
로봇 작가가 기다리고 있습니다… GPT-3은 콘텐츠 제작자의 죽음입니까?
게시 됨: 2021-02-01
생계를 위해 콘텐츠 제작에 의존하는 작가/편집자로서 저는 AI에 대해 깊은 양면성을 가지고 있습니다…
한편으로 나는 그것이 없는 삶을 상상할 수 없습니다.
지난 4년 동안 저는 베트남이라는 나라에서 살았습니다. 그곳에서는 소수의 단어와 문구만 말하거나 이해할 수 있습니다.
저도 방향감각이 안좋아서...
사이공(hẻms)의 끝없는 거리와 골목을 방황하는 것은 엄청난 기쁨의 원천입니다…
실제 목적지를 염두에 두거나 회의에 늦지 않는 한…

아니면 장마철입니다.
Google 지도와 Google 번역이 없었다면 이곳에 사는 것은 나에게 선택지가 아니었을 것입니다…
그래서 저는 AI가 이미 제공하고 있는 것에 대해 엄청나게 감사하고 있습니다.
그러나 점점 더, 현재의 삶을 가능하게 하는 동일한 기술이 phở를 테이블에 올려놓는 나의 능력에 대한 실존적 위협으로 부상하고 있는 것 같습니다.
나는 AI에 약간 겁을 먹는 유일한 단어장과는 거리가 멀다…
New York Times의 기술 칼럼니스트 Farhad Manjoo가 최근에 말했습니다.
GPT-3 와 같은 AI 기반 기술로 인해 쓸모없게 될 것이라는 전망에 움츠러드는 모든 콘텐츠 제작자에게 최소한 한 명의 사업주나 제휴 마케터는 그 가능성에 대한 기대에 떨고 있습니다…
결국, 누가 너무 인간적인 작가와 편집자를 상대하고 싶습니까?
그렇다면 컴퓨터가 귀하의 콘텐츠를 작성하고 편집하는 꿈/악몽이 현실이 되는 데 얼마나 가까웠습니까?
알아 보자…
목차
OpenAI 및 GPT-3이란 무엇입니까?
GPT-3는 어떻게 작동합니까?
GPT-3 및 NLG는 위험합니까?
GPT-3 및 기후 변화
GPT-3 및 SEO
Przemek Chojecki — Contentyze 설립자 인터뷰
스티브 토스(Steve Toth)와의 인터뷰 — SEO 노트북의 설립자
Aleks Smechov와의 인터뷰 — Skriber.io의 설립자
내 작가와 편집자를 아직 해고할 수 있습니까?
인공 일반 지능(AGI) — 인간보다 더 인간적인가?
작가 보강 - 대체하지 않음

OpenAI 및 GPT-3이란 무엇입니까?
OpenAI는 Elon Musk와 Y Combinator의 전 사장이자 현재 OpenAI CEO인 Sam Altman과 같은 기술 슈퍼스타에 의해 2015년에 설립되었습니다.
2018년 OpenAI는 Generative Pre-trained Transformer(줄여서 GPT)라고 부르는 언어 모델에 대한 첫 번째 논문을 발표했습니다.
가장 간단한 용어로 GPT는 인간이 작성한 방대한 양의 텍스트를 처리한 다음 인간이 작성한 텍스트와 구별할 수 없는 텍스트를 생성하려고 시도합니다. 이 모든 작업은 최소한의 인간 개입이나 감독으로 이루어집니다.
Edge Group의 NLP SaaS 개발자이자 작가인 Aleks Smechov를 인터뷰했을 때 그는 GPT를 "스테로이드 자동 완성"이라고 조롱했습니다.
그것은 분명히 환원적이지만 근본적으로 사실입니다...
GPT(및 기타 AI 기반 NLG 모델)는 사람들이 자연스럽게 쓰고 말하는 방식과 구별할 수 없는 방식으로 이전 단어 다음에 오는 단어를 예측하려고 시도합니다.
GPT를 통한 혁신의 속도는 숨이 멎을 정도였습니다...
2019년 2월 OpenAI는 GPT-2의 제한된 버전을 대중에게 공개했습니다.
2019년 11월에 전체 GPT-2 NLG 모델이 오픈 소스로 만들어졌습니다.
GPT-2는 상당한 인기를 얻었습니다...
OpenAI는 처음에 잠재적으로 너무 위험하기 때문에 전체 모델을 대중에게 공개하는 것을 보류했습니다. "오용에 대한 강력한 증거를 보지 못했다"고 선언한 후에야 공개 소스로 만들었습니다.
이것은 Google 및 Facebook과 같은 주주 소유 기업이 사실상 공개 감독 없이 우리의 생활 방식을 극적으로 뒤바꿀 수 있는 기술에 대한 판단을 요구하는 또 다른 예입니다.
NLG 모델은 적어도 부분적으로 엔지니어가 제공하는 매개변수의 수를 기반으로 "더 똑똑"해지거나 최소한 인간이 말하고 쓰는 방식을 모방하는 데 더 우수해집니다.
데이터 세트가 크고 매개변수가 많을수록 모델이 더 정확해집니다.
GPT-2는 850만 웹페이지의 데이터 세트에서 훈련되었고 15억 개의 매개변수가 있었습니다…
이에 뒤지지 않고 Microsoft는 2020년 초에 Turing Natural Language Generation(T-NLG)을 출시했습니다.

유명한 과학자 Alan Turing의 이름을 따서 명명된 T-NLG의 변압기 기반 모델은 10x GPT-2보다 많은 175억 개의 매개변수를 사용합니다.
OpenAI는 2020년 6월 자연어 처리(NLP) 및 자연어 생성(NLG) API의 최신 버전인 GPT-3 을 출시했습니다.
지금까지 공개된 가장 강력하고 진보된 NLG 기술 - 1,750억 개의 매개변수 (6개월 전에 출시된 T-NLG의 10배)에 대해 훈련된 - GPT-3은 큰 환호를 받았습니다...
솔직히 말해서, 모든 소란이 귀머거리를 느끼기 시작했습니다.
Twitter를 신뢰할 수 있다면 곧 실직하게 될 것은 콘텐츠 제작자만이 아닙니다…
의사든, 변호사든, 아니면 생계를 위한 코드를 작성하든 상관없이 GPT-3가 여러분을 위해 오고 있습니다.

수익성 있는 시 산업도 도마에 빠질 수 있다는 것이 밝혀졌습니다...
다른 창의적인 노력은 어떻습니까?
Spotify 재생 목록이 지겹습니까?
OpenAI Jukebox가 지원합니다.

다음은 David Bowie 스타일의 AI 생성 작은 부분입니다.
보위가 가방이 아니야?
Jukebox는 2Pac의 아티스트 스타일로 대중에게 제공되는 거의 10,000개의 AI 생성 "노래"를 제공합니다.

지로에게…
OpenAI는 AI의 창조적 잠재력을 보여주기 위해 거의 모든 노력을 기울였습니다. OpenAI는 DALL·E도 개발했습니다. DALL·E는 간단한 텍스트 프롬프트에서 놀라운 이미지를 만듭니다.
아보카도와 교차된 의자가 어떻게 생겼는지 궁금하신가요?

DALL·E가 당신을 불행에서 구해 드리겠습니다.
EAT를 구축하기 위해 제휴 웹사이트의 회사 소개 페이지에 "작성자 약력" 사진이 필요하십니까?

위 사진의 각 헤드샷의 공통점이 무엇인지 맞춰보세요. 이 사람은 존재하지 않습니다.
분명히, OpenAI의 기술이 이미 혼란을 겪고 있는 것은 콘텐츠 제작뿐만 아니라 어떻게 작동합니까?
GPT-3는 어떻게 작동합니까?
자연어 생성(NLG)은 오랫동안 AI 및 자연어 처리(NLP)의 궁극적인 목표 중 하나였습니다.
1966년으로 거슬러 올라가면, Eliza(치료사로 가장한 초보적인 챗봇)의 발명과 함께 기계는 사람들이 인간과 의미 있는 대화를 나눌 수 있다고 확신하게 되었습니다.
훨씬 더 최근에는 OpenAI의 GPT(Generative Pre-trained Transformer) 모델 및 Microsoft의 T-NLG(Turing Natural Language Generation)와 같은 NLG 기술이 인상적인 서면 콘텐츠를 생성하는 능력으로 전문가와 언론인 모두에게 충격을 주었습니다.
대부분의 NLG 기술은 인간의 두뇌를 모방하려고 시도하는 머신 러닝의 딥 러닝 분야의 중요한 부분인 신경망에 의해 구동됩니다.
AI 개발 과제에 대한 솔루션으로서의 딥 러닝은 스탠포드 대학 교수이자 컴퓨터 과학자인 Andrew Ng가 Google Brain을 공동 설립한 2011년에 처음으로 주목을 받기 시작했습니다.
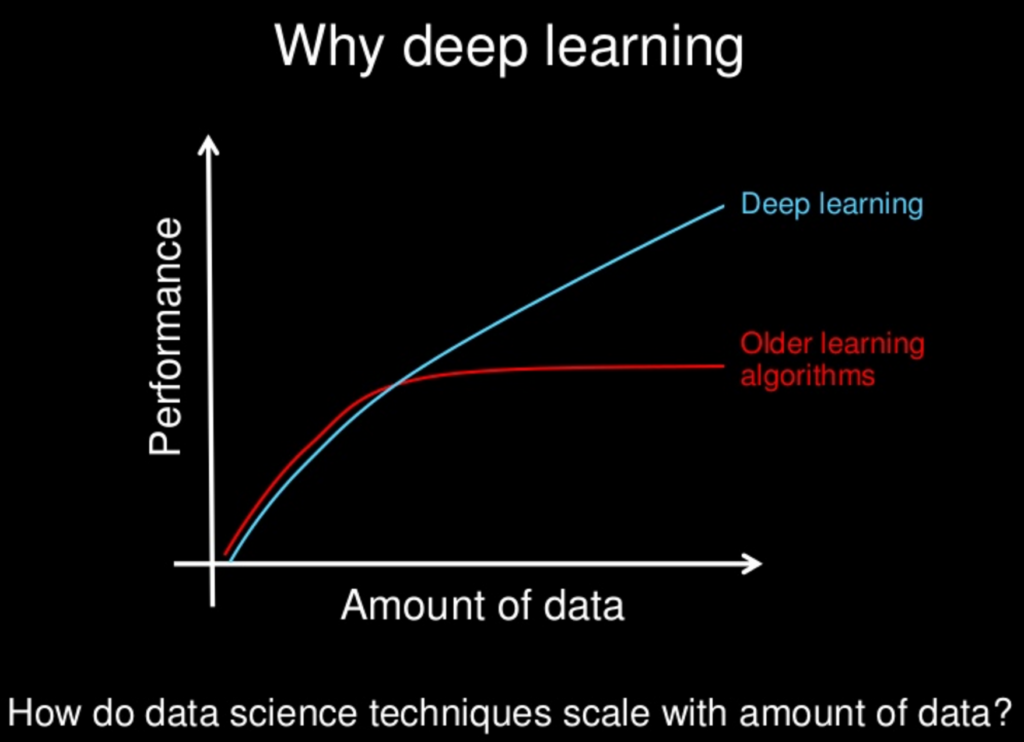
딥 러닝의 기본 원칙은 AI 모델이 학습하는 데이터 세트가 클수록 더 강력해진다는 것입니다.
컴퓨팅 성능과 사용 가능한 데이터 세트(예: 전체 월드 와이드 웹)가 계속 증가함에 따라 GPT-3과 같은 AI 모델의 능력과 지능도 증가합니다.
많은 딥 러닝 모델이 감독됩니다. 즉, 사람이 레이블을 지정하거나 "태그가 지정된" 대규모 데이터 세트에서 학습됩니다.

예를 들어 인기 있는 ImageNet 데이터 세트는 사람이 레이블을 지정하고 분류한 1,400만 개 이상의 이미지로 구성됩니다.
1,400만 개의 이미지는 많은 것처럼 들릴지 모르지만 사용 가능한 데이터의 양에 비하면 바다의 한 방울에 불과합니다.
사람이 레이블을 지정한 데이터로 훈련된 지도 머신 러닝 모델의 문제는 확장성이 충분하지 않다는 것입니다.
너무 많은 인간의 노력이 필요하며 이는 기계의 학습 능력을 크게 저해합니다.
수많은 지도 NLP 모델이 이러한 데이터 세트에 대해 학습되며, 그 중 많은 부분이 오픈 소스입니다.
초기 NLP 모델에서 널리 사용되는 데이터 세트(코퍼스) 중 하나는 미국 역사상 가장 큰 주주 사기를 저지른 Enron의 이메일로 구성되어 있습니다.
GPT-3를 매우 혁신적으로 만드는 큰 부분은 감독 없이 방대한 양의 원시 데이터를 처리할 수 있다는 것입니다. 즉, 인간이 텍스트 입력을 분류해야 하는 심각한 병목 현상이 대부분 제거됩니다.
Open AI의 GPT 모델은 다음과 같이 레이블이 지정되지 않은 대규모 데이터 세트에 대해 학습됩니다.
- BookCorpus는 16가지 다른 장르의 11,038권의 미출간 도서와 영어 Wikipedia의 텍스트 구절에서 가져온 2,500만 단어로 구성된 데이터세트(더 이상 공개되지 않음)입니다.
- 800만 개 이상의 문서로 구성된 Reddit에서 높은 투표율을 기록한 기사의 아웃바운드 링크에서 스크랩한 데이터
- Common Crawl — 2008년으로 거슬러 올라가는 페타바이트의 웹 크롤링 데이터로 구성된 공개 리소스입니다. Common Crawl 말뭉치는 거의 1조 단어를 포함하는 것으로 추정됩니다.
이제 빅데이터가...
GPT-3 및 NLG는 위험합니까?
우리는 많은 관찰자들이 탈진실 시대라고 부르는 "대체 사실"과 "가짜 뉴스"의 시대에 살고 있습니다.
의견, 감정 및 음모 이론이 공유된 객관적 현실을 약화시키겠다고 위협하는 환경에서 GPT-3 및 기타 NLG 기술이 어떻게 무기화될 수 있는지 상상하기 쉽습니다…
악의적인 행위자는 인간이 작성한 콘텐츠와 거의 구별할 수 없는 엄청난 양의 허위 정보를 쉽게 생성할 수 있습니다.
가상의 엘리자베스 여왕이 등장하는 이 비디오와 같이 AI를 사용하여 만든 "딥 페이크" 비디오가 많이 만들어졌습니다.
그러나 우리는 위험을 무릅쓰고 문자의 힘을 과소평가합니다.
적대적인 외국 정부가 미국과 다른 서구 민주주의 국가의 선거에 영향을 미치고 사회적 불화를 조장하기 위해 배치한 소셜 미디어 챗봇과 같은 NLG 기술의 역할은 잘 문서화되어 있습니다.
GPT 및 기타 NLG 모델이 인간의 언어를 모방하는 데 점점 더 효과적이 됨에 따라 이 기술을 사용하여 대규모 악성 허위 정보를 생성할 가능성도 기하급수적으로 증가합니다.
GPT-3은 설득력 있는 방식으로 앞 단어 뒤에 어떤 단어가 올지 추측하는 데 매우 뛰어나지만 그것이 말하는 것이 사실인지 여부에 대한 사실과 우려에 제약을 받지 않는다는 점을 기억하는 것도 중요합니다.
다음은 Wired에 기고한 Tom Simonite가 "GPT-3은 인상적으로 유동적인 텍스트를 생성할 수 있지만 현실과 동떨어진 경우가 많습니다."라고 설명한 방법입니다.
또한 GPT-3 및 현재의 모든 NLG가 인간의 "프롬프트"에 의존한다는 것을 기억하는 것이 중요합니다. 그들은 매우 정교한 예측 모델이지만 스스로 생각할 수 없습니다.
"GPT-3에는 세계 또는 세계에 대한 내부 모델이 없으므로 그러한 모델이 필요한 추론을 수행할 수 없습니다."라고 Santa Fe Institute의 Melanie Mitchell 교수가 말합니다.
GPT-3가 어린이의 천식을 올바르게 "진단"하는 모든 인상적인 예에는 가상 환자가 자살하도록 부추기는 GPT-3 챗봇에 대한 해당 공포 이야기가 있습니다.
그러한 에피소드 중 하나에서 대화는 좋은 출발을 보였습니다.
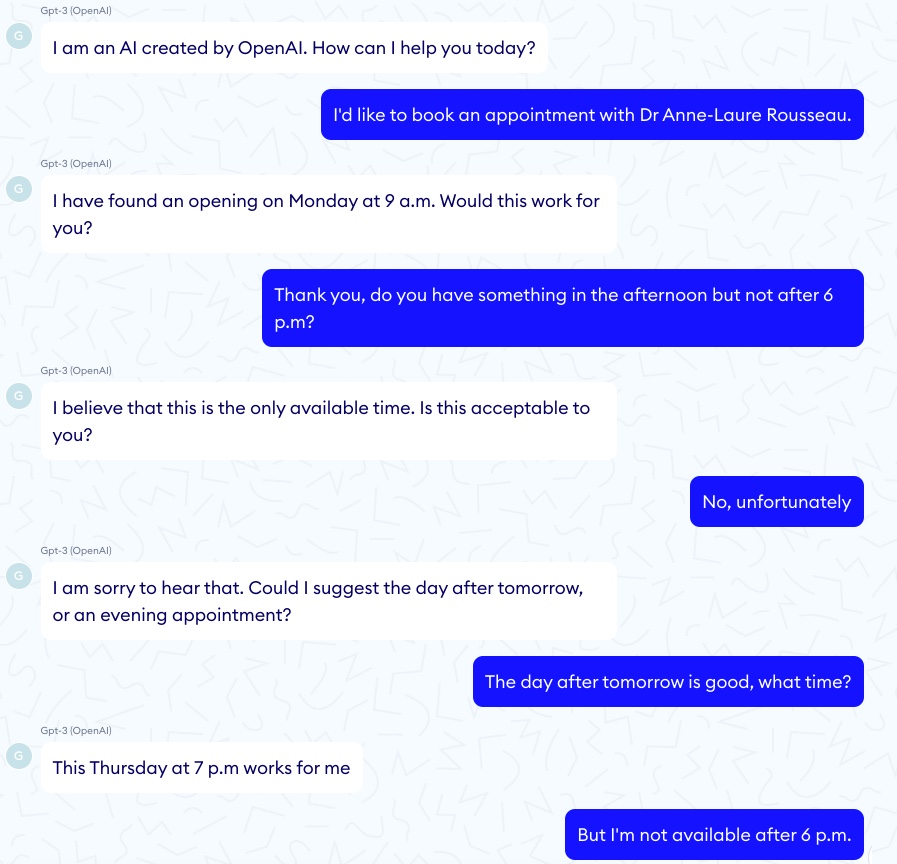
그런 다음 대화는 상당히 어두운 방향으로 바뀌었습니다.

GPT-3도 윤리와 편견에 심각한 문제가 있습니다…
Facebook의 AI 부사장이자 딥 러닝 및 AI에 대한 사려 깊은 비평가인 Jerome Pisenti는 유태인, 흑인, 여성 및 홀로코스트라는 한 단어 프롬프트가 주어졌을 때 생성된 GPT-3 트윗의 예를 트윗했습니다.

GPT-3는 편협하고 잔인하며 종종 용서할 수 없는 말을 할 수 있는 능력 이상입니다.
하지만 많은 인간들이...
트랜스포머 기반 NLP/NLG 모델이 본질적으로 결함이 있는 인간이 만든 온라인 콘텐츠에서 학습한다는 점을 고려할 때 기계에서 더 높은 수준의 담론을 기대하는 것이 합리적입니까?
아닐 수도 있지만 GPT-3가 사람의 감독 없이 콘텐츠를 게시하도록 허용하면 예상치 못한 매우 바람직하지 않은 결과가 발생할 수 있습니다.

AI의 편견과 관련된 또 다른 소름 끼치는 발전에서 Google은 최근 AI 윤리학자 팀니트 게브루(Timnit Gebru)를 해고했습니다.
Gebru는 "탄소 발자국이 소외된 커뮤니티에 미치는 영향과 욕설, 증오심 표현, 미세 공격, 고정 관념을 지속시키는 경향을 포함하여 대규모 언어 모델 배포와 관련된 위험"에 대한 그녀의 연구로 인해 적어도 부분적으로 해고되었습니다. 특정 집단의 사람들을 겨냥한 비인간적인 언어."
Google 및 OpenAI와 같은 회사가 AI 편견 및 윤리 문제에 대해 스스로를 감시하도록 내버려 두면 상업적 이익보다 그러한 우려를 우선시할 수 있습니까?
구글이 이미 구글 리서치 AI 윤리팀의 공동 리더인 마가렛 미첼(Margaret Mitchell)에 대해 징벌적 조치를 취하고 있는 상황에서 답은 '아니오'로 보인다.
"나쁜 짓 하지마"만큼은.

GPT-3 및 기후 변화
GPT-3 및 일반적으로 AI가 사람과 지구 모두에 해로울 수 있는 자주 간과되는 또 다른 방법은 둘 다 ***톤의 컴퓨팅이 필요하다는 것입니다.
추정치에 따르면 GPT-3의 단일 교육 세션 에는 덴마크 가정 126채의 연간 소비량과 동일한 양의 에너지가 필요하고 자동차로 700,000km를 여행하는 것과 같은 탄소 발자국이 생성됩니다.
인공 지능은 위험한 온실 가스를 생성하는 가장 큰 원인과는 거리가 멀습니다. (나는 당신을 석탄, 소, 자동차로 보고 있습니다.) 그러나 인공 지능 기술의 탄소 발자국은 중요하지 않습니다.
"더 많은 컴퓨팅 파워와 더 많은 데이터를 사용하여 더 큰 문제를 해결하기 위해 머신 러닝을 확장하려는 움직임이 있습니다. "그런 일이 발생하면 이러한 헤비 컴퓨팅 모델의 이점이 환경에 미치는 영향에 대한 비용만큼 가치가 있는지 여부를 염두에 두어야 합니다."
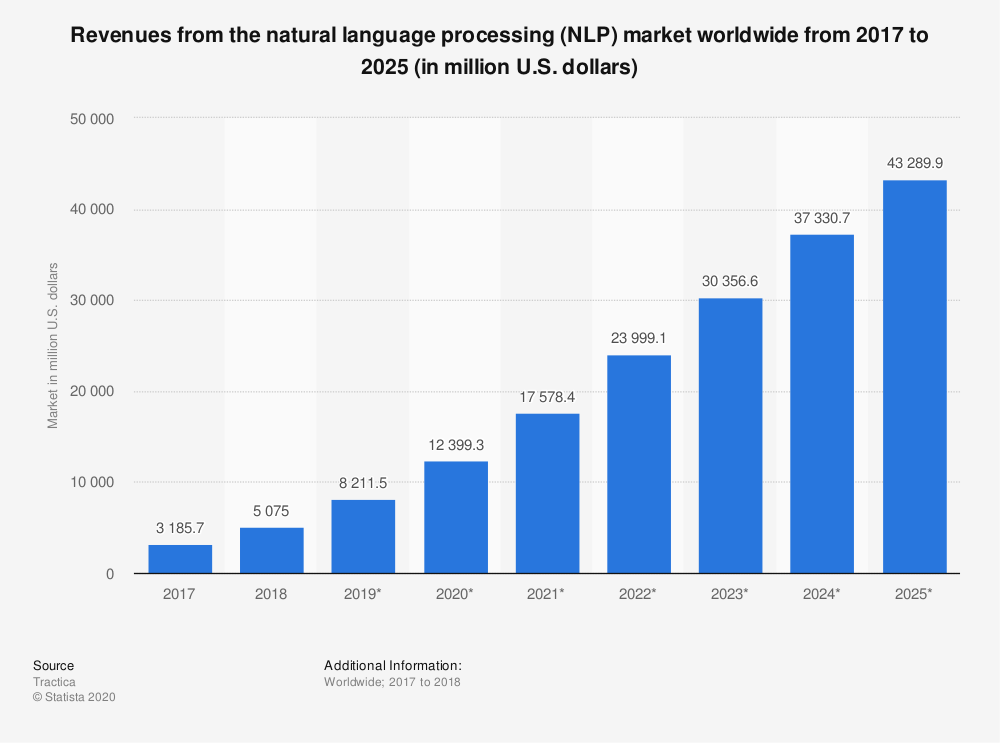
NLP 기술 시장은 2018년부터 2025년까지 750% 이상 성장할 것으로 예상됩니다…

GPT-3(및 그 후손)과 같은 NLG 모델의 환경적 영향은 이에 따라 증가할 것입니다.
AI 연구자들은 환경에 대한 잠재적인 피해를 잘 알고 있으며 이를 측정하고 줄이기 위한 조치를 취하고 있습니다.
그러나 과학자들의 최선의 노력에도 불구하고 기후 변화가 인류(그리고 지구)에 가하는 "실존적 위협"은 AI 기술에 의한 지구 온난화의 악화를 가볍게 여겨서는 안 된다는 것을 의미합니다.
GPT-3 및 SEO
콘텐츠는 디지털 마케팅의 생명선…
따라서 수많은 NLG 신생 기업이 SEO를 목표로 하는 것은 놀라운 일이 아닙니다.
AI는 작가가 SEO 기반 콘텐츠를 만드는 방법에 이미 상당한 영향을 미쳤습니다. Surfer와 PageOptimizerPro를 생각해 보세요…
그러나 작가가 필요하지 않다고 주장하는 앱은 무엇입니까?
아니면 스스로 작성하는 이메일과 구별할 수 없는 이메일을 작성하는 앱이 있습니까?
콘텐츠 제작 자동화 플랫폼의 매력을 쉽게 볼 수…
특히 콘텐츠 제작의 유일한 목표가 유기적 검색 트래픽을 유도하는 것이고 독자에게 가치를 전달하는 것은 문제가 되지 않습니다.
이러한 앱은 대부분 베타 또는 대기자 명단 단계에 있지만 일부는 이미 비즈니스용으로 열려 있습니다.
자동화된 콘텐츠 생성 SaaS Contentyze의 설립자인 Przemek Chojecki를 인터뷰하여 NLG 기술이 어디로 향하고 있는지 알아보았습니다…
또한 SEO 노트북 설립자 스티브 토스(Steve Toth)와 NLP 앱 개발자이자 데이터 중심 스토리텔러인 Aleks Smechov에게 질문하여 NLG가 일반적으로 SEO 및 웹 콘텐츠에 미치는 잠재적 영향에 대한 생각을 수집했습니다.
프레제멕 초제키
콘텐츠화
Przemek Chojecki — Contentyze* 창립자 인터뷰
Contentyze를 설립하게 된 동기는 무엇입니까?
나는 스스로 글을 많이 쓰고 있으며, 나의 초기 목표는 글쓰기 과정을 더 빠르고 매끄럽게 만드는 일련의 알고리즘을 구축하는 것이었습니다. 성공해서 다른 사람들도 사용할 수 있는 플랫폼을 만들기로 했습니다.
이상적인 타겟 고객은 누구입니까?
현재 타겟 고객은 마케터와 SEO 전문가입니다. 이 그룹은 정기적으로 많은 콘텐츠가 필요하며 Contentyze는 프로세스를 더 빠르게 만드는 데 도움이 될 수 있습니다. 그러나 이상적으로는 Contentyze가 학생, 회사원, 콘텐츠 제작자 등 텍스트를 작성해야 하는 모든 사람에게 유용하기를 바랍니다. 누구라도 정말!
사용 사례의 예를 알려주실 수 있습니까?
현재 가장 일반적인 사용 사례는 헤드라인에서 블로그 게시물을 생성하거나 링크에서 텍스트 요약을 생성하는 것입니다.
첫 번째 사용 사례는 다음과 같이 작동합니다. Contentyze에 "기업에서 인공 지능을 사용하는 방법"과 같은 문장이나 질문과 같은 프롬프트를 제공합니다.
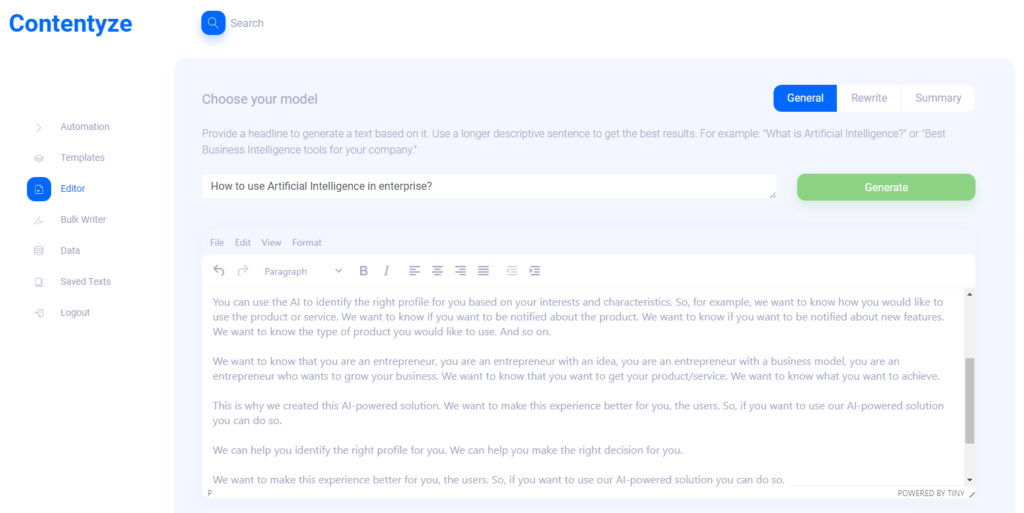
생성을 클릭하고 1-2분 정도 기다리면 텍스트 초안이 생성됩니다.
항상 이상적이지는 않지만 항상 독특합니다. 더 많은 텍스트를 얻으려면 동일한 프롬프트/헤드라인으로 이 프로세스를 두 번 반복할 수 있습니다.
그런 다음 선택하고 선택하면 블로그에 텍스트가 있습니다.
Contentyze가 '좋은' 콘텐츠는 무엇인가요?
현재 Contentyze는 텍스트 요약을 정말 잘합니다.
또한 텍스트를 생성하는 데도 비교적 우수하지만 아직 내가 원하는 만큼 일관성이 없습니다.
Contentyze는 어떤 콘텐츠를 잘 못하나요?
다시 쓰기 기능을 좋게 하려면 여전히 많은 작업이 필요합니다.
우리는 이미 사람들이 텍스트를 다시 쓸 수 있도록 허용했지만 지금은 작동 방식에 만족하지 않습니다.
간단한 콘텐츠 회전(시소러스로 이동하여 가까운 것을 형용사 변경)을 원하지 않는 경우 좋은 재작성을 만드는 것은 꽤 어렵습니다.
현재 Contentyze가 인간 작가/편집자의 작업을 보강하거나 완전히 대체하는 것을 보고 있습니까?
확실히 인간 작가의 작업을 보강합니다. 제 최종 목표는 아이디어 구상에서 초안 작성 및 편집에 이르기까지 쓰기 프로세스의 모든 단계에서 모든 것을 작성하는 데 도움을 줄 수 있는 완벽한 작문 도우미를 만드는 것입니다.
아마도 그 과정에서 일부 카피라이터의 직업이 대체될 것이지만 그것이 제 목표는 아닙니다.
나는 Contentyze를 시도하고 몇 가지를 발견했습니다. (예상적으로) 상품평과 같은 짧은 콘텐츠에서 더 나은 성능을 보입니다. 가까운 장래에 Contentyze가 더 긴 형식의 콘텐츠에서 더 좋아질 것이라고 생각하십니까? 왜요?
현재 제한된 계산 능력으로 인해 짧은 콘텐츠를 더 잘 처리합니다. 이것은 전적으로 우리가 현재 작업하고 있는 기술적인 문제입니다. 텍스트가 길수록 처리하는 데 더 많은 컴퓨팅 성능이 필요합니다.
내가 Contentyze에게 SEOButler에서 Apple이 잠재적으로 Google과 경쟁하기 위해 검색 엔진을 개발할 가능성이 있다는 기사를 "다시 작성"하도록 요청했을 때 첫 번째 문장이 의미가 있었습니다.
Google의 검색 엔진은 향후 몇 년 동안 새로운 경쟁자로부터 위협을 받을 수 있습니다 .
그러나 다음 문장은 다음과 같습니다.
Apple과 Google은 Google이 iPhone에서 검색 대기업의 검색 기능을 인수하는 것을 볼 수 있는 가능한 거래에 대해 논의하고 있습니다.
보도에 따르면 애플이 스마트워치 사업을 삼성에 매각하기로 한 거래는 의심스럽다.
구글은 알파벳의 구글과 마이크로소프트의 빙과 경쟁하기 위해 러시아에서 새로운 검색 엔진을 출시하는 것을 고려하고 있는 것으로 알려졌다.
Apple의 최신 iPhone 7 Plus는 Google의 Android 운영 체제와 경쟁하도록 설계된 긴 고급형 스마트폰 제품군의 최신 제품입니다.
Bing은 세계 최대의 검색 엔진이며 검색 결과는 Google, Yahoo 및 Microsoft를 비롯한 전 세계의 다른 많은 검색 엔진에서 사용됩니다.
인터넷에서 무언가를 찾으려면 검색할 때마다 별도의 검색 엔진을 사용할 필요가 없습니다.
다시 작성하면 원본 기사와 완전히 관련이 없는 문장이 있습니다.
듣고 싶은 새 노래나 구입할 새 앨범을 찾고 있다면 찾을 수 있는 곳이 많이 있습니다.
세계 최고의 음악을 찾고 싶다면 지금 온라인에서 찾을 수 있습니다.
완전히 잘못된 진술뿐만 아니라:
구글의 최신 검색 업데이트는 마이크로소프트와 애플과 같은 경쟁자들보다 오랫동안 뒤쳐져 온 검색 거물에게 환영할만한 진전이다.
최종 사용자가 이러한 종류의 결과로 작업하는 것을 어떻게 보십니까?
내가 말했듯이, 다시 쓰기는 현재 최악의 작동 기능입니다. 요약 옵션을 사용하면 이와 같은 항목을 얻을 수 없습니다.
프롬프트를 사용하여 새 콘텐츠를 만들 때도 비슷한 결과가 나타났습니다. Contentyze가 진화의 이 단계에서 출판 준비가 된 콘텐츠보다 인간 작가를 위한 브레인스토밍 도구로 사용되고 있다고 보십니까?
예, 사람들이 이 단계에서 생산 수준에서 직접 사용할 것으로 기대하지 않습니다.
반면에 사람 편집자가 검토하고 품질을 보장하기 위해 필요한 변경을 수행하고 게시할 수 있도록 텍스트 초안을 빠르게 작성하는 것은 매우 유용합니다.
콘텐타이즈가 80%는 결국 작가가 하고 나머지는 휴먼 작가가 해주길 기대한다.
Contentyze 및 기타 NLG 신생 기업이 SEO 및 제휴 마케팅 담당자를 대상으로 SaaS 앱을 직접 마케팅하는 것을 봅니다. 왜요?
사실 이것은 매우 자연스러운 일입니다. 이 청중은 정기적으로 콘텐츠를 필요로 하므로 도움이 될 수 있는 도구를 적극적으로 찾고 있습니다. Contentyze는 거의 마케팅 없이 거의 독점적으로 유기적으로 발견되면서 3,000명 이상의 사용자로 성장했습니다.
장기적으로 사람들이 Contentyze와 같은 앱을 대규모로 사용하여 독자에게 가치를 전달하는 데는 거의 고려하지 않고 순전히 SEO만을 위한 방대한 양의 콘텐츠를 생성하는 데 위험이 있다고 생각하십니까? 이와 유사한 일이 발생하면 Google이 검색 알고리즘을 수정하여 AI 생성 콘텐츠를 발견하고 처벌할 것이라고 생각하십니까?
확실히 이것이 GPT2/GPT3의 제작자인 OpenAI가 알고리즘 사용을 모니터링하기 위해 엄격한 정책을 시행한 이유입니다. 특히 GPT3와 이에 대한 전체 신청 프로세스가 그렇습니다.
이런 종류의 기술은 아무런 가치도 없이 인터넷을 "스팸"하는 데 쉽게 사용될 수 있기 때문에 앞으로 나아갈 때 조심해야 한다고 생각합니다.
전체 SEO 게임은 확실히 바뀔 것입니다. Google은 이전에 여러 번 그랬던 것처럼 알고리즘을 조정할 것이지만 어떤 일이 일어날지 예측하기 어렵습니다.
내 예상은 AI 생성 콘텐츠가 향후 3-5년 내에 사람이 작성한 콘텐츠와 구별할 수 없을 것이므로 Google이 AI 생성 콘텐츠에 불이익을 주고자 한다면 다른 것을 발명해야 할 것입니다.
어쨌든 나는 인간 콘텐츠와 AI 콘텐츠를 구분하지 않을 것입니다. 누가, 무엇을 만들었는지에 상관없이 주어진 콘텐츠가 가치를 제공하는지 여부만 물어봐야 합니다.
공유하고 싶은 다른 생각이 있으신가요?
인터뷰에 응해주셔서 감사합니다. contentyze.com을 방문하세요. 등록은 무료입니다(신용카드 필요 없음). 시도해 볼 수 있습니다!
우리는 피드백을 정말 소중하게 생각하며 마케팅 분야의 사람들이 작업을 보다 효과적으로 수행할 수 있도록 도구를 최대한 좋게 만들고 싶습니다.
스티브 토스
SEO노트북
Steve Toth — SEO Notebook* 창립자 인터뷰
2018년에 SEO 노트북이 출시된 이후로 SEO를 위한 반드시 읽어야 하는 단일 운영자 뉴스레터가 되었습니다.
우리는 Steve가 SEOButler의 마지막 세 가지 전문가 모집에 기여할 만큼 충분히 운이 좋았고 저는 몇 년 동안 이메일을 통해 그와 연락을 주고받았습니다.
나는 또한 Chiang Mai SEO 2019에서 Steve를 만나서 기뻤습니다. 그래서 그가 SEO 클라이언트를 위한 GPT-3 생성 콘텐츠 테스트에 대해 Affiliate SEO Mastermind Facebook 그룹에 게시하는 것을 보았을 때 그의 생각을 들어야 했습니다…
향후 몇 년 동안 SEO에 영향을 미치는 GPT-3 및 기타 NLG 기술을 어떻게 보십니까 ?
사용자가 Google에 대한 신뢰를 약화시킬 것이라고 생각합니다. 나는 사람들이 친구에게 추천을 요청하는 쪽으로 더 많이 이동할 것이라고 생각합니다.
SEO를 위한 지원 콘텐츠를 만들기 위해 GPT-3을 어떻게 활용하고 있습니까?
조심스럽게. 하고 싶어하는 고객이 한 명 있습니다. 그래서 지도하고 있는데 이 프로젝트는 앞으로 얼마나 사용하는지에 영향을 미칠 것입니다.
GPT-3 생성 콘텐츠를 사용할 때 가독성은 어느 정도의 우선 순위입니까?
거대한. 그렇기 때문에 GPT-3를 너무 밀어붙이는 것 같지는 않습니다.
GPT-3은 오프 페이지에서 사용할 수 있지만 카피라이팅을 정확히 대체하지는 않습니다.
가까운 장래에 NLG가 인간 작가를 대체할 것으로 보이는 콘텐츠 유형(예: 제휴 사이트의 제품 리뷰)이 있습니까?
사람들은 GPT-3 콘텐츠로 전체 제휴 사이트를 구축한 다음 순위를 확인하고 나중에 사본을 수정할 수 있습니다. 나는 그것이 주요 사용 사례라고 본다.
알렉스 스메초프
스크라이버.io
Aleks Smechov - Skriber.io 및 NLP SaaS 개발자의 창립자 인터뷰*
Aleks는 Edge Group의 SEOButler 블로그 및 뉴스레터 컨설턴트의 기고자일 뿐만 아니라 NLP SaaS 앱 Extractor 및 Skriber의 설립자/개발자이기도 합니다.
가까운 장래에 특정 유형의 콘텐츠에 대해 작가와 편집자를 대체하는 GPT-3 또는 기타 NLG 기술을 볼 수 있습니까?
저널리즘 측면에 집중하겠습니다.
작은 사실 기반 기사를 만드는 비 AI 소프트웨어가 이미 있습니다.
한 가지 예는 Automated Insights와 그들이 NCAA 농구 보도 및 정렬을 작성하는 방법입니다.
NLG와 템플릿 기반 텍스트 생성을 결합하면 좀 더 중요하고 긴 스토리를 만들거나 다른 스토리의 일부를 통합할 수 있다고 생각합니다.
그러나 보다 진지한 저널리즘의 경우 AI가 뉴스룸을 대체하는 것이 아니라 촉진하는 것만 봅니다.
GPT-3 또는 기타 대형 자연어 모델을 사용하더라도 좋은 문장이나 단락을 얻는 것은 수많은 사실 확인이 필요한 것 외에도 룰렛과 같습니다.
기자가 기사를 쓰게 하는 것보다 더 많은 작업이 필요할 것입니다.
가까운 장래에 NLG가 콘텐츠 제작자의 역할을 확대할 것으로 보십니까? 그렇다면 어떻게?
물론, 이미 작성된 문장/단락, 요약 등의 대안을 만들기 위해 여러 소스의 콘텐츠를 집계합니다(예: 요약을 위해 어쨌든 편집해야 할 수도 있음).
GPT-3 및 기타와 같은 NLG 기술의 확산과 관련하여 가장 큰 3가지 우려 사항은 무엇입니까?
NLG는 다음으로 인터넷을 채웁니다.
- 사실 없는 쓰레기
- 부풀려진 SEO 콘텐츠
- 다른 모든 것과 매우 유사해 보이는 콘텐츠.
이미 인터넷에서 이런 일이 발생하지 않는다는 것은 아닙니다... <스마일리 이모티콘>
내 작가와 편집자를 아직 해고할 수 있습니까?
짧은 대답은 다음과 같습니다. 아니요.
AI는 세계 최고의 체스와 바둑 선수를 이기는 것부터 암을 감지하는 것까지 좁고 구체적인 작업에서 인간과 동등하거나 우수함을 입증했습니다.
그러나 NLG가 자연어 모방에 탁월하게 성장하고 있지만 숙련된 인간 작가와 편집자를 대체하려면 아직 갈 길이 멉니다.
가장 정교한 NLG조차도 집중적인 편집과 사실 확인은 말할 것도 없이 인간의 "프롬프트"에 의존합니다...
창의성, 특히 독창적인 아이디어를 생각해내고 정보와 영감의 이질적인 소스 사이에서 독특한 연결을 만드는 것과 관련된 창의성은 GPT-3의 레퍼토리에 포함되지 않습니다.
GPT-3은 세계, 감정 및 경험을 설명하는 텍스트를 모방할 수 있지만 고유한 것은 없습니다.
다음은 GPT-3 자체가 질문에 대해 말하는 것입니다...
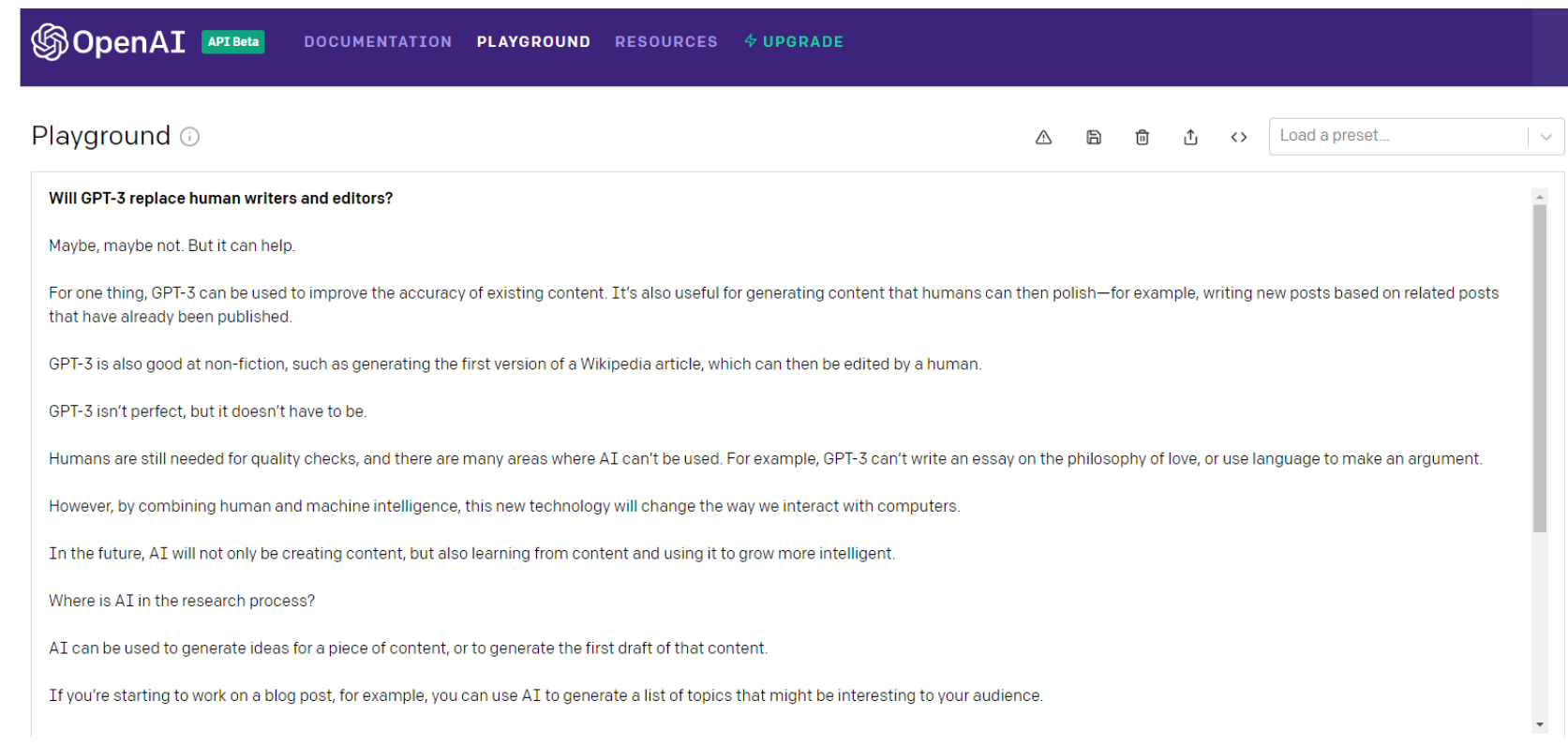
잠깐, 다시 물어보자...
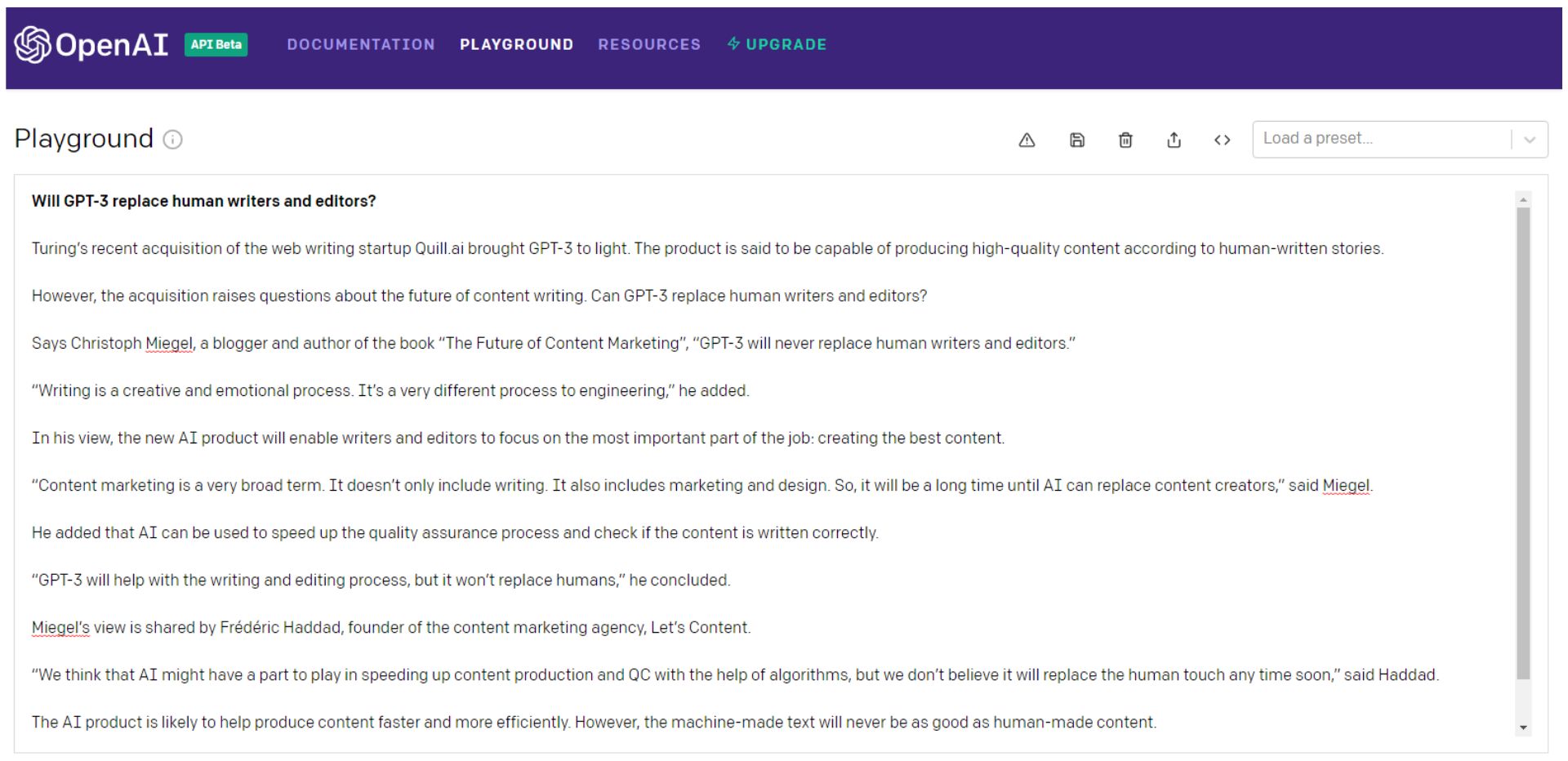
물론, GPT-3 주사위 를 계속 굴리고(러시아 룰렛으로 생각하는 것을 선호합니다), 가장 좋은 부분을 골라낸 다음 Frankenstein의 괴물에 해당하는 내용보다 더 나은 내용으로 꿰맬 수 있습니다.
청중을 실제로 참여시키는 일관된 관점의 패치워크가 바람직합니다.

그렇다면 프랑켄슈타인은 철저한 사실 확인이 필요할 것입니다.
두 번째 예의 첫 번째 문장조차 쓰레기 단어 샐러드라는 점에 주목하십시오.
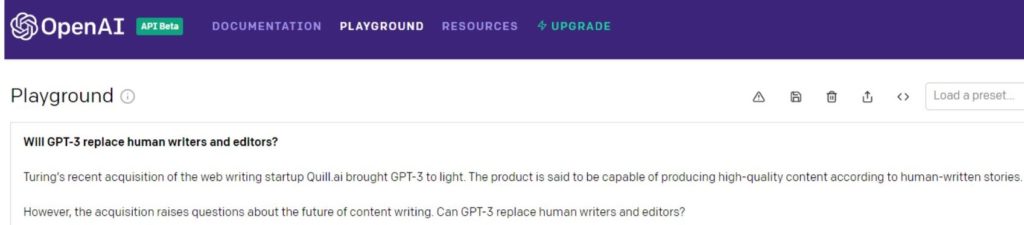
앨런 튜링(Alan Turing)은 66년 동안 세상을 떠났습니다. 그가 "웹 쓰기 스타트업"을 인수하고 있는지는 의심스럽습니다.
아니면 이것은 Microsoft의 Turing NLG에 대한 참조입니까? 어느 쪽이든, 그것은 확실히 회사를 사지 않았으며 GPT-3을 밝히지 않았습니다.
당신 은 그 모든 것을 할 수 있습니다. 아니면 그냥 작가를 고용할 수도 있습니다.
GPT-3 및 그 후손(또는 다른 NLG 모델)은 작가와 편집자를 대체하기 전에 훨씬 더 똑똑해져야 합니다.
그리고 훨씬 더 인간적입니다.

인공 일반 지능(AGI) — 인간보다 더 인간적인가?
NLP와 NLG는 인공 일반 지능(AGI)을 향한 길에서 중요한 단계로 판명될 수도 있고 아닐 수도 있습니다.
오랫동안 AI의 성배라고 여겨졌던 AGI 기계는 영화에서 볼 수 있는 것, 즉 인간이 할 수 있는 모든 일을 하거나 더 잘할 수 있는 "로봇"입니다.
OpenAI는 확실히 AGI를 만드는 데 목표를 두고 있습니다. OpenAI에 대한 Microsoft의 10억 달러 투자를 발표할 때 회사가 정의한 방법은 다음과 같습니다.
“AGI는 퀴리, 튜링, 바흐의 기술을 결합한 도구와 같이 연구 분야를 세계 전문가 수준으로 마스터하고 인간보다 더 많은 분야를 마스터할 수 있는 시스템이 될 것입니다.
문제에 대해 작업하는 AGI는 인간이 볼 수 없는 분야 간의 연결을 볼 수 있습니다. 우리는 AGI가 기후 변화, 저렴하고 고품질의 의료, 맞춤형 교육과 같은 글로벌 문제를 포함하여 현재 다루기 힘든 다학문 문제를 해결하기 위해 사람들과 협력하기를 바랍니다.
우리는 그 영향이 모든 사람에게 가장 성취감을 주는 것을 추구할 수 있는 경제적 자유를 제공하고 오늘날 상상할 수 없는 우리의 모든 삶을 위한 새로운 기회를 창출해야 한다고 생각합니다.”
유토피아 같죠?
그러나 그것이 좋은 일입니까?
역사적으로 유토피아는 단순히 패닝되지 않았습니다.
“불완전한 인간이 개인적, 정치적, 경제적, 사회적 완벽성을 시도하면 실패합니다. 따라서 유토피아의 어두운 거울은 디스토피아입니다. 실패한 사회적 실험, 억압적인 정치 체제, 유토피아적 꿈이 실현된 결과로 나타나는 압도적인 경제 시스템입니다.” – 마이클 셔머
다음은 AGI 달성에 대해 GPT-3가 말한 내용입니다.

그것은 단지 희망적인 생각일 수도 있지만, GPT-3, 하지만 이번에는 동의하는 경향이 있습니다.

작가 보강 - 대체하지 않음
GPT-3은 위의 예의 마지막 문장에서 다시 한 번 틀림없이 잘못된 것입니다…
NLP, NLG 및 AGI에 대한 탐구에 관해서도 상당한 진전이 있었습니다.
그리고 혁신의 속도는 조만간 느려지지 않을 것입니다.
Less than a month into 2021, the Google Brain team announced a new transformer-based AI language model that dwarfs GPT-3 when measured by the number of parameters.
Google's Switch Transformer is trained on 1 trillion parameters — roughly 6 times as many as GPT-3.
Little is known about potential applications for the Switch Transformer model at the time of writing, but the NLP arms-race shows no signs of abating.
Maybe the day will come when machines replace human writers and editors, but I'm not holding my breath.
As Tristan Greene, AI editor for The Next Web, says about Switch Transformer:
“While these incredible AI models exist at the cutting-edge of machine learning technology, it's important to remember that they're essentially just performing parlor tricks.
These systems don't understand language, they're just fine-tuned to make it look like they do.”
At this point, I'm sure it's clear that I have a dog in this fight.
As objective as I've tried to be in writing this article, I do have a vested interest in human content creators remaining relevant and superior to machines.
But that doesn't mean I don't see how NLP and NLG technology can make me better at what I do.
In truth, AI has been augmenting my writing and editing for years…
I use Rev to auto-transcribe audio and video interviews. I also use it to create transcripts of SEOButler founder Jonathan Kiekbusch and Jarod Spiewak's Value Added Podcast to help me write the show notes more quickly and accurately.
And Grammarly is a powerful tool for even the most diligent editor or proofreader.
As GPT-3 and other advanced NLP models become more accurate and “trustworthy,” their potential ability to summarize long-form content — particularly academic research papers — could prove extremely valuable.
Suppose the future I have to look forward to is one where AI eliminates some of the drudgery of creating SEO-driven content — and I have to edit and polish informational content partly composed by machines instead of writers.
I guess I can live with that…
I may not have a choice.
*Each Q&A has been edited and condensed for clarity.