
クロール バジェットとは何ですか? また、それを適切に最適化する方法は?
公開: 2021-08-19目次
クロール バジェット分析は、SEO エキスパートの職務の 1 つです (特に、大規模な Web サイトを扱っている場合)。 重要なタスクであり、Google が提供する資料で適切にカバーされています。 しかし、Twitter で見られるように、Google の従業員でさえ、より良いトラフィックとランキングを獲得する上でのクロール バジェットの役割を軽視しています。

彼らはこれについて正しいですか?
Google はどのように機能し、データを収集しますか?
話題を広げながら、検索エンジンがどのように情報を収集し、索引付けし、整理するかを思い出してみましょう。 次の 3 つの手順を頭の片隅に置いておくことは、後で Web サイトで作業する際に不可欠です。
ステップ 1: クロール. すべての既存のリンク、ファイル、およびデータを発見し、それらをナビゲートする目的で、オンライン リソースを精査します。 一般に、Google は Web で最も人気のある場所から始めて、トレンドの少ないその他のリソースをスキャンします。
ステップ 2: 索引付け。 Google は、ページの内容と、分析中のコンテンツ/ドキュメントが独自の素材または重複した素材を構成しているかどうかを判断しようとします。 この段階で、Google はコンテンツをグループ化し、重要な順序を確立します ( rel=”canonical”またはrel=”alternate”タグなどの提案を読み取ることにより)。
ステップ 3: サービング。 セグメント化されてインデックスが作成されると、ユーザーのクエリに応じてデータが表示されます。 これは、Google がユーザーの場所などの要因を考慮して、データを適切に並べ替える場合でもあります。
重要: 利用可能な資料の多くは、ステップ 4:コンテンツのレンダリングを見落としています。 デフォルトでは、Googlebot はテキスト コンテンツをインデックスに登録します。 しかし、ウェブ テクノロジーが進化し続けるにつれて、Google は単に「読む」だけでなく「見る」こともできるようにするための新しいソリューションを考案する必要がありました。 それがレンダリングのすべてです。 これは、Google が新しく立ち上げた Web サイト間でのリーチを大幅に改善し、インデックスを拡大するのに役立ちます。
注: コンテンツ レンダリングの問題は、クロール バジェットの失敗の原因である可能性があります。
クロール バジェットとは?
クロール バジェットとは、クローラーと検索エンジン ボットが Web サイトをインデックスに登録できる頻度と、1 回のクロールでアクセスできる URL の総数に他なりません。 クロール バジェットを、サービスやアプリで使用できるクレジットと想像してみてください。 クロール バジェットを「課金」することを忘れると、ロボットの速度が低下し、アクセス数が少なくなります。
SEO では、「課金」とは、バックリンクを獲得したり、Web サイトの全体的な人気を向上させたりするために費やされる作業を指します。 したがって、クロール バジェットは Web のエコシステム全体の不可欠な部分です。 コンテンツとバックリンクで良い仕事をしているときは、利用可能なクロール バジェットの上限を引き上げていることになります。
Google のリソースでは、クロール バジェットを明示的に定義することは一切行っていません。 代わりに、Googlebot の完全性とアクセス頻度に影響を与えるクロールの 2 つの基本的な要素を指摘しています。
- クロール レート制限;
- クロール需要。
クロール レートの制限とその確認方法を教えてください。
簡単に言うと、クロール レートの制限は、Googlebot がサイトをクロールするときに確立できる同時接続数です。 Google はユーザー エクスペリエンスを損なうことを望んでいないため、接続数を制限して、ウェブサイトやサーバーのスムーズなパフォーマンスを維持しています。 簡単に言えば、Web サイトが遅いほど、クロール レートの制限が小さくなります。
重要: クロール制限は、Web サイトの全体的な SEO の健全性にも依存します。サイトが多くのリダイレクト、404/410 エラーをトリガーする場合、またはサーバーが頻繁に 500 ステータス コードを返す場合、接続数も減少します。
Google Search Console のクロール統計レポートで利用可能な情報を使用して、クロール レート制限データを分析できます。
クロールの需要、または Web サイトの人気
クロール レート制限では Web サイトの技術的な詳細を磨く必要がありますが、クロールの需要は Web サイトの人気に報いるものです。 大雑把に言えば、あなたのウェブサイト(およびウェブサイト上)の話題が大きければ大きいほど、そのクロール需要は大きくなります。
この場合、Google は次の 2 つの問題を検討します。
- 全体的な人気 – Google は、インターネット上で一般的に人気のある URL を頻繁にクロールすることに熱心です (必ずしも、最も多くの URL からのバックリンクがあるとは限りません)。
- インデックス データの鮮度 – Google は最新の情報のみを提供するよう努めています。 重要: 新しいコンテンツをどんどん作成しても、全体的なクロール バジェットの上限が上がるわけではありません。
クロール バジェットに影響する要因
前のセクションでは、クロール バジェットをクロール レート制限とクロール デマンドの組み合わせとして定義しました。 Web サイトの適切なクロール (およびインデックス作成) を確実に行うには、両方を同時に処理する必要があることに注意してください。
以下に、クロール バジェットを最適化する際に考慮すべきポイントの簡単なリストを示します。
- サーバー– 主な問題はパフォーマンスです。 速度が遅いほど、Google が新しいコンテンツのインデックス作成に割り当てるリソースが少なくなるリスクが高くなります。
- サーバー応答コード– Web サイトでの 301 リダイレクトと 404/410 エラーの数が多いほど、インデックス作成の結果が悪化します。 重要: リダイレクト ループに注意してください。すべての「ホップ」は、ボットの次の訪問に対する Web サイトのクロール レート制限を減らします。
- robots.txt のブロック– robots.txt ディレクティブを直感に基づいて作成している場合、インデックス作成のボトルネックが発生する可能性があります。 結果: インデックスをクリーンアップしますが、新しいページのインデックス作成の有効性を犠牲にします (ブロックされた URL が Web サイト全体の構造にしっかりと埋め込まれている場合)。
- ファセット ナビゲーション / セッション識別子 / URL 内の任意のパラメーター– 最も重要なのは、1 つのパラメーターを持つアドレスが、制限なしでさらにパラメーター化される可能性がある状況に注意することです。 そうなった場合、Google は無限の数のアドレスに到達し、利用可能なすべてのリソースをウェブサイトの重要でない部分に費やします。
- 重複コンテンツ– コピーされたコンテンツ (カニバリゼーションを除く) は、新しいコンテンツのインデックス作成の有効性を著しく損ないます。
- 薄いコンテンツ– ページのテキストと HTML の比率が非常に低い場合に発生します。 その結果、Google はそのページをいわゆるソフト 404 として識別し、そのコンテンツのインデックス作成を制限することがあります (コンテンツが意味のあるものである場合でも、たとえば、単一の製品を提示しているメーカーのページに固有のものがない場合など)。テキストコンテンツ)。
- 内部リンクが不十分であるか、その欠如。
クロール バジェット分析に役立つツール
クロール バジェットのベンチマークがないため (つまり、Web サイト間で制限を比較するのは困難です)、データの収集と分析を容易にするために設計された一連のツールを用意してください。
Googleサーチコンソール
GSC は長年にわたって順調に成長してきました。 クロール バジェット分析では、インデックス カバレッジとクロール統計という 2 つの主なレポートを確認する必要があります。
GSC のインデックス カバレッジ
レポートは膨大なデータ ソースです。 インデックスから除外された URL の情報を確認してみましょう。 直面している問題の規模を理解するのに最適な方法です。
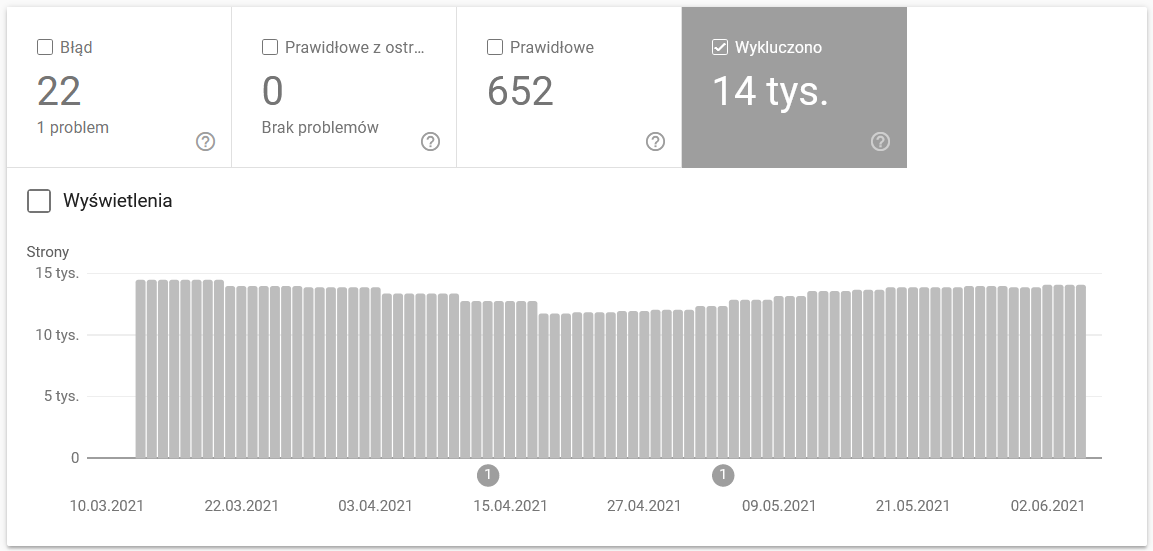
レポート全体は別の記事を保証するので、今のところ、次の情報に焦点を当てましょう。
- 「noindex」タグによる除外– 一般に、noindex ページが多いほど、トラフィックが少なくなります。 ここで疑問が生じます – それらをウェブサイトに残すことに何の意味があるのでしょうか? これらのページへのアクセスを制限するにはどうすればよいですか?
- クロール済み - 現在はインデックスに登録されていません - これが表示された場合は、コンテンツが Googlebot の目に正しく表示されるかどうかを確認してください。 そのステータスのすべての URL は、オーガニック トラフィックを生成しないため、クロール バジェットを浪費することに注意してください。
- 発見されました – 現在は索引付けされていません– 優先順位リストの一番上に置く価値のある、より憂慮すべき問題の 1 つです。
- ユーザーが選択したカノニカルなしで複製する - すべての複製ページは、クロール バジェットを損なうだけでなく、カニバリゼーションのリスクを高めるため、非常に危険です。
- 重複、Google はユーザーとは異なる標準を選択しました。理論的には、心配する必要はありません。 結局のところ、Google は私たちの代わりに適切な決定を下せるほど賢明でなければなりません。 実際には、Google はその canonical を非常にランダムに選択します。多くの場合、貴重なページを、正規のページを指すページで切り捨てます。
- ソフト 404 – すべての「ソフト」エラーは、重要なページがインデックスから削除される可能性があるため、非常に危険です。
- 重複して送信された URL が正規として選択されていません – ユーザーが選択した正規の欠如に関するステータス レポートと同様です。
クロール統計
このレポートは完璧ではありません。推奨事項に関する限り、古き良きサーバー ログも試してみることを強くお勧めします。これにより、データ (およびより多くのモデリング オプション) に対するより深い洞察が得られます。
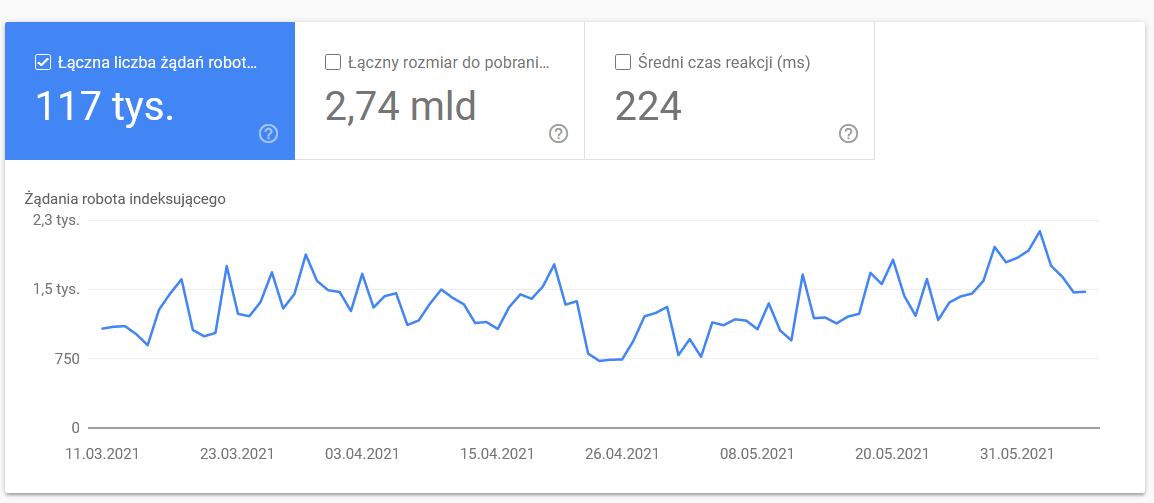
すでに述べたように、上記の数値のベンチマークを探すのは難しいでしょう。 ただし、以下を詳しく見てみるとよいでしょう。
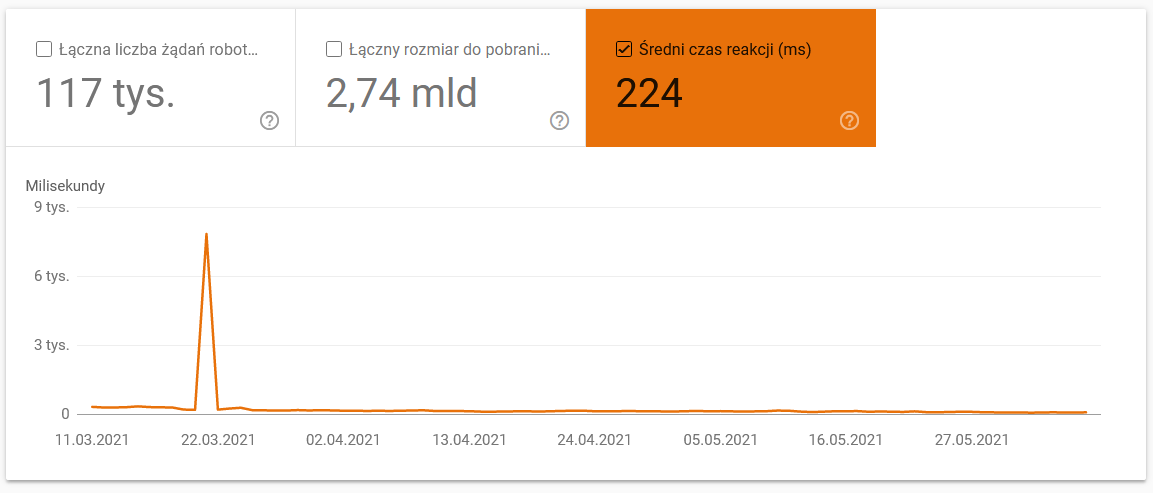
- 平均ダウンロード時間。 以下のスクリーンショットは、サーバー関連の問題が原因で平均応答時間が大幅に短縮されたことを示しています。
- 応答をクロールします。 一般的に、レポートを見て、Web サイトに問題があるかどうかを確認します。 以下の 304 のような非典型的なサーバー ステータス コードに細心の注意を払ってください。 これらの URL は機能的な目的を果たしませんが、Google はコンテンツのクロールにリソースを浪費します。

- クロールの目的。 一般に、これらのデータは、Web サイトの新しいコンテンツの量に大きく依存します。 Google が収集した情報とユーザーが収集した情報の違いは、非常に興味深いものです。
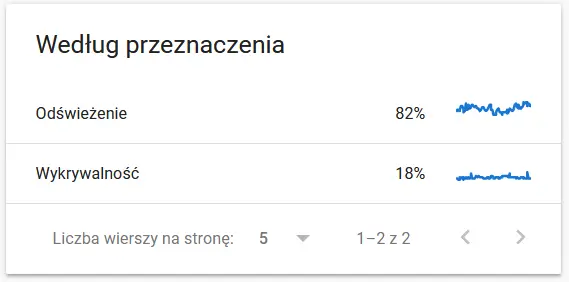
Google から見た再クロールされた URL の内容:
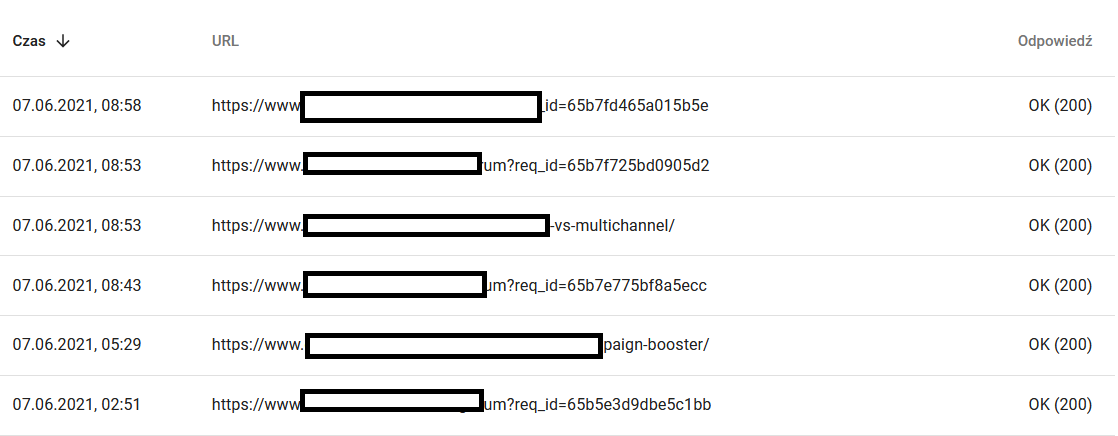
一方、ブラウザには次のように表示されます。
間違いなく思考と分析の原因です:)
- Googlebot タイプ。 ここでは、ウェブサイトにアクセスするボットと、コンテンツを解析する動機を示しています。 以下のスクリーンショットは、リクエストの 22% がページ リソースの読み込みに関するものであることを示しています。
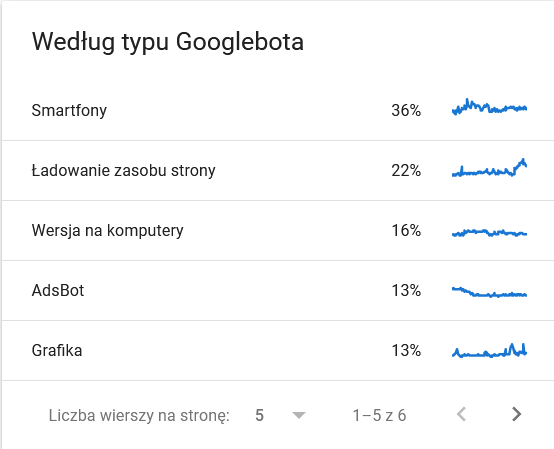
時間枠の最後の日に膨らんだ合計:
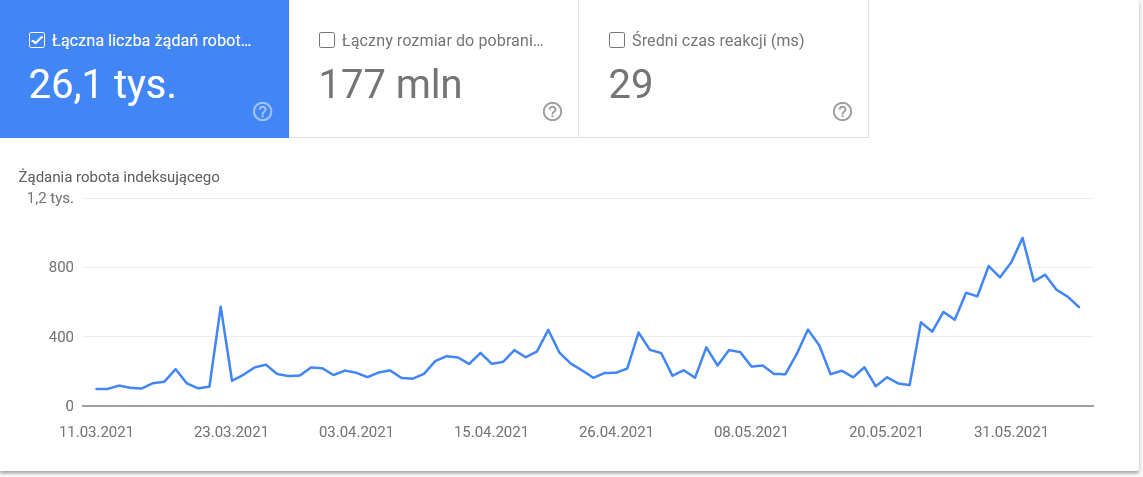
詳細を見ると、注意が必要な URL が明らかになります。
外部クローラー (Screaming Frog SEO Spider の例を含む)
クローラーは、Web サイトのクロール バジェットを分析するための最も重要なツールの 1 つです。 彼らの主な目的は、Web サイト上のクロール ボットの動きを模倣することです。 シミュレーションは、すべてが順調に進んでいるかどうかを一目で示します。
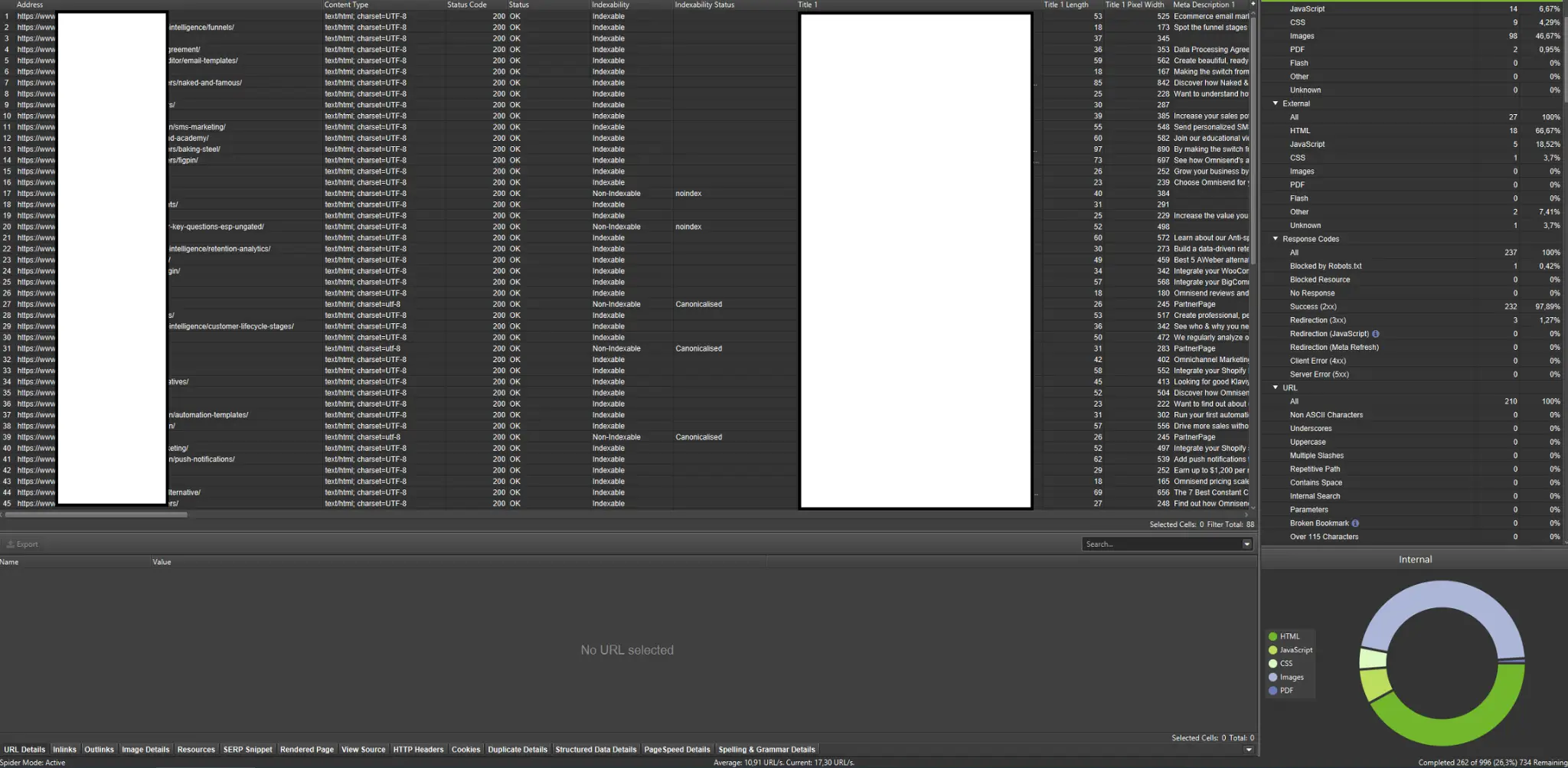
視覚的な学習者であれば、市場で入手可能なほとんどのソリューションがデータの視覚化を提供していることを知っておく必要があります。
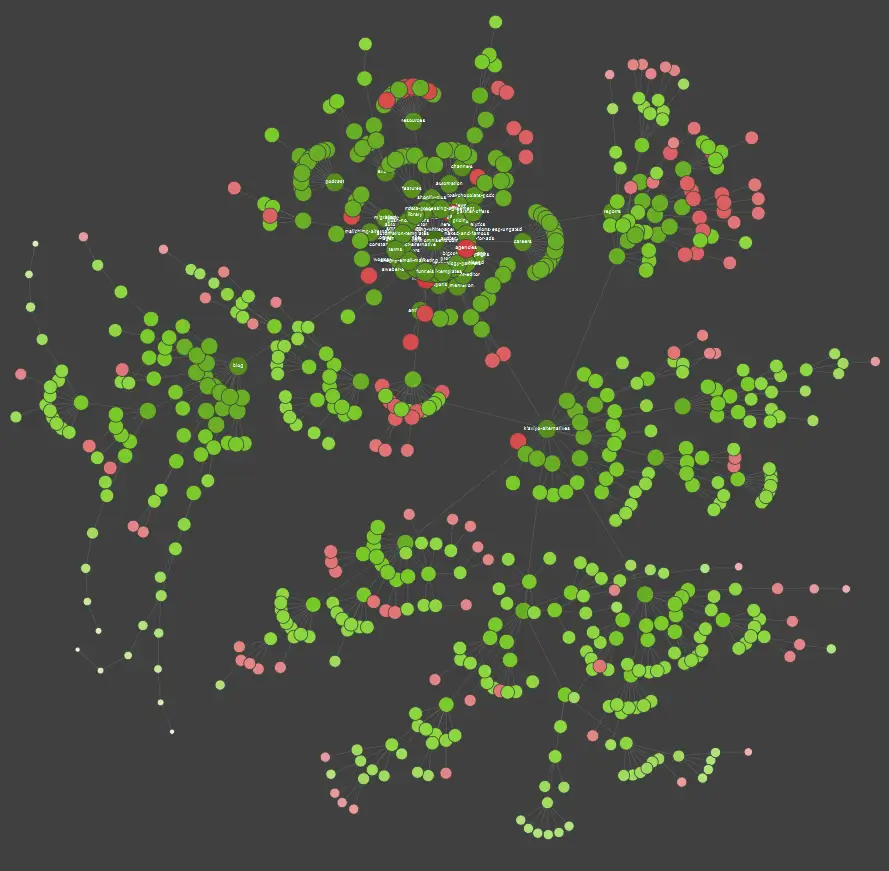
上記の例では、赤い点はインデックスが作成されていないページを表しています。 それらの有用性とサイトの運用への影響を検討するのに時間がかかります。 サーバー ログにより、これらのページが Google の多くの時間を浪費し、何の価値ももたらさないことが明らかになった場合は、Web サイトにそれらを保持するポイントを真剣に検討する必要があります。

重要: Googlebot の動作をできるだけ正確に再現するには、適切な設定が必要です。 ここでは、私のコンピューターからのサンプル設定を確認できます。
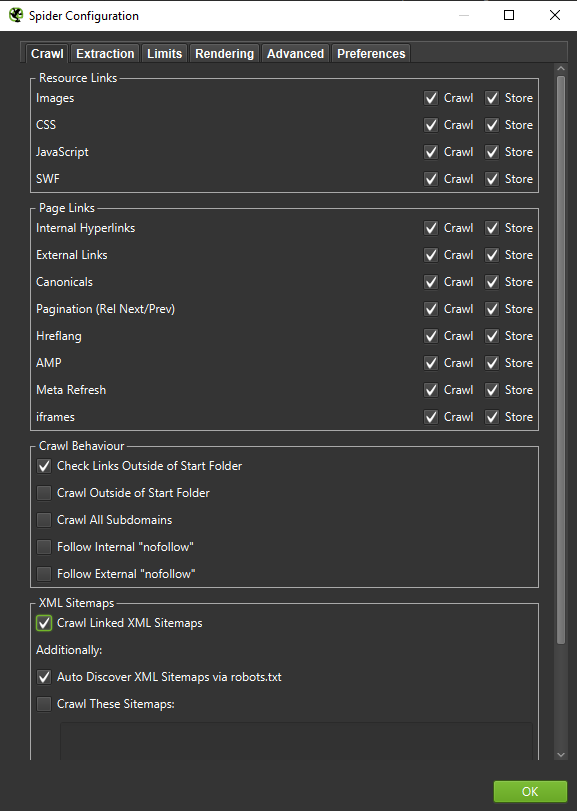
詳細な分析を行う場合は、テキストのみと JavaScript の 2 つのモードをテストして、相違点 (ある場合) を比較することをお勧めします。
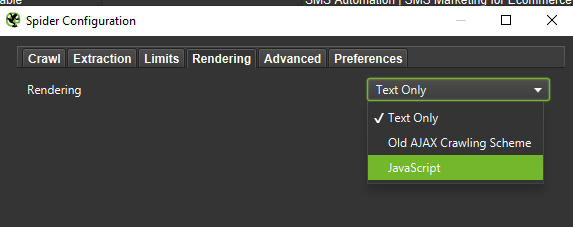
最後に、上記の設定を 2 つの異なるユーザー エージェントでテストしても問題はありません。
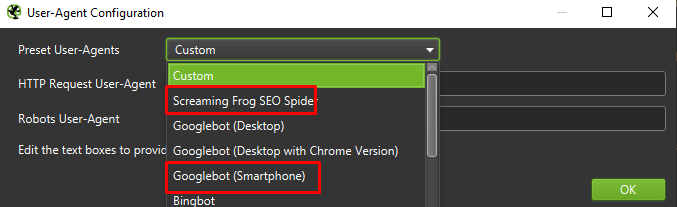
ほとんどの場合、モバイル エージェントによってクロールまたはレンダリングされた結果に注目するだけで済みます。
重要: Screaming Frog が提供する機会を利用して、クローラーに GA と Google Search Console からのデータをフィードすることもお勧めします。 統合は、トラフィックを受信しない潜在的に冗長な URL のかなりの部分など、クロール バジェットの浪費を識別するための迅速な方法です。
ログ分析用ツール (Screaming Frog Logfile など)
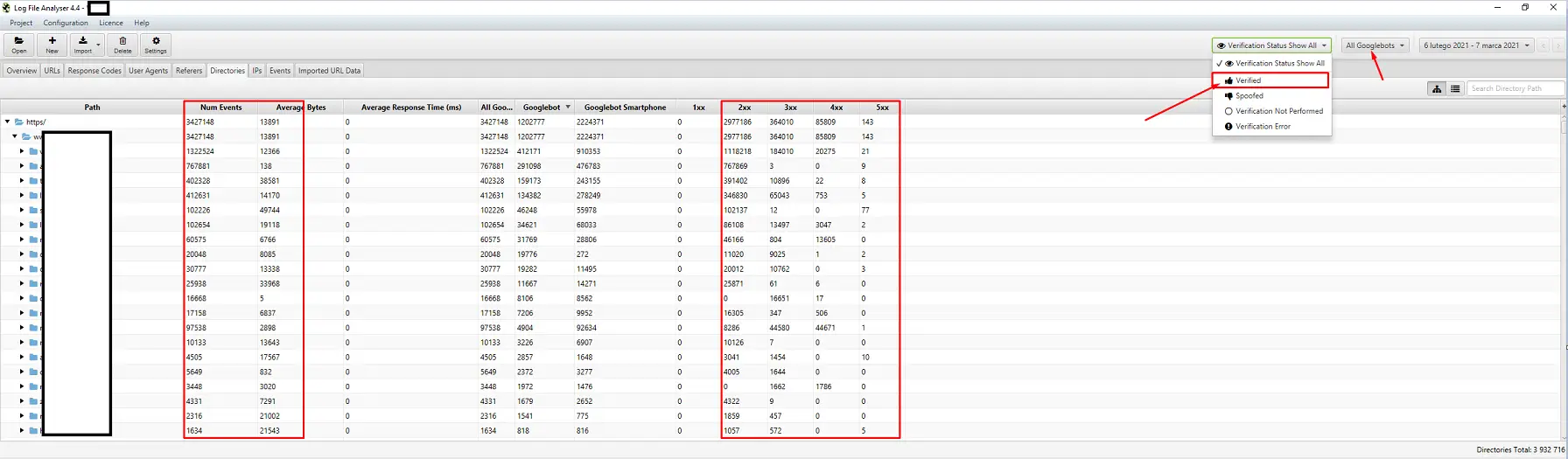
サーバー ログ アナライザーの選択は、個人的な好みの問題です。 私の頼りになるツールは、Screaming Frog Log File Analyzer です。 これは最も効率的な解決策ではないかもしれません (ログの巨大なパッケージをロードする = アプリケーションが停止する) が、インターフェイスは気に入っています。 重要な部分は、確認済みの Googlebot のみを表示するようにシステムに指示することです。
可視性追跡ツール
トップページを特定できるので便利です。 ページが Google の多くのキーワードで上位にランク付けされている (= 大量のトラフィックを受信している) 場合、より大きなクロール需要がある可能性があります (ログで確認してください。Google はこの特定のページに対して本当に多くのヒットを生成していますか?)。
私たちの目的のために、今後の継続的なレビューのために、Senuto の一般的なレポート (パスと URL) が必要になります。 どちらのレポートも、[可視性分析] の [セクション] タブで利用できます。 見てください:
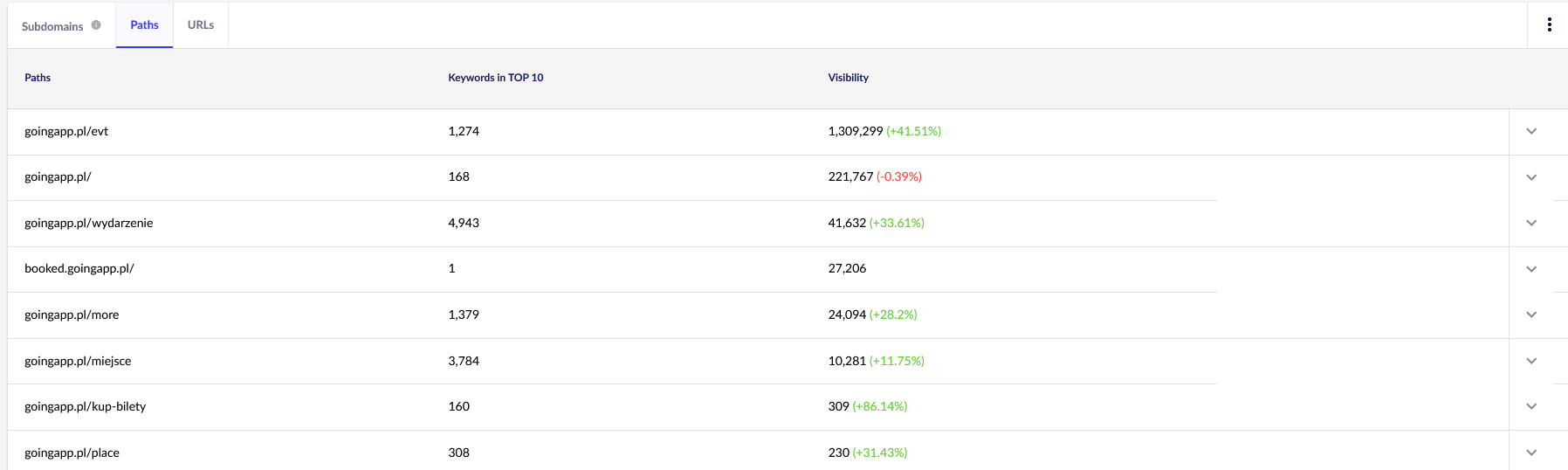
私たちの主な関心事は、2 番目のレポートです。 それを並べ替えて、キーワードの可視性 (当社の Web サイトが上位 10 位にランク付けされたキーワードのリストと総数) を調べてみましょう。 結果は、クロール バジェットの刺激 (および効率的な割り当て) の主軸を特定するのに役立ちます。
被リンク分析ツール (Ahrefs、Majestic)
ページの 1 つに大量のインバウンドリンクがある場合は、それをクロール バジェット最適化戦略の柱として使用します。 人気のあるページは、さらに勢いを増すハブの役割を担うことができます。 さらに、価値のあるリンクが豊富にある人気のあるページは、頻繁にクロールされる可能性が高くなります。
Ahrefs では、Pages レポートが必要です。正確には、「Best by links」というタイトルの部分です。
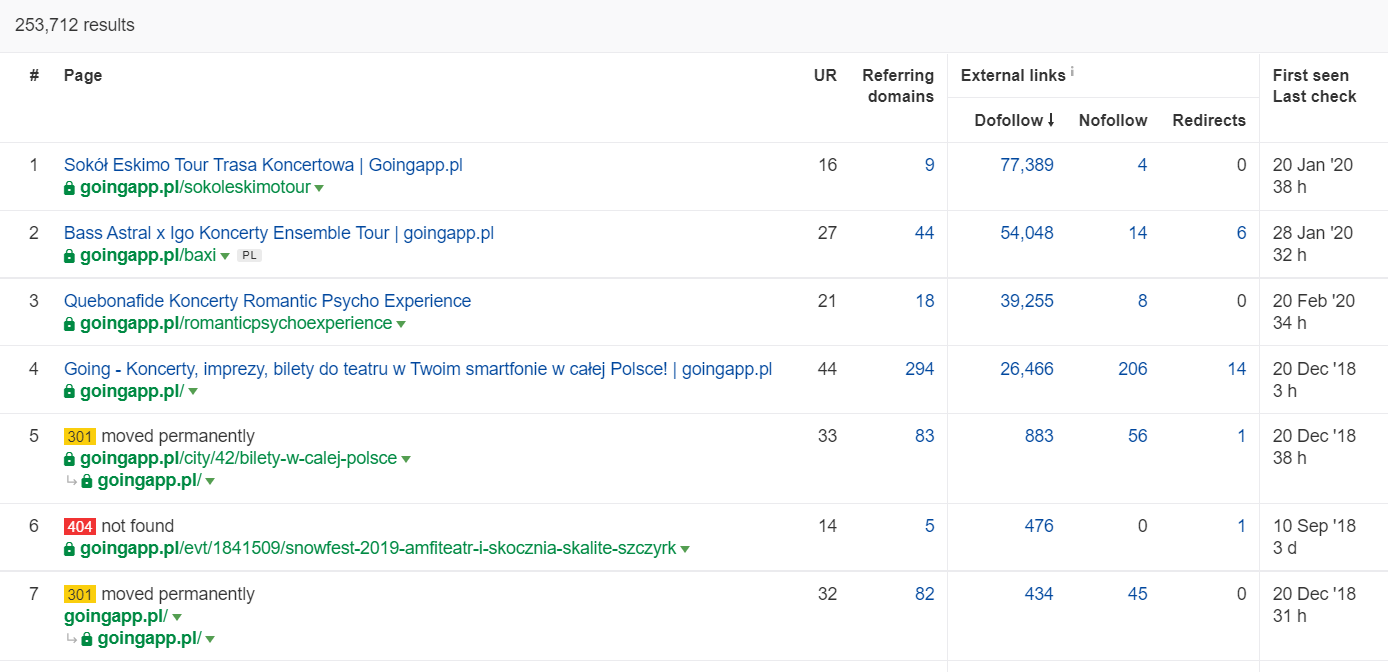
上記の例は、一部のコンサート関連の LP が引き続きバックリンクの堅実な統計を生成していることを示しています。 パンデミックのためにすべてのコンサートがキャンセルされたとしても、歴史的に強力なページを使用してクロール ボットの好奇心をそそり、そのジュースを Web サイトの隅々まで広めることは、依然として有効です。
クロール バジェットの問題を示す明確な兆候は何ですか?
問題のある (過度に低い) クロール バジェットに対処していることを認識するのは容易ではありません。 なんで? 主に、SEO は非常に複雑な企業であるためです。 低ランクやインデックスの問題は、平凡なリンク プロファイルや Web サイトに適切なコンテンツがないことの結果である可能性があります。
通常、クロール バジェットの診断には次のチェックが含まれます。
- Google Search Console からインデックス登録をリクエストしない場合、公開から新しいページ (ブログ投稿/製品) のインデックス登録までにどのくらいの時間がかかりますか?
- Google が無効な URL をインデックスに保持する期間はどれくらいですか? 重要: リダイレクトされたアドレスは例外です。Google は意図的にアドレスを保存します。
- 後でドロップするだけでインデックスに登録されるページがありますか?
- Google は、価値 (トラフィック) を生み出さないページにどれくらいの時間を費やしていますか? ログ分析に移動して確認してください。
クロール バジェットを分析して最適化する方法
クロール バジェットの最適化を行うかどうかは、主に Web サイトのサイズによって決まります。 一般に、ページ数が 1000 未満の Web サイトでは、利用可能なクロール制限を最大限に活用することに苦労するべきではないと Google は示唆しています。 私の本では、Web サイトに 300 以上のページが含まれていて、コンテンツが動的に変化している場合 (たとえば、新しいページやブログ投稿を追加し続ける場合) は、より効率的かつ効果的なクロールのために戦い始める必要があります。
なんで? それはSEOの衛生の問題です。 初期の段階で適切な最適化の習慣を実装し、適切なクロール バジェットを管理すれば、将来的に修正や再設計を行う必要が少なくなります。
クロール バジェットの最適化。 標準的な手順
一般に、クロー バジェットの分析と最適化の作業は、次の 3 つの段階で構成されます。
- ウェブマスターと外部ツールの両方から、ウェブサイトについて私たちが知っているすべてをコンパイルするプロセスであるデータ収集。
- 可視性分析と容易に達成できる成果の識別。 時計仕掛けのように動くのは何ですか? 何が良いでしょうか? 成長の可能性が最も高い分野は?
- クロール バジェットの推奨事項。
クロール バジェット監査のためのデータ収集
1. 市販のツールの 1 つを使用して Web サイト全体をクロールします。 目標は、少なくとも 2 回のクロールを完了することです。1 回目は Googlebot をシミュレートし、もう 1 回目はデフォルトのユーザー エージェント (ブラウザーのユーザー エージェント) として Web サイトを取得します。 この段階では、コンテンツを 100% ダウンロードすることにのみ関心があります。 クローラーがループに陥ったことに気付いた場合 (1 日クロールした後、まだハード ドライブに Web サイトの 10% しか残っていない場合)、問題があることを知らせ、クロールを停止できます。 大規模な Web サイトの場合、分析に適した URL の数は約 25 万から 30 万ページです。
a) 私たちが探しているのは、主に内部の 301 リダイレクト、404 エラーですが、テキストが内容の薄いコンテンツとして分類される可能性がある状況でもあります。 Screaming Frog には、ほぼ重複するコンテンツを検出するオプションがあります。
2. サーバーログ。 理想的な時間枠は先月にまたがる必要がありますが、大規模な Web サイトの場合は、最後の 2 週間で十分な場合があります。 最良のシナリオでは、過去のサーバー ログにアクセスして、すべてが順調に進んでいたときの Googlebot の動きを比較できるようにする必要があります。
3. Google Search Console からのデータ エクスポート。 上記のポイント 1 と 2 を組み合わせると、インデックス カバレッジとクロール統計のデータから、Web サイトでのすべての出来事を包括的に把握できます。
4. オーガニック トラフィック データ。 Google Search Console、Google アナリティクス、および Senuto と Ahrefs によって決定された上位ページ。 可視性の高い統計、トラフィック量、またはバックリンク数で群集の中で際立っているすべてのページを特定したいと考えています。 これらのページは、クロール バジェットの作業のバックボーンになる必要があります。 それらを使用して、最も重要なページのクロールを改善します。
5. 手動インデックス レビュー。 場合によっては、SEO エキスパートの親友が簡単な解決策になることもあります。 この場合: インデックスから直接取得したデータのレビュー! inurl: + site:演算子の組み合わせで Web サイトをチェックするのは良い呼び出しです。最後に、収集したすべてのデータをマージする必要があります。 通常、外部データのインポート (GSC データ、サーバー ログ、オーガニック トラフィック データ) を可能にする機能を備えた外部クローラーを使用します。
可視性分析と簡単な成果
このプロセスについては別の記事を書く必要がありますが、今日の目標は、Web サイトの目的と進捗状況を俯瞰することです。 突然のトラフィックの減少 (季節的な傾向では説明できない) と、有機的な可視性の同時変化など、異常なことすべてに関心があります。 Googlebot をウェブサイトの奥深くに押し込むためのハブになるため、どのグループのページが最も強力かを確認しています。
完璧な世界では、そのようなチェックは、当社のウェブサイトの立ち上げ以来の全履歴をカバーする必要があります. ただし、データ量は毎月増え続けるため、過去 12 か月間の可視性とオーガニック トラフィックの分析に焦点を当てましょう。
クロールの予算 – 推奨事項
上記のアクティビティは、最適化された Web サイトのサイズによって異なります。 ただし、これらはクロール バジェット分析を実行する際に常に考慮する最も重要な要素です。 最も重要な目標は、Web サイトのボトルネックを解消することです。 つまり、Googlebot (または他のインデックス作成エージェント) のクロール可能性を最大限に保証するためです。
1. 基本から始めましょう –あらゆる種類の 404/410 エラーの排除、内部リダイレクトの分析、内部リンクからのそれらの除去. 最終クロールでジョブを終了する必要があります。 今回は、すべてのリンクが 200 応答コードを返し、内部リダイレクトや 404 エラーは発生しません。
- この段階で、バックリンク レポートで検出されたすべてのリダイレクト チェーンを修正することをお勧めします。
2. クロール後、ウェブサイトの構造に明らかな重複がないことを確認します。
- カニバリゼーションの可能性もチェックしてください。複数のページで同じキーワードをターゲットにすることで発生する問題は別として (つまり、Google によってどのページが表示されるかを制御できなくなります)、カニバリゼーションはクロール バジェット全体に悪影響を及ぼします。
- 識別された重複を 1 つの URL (通常はランクの高い URL) に統合します。
3. noindex タグを持つ URL の数を確認します。 ご存じのとおり、Google は引き続きこれらのページ間を移動できます。 検索結果に表示されないだけです。 私たちは、ウェブサイト構造におけるnoindexタグのシェアを最小限に抑えようとしています。
- 適切な例 – ブログはその構造をタグで編成します。 著者は、解決策はユーザーの利便性によって決まると主張しています。 すべての投稿には 3 ~ 5 個のタグが付けられ、一貫して割り当てられておらず、インデックスも作成されていません。 ログ分析によると、これは Web サイトで 3 番目に多くクロールされた構造です。
4. robots.txtを確認します。 robots.txt を実装しても、Google のインデックスにアドレスが表示されなくなるわけではありません。
- ブロックされたアドレス構造のうち、まだクロールされているものを確認します。 多分それらを遮断することがボトルネックを引き起こしていますか?
- 古い/不要なディレクティブを削除します。
5. Web サイト上の非正規 URL の量を分析します。 Google はrel="canonical"をハード ディレクティブと見なしなくなりました。 多くの場合、属性は検索エンジンによって完全に無視されます (インデックス内のパラメーターの並べ替え – 依然として悪夢です)。
6. フィルターとその根底にあるメカニズムを分析します。 リストのフィルタリングは、クロール バジェットの最適化における最大の頭痛の種です。 e コマースのビジネス オーナーは、任意の組み合わせで適用可能なフィルターを実装することを主張します (たとえば、色 + 素材 + サイズ + 在庫状況によるフィルタリングなど)。 ソリューションは最適ではなく、最小限に制限する必要があります。
7. Web サイトの情報アーキテクチャ– ビジネス目標、トラフィックの可能性、および現在のリンク プロファイルを考慮したもの。 ビジネス目標にとって重要なコンテンツへのリンクは、サイト全体 (すべてのページ) またはホームページに表示される必要があると仮定してみましょう。 もちろん、ここでは単純化していますが、ホームページとトップメニュー/サイト全体のリンクは、内部リンクから価値を構築する上で最も強力な指標です. 同時に、最適なドメイン スプレッドを達成しようとしています。目標は、任意のページからクロールを開始し、同じ数のページに到達できる状況です (すべての URL に少なくとも 1 つの着信リンクが必要です)。 .
- 堅牢な情報アーキテクチャに向けて取り組むことは、クロール バジェットの最適化の重要な要素の 1 つです。 これにより、ボットのリソースの一部をある場所から解放し、別の場所にリダイレクトできます。 それはまた、ビジネス関係者の協力を必要とするため、最大の課題の 1 つでもあります。これは、SEO の推奨事項を弱体化させる大規模な戦いや批判につながることがよくあります。
8. コンテンツのレンダリング。 ユーザーの行動をキャプチャするレコメンダー システムに基づいて内部リンクを作成することを目的とする Web サイトの場合、これは重要です。 とりわけ、これらのツールのほとんどは Cookie ファイルに依存しています。 Google は Cookie を保存しないため、カスタマイズされた結果は得られません。 結果: Google は常に同じコンテンツを表示するか、まったくコンテンツを表示しません。
- Googlebot が重要な JS/CSS コンテンツにアクセスできないようにするのはよくある間違いです。 この移動により、ページのインデックス作成で問題が発生する可能性があります (また、利用できないコンテンツのレンダリングに Google の時間が浪費されます)。
9. ウェブサイトのパフォーマンス – コア ウェブ バイタル. CWV がサイトのランキングに与える影響については懐疑的ですが (市販のデバイスの多様性やインターネット接続の速度の違いなど、さまざまな理由から)、コーダーと議論する価値のあるパラメーターの 1 つです。
10. Sitemap.xml – 機能し、すべての主要な要素 (ステータス コード 200 を返す正規の URL のみ) が含まれているかどうかを確認します。
- sitemap.xml を最適化するための最初の推奨事項は、ページをタイプごと、または可能な場合はカテゴリごとに分割することです。 この部門により、Google の動きとコンテンツのインデックス作成を完全に制御できます。