
コンテンツマーケティングでNLPを使用する方法
公開: 2022-05-02TrustInsightsの共同創設者であるChrisPennと、MarketMuseの共同創設者兼最高製品責任者であるJeff Coyleが、マーケティング用AIのビジネスケースについて話し合います。 ウェビナーの後、PaulはSlackコミュニティのコンテンツ戦略コレクティブ(ここに参加)で何でも聞いてセッションに参加しました。 これがウェビナーノートとそれに続くAMAのトランスクリプトです。

ウェビナー
問題
コンテンツの爆発的な増加に伴い、新しい仲介者が生まれました。 彼らはジャーナリストやソーシャルメディアの影響力者ではありません。 それらはアルゴリズムです。 あなたとあなたの聴衆の間にあるすべてのものを指示する機械学習モデル。
これを説明しないと、コンテンツはあいまいになり続けます。
解決策:自然言語処理
NLPは、大量の自然言語データを処理および分析するためのコンピューターのプログラミングです。 これは、ドキュメント、チャットボット、ソーシャルメディアの投稿、Webサイトのページなど、本質的に言葉の山であるものすべてに由来します。 ルールベースのNLPが最初に登場しましたが、統計的自然言語処理に取って代わられました。
NLPの仕組み
自然言語処理の3つのコアタスクは、認識、理解、および生成です。
認識–コンピューターは人間のようにテキストを処理できません。 彼らは数字しか読めません。 したがって、最初のステップは、言語をコンピューターが理解できる形式に変換することです。
理解–テキストを数字で表すことにより、アルゴリズムは統計分析を実行して、どのトピックが最も頻繁に一緒に言及されているかを判断できます。
生成–分析と数学的理解の後、NLPの次の論理的なステップはテキストの生成です。 マシンを使用して、ライターがコンテンツ内で答える必要のある質問を明らかにすることができます。 別のレベルでは、人工知能は、専門家レベルのコンテンツを作成するための追加の洞察を提供するコンテンツブリーフを推進できます。
これらのツールは、MarketMuseを通じて現在市販されています。 これを超えて、今日遊ぶことができる自然言語生成モデルがありますが、商業的に使用可能な形式ではありません。 MarketMuseNLGテクノロジーは間もなく登場しますが。
言及された追加のリソース
- Huggingface.co
- Python
- R
- コラボ
- IBM Watson Studio

AMA
AI業界のトレンドに追いつくための記事やWebサイトの推奨事項はありますか?
そこに発表された学術研究を読んでください。 これらのようなサイトはすべて、最新かつ最高のものをカバーするという素晴らしい仕事をしています。
- KDNuggets.com
- データサイエンスに向けて
- Kaggle
それとFacebook、Google、IBM、Microsoft、Amazonの主要な研究出版ハブ。 これらのサイトで共有されているすばらしい資料がたくさんあります。
「すべてのコンテンツにキーワード密度チェッカーを使用しています。 今日のSEOにとって、これは合理的な戦略からどれだけ離れているのでしょうか?」
キーワード密度は、本質的に用語頻度カウントです。 それはテキストの非常に大まかな性質を理解するための場所を持っていますが、それはどんな種類の意味的な知識も欠いています。 NLPツールにアクセスできない場合は、少なくとも、選択したSEOツールの「ユーザーも検索した」コンテンツなどを確認してください。
コンテンツを…Webページに生成する方法について具体的な例をいくつか挙げてください。 投稿? ツイート?
課題は、これらのツールがまさにそれであるということです–それらはツールです。 ヘラをどのように操作するのですか? それはあなたが料理しているものに依存します。 スープをかき混ぜたり、パンケーキをひっくり返したりするのに使用できます。 この知識の一部を開始する方法は、技術的なスキルのレベルによって異なります。 たとえば、PythonとJupyterノートブックに慣れている場合は、文字通りトランスフォーマーライブラリをインポートし、トレーニングテキストファイルをフィードして、すぐに生成を開始できます。 私は特定の政治家のツイートでそれを行い、それは世界大戦3を開始するツイートを吐き出し始めました。技術的に慣れていない場合は、MarketMuseのようなツールを検討し始めてください。 ジェフ・コイルに、平均的なマーケターがそこでどのように始められるかについての提案をさせましょう。
ツールだけでなく、戦略についても詳しく調べた場合、この知識を活用するために実装できる戦略の例は何でしょうか。
いくつかのクイックヒットは、メタディスクリプション、ページまたはコンテンツブロックを分類法に分類するため、または回答が必要な質問を推測するためのものですが、これらは実際にはポイントソリューションです。 これを使用して、現在の強み、ギャップ、勢いがある場所を示すと、より大きな戦略的知恵が生まれます。 そこから、何を作成、更新、拡張するかを決定することは、ビジネスにとって変革をもたらします。 ここで、競合他社に対して同じことを行うことを想像してください。 彼らのギャップを見つける。 泡立て、すすぎ、繰り返します。
戦略は常に目標に基づいています。 どのような目標を達成しようとしていますか? 検索トラフィックを集めていますか? 潜在顧客をやっていますか? PRをしていますか? NLPは一連のツールです。 これは似ています–戦略はメニューです。 朝食、昼食、夕食のどちらを提供していますか? 使用するツールとレシピは、提供するメニューに大きく依存します。 スパナコピタを作る場合、スープポットは非常に役に立たないでしょう。
洞察を得るためにデータのマイニングを開始したい人にとって、良い出発点は何ですか?
科学的方法から始めます。
- どんな質問に答えたいですか?
- その質問に答えるには、どのようなデータ、プロセス、ツールが必要ですか?
- テストできる仮説、単一条件、おそらく真または偽のステートメントを作成します。
- テスト。
- テストデータを分析します。
- 仮説を精緻化または拒否します。
データ自体については、6Cデータフレームワークを使用してデータの品質を判断してください。
あなたの意見では、マーケターが考慮すべき主な検索ユーザーの意図は何ですか?
カスタマージャーニーに沿ったステップ。 顧客体験を最初から最後まで計画します–認識、検討、関与、購入、所有権、忠誠心、伝道。 次に、各段階での意図がどのようなものになる可能性があるかを計画します。 たとえば、所有権では、検索インテントはサービス指向である可能性が非常に高くなります。 「AirpodsProのパチパチという音を修正する方法」はその一例です。 課題は、旅の各段階でデータを収集し、それを使用してトレーニング/調整することです。
これは少し不安定になる可能性があると思いませんか? プロセスを自動化するためにより安定したものが必要な場合は、より高いレベルで物事を一般化する必要があります。
ジェフ・ベゾスは有名に言った、変わらないものに焦点を合わせなさい。 所有権への一般的な道筋はそれほど変わりません。チューインガムのパックに不満を持っている人は、委託した新しい空母に不満を持っている人と同じようなことを経験します。 詳細は確かに変わりますが、旅の途中で誰かが感情的にどこにいるのか、そしてそれを言語でどのように伝えるのかを知るには、どのような種類のデータと意図を理解することが不可欠です。
ユーザーインテント分類を行おうとすると、人々が陥る可能性のある落とし穴は何ですか?
はるかに、確証バイアス。 人々は彼ら自身の仮定を顧客体験に投影し、彼ら自身のバイアスを通して顧客データを解釈します。 また、可能な限り、インタラクションデータ(開いたメール、ドアの足元、コールセンターへの電話など)を可能な限り使用して検証することをお勧めします。 一部の場所、特に大規模な組織は、ユーザーの意図を理解するための構造化方程式モデリングの大ファンであることを私は知っています。 私は彼らほどファンではありませんでしたが、それは追加の潜在的なアプローチです。
クエリのユーザーの意図を判断するのに良い仕事をしていると思うツールや製品は何ですか?
横糸。 MarketMuse以外に? 正直なところ、特に主流のSEOツールから素晴らしい結果が得られなかったため、自分のもので作業する必要がありました。 ベクトル化と非構造化クラスタリングのためのFastText。
あなたの経験では、BERTはGoogle検索をどのように変えましたか?
BERTの主な貢献は、特に修飾子を使用したコンテキストです。 BERTを使用すると、Googleは語順を確認し、意味を解釈することができます。 それ以前は、これら2つのクエリは、バッグオブワードスタイルモデルでは機能的に同等である可能性があります。
- 最高のコーヒーショップはどこですか
- コーヒーを買うのに最適な場所はどこですか
これらの2つのクエリは非常に似ていますが、結果が大幅に異なる可能性があります。 コーヒーショップはあなたが豆を買いたい場所ではないかもしれません。 ウォルマートは間違いなくあなたがコーヒーを飲みたい場所ではありません。
AIやICTは、人間のように意識/感情/共感を育むと思いますか? それらをどのようにプログラムしますか? AIを人間化するにはどうすればよいですか?
その答えは、量子コンピューティングで何が起こるかによって異なります。 Quantumは、可変のファジー状態と、私たち自身の脳で起こっていることを模倣する超並列コンピューティングを可能にします。 あなたの脳は非常に遅い、化学物質ベースの大規模な並列プロセッサです。 すぐではないにしても、一度にたくさんのことをするのは本当に得意です。 Quantumを使用すると、コンピューターで同じことを実行できますが、はるかに高速になります。これにより、人工知能への扉が開かれます。 これが私の懸念事項です。これは、今日のAIの懸念事項であり、すでに狭い範囲で使用されています。私たちは、私たちに基づいてAIをトレーニングします。 人類は、自分自身や私たちが住んでいる惑星をうまく扱うという素晴らしい仕事をしていません。 私たちは自分のコンピューターがそれを模倣することを望んでいません。
システムが許す限り、コンピューターの感情は私たちの感情とは機能的に非常に異なり、化学ベースのニューラルネットワークの場合と同じようにデータから自己組織化するのではないかと思います。 つまり、彼らは私たちとは非常に異なった感じをするかもしれません。 主に論理とデータに基づいた機械が人類の率直で客観的な評価を行う場合、率直に言って、私たちが価値があるよりも問題が多いと判断する可能性があります。 そして、率直に言って、彼らは間違っていないでしょう。 私たちは種として、ほとんどの場合野蛮な混乱です。
あなたの意見では、コンテンツマーケターは、自然言語生成を日常のワークフロー/プロセスに統合/採用していると思いますか?
MarketMuseの製品でデモしたように質問に答えているだけでも、マーケターはすでに何らかの形で統合しているはずです。 視聴者が気にかけていることがわかっている質問に答えることは、意味のあるコンテンツをすばやく簡単に作成する方法です。 私の友人であるマーカス・シェリダンは、皮肉なことに、顧客のコア戦略を把握するために実際に読む必要のない素晴らしい本「They Ask、You Answer」を書きました。それは、人々の質問に答えることです。 実在の人物からの質問がまだない場合は、NLGを使用して質問してください。

今後2年間でAIとNLPはどこで進歩すると思いますか?
それを知っていたら、収入で購入した山頂の要塞にいるので、ここにはいません。 しかし、深刻なことに、過去2年間に見られた、変化の兆候が見られない主要な要点は、「自分でロールする」モデルから「事前にトレーニングされた微調整をダウンロードする」への進歩です。 マシンの合成が上手くいくにつれて、ビデオとオーディオのエキサイティングな時期が来ると思います。 特に音楽の生成は自動化のためのRIPEです。 現在、機械はせいぜい平凡な音楽を生成し、最悪の場合は耳障りな音楽を生成します。 それは急速に変化しています。 モデルの進行と最先端の結果の主要な次のステップとして、BARTが行ったように、トランスフォーマーとオートエンコーダーをブレンドするような例がさらにあります。
情報検索に関して、Googleの研究はどこに向かっていると思いますか?
グーグルが直面し続けている課題は、彼らの研究論文の多くに見られるように、規模です。 彼らは特にYouTubeのようなものに挑戦しています。 彼らがまだバイグラムに大きく依存しているという事実は、彼らの洗練度を損なうものではありません。それ以上のものには非常識な計算コストがかかることを認めています。 それらからの主要なブレークスルーは、毎日インターネットに注がれている新しいリッチコンテンツの大洪水に対処するためのスケールレベルほどモデルレベルではありません。
あなたが遭遇したAIの最も興味深いアプリケーションのいくつかは何ですか?
自律的なすべてが私が注意深く見ている領域です。 ディープフェイクもそうです。 注意しないと、これらは前方の道路がどれほど危険であるかの例です。 特にNLPでは、世代が急速に進歩しており、注目すべき分野です。
SEOが機能しないまたは機能しない方法でNLPを使用しているのを見たことがありますか?
カウントを失いました。 多くの場合、それは意図されていない方法でツールを使用し、標準以下の結果を得る人々です。 ウェビナーで述べたように、モデルのさまざまな最先端のテストのスコアカードがあり、ツールが強くない領域でツールを使用する人は、通常、結果を享受しません。 そうは言っても…ほとんどのSEO実践者は、ベンダーが提供するものを除いて、いかなる種類のNLPも使用しておらず、多くのベンダーは2015年もまだ立ち往生しています。それは常にすべてのキーワードリストです。
Googleでビデオ(YouTube)と画像検索をどこで見ますか? すべてのタイプの検索に使用されるGoogleによって展開されたテクノロジーは、互いに非常に類似しているか、または異なっていると思いますか?
Googleのテクノロジーはすべて、インフラストラクチャ上に構築されており、そのテクノロジーを使用しています。 多くがTensorFlowに基づいて構築されており、それには正当な理由があります。これは非常に堅牢でスケーラブルです。 状況が異なるのは、Googleがさまざまなツールをどのように使用するかです。 画像認識用のTensorFlowは、本質的に、ペアワイズ比較と言語処理用のTensorFlowとは非常に異なる入力とレイヤーを持っています。 しかし、TensorFlowとそこにあるさまざまなモデルの使用方法を知っていれば、自分でかなりクールなものを実現できます。
AIとNLPの進歩にどのように適応/追いつくことができますか?
読み、調査し、テストし続けてください。 少なくとも少しは手を汚す以外に方法はありません。 無料のGoogleColabアカウントにサインアップして、試してみてください。 少しPythonを教えてください。 StackOverflowからコード例をコピーして貼り付けます。 車を運転するために内燃エンジンのすべての内部動作を知る必要はありませんが、何かがうまくいかない場合は、少しの知識が大いに役立ちます。 AIとNLPについても同じことが言えます。ベンダーでBSに電話をかけることができるだけでも、貴重なスキルです。 これが、MarketMuseの人々と一緒に仕事をすることを楽しんでいる理由の1つです。 彼らは実際に彼らが何をしているのかを知っており、彼らのAIの仕事はBSではありません。
AIが仕事を引き受けることを心配している人々にあなたは何を言いますか? たとえば、NLGのようなテクノロジーを見て、編集者がテキストを少しだけクリーンアップするのにAIが「十分に優れている」場合、AIが機能しなくなるのではないかと心配しているライター。
「AIは仕事ではなく仕事に取って代わる」–ブルッキングス研究所そしてそれは絶対に真実です。 しかし、これが起こるので、ネットジョブは失われます。 あなたの仕事が50のタスクで構成されていると仮定します。 AIはそれらの30を行います。 これで、20個のタスクがあります。 あなたがそれをする唯一の人であるなら、あなたはニルヴァーナにいます。なぜなら、あなたはもっと面白くてもっと楽しい仕事をするための30単位以上の時間があるからです。 それがAIの楽観主義者が約束していることです。現実のチェック:5人がそれらの50ユニットを実行していて、AIがその30ユニットを実行している場合、AIは現在150/250ユニットの作業を実行しています。 つまり、100単位の仕事が残っており、企業は2人で100単位の仕事ができるので、すぐに3つのポジションを削減します。AIが仕事を引き受けることを心配しませんか? 仕事によって異なります。 あなたがする仕事が信じられないほど反復的であるならば、絶対に心配してください。 私の古い代理店には、検索結果をコピーしてクライアントのスプレッドシートに貼り付けることが仕事であった貧しい人々がいました(私は、最も技術的に進んだ場所ではなく、PR会社で働いていました)。 その仕事は差し迫った危険にさらされており、率直に言って何年も前からあったはずです。繰り返し=自動化=AI=タスクの損失。 繰り返しの少ない作業ほど、安全です。
それぞれの変化はまた、ますます多くの所得の不平等を生み出しました。 私たちは今、消費しない、消費しない機械が、消費する人々、消費する人々の仕事をますます行うという危険な状況にあります。これは、テクノロジーにおける莫大な富の支配に見られます。 これは、ある時点で取り組む必要のある社会的な問題です。
そしてそれに関する挑戦は進歩です力です。 ロバート・インガーソルが書いたように(そして後にエイブラハム・リンカーンに誤解された):「ほとんどすべての男性は逆境に耐えることができますが、男性の性格をテストしたい場合は、彼に力を与えてください。」今日の人々がどのように力を扱っているかがわかります。
GoogleAnalyticsデータをNLPResearchとペアリングするにはどうすればよいですか?
GAは方向を示し、NLPは作成を示します。 何が人気ですか? 私は少し前にクライアントのためにこれをしました。 彼らは何千ものウェブページとチャットセッションを持っています。 GAを使用して、サイトで最も急速に成長しているカテゴリを分析し、NLPを使用してそれらのチャットログを処理し、トレンドとコンテンツの作成に必要なものを示しました。
Google Analyticsは、何が起こったのかを伝えるのに最適です。 NLPは、その理由を少し説明し始めることができます。その後、市場調査でそれを完了します。
多くの研究で、データソースとしてTalkwalkerを使用しているのを見てきました。 分析のために他にどのような情報源とユースケースを検討する必要がありますか?
だから、とてもたくさん。 Data.gov。 トークウォーカー。 MarketMuse。 オーディオを転写するためのOtter.ai。 Kaggleカーネル。 Google Data Search –ちなみに、これはGOLDであり、使用しない場合は絶対に使用する必要があります。 GoogleニュースとGDELT。 そこには非常に多くの素晴らしい情報源があります。
マーケティングチームとデータ分析チームの間の理想的なコラボレーションは、あなたにとってどのように見えますか?
冗談じゃない; Katie Robbertと私がクライアントでいつも目にする最大の過ちの1つは、組織のサイロです。 左手は右手が何をしているのかわからず、どこでも熱狂的です。 人々を集め、アイデアを共有し、やることリストを共有し、共通の立場を持ち、互いに教え合う–機能的には「1つのチーム、1つの夢」であることが理想的なコラボレーションであり、コラボレーションという言葉を使う必要がなくなります。 。 人々はただ一緒に働き、すべてのスキルをテーブルにもたらします。
プレゼンテーションで頻繁にプレビューするMVPレポートと、それがどのように機能するかを確認できますか?
MVPレポートは、最も価値のあるページを表しています。 それが機能する方法は、Google Analyticsからパスデータを抽出し、それを順序付けてから、それをマルコフ連鎖モデルに通して、どのページが変換を支援する可能性が最も高いかを確認することです。
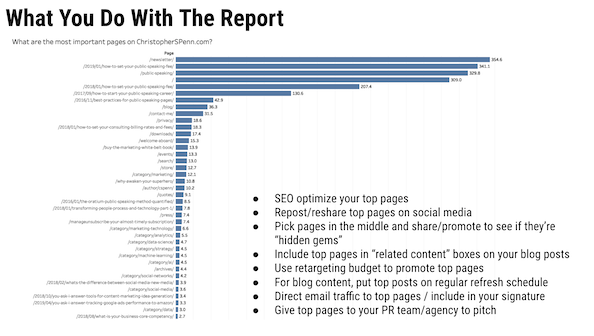
そして、もっと長い説明が必要な場合。
データバイアスについてもう少し洞察を与えることができますか? NLPまたはNLGモデルを構築する際の考慮事項は何ですか?
そうそう。 ここで言うことはたくさんあります。 まず、2つの基本的な種類があるため、バイアスとは何かを確立する必要があります。
人間の偏見は、一般的に「他のものと比較して何かに賛成または反対する偏見、通常は不公平と見なされる方法で」と定義されると認められています。
次に、数学的な偏りがあります。これは、「統計は、推定される母集団パラメータと体系的に異なる方法で計算された場合、偏りがある」と一般に定義されています。
それらは異なりますが、関連しています。 数学的バイアスは必ずしも悪いわけではありません。 たとえば、ビジネス感覚がある場合は、最も忠実な顧客に有利に偏ることを絶対に望んでいます。 人間の偏見は、特に保護されたクラスと見なされるもの(年齢、性別、性的指向、性同一性、人種/民族、ベテランの地位、障害など)に対して、不公平という意味で暗黙のうちに悪いものです。これらはあなたがしてはならないクラスです。差別する。
人間の偏見は、通常、人、戦略、データ、アルゴリズム、モデル、行動の6か所でデータの偏見を生みます。 私たちは偏見のある人を雇います–会社のエグゼクティブスイートまたは取締役会を見て、その偏見が何であるかを判断するだけです。 先日、PRエージェンシーが多様性への取り組みを宣伝し、エグゼクティブチームにワンクリックで参加しているのを見ました。彼らは単一の民族であり、15人全員です。
私はこれについてかなりの時間を続けることができましたが、マーケティングAIインスティテュートで、このトピックについて私が開発したコースを受講することをお勧めします。 NLGモデルとNLPモデルに関しては、いくつかのことを行う必要があります。
まず、データを検証する必要があります。 それに偏見はありますか?もしそうなら、それは保護されたクラスに対して差別的ですか? 第二に、それが差別的である場合、それを軽減することは可能ですか、それともデータを破棄する必要がありますか?
一般的な戦術は、メタデータをデバイアスに変換することです。 たとえば、60%が男性で40%が女性のデータセットがある場合、モデルトレーニングのためにバランスを取るために男性の10%を女性に再コード化します。 それは不完全でいくつかの問題がありますが、バイアスをかけるよりはましです。
理想的には、プロセス中にチェックを実行できるようにモデルに解釈可能性を構築し、その後、結果(説明可能性)を事後的に検証します。 モデルにバイアスを組み込んでいないことを証明する監査に合格できるようにする場合は、両方が必要です。 災いは事後の説明しかない会社です。
そして最後に、結果を検証するには、多様で包括的なチームを人間が監視する必要があります。 理想的にはサードパーティを使用しますが、信頼できる内部パーティは問題ありません。 モデルとその結果は、母集団自体から得られるよりも歪んだ結果を示していますか?
たとえば、16〜22歳向けのコンテンツを作成していて、生成されたテキストにデッドアス、ダンク、ローキーなどの用語が一度も表示されなかった場合、入力側のデータをキャプチャできませんでした。これにより、言語を正確に使用するようにモデルがトレーニングされます。
ここでの最大の主な課題は、非構造化データを介してこれらすべてに対処することです。 それが血統がとても重要な理由です。 系統がなければ、母集団を正しくサンプリングしたことを証明することはできません。 リネージュは、データソースが何であるか、どこから来たのか、どのように収集されたのか、規制要件や開示が適用されるかどうかについてのドキュメントです。
あなたが今すべきこと
準備ができたら…より良いコンテンツをより速く公開するための3つの方法を次に示します。
- MarketMuseで時間を予約するストラテジストの1人と一緒にライブデモをスケジュールして、MarketMuseがチームのコンテンツ目標の達成にどのように役立つかを確認します。
- より良いコンテンツをより速く作成する方法を学びたい場合は、私たちのブログにアクセスしてください。 コンテンツのスケーリングに役立つリソースが満載です。
- このページを読んで楽しんでいる別のマーケティング担当者を知っている場合は、電子メール、LinkedIn、Twitter、またはFacebookを介して共有してください。