトで既存の高品質のコンテンツをユーザーに提供できます。 または、ブランドの認知度を高めながら、サイトにコンテンツのライブラリを構築し続けます。
ただし、canonical タグがないと、検索エンジンはサイトを記事またはサード パーティのどちらでインデックス化するかわかりません。 Canonical タグを使用すると、あなたとあなたのシンジケーション パートナーはこの問題を単純化できます。 注: 重複を防ぐために、いずれかのページで noindex タグを使用することもできます。
重複コンテンツの問題とは?

重複したコンテンツは、SEO に関連するさまざまな問題を引き起こす可能性があります。 Googlebot が同一または非常に類似したコンテンツを含むウェブページをインデックスに登録すると、次のことが可能になります。
- インデックス作成プロセスを遅くすると、インデックスに登録されるサイトが少なくなります。
- ネガティブ ランキング シグナルとして Google に登録すると、ページが SERP のさらに下にランク付けされます。
- どのページを検索者に表示するかについて、検索エンジンを混乱させます。
Canonical タグが SEO にどのように役立つか
何よりもまず、canonical タグは、Google がサイトを検索者に表示する方法に影響を与えることができる数少ない方法の 1 つです。 Canonicalization はまた、コンテンツが重複しているために PageRank で「ドッキング」されるのを防ぎます。Google は重複コンテンツを直接罰することはありませんが、よく整理されたオリジナル コンテンツを優先します。
最後に、バックリンクとブランド構築のための優れたコンテンツを Web サイト以外のユーザーに提供することもできます。
重複コンテンツとは?

重複コンテンツは、単にコピー アンド ペーストされたテキストではありません。 まったく同じ、類似、または並べ替えられたテキスト、画像、およびその他のメディアを記述することができます。 Google は、ウェブに公開されている場合、CMS の重複コンテンツからのプレースフィラーのテキストと画像も考慮します。
サイトのすべてのページにある著作権テキストなどの基本情報に、重複としてフラグが立てられることさえあります。
Canonical タグの使用方法
最終的に、最高の SEO 結果を得るには、Web サイト全体で canonical タグを使用することをお勧めします。 既存のページを更新したら、引き続き正規化のベスト プラクティスを実装する必要があります。
最初のステップは、サイト ページのどの URL バージョンを正規 URL にするかを特定することです。 Google は、正規リンクの形式が一貫していることが望ましいと考えています。 したがって、「www.」を使用すると、 ホームページの正規リンクに、他の正規 URL に含めます。
たとえば、LinkGraph では、canonical タグ全体で「https」プロトコルを使用していますが、「www」は含まれていません。

これにより、同じページを指す複数の URL に関する問題が解決されます。
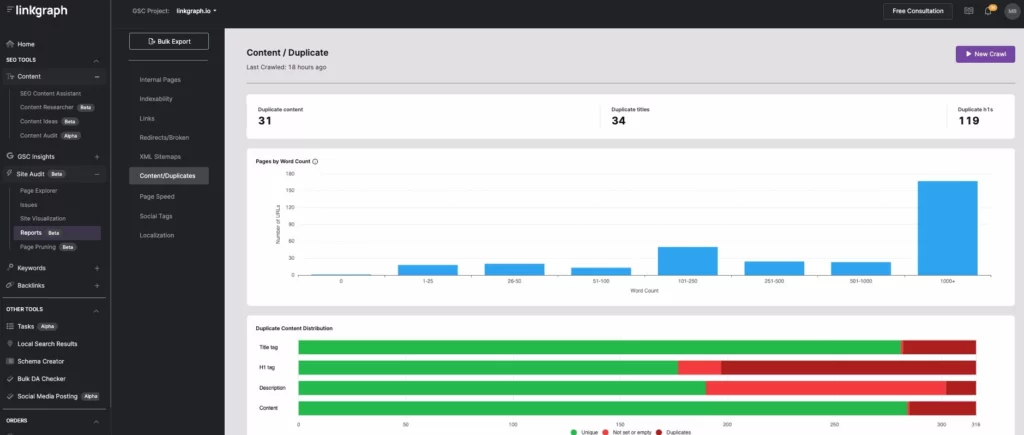
次に、サイト内の重複するコンテンツにタグを付けるか削除します。 これは、SearchAtlas の Site Audit ツールを使用して行うことができます。 コンテンツ/重複レポートを表示するのと同じくらい簡単です。
最後に、サード パーティのサイトに残っている重複コンテンツを見つけます。 これには、Copyscape などのツールを使用できます。 Web 上の他の場所にあるコンテンツを特定したら、次のことを決定します。
- あなたのコンテンツが盗まれ、許可なく再公開されました
- 既存のコンテンツまたは書かれたコンテンツを誤って盗用した場合、別のページのコンテンツに非常に似ています。
- シンジケートされたページが重複として登録されています
- 2 つの異なるカテゴリ ページに商品が表示されているなど、同じコンテンツのページがありますが、適切です。
次に、対応するソリューションで応答する必要があります。
- 重複を Google に報告する
- すぐにコンテンツを削除し、オリジナルの高品質のコンテンツを作成してください
- シンジケーション パートナーと正規 URL にするページについて話し合い、正しい正規 URL を反映する正規タグを実装します。
- 指定された canonical URL で canonical タグを使用する
Canonical タグを使用する場合
canonical タグに関しては、常に canonical タグを使用することでコンテンツの重複の問題を減らすことができます。 ただし、サイトを更新する場合は、次のことを優先する必要があります。

- バリエーション フィルタリングのある製品カテゴリ ページ: これには、さまざまなサイズ、ブランド、色、および数量が含まれます。 これらの各バリエーションには、異なる URL が必要です。
- ページネーションを使用する記事やページ: 多くの場合、これらは複数のページに分割された長いブログです。
- 複数のカテゴリ ページに表示される製品ページ。
- ビジネスに関する情報など、同様のコンテンツを含むページ。
Web サイトに Canonical タグを実装する
canonical タグを実装するにはウェブマスターである必要がありますか? 必ずしも。 サイトの HTML コードの操作に慣れている場合は、canonical タグを独自に実装できます。
正規タグを設定する方法は次のとおりです。
HTTP ヘッダーの正規タグ
canonical タグを採用する最も簡単な方法は、HTTP ヘッダーにタグ テキストを挿入して更新することです。 ページのこの HTTP ヘッダー セクションは次のようになります。 ![]()
1. 希望する正規 URL を特定します。
2. 非正規ページの <head> セクションに rel=canonical リンク タグを追加し、正しい正規 URL リンクを HTML リンク タグに挿入します。
次のようになります。

コピー アンド ペースト バージョン:
<link rel= “canonical” href= “https://yoursite/canonicalpage” />
それだけです。 ページの正規バージョンにリンクするには、ウェブマスターである必要はありません。
Canonical タグの検証
正しい URL を持つ canonical タグが正しく実装されているかどうかを確認するには、ウェブページのソース コードを表示する必要があります。 このプロセスは簡単です。
- まず、ブラウザを使用して、確認したい Web ページまたはコンテンツのバージョンに移動します。
- 次に、ページ内の任意の場所を右クリックし、[検査] を選択します。 これにより、自分のサイトまたは他のサイトのページ (または URL 検査ツール) のソース コードが開き、他のサイトの正規リンク要素が表示されます。
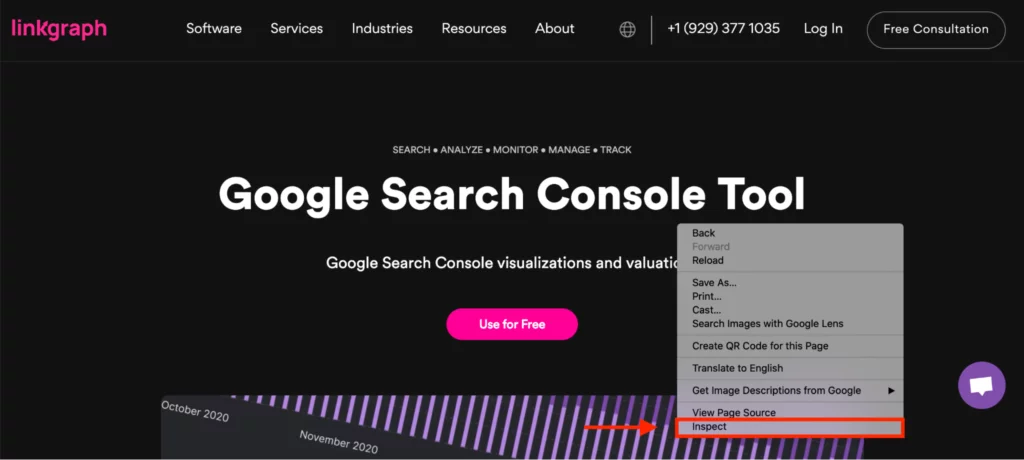
- HTML ソース コード メニューが開いたら、Ctrl + f (Windows の場合) または f + command (Mac の場合) を押します。 次に、文字列、セレクター、または XPath による検索に「canonical」と入力します。
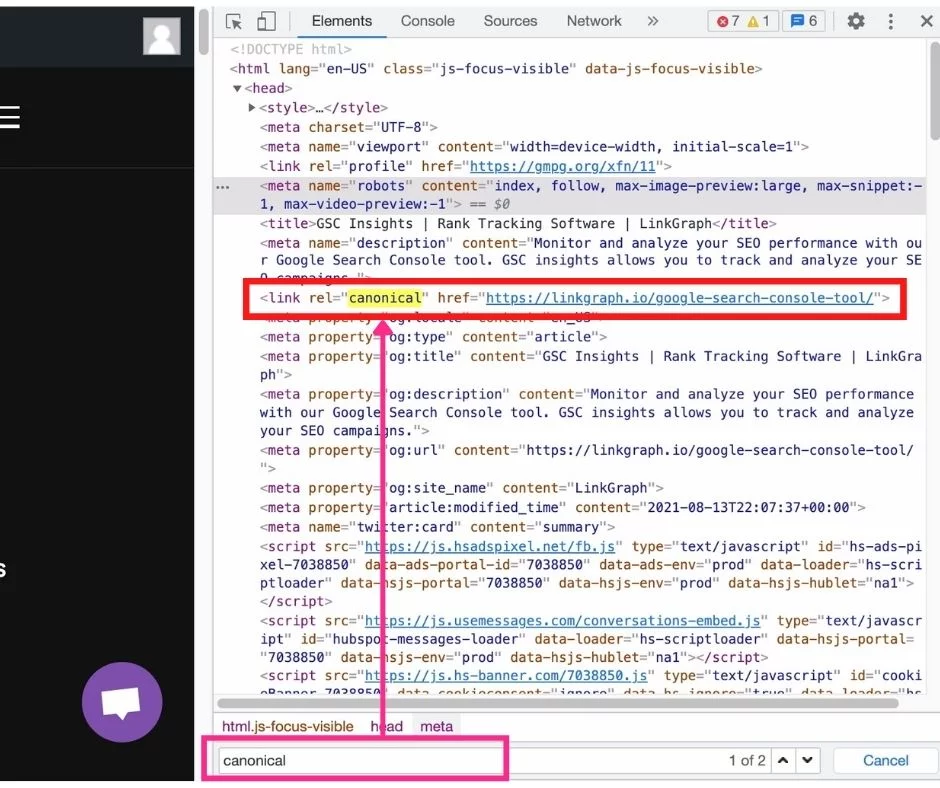
- 「canonical」という単語が表示され、黄色で強調表示されるため、ヘッダーが確認しやすくなります。 正規化された URL が正しいことを確認してください。 結果が表示されない場合、そのページには正規の HTML タグがありません。
Canonical タグを検証するその他の方法
Google Search Console と GSC Insights は、誤ってタグ付けされたページを見つけるための優れたツールです。 オーガニック トラフィックの統計を調べていると、検索トラフィックが非標準ページに到達していることに気付いた場合、標準タグが正しくない可能性があります。
これらのページを修正するには、特定の URL に移動してページを検査します。
サイトマップの正規 URL
サイトマップを作成または更新するときは、重複する URL を含めないでください。 正規 URL のみを含める必要があります。 サイトマップに正規バージョンのページが含まれていると、Google のボットがコンテンツの重複バージョンをクロールしないように示唆されます。
Robots.txt ファイルで重複ページを除外する必要がありますか?
robots.txtファイルで重複ページを禁止しないでください。 これにより、Google がこれらのページのランキング シグナルを使用できなくなります。 正規タグを正しく実装すると、エンゲージメント (クリック、スクロール、テキスト入力) などのランキング シグナルやコンテンツ シグナルが正規ページの指標にカウントされます。
CMS で Canonical タグを使用する方法
WordPress、Shopify、Wix、BigCommerce などの CMS プラットフォームを介してサイトを編集する場合。 これらの CMS のほとんどには、HTML ドキュメントを直接編集せずに正規リンク タグを追加するための具体的な手順が用意されています。 最も一般的な CMS プラットフォームについて説明します。
Yoast を Wix、Shopify、または WordPress サイトの Canonical タグに使用する
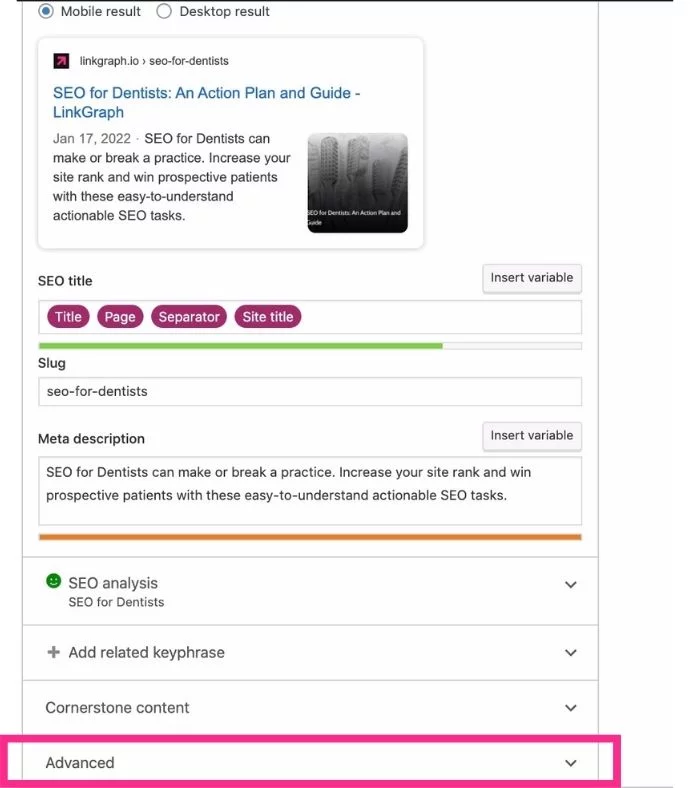
WordPress、Shopify、または Wix 用のYoast SEO プラグインを使用すると、優先 URL を簡単に編集して正規タグとして追加できます。
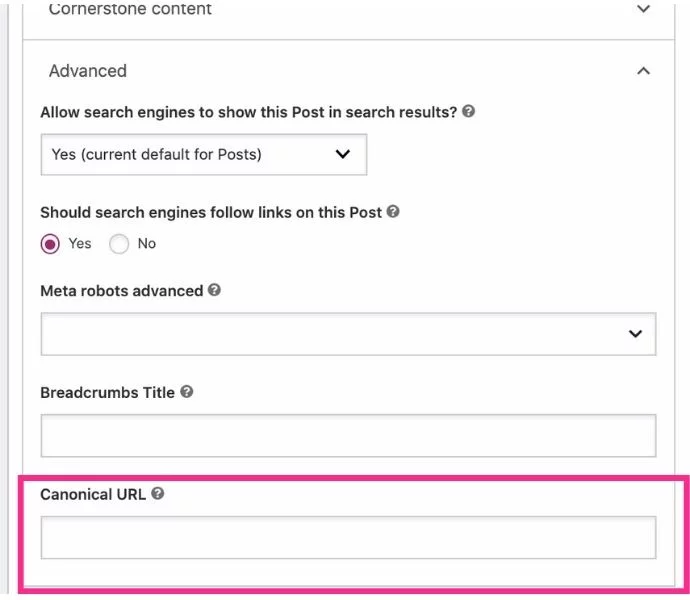
- Yoast SEO プラグインを追加すると、Yoast 編集の下部に [詳細] メニューが表示されます。 このメニューを開きます。
- 正規 URL として指定する URL のバージョンを入力します。
これらの8つの正規タグの間違いを犯さないでください

Canonical タグは、正しく実装された場合にのみ機能します。誤った実装は災害になる可能性があります。 幸いなことに、e コマース サイトまたは広告収益サイトが次の Google クロールを最大限に活用できるようにするために回避できるよくある間違いがあります。
優先されないバージョンのページへのオーガニック トラフィックを受信していることに気付いた場合は、次の問題を確認する必要があります。
1. 正規リンクの代わりに 301 リダイレクトを使用しない

Google やその他の検索エンジンは、Web サイトの構成を改善し、ユーザー エクスペリエンスを向上させるために正規属性を作成しました。 301 リダイレクトを使用すると、ページの読み込み時間が長くなります。 これは、サーバーがページの別のバージョンを取得する前に、リダイレクトされた URL を取得する必要があるためです。
さらに、正規属性の代わりにリダイレクトを選択すると、間違ったシグナルを Googlebot に送信することになります。
2. 内部リンクと正規タグ
内部リンクが指定されていないページを正規バージョンとして選択しないでください。 Canonical タグはクローラーへのヒントにすぎません。サイトマップに Canonical URL が表示されない場合は、インデックスに登録されない可能性が高くなります。
3. 重複ページで「noindex」を使用する

Googlebot が重複ページをインデックスに登録するのを防ぐ必要はありません。 実際、複製ページがリンク エクイティやその他の品質シグナルを正規ページに渡してほしいと考えています。
Noindexは、ゲートされたコンテンツや、検索結果から隠したいその他のコンテンツ用に予約する必要があります。
4. 正規化された URL の 4XX ステータス コードを防止する
正規リンクの URL を正しく入力してください。 使用するバージョンがわからない場合は、絶対 URL をデフォルトにすることを検討してください。
絶対 URL には、プロトコル (HTTPS)、ドメイン名 ( www.yourhomepage.com )、およびサブフォルダー (/subfolder) を含める必要があります。 HTTPS プロトコルを使用して、サイトがユーザーに対して SSL セキュリティを備えていることを示すことを忘れないでください。
また、優先 URL のスペルが正しいことを常に確認してください。 これは、404 エラーの最も一般的な理由です。
5. ページ分割されたすべてのページをルートページに正規化する
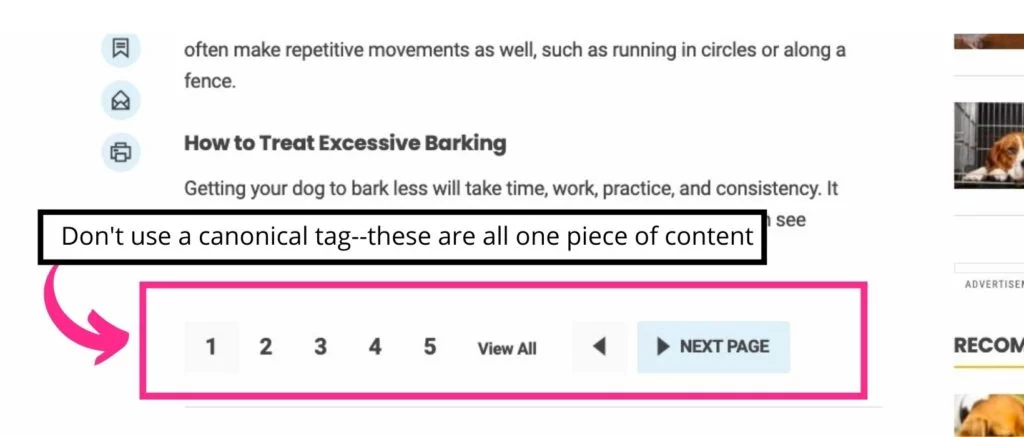
複数の Web ページを含むブログ投稿またはガイドを作成する場合は、後続のページからシリーズの最初のページに正規にリンクしないでください。 これにより、Googlebot がシリーズ全体をインデックスに登録できなくなります。 代わりに、rel="canonical" を rel="prev" および rel="next" に置き換えます。
6.HreflangタグでCanonicalsを使用しない
Hreflanf タグは、ページが複数の言語で表示されることを Google に伝え、多様な多地域のユーザーにより良いサービスを提供します。 異なる言語バージョンは、コンテンツの重複として表示される可能性があります。 そのため、Google では、ウェブマスターが常に正規タグと組み合わせて Hreflang タグを使用するようお願いしています。
7. 1 つのページで複数の Canonical タグを使用する
見過ごされがちな問題として、複数の rel=canonical タグを誤って使用することがあります。 この問題は、複数のユーザーがページを編集するときに発生する可能性があります。 幸いなことに、認識していれば簡単に修正でき、簡単に回避できます。
8. Canonical URL の基本的なタイプミス
canonical タグを挿入しても、オーガニック トラフィックが非優先ページに到達することに気付いた場合は、すべての要素が正しく配置されていることを再確認してください。 最も一般的にスキップされる文字の 1 つは、末尾のスラッシュであることに注意してください。
Canonical タグを採用して、より良い SEO 結果を享受
canonical タグを使用していない場合は、見逃している可能性があります。 Canonical タグを使用すると、URL のバリエーションから生じる多数の重複コンテンツの問題を防ぐことができるため、SEO のパフォーマンスが向上し、Google がクロールするサイトがより整理されます。 さらに、canonical タグを実装すると、すべての検索指標が無数のバリアントではなく、1 つの整然としたページにコンパイルされます。
利用可能な最高のキーワード追跡ツールを使用して、検索指標を先取りし、統合されたデータを最大限に活用してください。