
Word2Vecによるトピックモデリング
公開: 2022-05-02単語は、それが保持する会社によって定義されます。 これが、単語を数字に変換して多次元空間で表現する方法であるWord2Vecの背後にある前提です。 ドキュメントのコレクション(コーパス)で頻繁に近くにある単語も、このスペースに近くに表示されます。 それらは文脈的に関連していると言われています。
Word2Vecは、コーパスと適切なトレーニングを必要とする機械学習の方法です。 両方の品質は、トピックを正確にモデル化する能力に影響します。 非常に具体的で複雑なトピックの出力を調べると、これらが正確にモデル化するのが最も難しいため、欠点がすぐに明らかになります。 Word2Vecは単独で使用できますが、他のモデリング手法と組み合わせて制限に対処することがよくあります。
この記事の残りの部分では、Word2Vecの背景、動作、トピックモデリングでの使用方法、およびWord2Vecが提示するいくつかの課題について説明します。
Word2Vecとは何ですか?
2013年9月、Googleの研究者であるTomas Mikolov、Kai Chen、Greg Corrado、Jeffrey Deanが、論文「ベクトル空間での単語表現の効率的な推定」(pdf)を公開しました。 これが現在Word2Vecと呼ばれているものです。 この論文の目的は、「数十億の単語と数百万の単語を含む膨大なデータセットから高品質の単語ベクトルを学習するために使用できる手法を紹介すること」でした。
この時点より前は、自然言語処理技術は単語を単一の単位として扱いました。 彼らは単語間の類似性を考慮していませんでした。 このアプローチには正当な理由がありましたが、制限がありました。 これらの基本的な手法をスケーリングしても、大幅な改善が得られない状況がありました。 したがって、高度な技術を開発する必要があります。
この論文は、計算要件が低い単純なモデルで、高品質の単語ベクトルをトレーニングできることを示しました。 論文が結論付けているように、「はるかに大きなデータセットから非常に正確な高次元の単語ベクトルを計算することが可能です」。 彼らは、事実上無制限のサイズの語彙を提供する1兆語のドキュメントコレクション(コーパス)について話しています。
Word2Vecは、単語を数字(この場合はベクトル)に変換する方法であり、類似点を数学的に発見できるようにします。 アイデアは、類似した単語のベクトルがベクトル空間内でグループ化されるというものです。
地図上の緯度と経度の座標を考えてみてください。 この2次元ベクトルを使用すると、2つの場所が比較的接近しているかどうかをすばやく判断できます。 ベクトル空間で単語を適切に表現するには、2次元では不十分です。 したがって、ベクトルには多くの次元を組み込む必要があります。
Word2Vecはどのように機能しますか?
Word2Vecは、入力として大きなテキストコーパスを受け取り、浅いニューラルネットを使用してそれをベクトル化します。 出力は単語(語彙)のリストであり、それぞれに対応するベクトルがあります。 同様の意味を持つ単語は、空間的に近接して発生します。 数学的には、これはコサイン類似性によって測定されます。ここで、総類似性は0度の角度として表され、類似性は90度の角度として表されません。
単語は、さまざまなタイプのモデルを使用してベクトルとしてエンコードできます。 彼らの論文では、Mikolovetal。 2つの既存のモデル、フィードフォワードニューラルネット言語モデル(NNLM)とリカレントニューラルネット言語モデル(RNNLM)を調べました。 さらに、2つの新しい対数線形モデル、連続バッグオブワード(CBOW)と連続スキップグラムを提案します。
それらの比較では、CBOWとSkip-gramのパフォーマンスが優れていたので、これら2つのモデルを調べてみましょう。
CBOWはNNLMに似ており、ターゲット単語を決定するためにコンテキストに依存します。 前後の単語に基づいて対象単語を決定します。 ミコロフは、4つの未来と4つの歴史的な言葉で最高のパフォーマンスが発生したことを発見しました。 履歴内の単語の順序が出力に影響を与えないため、「単語のバッグ」と呼ばれます。 CBOWという用語の「連続」とは、「コンテキストの連続分散表現」の使用を指します。
スキップグラムはCBOWの逆です。 単語が与えられると、特定の範囲内の周囲の単語を予測します。 範囲が広いほど、より高品質の単語ベクトルが提供されますが、計算が複雑になります。 通常、現在の単語との関連性が低いため、離れた用語にはあまり重みがありません。
CBOWをSkip-gramと比較すると、Skip-gramは、大規模なデータセットでより高品質の結果を提供することがわかっています。 CBOWの方が高速ですが、Skip-gramは使用頻度の低い単語をより適切に処理します。
トレーニング中に、ベクトルが各単語に割り当てられます。 そのベクトルのコンポーネントは、(コンテキストに基づいて)類似した単語が互いに近づくように調整されます。 これを綱引きと考えてください。この綱引きでは、スペースに別の用語が追加されるたびに、この多次元ベクトル内で単語が押し出されたり引っ張られたりします。
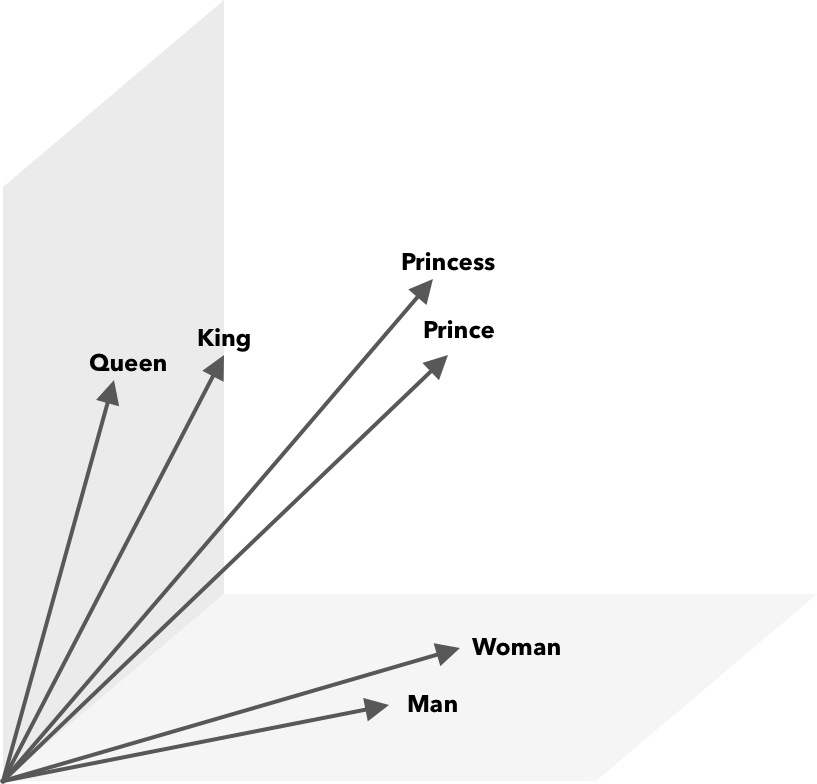
コサイン類似性に加えて、数学演算を単語ベクトルに対して実行できます。 たとえば、vector(” King”)– vector(” Man”)+ vector(” Woman”)は、単語Queenを表すベクトルに最も近いベクトルになります。
トピックモデリングのためのWord2Vec
Word2Vecによって作成された語彙を直接照会して、単語間の関係を検出したり、深層学習ニューラルネットワークに入力したりできます。 CBOWやSkip-gramなどのWord2Vecアルゴリズムの問題の1つは、各単語に均等に重みを付けることです。 ドキュメントを操作するときに発生する問題は、単語が文の意味を等しく表していないことです。

一部の単語は他の単語よりも重要です。 したがって、TF-IDFなどのさまざまな重み付け戦略が、状況に対処するために採用されることがよくあります。 これは、次のセクションで説明するハブネスの問題に対処するのにも役立ちます。 Searchmetrics ContentExperienceは、TF-IDFとWord2Vecの組み合わせを使用します。これについては、MarketMuseとの比較でここで読むことができます。
Word2Vecのような単語の埋め込みは、形態学的、意味論的、および構文上の情報をキャプチャしますが、トピックモデリングは、コーパス内の潜在的な意味論的構造化またはトピックを発見することを目的としています。
Budhkar and Rudzicz(PDF)によると、潜在的ディリクレ割り当て(LDA)とWord2Vecを組み合わせると、「これらのモデルに埋め込まれたコンテキスト情報の欠如によって引き起こされる問題に対処する」ための識別機能を生成できます。 LDA2vecの読みやすさは、このDataCampチュートリアルにあります。
Word2Vecの課題
Word2Vecを含め、一般的に単語の埋め込みにはいくつかの問題があります。 これらのいくつかに触れます。より詳細な分析については、Amir Bakarovによる「単語埋め込み評価方法の調査」(pdf)を参照してください。 コーパスとそのサイズ、およびトレーニング自体は、出力品質に大きな影響を与えます。
出力をどのように評価しますか?
バカロフが彼の論文で説明しているように、NLPエンジニアは通常、埋め込みのパフォーマンスを、計算言語学者やコンテンツマーケティング担当者とは異なる方法で評価します。 論文で引用されているいくつかの追加の問題があります。
- セマンティクスは漠然とした考えです。 「良い」単語の埋め込みは、セマンティクスの概念を反映しています。 しかし、私たちの理解が正しいかどうかを私たちは知らないかもしれません。 また、単語には、意味的関連性や意味的類似性など、さまざまなタイプの関係があります。 埋め込みという言葉はどのような関係を反映する必要がありますか?
- 適切なトレーニングデータの欠如。 単語の埋め込みをトレーニングする場合、研究者はデータに合わせて単語を調整することで品質を向上させることがよくあります。 これは、カーブフィッティングと呼ばれるものです。 結果をデータに適合させるのではなく、研究者は単語間の関係を把握するように努める必要があります。
- 内因性メソッドと外因性メソッドの間に相関関係がないということは、どのクラスのメソッドが好ましいかが不明確であることを意味します。 外部評価は、他の自然言語処理タスクでさらに下流で使用するための出力品質を決定します。 本質的な評価は、単語の関係の人間の判断に依存しています。
- ハブネスの問題。 一般的な単語を表す単語ベクトルであるハブは、他の単語ベクトルの数が多すぎます。 このノイズは評価にバイアスをかける可能性があります。
さらに、特にWord2Vecには2つの重要な課題があります。
- あいまいさをうまく処理することはできません。 その結果、複数の意味を持つ単語のベクトルは平均を反映し、理想からはほど遠いものになります。
- Word2Vecは、語彙外(OOV)の単語や形態学的に類似した単語を処理できません。 モデルが新しい概念に遭遇すると、正確な表現ではないランダムベクトルを使用することになります。
概要
Word2Vecまたはその他の単語の埋め込みを使用しても、成功を保証するものではありません。 質の高い出力は、適切で十分に大きなコーパスを使用した適切なトレーニングに基づいています。
出力の品質を評価するのは面倒な場合がありますが、コンテンツマーケター向けの簡単なソリューションを次に示します。 次回コンテンツオプティマイザーを評価するときは、非常に具体的なトピックを使用してみてください。 この方法でのテストに関しては、質の悪いトピックモデルは失敗します。 一般的な用語では問題ありませんが、リクエストが具体的になりすぎると機能しなくなります。
したがって、「アボカドを育てる方法」というトピックを使用する場合は、提案が一般的なアボカドではなく、植物の育てに関係していることを確認してください。
MarketMuse NLG Technologyの自然言語生成は、この記事の作成に役立ちました。
あなたが今すべきこと
準備ができたら…より良いコンテンツをより速く公開するための3つの方法を次に示します。
- MarketMuseで時間を予約するストラテジストの1人と一緒にライブデモをスケジュールして、MarketMuseがチームのコンテンツ目標の達成にどのように役立つかを確認します。
- より良いコンテンツをより速く作成する方法を学びたい場合は、私たちのブログにアクセスしてください。 コンテンツのスケーリングに役立つリソースが満載です。
- このページを読んで楽しんでいる別のマーケティング担当者を知っている場合は、電子メール、LinkedIn、Twitter、またはFacebookを介して共有してください。