
Stan głębokiego uczenia się: z perspektywy programisty i VC
Opublikowany: 2017-09-05Nikhil Kapur omawia stan głębokiego uczenia się, najpierw jako student-programista, a teraz jako VC
Spędziłem jedną sobotę na warsztatach głębokiego uczenia się i TensorFlow w gigantycznym biurze Level 3 firmy Unilever Foundry i Padang.co. To był fajny dzień, gdy ponownie zanurzyłem się w świecie deweloperów i podobały mi się wszystkie rozmowy z moimi kolegami przy stole, jednym z nich prowadził rodzinny biznes i uczył się ML/głębokiego uczenia się jako hobby (jest entuzjastą programowania), a drugi z Dział marketingu firmy Zalora chce zastosować sztuczną inteligencję w swojej pracy.
Zaczęliśmy od skonfigurowania TensorFlow i Keras (abstrakcja nad TensorFlow) na naszych maszynach, a następnie zaczęliśmy majstrować przy niektórych typowych problemach z głębokim uczeniem i przykładach, takich jak korzystanie z zestawu danych MNIST. Zaczynając od prostego, małego modelu NLP do rozpoznawania tekstu, zanurzyliśmy się w Convolutional Neural Networks , które okazały się naprawdę zabawne.
Korzystaliśmy z gotowych, wstępnie wytrenowanych modeli, takich jak Incepcja V3, ale bawiliśmy się własnymi zestawami danych i ponownie trenowaliśmy model, aby rozwiązać różne problemy, takie jak „Czy to kot czy pies?” Celem zajęć było zrozumienie podstaw głębokiego uczenia się oraz eksperymentowanie z parametrami i funkcjami. Jeśli już czujesz się zazdrosny, sugeruję, abyś poszedł i pobawił się placem zabaw.tensorflow.org, to była najłatwiejsza część warsztatu!
Ogromne okrzyki dla Sama Witteveena i Martina Andrewsa za zorganizowanie tego. Przytaczam tutaj niektóre z perspektyw, z których wyszedłem i gdzie widzę głębokie uczenie się i sztuczną inteligencję w ogólnym ujęciu, szczególnie z perspektywy VC.
Głębokie uczenie się z perspektywy programisty
Aby dać trochę tła, miałem dość dużą ekspozycję na „sztuczną inteligencję”. Na drugim roku studiów odbyłam staż w dziale doradztwa technologicznego firmy Deloitte. Wraz z moim przyjacielem Ujjwalem Dasguptą, który później skończył studia magisterskie w ML, a teraz jest w Google, spędziłem kilka miesięcy, pracując nad ulepszonym procesem ETL (Extract-Transform-Load) w IBM Datastage, oprogramowaniu do hurtowni danych. W tamtym czasie Ujjwal, który zawsze był bardziej wybiegający w przyszłość niż ja, wprowadził mnie w eksplorację danych i zacząłem śledzić wykłady i kursy online Andrew Ng.
Następnego lata, zaintrygowany czasem, który już spędziłem na tym temacie, chciałem zagłębić się w ML. Miałem szczęście, że zostałem przydzielony do projektu w Mozilli, aby poprawić wydajność Firefoksa za pomocą kompilatora opartego na uczeniu maszynowym — Milespot GCC. Używając tego kompilatora ML, mogłem skompilować kod Mozilla Firefox, aby uzyskać około 10% poprawę czasu ładowania programu.
A potem dla mojej pracy dyplomowej nie było mowy, żebym mógł odpuścić ML. Współpracowałem z DFKI, Niemieckim Instytutem Sztucznej Inteligencji, aby pracować nad niezwykle wymagającym projektem, używając prostej kamery internetowej do śledzenia gałek ocznych. Zespół DFKI używał tego do konkretnej aplikacji, Text 2.0. Używali specjalnej kamery HD do śledzenia twoich oczu i odpowiednio powiększali tekst za pomocą mega fajnych funkcji , takich jak automatyczne przewijanie, automatyczne tłumaczenie, wyskakujący słownik itp.
Zdecydowaliśmy się zrobić to samo z prostą kamerką internetową, ponieważ nikt w Indiach nie miał pieniędzy na zakup tej specjalnej kamery HD. Aby być precyzyjnym, nie udało nam się tego osiągnąć, osiągając tylko około 70% dokładności w naszym śledzeniu. Ale to był jeden z najbardziej ekscytujących projektów, nad którymi pracowałem.
Polecany dla Ciebie:

Jak Metaverse zmieni indyjski przemysł motoryzacyjny?

Co oznacza przepis anty-profitowy dla indyjskich startupów?

W jaki sposób start-upy Edtech pomagają indyjskim pracownikom podnosić umiejętności i być gotowym na przyszłość...

Akcje New Age Tech w tym tygodniu: Kłopoty Zomato nadal, EaseMyTrip publikuje Stro...

Indyjskie startupy idą na skróty w pogoni za finansowaniem

Digital Marketing Platform Logicserve Bags Finansowanie INR 80 Cr, zmienia nazwę na LS Dig...
Dlaczego więc nudzę cię szczegółami tego? Głównie po to, aby dać ci trochę historii o tym, gdzie znajdowała się sztuczna inteligencja, kiedy szlifowałem moją inżynierię. Nawet dekady temu głębokie uczenie i ML już istniały, ale dopiero w ciągu ostatnich 10 lat dziedzina ta dojrzała. Co dokładnie zmieniło się w ciągu ostatnich kilku lat?

Po pierwsze, prawo Moore'a doprowadziło nas do punktu, w którym koszt przechowywania i przetwarzania stał się minimalny dla kogoś, kto zaimplementował ML w swoim domu. Możesz teraz uruchamiać prawie wszystkie podstawowe modele na własnym komputerze, a jeśli kupisz dobry procesor graficzny (który nie jest już tak kosztowny), może on zoptymalizować czas obliczeniowy prawie 10x, aby móc uruchamiać złożone modele.
Magazyn Wired ma świetny artykuł na temat tej zmiany.
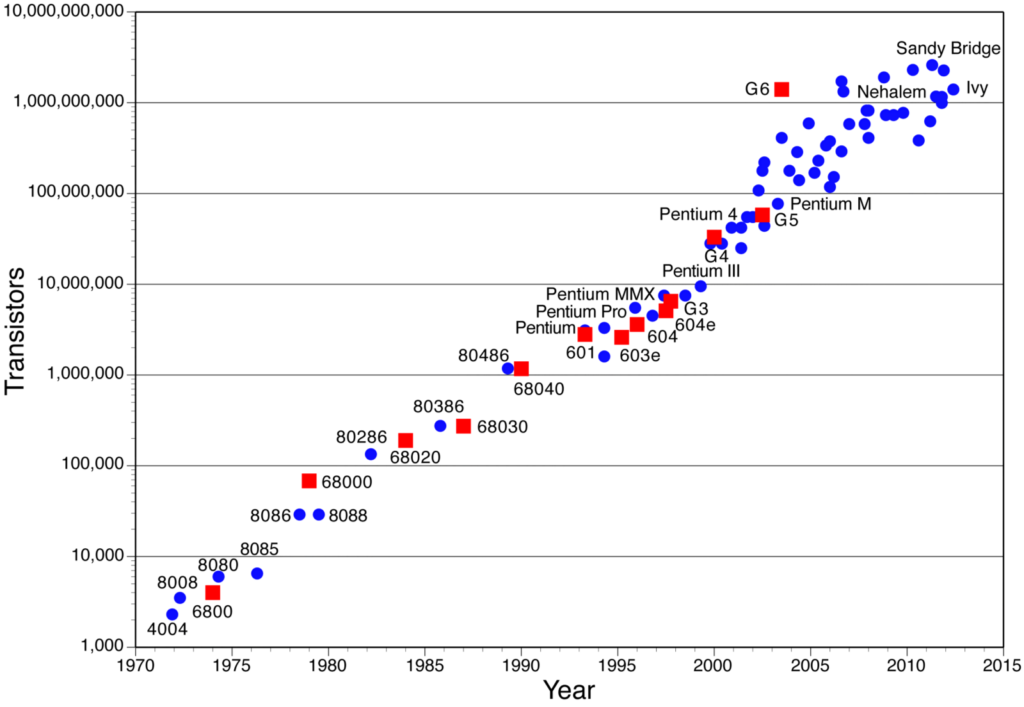
Liczba tranzystorów w chipach w ciągu roku (zauważ, że oś Y to skala logarytmiczna!). Źródło: Assured-Systems
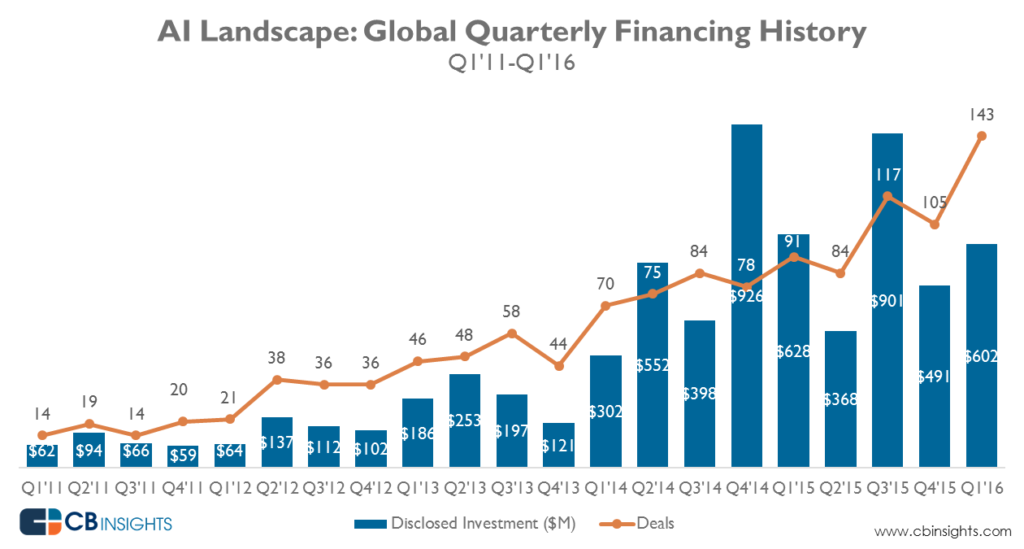
Kolejną rzeczą, która się zmieniła, jest to, że firmy zdały sobie sprawę z potrzeby automatyzacji. W wyniku tego, podczas gdy aktywność w zakresie fuzji i przejęć w terenie ogromnie wzrosła, inwestorzy VC przelewali pieniądze w teren przez ostatnie 5 lat.
Perspektywy inwestora dotyczące głębokiego uczenia
Na czym więc teraz stoimy i jak inwestor lub startup powinien postrzegać ten ekstremalny szum sztucznej inteligencji? Z mojego punktu widzenia, start-up AI ma cztery kluczowe aspekty, z których wszystkie muszą się połączyć, aby stworzyć silną firmę.
- Talent: Tutaj wszystko się zaczyna. O ile w startupie zespół jest oczywiście najważniejszym aspektem, o tyle w startupie AI to prawdziwy silnik firmy. Dostęp do silnych talentów w zakresie analityki danych i inżynierii komputerowej w celu dostrojenia tych gotowych modeli będzie kluczowy dla startupów AI i dlatego amerykańskie i chińskie startupy prawdopodobnie będą mieć przewagę w innych regionach geograficznych. Singapur ma niewielki skrawek talentu w zakresie analizy danych i prawdopodobnie będzie dobrym miejscem do założenia firmy zajmującej się sztuczną inteligencją. To powiedziawszy, najlepsze talenty prawdopodobnie trafią do gigantów technologicznych w sposób organiczny lub nieorganiczny. Przejęcie DeepMind przez Google było właśnie tym, grą w celu zdobycia jednych z najlepszych umysłów w Deep Mind.
- Dane: Jeśli zespół jest silnikiem, dane to benzyna w starcie AI. Bez dużej ilości czystych i uporządkowanych danych jest mało prawdopodobne, aby wyszkolony system był w stanie uzyskać dokładność, która utrudniałaby działanie aplikacji biznesowych. Ze względu na podstawową zależność możliwości predykcyjnych modelu od wprowadzanych danych, duże firmy prawdopodobnie będą miały znaczną przewagę nad start-upami na małą skalę, jeśli chodzi o wymyślanie lepszych i dokładniejszych systemów. Jest to niepokojąca myśl, a jedynym sposobem na przełamanie schematu będzie generowanie i wykorzystywanie własnych zastrzeżonych danych. System ewidencji, taki jak Salesforce, będzie w tym aspekcie niezwykle krytyczny.
- Model: Wszyscy giganci technologiczni uruchamiają obecnie własne systemy sztucznej inteligencji (platforma deweloperska, biblioteki, wytrenowane modele), aby stworzyć platformę dla przyszłego rozwoju sztucznej inteligencji. Nie wiadomo jeszcze, kto wygra wojnę, ale potrzeba tworzenia modeli od podstaw prędzej czy później się skończy. Tylko w przypadku naprawdę złożonych systemów istniałaby potrzeba rozpoczęcia budowania modeli od podstaw, ale w większości przypadków badacz danych będzie w stanie ponownie wykorzystać gotowe modele i przeszkolić je przy użyciu własnych danych. Skąd jednak wiesz, że osiągnąłeś najlepszy możliwy model? Firma Numerai, wspierana przez Union Square Ventures, rozwiązuje ten problem w bardzo inteligentny sposób, poprzez crowdsourcing do ekspertów ML i zachęty finansowe do budowania lepszych modeli.
- Problem biznesowy: tutaj sprawy stają się interesujące. Po pierwsze, użytkownik nie dba o to, czy Twoje systemy są zautomatyzowane, czy nie. Systemy AI mają na celu optymalizację własnej organizacji i sprawić, by maszyna wykonywała zadanie człowieka, a nie zadziwić użytkownika. Dlatego rozwiązanie konkretnego problemu biznesowego jest kluczem do zapewnienia dobrego doświadczenia użytkownika, a tym samym zwiększenia lepkości.
Po drugie, większość gigantów technologicznych ograniczy się do budowy szerokiej i ogólnej platformy. Podczas gdy firmy technologiczne, takie jak Salesforce, Hubspot itp., skaczą na sztuczną inteligencję, ich prawdopodobnie będzie trasą przejęcia. Salesforce już ogłosił Einsteina (choć jeszcze nie zrealizował poprawnie jego proklamacji), a Hubspot co tydzień pisze o sztucznej inteligencji na swoim blogu. Pokazuje tylko, jak bardzo są zainteresowani tą dziedziną, ale także jak trudno jest im zająć się konkretnymi problemami. W tym miejscu istnieją luki, które startup może wykorzystać, a nasza spółka portfelowa Saleswhale właśnie podąża tą drogą.
Moim zdaniem, jeśli startup rozwiąże poprzez automatyzację bardzo ukierunkowany problem, który dotyczy wystarczającej liczby osób korzystających z zastrzeżonych danych, które jego systemy gromadzą po drodze, prawdopodobnie będzie to bardzo lukratywny biznes z silnymi barierami wejścia. Jednak, o ile widzę, jest to mało prawdopodobne, aby była to okazja wielkości jednorożca w regionie, nie dopóki giganci technologiczni wciąż żyją.
[Ten post Nikhila Kapura po raz pierwszy pojawił się na Medium i został skopiowany za zgodą.]