
Osiąganie odporności dzięki kolejkom: budowanie systemu, który nigdy nie pomija rytmu w ciągu miliarda
Opublikowany: 2018-12-21Braze przetwarza miliardy zdarzeń dziennie w imieniu swoich klientów, co skutkuje miliardami bardzo skoncentrowanych, spersonalizowanych wiadomości wysyłanych do ich użytkowników końcowych. Niewysłanie jednej z tych wiadomości ma konsekwencje, niezależnie od tego, czy jest to pominięty paragon, czy – co gorsza – nieodebrane powiadomienie informujące użytkownika, że jedzenie jest gotowe. Aby mieć pewność, że te kluczowe wiadomości są zawsze poprawne i zawsze na czas, Braze stosuje strategiczne podejście do tego, jak wykorzystujemy kolejki zadań.
Co to jest kolejka pracy?
Typowa kolejka zadań to wzorzec architektoniczny, w którym procesy przesyłają zadania obliczeniowe do kolejki, a inne procesy faktycznie wykonują zadania. Zwykle jest to dobra rzecz — gdy jest właściwie używana, zapewnia stopnie współbieżności, skalowalności i nadmiarowości, których nie można uzyskać w tradycyjnym paradygmacie żądanie-odpowiedź. Wielu pracowników może jednocześnie wykonywać różne zadania w wielu procesach, na wielu komputerach, a nawet w wielu centrach danych, aby zapewnić maksymalną współbieżność. Można przypisać określone węzły robocze do pracy w określonych kolejkach i wysyłać określone zadania do określonych kolejek, co pozwala na skalowanie zasobów zgodnie z potrzebami. Jeśli proces roboczy ulegnie awarii lub centrum danych przejdzie w tryb offline, inni pracownicy mogą wykonać pozostałe zadania.
Chociaż z pewnością możesz zastosować te zasady i łatwo uruchomić system kolejkowania zadań na małą skalę, szwy zaczynają się pojawiać (a nawet pękać), gdy przetwarzasz miliardy zadań. Przyjrzyjmy się kilku problemom, z jakimi borykał się Braze, gdy przeszliśmy od przetwarzania tysięcy do milionów, a teraz miliardów miejsc pracy dziennie.
Brak konsekwencji jest słabością
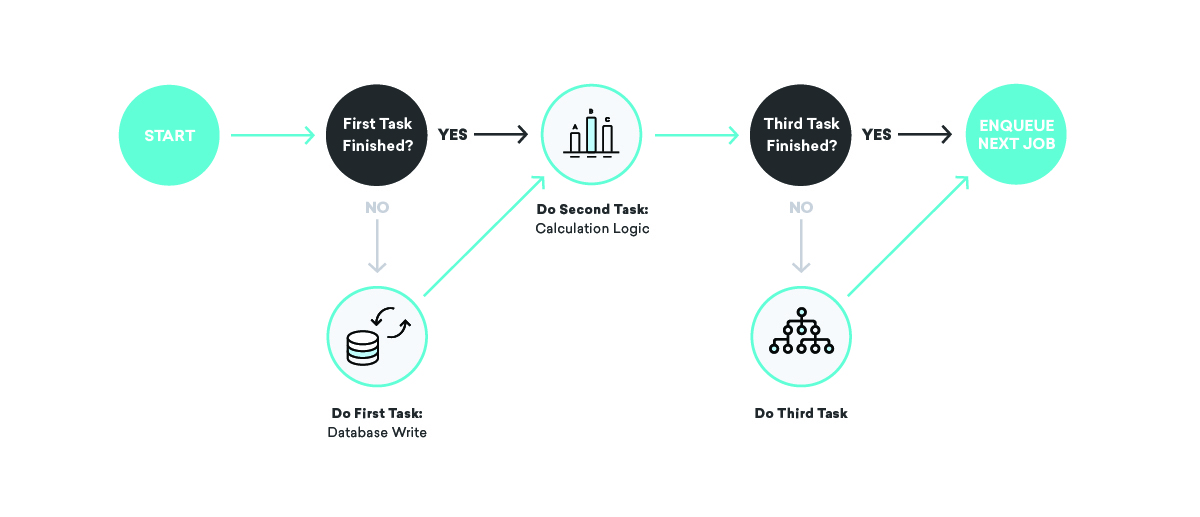
Co się stanie, jeśli wyślemy wiadomość, ale ulegniemy awarii przed zarejestrowaniem faktu, że właśnie wysłaliśmy tę wiadomość?
Możliwych jest tutaj kilka różnych złych wyników. Po pierwsze, możesz przełożyć nieudane zadanie i ponownie wysłać wiadomość. To… nie jest idealne: nikt nie chce otrzymać tego samego dwa razy. Zamiast tego rozważ w ogóle nie zmienianie tego harmonogramu. W takim przypadku nasza wewnętrzna księgowość będzie nieprawidłowa, więc atrybucje, konwersje i inne rzeczy nie będą prawidłowe.
Jak to naprawić? Pisząc nasze definicje pracy, bardzo intensywnie myślimy o idempotentności i zachowaniach związanych z ponawianiem próby.
Kiedy mówimy o kolejkach, idempotentność oznacza, że pojedyncze zadanie może zostać zakończone w dowolnym momencie, ponownie kolejkowane zadanie w całości zostało ponownie uruchomione, a efekt końcowy będzie taki sam, jak gdybyśmy pomyślnie uruchomili zadanie dokładnie jedno czas. Jest to ściśle związane z naszym wybranym przez nas zachowaniem w zakresie ponawiania próby — przynajmniej jednokrotnym dostarczeniem. Pamiętając, że wszystkie nasze zadania będą uruchamiane co najmniej raz, a być może wiele razy, możemy napisać idempotentne definicje zadań, które zapewniają spójność nawet w obliczu losowych awarii.
Wracając do naszego przykładu wysyłania wiadomości, w jaki sposób możemy wykorzystać te koncepcje, aby zapewnić spójność? W takim przypadku możemy podzielić zadanie na dwie części, przy czym pierwsza wysyła wiadomość i umieszcza w kolejce drugą, a druga zapisuje do bazy danych. W tym scenariuszu możemy ponawiać dowolne zadanie tyle razy, ile chcemy — jeśli dostawca wysyłający wiadomości nie działa lub wewnętrzna baza danych księgowości nie działa, będziemy odpowiednio ponawiać próbę, aż się powiedzie!
Dobre ogrodzenia tworzą dobrych sąsiadów
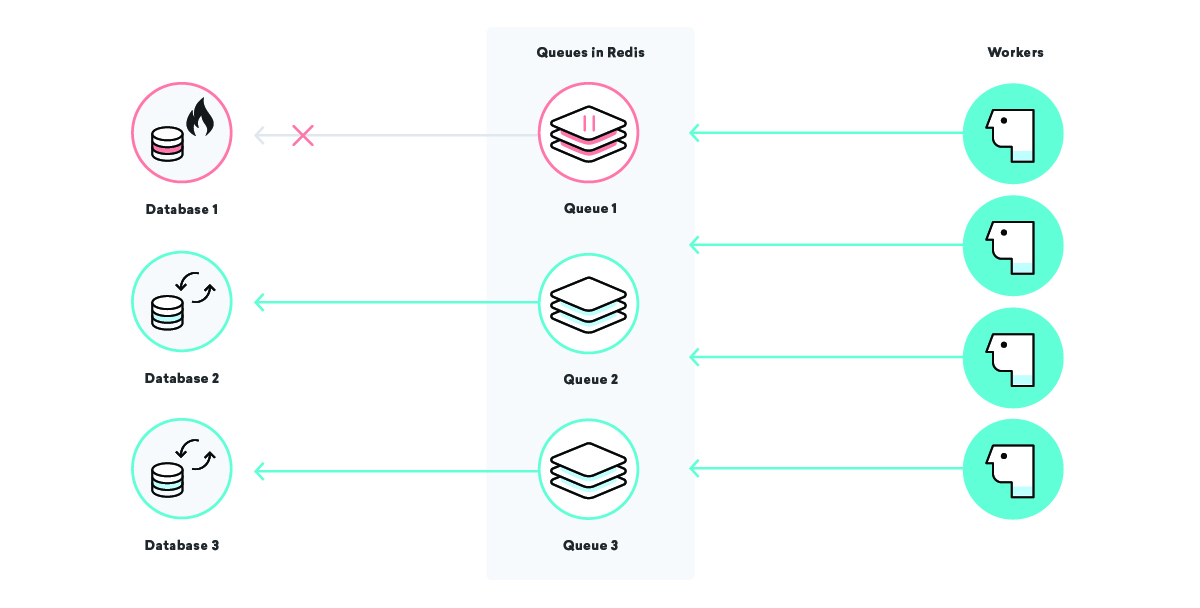
Co dzieje się z przetwarzaniem danych naszej przykładowej firmy Consolidated Widgets, gdy baza danych Global Gizmos przestanie działać?
W tym scenariuszu, jeśli nasza przynajmniej raz strategia dostarczania jest w grze, oczekiwalibyśmy, że wszystkie zadania związane z przetwarzaniem danych dla Global Gizmos będą powtarzać się w kółko, aż do skutku. To świetnie — nie stracimy żadnych danych, nawet gdy ich baza danych nie działa. Jednak w przypadku konsolidowanych widżetów może nie być tak wspaniale: jeśli pracownicy ciągle próbują i zawodzą, mogą być zbyt zajęci, aby terminowo przetwarzać zadania skonsolidowanych widżetów.
Możemy to naprawić, używając dobrze dobranych nazw kolejek i wstrzymując niektóre kolejki w razie potrzeby. Dzięki temu w naszym pasie narzędziowym możemy odciążyć elementy infrastruktury w sposób chirurgiczny. W naszym scenariuszu powyżej, gdy wiemy, że baza danych Global Gizmos nie działa, możemy wstrzymać kolejkę przetwarzania danych, dopóki nie dowiemy się, że jest to kopia zapasowa, upewniając się, że jedna konkretna awaria nie wpłynie na innych klientów!

Czekanie jest bolesne
Co się stanie, jeśli skonsolidowane widżety i globalne gadżety wyślą kampanie e-mailowe do 50 milionów użytkowników w odstępie 5 minut? Kto idzie pierwszy?
Proste systemy kolejkowania zadań mają prostą kolejkę „pracy”, z której pracownicy pobierają zadania. Kiedy już masz spory wybór różnych zadań i typów zadań, prawdopodobnie przejdziesz do posiadania wielu rodzajów kolejek, z których każda ma inne priorytety lub typy pracowników wyciągających z tych kolejek. W tym duchu mamy wiele prostych kolejek do przetwarzania danych, przesyłania wiadomości i różnych zadań konserwacyjnych.
Przewiń do przodu, gdy wysyłasz miliardy spersonalizowanych wiadomości dziennie, jedna kolejka „wiadomości” nie wystarczy — co się stanie, gdy ta kolejka bardzo się rozrośnie, jak w powyższym przykładzie? Czy priorytetowo traktujemy zadania, które pojawiły się jako pierwsze?
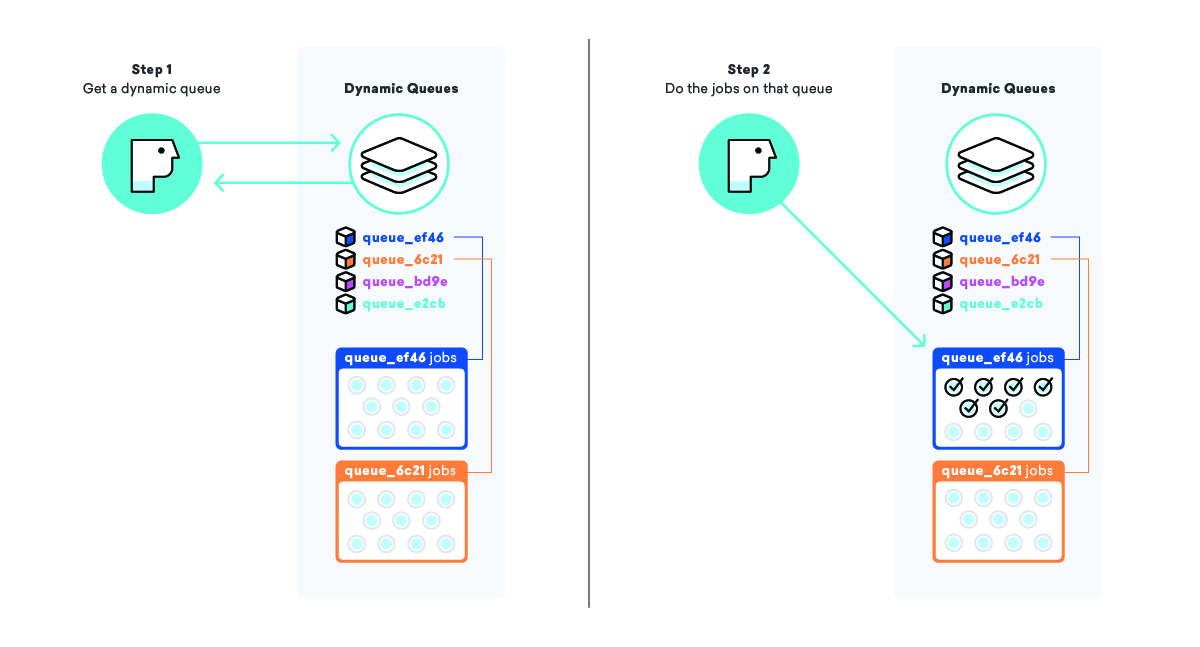
Nasz dynamiczny system kolejkowania ma na celu rozwiązanie problemu zwanego głodem pracy, w którym zadanie gotowe do wykonania czeka przez długi czas przed wykonaniem, zwykle z powodu jakiegoś priorytetu. W prostej kolejce „wiadomości” priorytetem jest po prostu czas, w którym zadanie znalazło się w kolejce, co oznacza, że zadania dodane na końcu dużej kolejki mogą czekać bardzo długo.
Kiedy przechodzimy do kolejki kampanii i wszystkich jej wiadomości, zamiast dodawać zadania do dużej kolejki „wiadomości”, tworzymy zupełnie nową kolejkę tylko dla tej kampanii, ze specjalną nazwą, abyśmy wiedzieli, co to jest i jak to znaleźć. Po dodaniu zadań do kolejki, pobieramy naszą listę „kolejek dynamicznych” i dodajemy tę nową nazwę kolejki na koniec.
Stosując tę strategię, możemy poinstruować pracowników, aby wybrali nazwę kolejki dynamicznej z listy „kolejek dynamicznych”, a następnie przetworzyli wszystkie zadania w tej konkretnej kolejce. Dzięki temu możemy zapewnić, że wiadomości są wysyłane tak szybko, jak to możliwe ORAZ, że wszyscy nasi klienci są traktowani z równym priorytetem.
W konsekwencji ma to inne zalety, takie jak wyższe współczynniki trafień w pamięci podręcznej i mniej połączeń z bazą danych, ze względu na wzrost lokalizacji pracy dla poszczególnych pracowników. Każdy wygrywa!
Zawsze miej plan tworzenia kopii zapasowych
Co się dzieje, gdy baza danych nie działa, niektóre kolejki są wstrzymane, a kolejki zadań zaczynają się zapełniać?
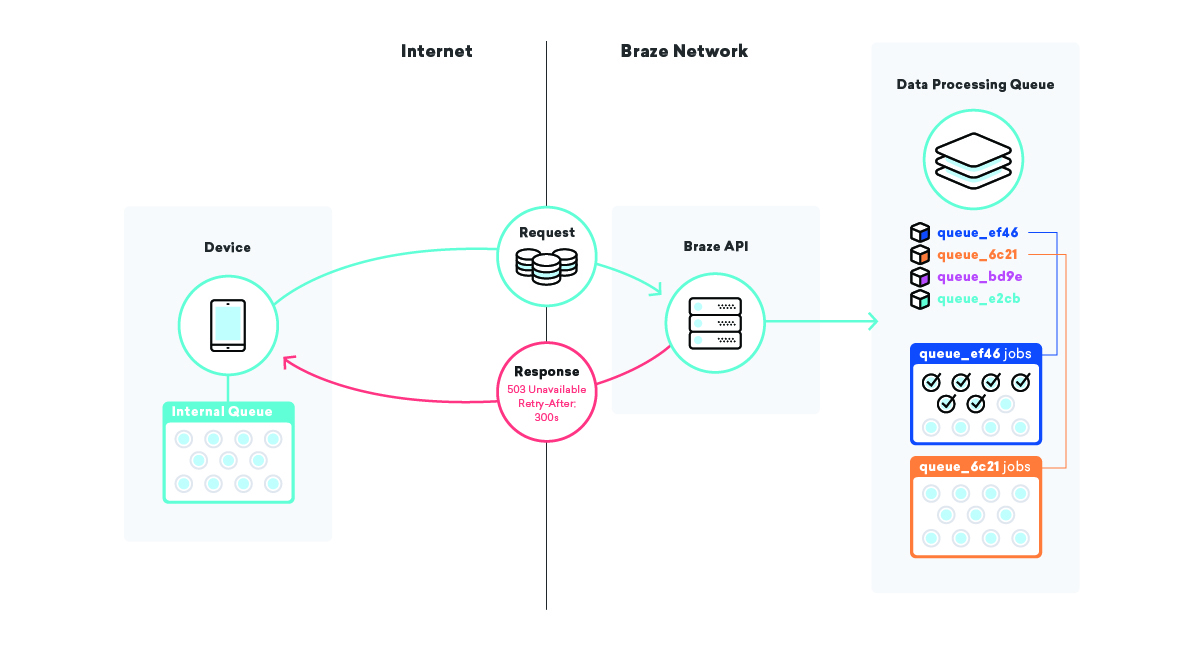
Czasami ważne elementy infrastruktury po prostu umierają na tobie. Mamy zapasowe i kopie zapasowe, ale czas potrzebny na promowanie infrastruktury kopii zapasowych prawie nigdy nie jest zerowy. Posiadanie wielu warstw kolejek w całej infrastrukturze aplikacji może być bardzo pomocne w łagodzeniu wpływu tego typu zdarzeń.
Jedną z takich strategii, którą stosujemy, jest ustawianie się w kolejce na samych urządzeniach. Miliony urządzeń mają różne aplikacje korzystające z Braze SDK, a w tych aplikacjach wykorzystujemy kolejkę do wysyłania danych do naszych interfejsów API.
Kiedy nasz zestaw SDK przesyła te dane i z jakiegoś powodu nie powiedzie się, zestaw SDK ustawia w kolejce ponowną próbę, używając algorytmu wykładniczego wycofywania, aż się powiedzie. Ta strategia minimalizuje wpływ awarii infrastruktury lub kodu, ponieważ urządzenia po prostu ustawiają swoje dane w kolejce i wysyłają je do Braze, gdy wszystko będzie ponownie online.
Porusza się szybko i nie niszczy rzeczy
W ostatecznym rozrachunku naszym celem jest wysyłanie bardzo skoncentrowanych, spersonalizowanych wiadomości lepiej niż ktokolwiek inny, a to obejmuje szybkie poruszanie się, bycie odpornym i robienie wszystkiego dobrze. Kolejki zadań są sercem infrastruktury Braze, więc zawsze obserwujemy naszą wydajność, stosujemy najlepsze praktyki i eksperymentujemy z nowymi strategiami i zaawansowanymi technikami, aby być najlepszymi w grze.
Jeśli ekscytuje Cię ten rodzaj wysokowydajnej inżynierii systemów o niskim opóźnieniu w obszarze automatyzacji marketingu, zdecydowanie powinieneś sprawdzić naszą tablicę ogłoszeń!