
Noindex Nofollow と Disallow: 検索クローラー ディレクティブ
公開: 2022-12-01検索エンジンが検索結果としてサイトから情報を検出、保存、および提供する方法を指示するために使用できる 3 つのディレクティブ (コマンド) があります。
- NoIndex:マイページを検索結果に追加しません。
- NoFollow:このページのリンクを見ないでください。
- 許可しない:このページを一切見ないでください。
これらのディレクティブを使用すると、検索エンジンがクロールして検索結果に表示できるサイト ページを制御できます。
索引なし とはどういう意味ですか?
noindex ディレクティブは、Googlebot などの検索クローラーに、検索結果にウェブページを含めないように指示します。

ページに NoIndex をマークするにはどうすればよいですか?
noindexディレクティブを発行するには、次の 2 つの方法があります。
- ページの HTML コードに noindex メタ タグを追加します。
- HTTP リクエストで noindex ヘッダーを返す
ページに「no index」メタ タグを使用するか、HTTP 応答ヘッダーとして使用することで、本質的にページを検索から隠しています。
noindexディレクティブを使用して、特定の検索エンジンのみをブロックすることもできます。 たとえば、Google によるページのインデックス作成をブロックしても、Bing は許可できます。
例: ほとんどの検索エンジンをブロックする*
<meta name="robots" content="noindex">
例: Google のみをブロックする
<meta name="googlebot" content="noindex">
注: 2019 年 9 月以降、 Google は robots.txt ファイルの noindex ディレクティブを尊重しなくなりました。 Noindex は、HTML メタ タグまたは HTTP 応答ヘッダーを介して発行する必要があります。 より高度なユーザーの場合、 disallow は今のところ機能しますが、すべてのユース ケースでは機能しません。
noindex と nofollow の違いは何ですか?
これは、コンテンツの保存とコンテンツの発見の違いです。
noindexはページ レベルで適用され、検索エンジンのクローラーに、検索結果のページをインデックスに登録して提供しないように指示します。
nofollowはページまたはリンク レベルで適用され、検索エンジン クローラーにリンクをたどらない (発見しない) ように指示します。
基本的に、noindex タグは検索インデックスからページを削除し、nofollow 属性は検索エンジンのリンク グラフからリンクを削除します。
ページ属性としての NoFollow
ページ レベルで nofollow を使用すると、クローラーはそのページのリンクをたどって追加のコンテンツを検出することはなく、クローラーはそのリンクをターゲット サイトのランキング シグナルとして使用しません。
<meta name="robots" content="nofollow">
リンク属性としての NoFollow
リンク レベルで nofollow を使用すると、クローラーが広告固有のリンクを探索するのを防ぎ、そのリンクがランキング シグナルとして使用されるのを防ぎます。
nofollow ディレクティブは、a href タグ内の rel 属性を使用してリンク レベルで適用されます。
<a href="https://domain.com" rel="nofollow">
特に Google の場合、nofollow リンク属性を使用すると、サイトが PageRank をリンク先 URL に渡すことができなくなります。
ページを NoFollow としてマークする必要があるのはなぜですか?
ほとんどの場合、ページ全体を nofollow としてマークするべきではありません。個々のリンクを nofollow としてマークするだけで十分です。
ページ上のリンクを Google に表示させたくない場合、またはページ上のリンクがサイトに悪影響を与える可能性があると思われる場合は、ページ全体をnofollowとしてマークします。
ほとんどの場合、ページに投稿されるコンテンツを制御できない場合(例: ユーザーが生成したコンテンツをページに投稿できる場合)、包括的なページ レベルのnofollowディレクティブが使用されます。
一部のハイエンド パブリッシャーは、ページに nofollow ディレクティブを全面的に適用して、ライターがコンテンツ内にスポンサー リンクを配置するのを思いとどまらせています。
NoIndex ページの使用方法
ユーザーに価値を提供する可能性が低く、検索結果として表示されるべきではないページを noindex としてマークします。 たとえば、ページネーション用に存在するページは、時間の経過とともに同じコンテンツが表示される可能性はほとんどありません。
Domain.com/category/resultspage=2がdomain.com/category/resultspage=1よりも優れた結果をユーザーに表示する可能性は低く、2 つのページは検索で競合するだけです。 ページネーションのみを目的とするページはインデックスに登録しないことをお勧めします。
インデックスなしを考慮する必要があるページの種類は次のとおりです。
- ページネーションに使用されるページ
- 内部検索ページ
- 広告最適化ランディング ページ
- 例: ピッチとサインアップ フォームのみが表示され、メイン ナビゲーションは表示されません。
- 例: 広告のみに使用される、同じコンテンツの重複バリエーション
- アーカイブされた著者ページ
- チェックアウト フローのページ
- 確認ページ
- 例: ありがとうページ
- 例: 注文完了ページ
- 例:成功! ページ
- サイトに関係のないプラグイン生成ページ(例: コマース プラグインを使用しているが、通常の製品ページを使用していない場合)
- 管理ページと管理ログイン ページ
ページに Noindex と Nofollow のマークを付ける
noindex と nofollow の両方がマークされたページは、クローラーがそのページのインデックスを作成するのをブロックし、クローラーがページ上のリンクを探索するのをブロックします。
基本的に、以下の画像は、noindex および nofollow ディレクティブの使用方法に応じて、検索エンジンが Web ページに表示する内容を示しています。

すでにインデックスが作成されているページを NoIndex としてマークする
検索エンジンが既にページをインデックスに登録している場合、そのページをnoindexとしてマークすると、次にそのページがクロールされたときに、そのページは検索結果から削除されますインデックスからページを削除するこの方法を機能させるには、robots.txt ファイルでクローラーをブロック (禁止) してはなりません。
ページを読み取らないようにクローラーに指示している場合、 noindexマーカーは表示されず、コンテンツは更新されませんが、ページはインデックスに登録されたままになります。
検索エンジンが自分のサイトをインデックスしないようにするにはどうすればよいですか?
検索インデックスからページを削除する場合は、既にインデックスが作成されている場合は、次の手順を実行できます。
- noindex ディレクティブを適用するnoindex 属性を meta タグまたは HTTP 応答ヘッダーに追加する
- 検索エンジンにページのクロールをリクエストするGoogle の場合、検索コンソールでこれを行うことができます。Google にページの再インデックスをリクエストします。 これにより、Googlebot がページのクロールをトリガーし、Googlebot が noindex ディレクティブを検出します。ページを削除する検索エンジンごとにこれを行う必要があります。
- ページが検索から削除されたことを確認する クローラーに Web ページへの再アクセスをリクエストしたら、しばらく待ってから、ページが検索結果から削除されたことを確認します。 これを行うには、任意の検索エンジンに移動し、下の画像のようにサイト コロン ターゲット URL を入力します。
検索結果が返されない場合、そのページはその検索インデックスから削除されています。 - ページが削除されていない場合は、robots.txt ファイルに「disallow」ディレクティブがないことを確認してください。 Google などの検索エンジンは、ページのクロールが許可されていない場合、noindex ディレクティブを読み取ることができません。その場合は、対象ページの disallow ディレクティブを削除してから、再度クロールをリクエストしてください。
- robots.txt ファイルで、ターゲット ページの許可しないディレクティブを設定します。許可しない: /page$
robots.txt ファイルの URL の末尾にドル記号を付ける必要があります。そうしないと、そのページの下のページや、同じ文字列で始まるページが誤って許可されない可能性があります。 例: Disallow: /sweaterは /sweater-weather と /sweater/green も禁止しますが、 Disallow: /sweater$は正確なページ /sweater のみを禁止します。
どのようにGoogle 検索からページを削除するには
検索から削除したいページが所有または管理しているサイトにある場合、ほとんどのサイトでは Webmaster URL Removal Tool を使用できます。

ウェブマスター URL 削除ツールは、検索からコンテンツを約 90 日間のみ削除します。より永続的な解決策が必要な場合は、noindex ディレクティブを使用するか、robots.txt からのクロールを禁止するか、サイトからページを削除する必要があります。 Google では、URL を完全に削除するための追加手順をこちらで提供しています。
所有していないサイトの検索からページを削除しようとしている場合、次の条件を満たしている場合は、検索からページを削除するよう Google にリクエストできます。
- クレジット カードや社会保障番号などの個人情報を表示する
- ページがマルウェアまたはフィッシング スキームの一部である
- このページは法律に違反しています
- ページは著作権を侵害しています
ページが上記の基準のいずれにも当てはまらない場合は、SEO 会社または PR 会社に連絡して、オンラインの評判管理の支援を受けることができます。
カテゴリページのインデックスを作成しないでください。
通常、カテゴリ ページのインデックスを作成しないことはお勧めしません。ただし、エンタープライズ レベルの組織で、ユーザーが生成した検索やタグに基づいてプログラムでカテゴリ ページをスピンアップし、重複したコンテンツが扱いにくくなっている場合を除きます。
ほとんどの場合、ユーザーがサイトをより適切にナビゲートして必要なものを見つけられるように、コンテンツをインテリジェントにタグ付けしていれば問題ありません。
実際、カテゴリ ページは通常、カテゴリ トピックの下に詳細なコンテンツを表示するため、SEO の金鉱となる可能性があります。
2018 年 12 月に行ったこの分析を見て、いくつかのオンライン出版物のカテゴリ ページの価値を定量化してください。
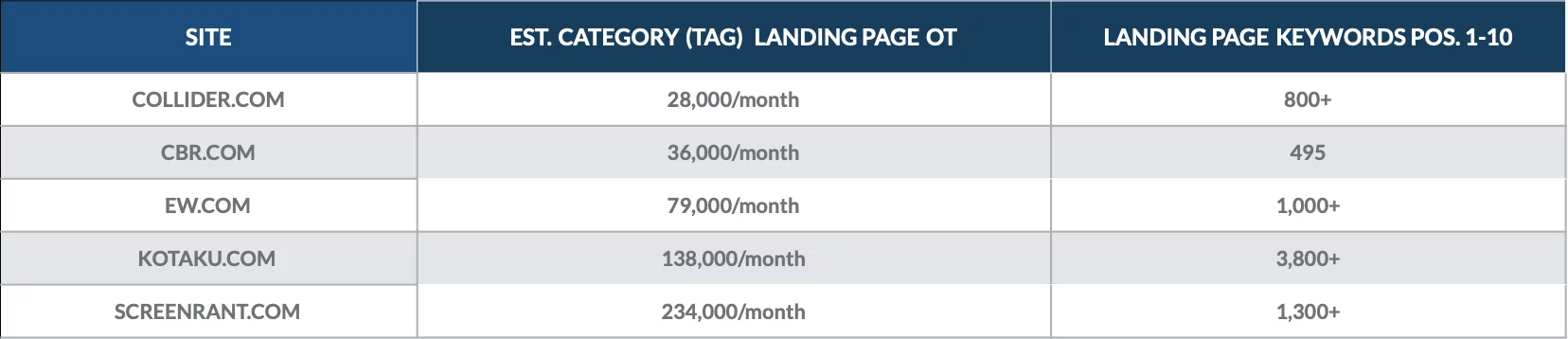
カテゴリのランディング ページは、何百ものページ 1 キーワードでランク付けされ、毎月何千ものオーガニック ユーザーを獲得していることがわかりました。
各サイトで最も価値のあるカテゴリ ページには、多くの場合、それぞれ数千人のオーガニック ユーザーがアクセスしました。
以下の EW.com を見てください。各ページへのトラフィック(円の大きさで表されます)と各ページへのトラフィックの値(円の色で表されます) を測定しました。
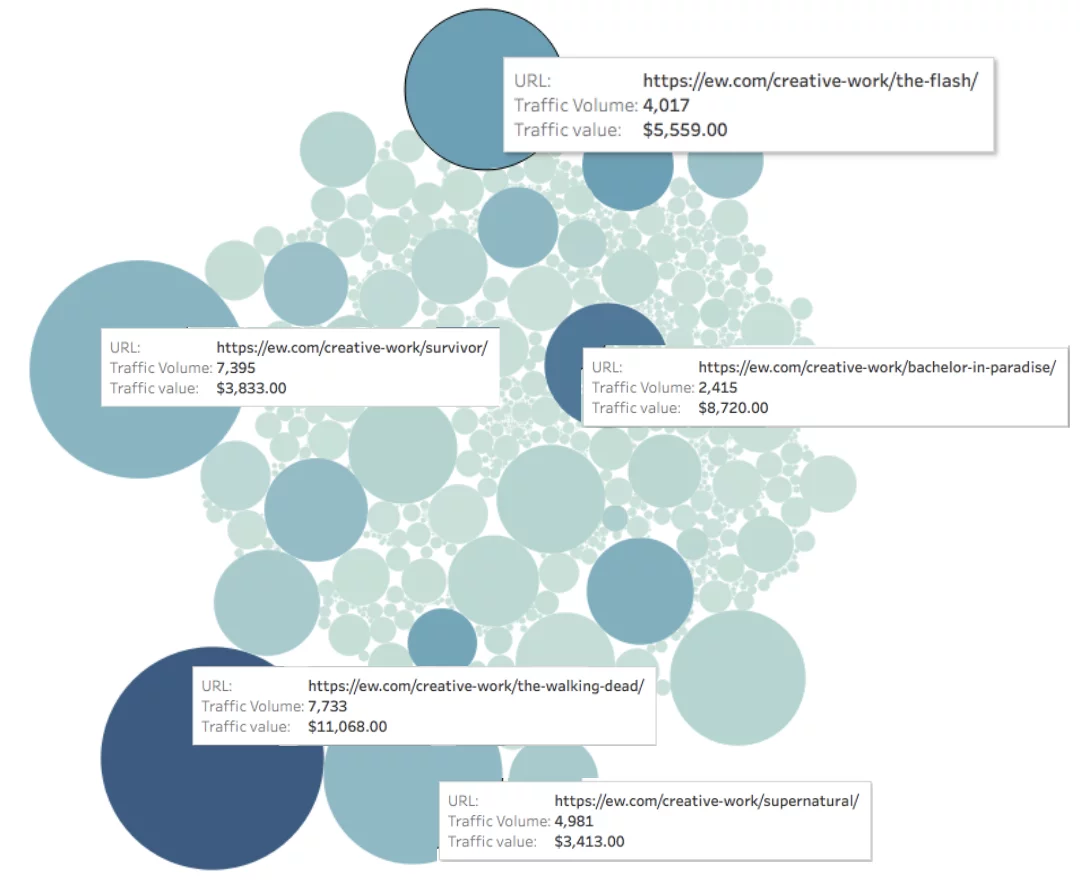
ページの月間オーガニック値 = 色の濃さ
同じグラフを想像してみてください。ただし、訪問者が積極的に購入する可能性が高い製品ベースのサイトを対象としています。
そうは言っても、ユーザーの混乱を引き起こしたり、検索で競合するほどカテゴリが類似している場合は、変更が必要になる場合があります。
- カテゴリを自分で設定する場合は、あるカテゴリから別のカテゴリにコンテンツを移行し、全体のカテゴリの総数を減らすことをお勧めします。
- ユーザーがカテゴリをスピンアップできるようにしている場合は、少なくとも新しいカテゴリがレビュー プロセスを経るまで、ユーザーが生成したカテゴリ ページのインデックスを作成しないことをお勧めします。
Google によるサブドメインのインデックス作成を停止するにはどうすればよいですか?
Google によるサブドメインのインデックス作成を停止するには、いくつかのオプションがあります。
- .htpasswd ファイルを使用してパスワードを追加できます
- robots.txt ファイルでクローラーを禁止できます
- サブドメイン内のすべてのページに noindex ディレクティブを追加できます
- すべてのサブドメイン ページを 404 にすることができます
ブロック インデックス作成へのパスワードの追加
サブドメインが開発目的の場合、サブドメインのルート ディレクトリに .htpasswd ファイルを追加するのが最適なオプションです。 ログイン ウォールは、クローラーによるサブドメインのコンテンツのインデックス作成を防ぎ、不正なユーザー アクセスを防ぎます。
ユースケースの例:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
robots.txt を使用してインデックス作成をブロックする
サブドメインが他の目的に役立つ場合は、robots.txt ファイルをサブドメインのルート ディレクトリに追加できます。 次に、次のようにアクセスできるようにする必要があります。
https://subdomain.domain.com/robots.txt
検索からブロックしようとしている各サブドメインに robots.txt ファイルを追加する必要があります。 例:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
いずれの場合も、robots.txt ファイルでクローラーを禁止する必要があります。1 つのコマンドでほとんどのクローラーをブロックするには、次のコードを使用します。
ユーザーエージェント: *
許可しない: /
user-agent: の後のアスタリスク *はワイルドカードと呼ばれ、任意の文字列に一致します。 ワイルドカードを使用すると、名前に関係なく、googlebot から yandex まで、すべてのユーザー エージェントに次の禁止ディレクティブが送信されます。
バックスラッシュは、サブドメイン外のすべてのページが disallow ディレクティブに含まれていることをクローラーに伝えます。
サブドメイン ページのインデックス作成を選択的にブロックする方法
サブドメインの一部のページを検索に表示させたいが、他のページは表示させたくない場合は、次の 2 つのオプションがあります。
- ページレベルの noindex ディレクティブを使用する
- フォルダまたはディレクトリ レベルの許可しないディレクティブを使用する
ページ レベルの noindex ディレクティブは、すべてのページの HTML またはヘッダーにディレクティブを追加する必要があるため、実装がより面倒になります。 ただし、noindex ディレクティブは、サブドメインが既にインデックスに登録されているかどうかにかかわらず、Google によるサブドメインのインデックス登録を停止します。
ディレクトリ レベルの disallow ディレクティブは実装が簡単ですが、サブドメイン ページがまだ検索インデックスにない場合にのみ機能します。 サブドメインの robots.txt ファイルを更新して、該当するディレクトリまたはサブフォルダーのクロールを禁止するだけです。
自分のページが NoIndexed かどうかを知るにはどうすればよいですか?
サイトにインデックス ディレクティブのないページを誤って追加すると、検索のランキングと検索の可視性に大きな影響を与える可能性があります。
優れたコンテンツとバックリンクがあるにもかかわらず、ページにオーガニック トラフィックが表示されない場合は、最初に、robots.txt ファイルのクローラーを誤って許可していないかどうかを確認してください。 それでも問題が解決しない場合は、個々のページで noindex ディレクティブを確認する必要があります。
WordPress ページの NoIndex を確認する
WordPress では、このタグをページに簡単に追加または削除できます。 ページの nofollow をチェックする最初のステップは、[設定] メニューの [閲覧] タブで検索エンジンの表示設定を切り替えるだけです。
これで問題が解決する可能性がありますが、この設定はルールではなく「提案」として機能するため、コンテンツの一部がインデックスに登録される可能性があります。
ファイルとコンテンツの完全なプライバシーを確保するために、利用可能な場合は cPanel 管理ツールを使用するか、単純なプラグインを使用して、サイトをパスワードで保護する最後のステップを実行する必要があります。
同様に、コンテンツからこのタグを削除するには、パスワード保護を削除し、表示設定をオフにします。
Squarespace で NoIndex を確認する
Squarespace ページは、プラットフォームのコード インジェクション機能を使用して簡単に NoIndexed にすることもできます。 WordPress と同様に、Squarespace はパスワード保護を使用して日常的な検索から簡単にブロックできますが、プラットフォームは、コンテンツの完全性を保護するためにこの手順を実行しないようにアドバイスしています.
インターネット検索エンジンから隠したい各ページ内とその下の各サブページにコードの NoIndex 行を追加することで、パブリック アクセスを禁止する必要がある保護されたコンテンツの安全性を確保できます。 他のプラットフォームと同様に、このタグの削除も非常に簡単です。コード インジェクション機能を使用してコードを元に戻すだけです。
Squarespace は、競合他社が主にページ管理ツールの一連の設定の一部としてこのオプションを提供しているという点でユニークです. Squarespace はここから出発し、コードの個人的な操作を可能にします。 このスペースの他のコンテンツとは異なり、ページのコンテンツに加えている変更を確認できるため、これは興味深いことです。
Wix で NoIndex を確認する
Wix では、NoIndexing の問題を簡単かつ迅速に修正することもできます。 サイト内の単一のページを NoIndex にしたい場合は、「メニューとページ」設定で、「このページを検索結果に表示する」オプションを無効にするだけです。
競合他社と同様に、Wix も、プライバシーを強化するために、ページまたはサイト全体を保護するパスワードを提案しています. ただし、クローラーからコンテンツを保護するために、サポートチームが両方の面で並行したアクションを規定していないという点で、Wix は他のものとは異なります. メニューからページを非表示にすることと、検索条件からページを非表示にすることの違いについて、Wix は特に注意を払っています。
これは、サイトメニューから削除するとサイトからページに到達できなくなるが、慎重な Google 検索用語からは到達できないことを考えると、最初は違いを理解できない可能性がある、経験の浅い Web サイトビルダーにとって特に役立つアドバイスです。