
Skuteczne uczenie się: niedaleka przyszłość sztucznej inteligencji
Opublikowany: 2017-11-09Te skuteczne techniki uczenia się nie są nowymi technikami głębokiego uczenia/uczenia maszynowego, ale wzbogacają istniejące techniki jako hacki
Z pewnością nie ma wątpliwości, że ostateczną przyszłością sztucznej inteligencji jest dotarcie do ludzkiej inteligencji i przewyższenie jej. Ale jest to dalekosiężny wyczyn do osiągnięcia. Nawet najbardziej optymistyczni spośród nas zakładają, że sztuczna inteligencja na poziomie człowieka (AGI lub ASI) będzie za 10-15 lat, a sceptycy będą nawet skłonni założyć, że zajmie to wieki, jeśli to możliwe. Cóż, nie o to chodzi w tym poście.
Tutaj porozmawiamy o bardziej namacalnej, bliższej przyszłości i omówimy pojawiające się i potężne algorytmy i techniki AI, które naszym zdaniem będą kształtować najbliższą przyszłość AI.
AI zaczęła ulepszać ludzi w kilku wybranych i konkretnych zadaniach. Na przykład pokonanie lekarzy w diagnozowaniu raka skóry i pokonanie graczy Go na mistrzostwach świata. Ale te same systemy i modele zawiodą w wykonywaniu zadań innych niż te, do rozwiązywania których zostali przeszkoleni. Dlatego na dłuższą metę przyszłością sztucznej inteligencji określa się ogólnie inteligentny system, który skutecznie wykonuje zestaw zadań bez konieczności ponownej oceny.
Ale w niedalekiej przyszłości AI, na długo przed pojawieniem się AGI, w jaki sposób naukowcy mogą sprawić, że algorytm oparty na sztucznej inteligencji przezwycięży problemy, z którymi borykają się dzisiaj, aby wyjść z laboratoriów i stać się przedmiotami codziennego użytku?
Kiedy się rozejrzysz, AI wygrywa jeden zamek na raz (przeczytaj nasze posty o tym, jak AI wyprzedza ludzi, część pierwsza i część druga). Co może się nie udać w takiej grze, w której każdy wygrywa? Z czasem ludzie wytwarzają coraz więcej danych (czyli paszy, którą konsumuje sztuczna inteligencja), a nasze możliwości sprzętowe również się poprawiają. W końcu dane i lepsze obliczenia to powody, dla których w 2012 roku rozpoczęła się rewolucja Deep Learning, prawda? Prawda jest taka, że szybszy niż wzrost danych i obliczeń jest wzrost ludzkich oczekiwań. Naukowcy zajmujący się danymi musieliby wymyślić rozwiązania wykraczające poza to, co obecnie istnieje, aby rozwiązać rzeczywiste problemy. Na przykład klasyfikacja obrazów, jak sądzi większość ludzi, jest naukowo rozwiązanym problemem (jeśli oprzeć się pokusie stwierdzenia 100% dokładności lub GTFO).
Możemy klasyfikować obrazy (powiedzmy na obrazy kotów lub obrazy psów) pasujące do ludzkich możliwości za pomocą sztucznej inteligencji. Ale czy można to już wykorzystać w rzeczywistych przypadkach użycia? Czy sztuczna inteligencja może zapewnić rozwiązanie bardziej praktycznych problemów, z którymi borykają się ludzie? W niektórych przypadkach tak, ale w wielu przypadkach jeszcze nas tam nie ma.
Przeprowadzimy Cię przez wyzwania, które są głównymi przeszkodami na drodze do opracowania rzeczywistego rozwiązania wykorzystującego sztuczną inteligencję. Załóżmy, że chcesz sklasyfikować obrazy kotów i psów. Będziemy używać tego przykładu w całym poście.

Nasz przykładowy algorytm: Klasyfikowanie wizerunków kotów i psów
Poniższa grafika podsumowuje wyzwania:

Wyzwania związane z rozwojem sztucznej inteligencji w świecie rzeczywistym
Omówmy szczegółowo te wyzwania:
Nauka z gorszymi danymi
- Dane treningowe, z których korzystają najbardziej skuteczne algorytmy Deep Learning, wymagają oznaczenia zgodnie z zawartością/funkcją, którą zawierają. Ten proces nazywa się adnotacją.
- Algorytmy nie mogą wykorzystywać naturalnie znalezionych danych wokół ciebie. Adnotacja kilkuset (lub kilku tysięcy punktów danych) jest łatwa, ale nasz algorytm klasyfikacji obrazów na poziomie człowieka wziął milion obrazów z adnotacjami, aby dobrze się nauczyć.
- Powstaje więc pytanie, czy możliwe jest dodawanie adnotacji do miliona obrazów? Jeśli nie, to w jaki sposób sztuczna inteligencja może skalować się z mniejszą ilością danych z adnotacjami?
Rozwiązywanie różnorodnych rzeczywistych problemów
- Podczas gdy zestawy danych są stałe, wykorzystanie w świecie rzeczywistym jest bardziej zróżnicowane (na przykład algorytm wyszkolony na kolorowych obrazach może źle działać na obrazach w skali szarości, w przeciwieństwie do ludzi).
- Udoskonaliliśmy algorytmy widzenia komputerowego, aby wykrywać obiekty, aby dopasować je do ludzi. Ale jak wspomniano wcześniej, algorytmy te rozwiązują bardzo specyficzny problem w porównaniu z ludzką inteligencją, która pod wieloma względami jest znacznie bardziej ogólna.
- Nasz przykładowy algorytm AI, który klasyfikuje koty i psy, nie będzie w stanie zidentyfikować rzadkiego gatunku psa, jeśli nie zostanie karmiony obrazami tego gatunku.
Dostosowywanie danych przyrostowych
- Kolejnym poważnym wyzwaniem są dane przyrostowe. W naszym przykładzie, jeśli próbujemy rozpoznać koty i psy, możemy wyszkolić naszą sztuczną inteligencję pod kątem wielu obrazów kotów i psów różnych gatunków podczas pierwszego wdrożenia. Ale po odkryciu zupełnie nowego gatunku musimy wytrenować algorytm, aby rozpoznawał „Kotpies” wraz z poprzednim gatunkiem.
- Chociaż nowe gatunki mogą być bardziej podobne do innych niż nam się wydaje i można je łatwo wyszkolić, aby dostosować algorytm, są punkty, w których jest to trudniejsze i wymaga całkowitego przeszkolenia i ponownej oceny.
- Pytanie brzmi, czy możemy sprawić, by sztuczna inteligencja przynajmniej przystosowała się do tych małych zmian?
Aby sztuczna inteligencja stała się natychmiast użyteczna, chodzi o rozwiązanie wyżej wymienionych wyzwań za pomocą zestawu podejść o nazwie Efektywne uczenie się (proszę zauważyć, że nie jest to oficjalny termin, po prostu zmyślam go, aby uniknąć pisania Meta-Learning, Transfer Learning, Few Shot Learning, Adversarial Learning i Multi-Task Learning za każdym razem). W ParallelDots używamy teraz tych podejść do rozwiązywania wąskich problemów ze sztuczną inteligencją, wygrywając małe bitwy, jednocześnie przygotowując się do bardziej wszechstronnej sztucznej inteligencji, aby podbijać większe wojny. Pozwól, że przedstawimy Ci te techniki pojedynczo.
Zauważalnie, większość z tych technik efektywnego uczenia się nie jest czymś nowym. Po prostu widzą teraz odrodzenie. Badacze SVM (Support Vector Machines) od dawna stosują te techniki. Z drugiej strony, uczenie się kontradyktoryjności jest czymś, co wywodzi się z ostatnich prac Goodfellowa dotyczących GAN, a rozumowanie neuronowe to nowy zestaw technik, dla których zbiory danych stały się dostępne bardzo niedawno. Przyjrzyjmy się, jak te techniki pomogą w kształtowaniu przyszłości sztucznej inteligencji.
Transfer nauki
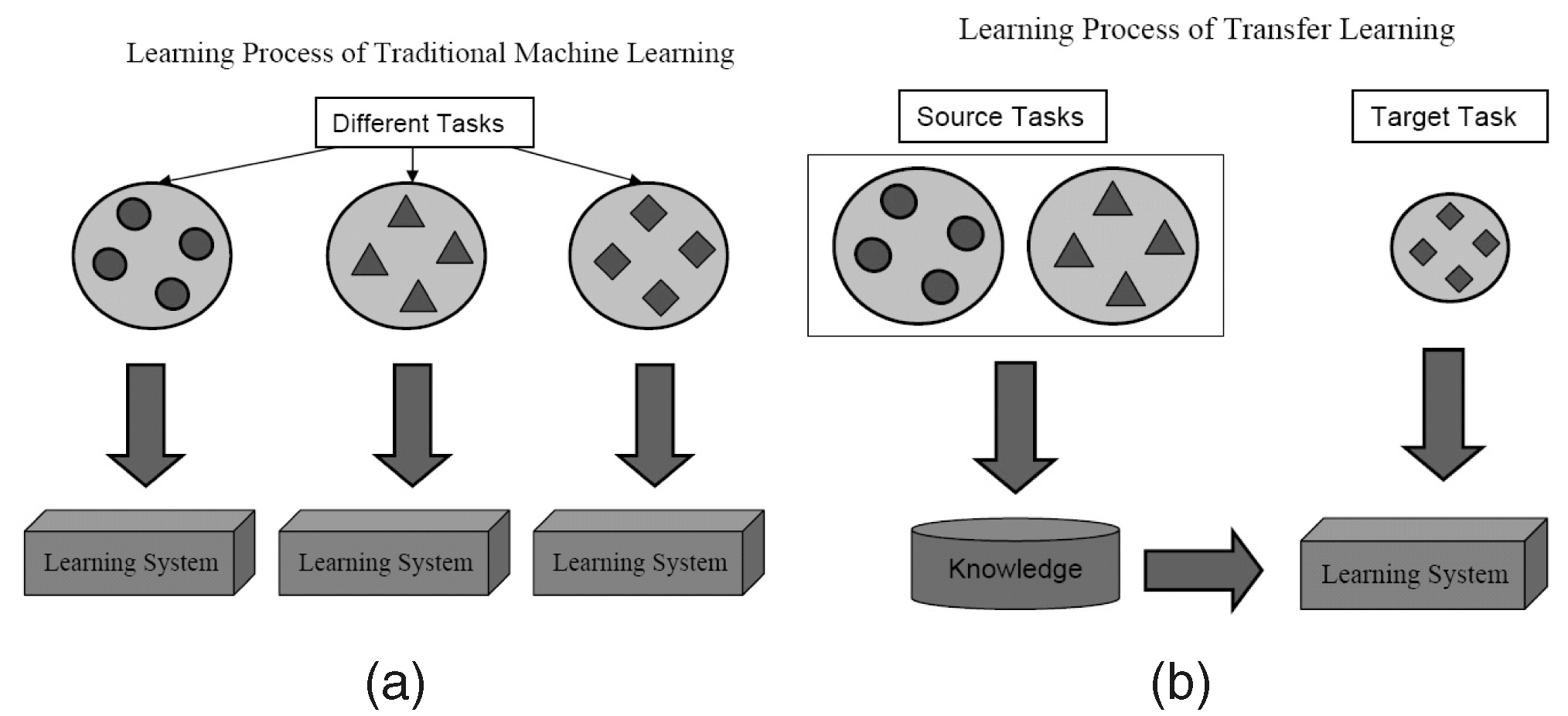
Co to jest?
Jak sama nazwa wskazuje, nauka jest przenoszona z jednego zadania do drugiego w ramach tego samego algorytmu w Transfer Learning. Algorytmy wytrenowane na jednym zadaniu (zadaniu źródłowym) z większym zbiorem danych mogą być przesyłane z lub bez modyfikacji jako część algorytmu próbującego nauczyć się innego zadania (zadanie docelowe) na (stosunkowo) mniejszym zbiorze danych.
Kilka przykładów
Wykorzystanie parametrów algorytmu klasyfikacji obrazów jako ekstraktora cech w różnych zadaniach, takich jak wykrywanie obiektów, jest prostym zastosowaniem Transfer Learning. W przeciwieństwie do tego może być również używany do wykonywania złożonych zadań. Algorytm, który niedawno opracował Google, aby klasyfikować retinopatię cukrzycową lepiej niż lekarze, został stworzony przy użyciu Transfer Learningu. Co zaskakujące, detektor retinopatii cukrzycowej był w rzeczywistości klasyfikatorem obrazów ze świata rzeczywistego (klasyfikatorem obrazów psów/kotów) Transfer Learning do klasyfikowania skanów oczu.
Powiedz mi więcej!
W literaturze Deep Learning można znaleźć Data Scientystów, którzy nazywają takie przeniesione części sieci neuronowych od źródła do zadania docelowego jako sieci wstępnie wytrenowane. Dostrajanie precyzyjne ma miejsce, gdy błędy zadania docelowego są łagodnie wstecznie propagowane do wstępnie wytrenowanej sieci, zamiast korzystać z wstępnie wytrenowanej sieci w postaci niezmodyfikowanej. Dobre wprowadzenie techniczne do Transfer Learningu w Computer Vision można zobaczyć tutaj. Ta prosta koncepcja Transfer Learningu jest bardzo ważna w naszym zestawie metodologii efektywnego uczenia się.
Polecany dla Ciebie:

Jak Metaverse zmieni indyjski przemysł motoryzacyjny?

Co oznacza przepis anty-profitowy dla indyjskich startupów?

W jaki sposób start-upy Edtech pomagają indyjskim pracownikom podnosić umiejętności i być gotowym na przyszłość...

Akcje New Age Tech w tym tygodniu: Kłopoty Zomato nadal, EaseMyTrip publikuje Stro...

Indyjskie startupy idą na skróty w pogoni za finansowaniem

Digital Marketing Platform Logicserve Bags Finansowanie INR 80 Cr, zmienia nazwę na LS Dig...
Nauka wielozadaniowa
Co to jest?
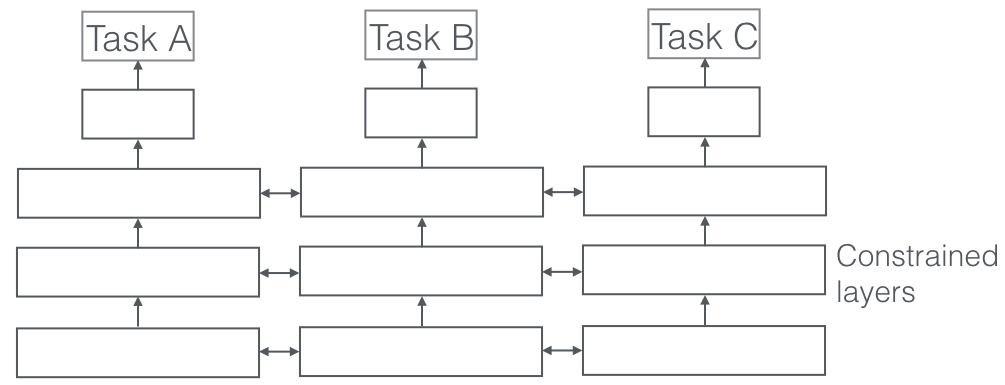

W uczeniu wielozadaniowym wiele zadań edukacyjnych jest rozwiązywanych w tym samym czasie, wykorzystując podobieństwa i różnice między zadaniami. To zaskakujące, ale czasami wspólne uczenie się dwóch lub więcej zadań (zwanych również zadaniami głównymi i zadaniami pomocniczymi) może poprawić wyniki zadań. Należy pamiętać, że nie każdą parę, trójkę lub kwartet zadań można uznać za pomocniczą. Ale kiedy to działa, jest to darmowy przyrost dokładności.
Kilka przykładów
Na przykład w ParallelDots nasze klasyfikatory wykrywania nastrojów, intencji i emocji zostały przeszkolone jako uczenie wielozadaniowe, co zwiększyło ich dokładność w porównaniu z tym, gdybyśmy trenowali je osobno. Najlepszym znanym nam systemem semantycznego etykietowania ról i tagowania POS w NLP jest system uczenia wielozadaniowego, a więc jest jednym z najlepszych systemów do segmentacji semantycznej i instancji w Computer Vision. Google wymyślił multimodalne wielozadaniowe osoby uczące się (jeden model, który rządzi wszystkimi), które mogą uczyć się zarówno na podstawie wizji, jak i zbiorów danych tekstowych w tym samym ujęciu.
Powiedz mi więcej!
Bardzo ważnym aspektem uczenia się wielozadaniowego, który jest widoczny w rzeczywistych aplikacjach, jest to, że uczenie każdego zadania, aby stało się kuloodporne, musimy szanować dane z wielu domen (zwane również adaptacją domen). Przykładem w naszych zastosowaniach dla kotów i psów będzie algorytm, który potrafi rozpoznawać obrazy z różnych źródeł (np. kamery VGA i kamery HD, a nawet kamery na podczerwień). W takich przypadkach do dowolnego zadania można dodać pomocniczą utratę klasyfikacji domeny (skąd pochodziły obrazy) i wtedy maszyna uczy się, że algorytm jest coraz lepszy w głównym zadaniu (klasyfikowanie obrazów na obrazy kota lub psa), ale celowo pogarsza się w zadaniu pomocniczym (odbywa się to przez wsteczną propagację wstecznego gradientu błędu z zadania klasyfikacji domeny). Chodzi o to, że algorytm uczy się cech rozróżniających dla głównego zadania, ale zapomina o cechach, które różnicują domeny, a to polepszyłoby to zadanie. Uczenie się wielozadaniowe i jego kuzyni z adaptacji domeny to jedna z najbardziej udanych technik efektywnego uczenia się, jakie znamy, i która ma do odegrania dużą rolę w kształtowaniu przyszłości sztucznej inteligencji.
Nauka kontradyktoryjności
Co to jest?
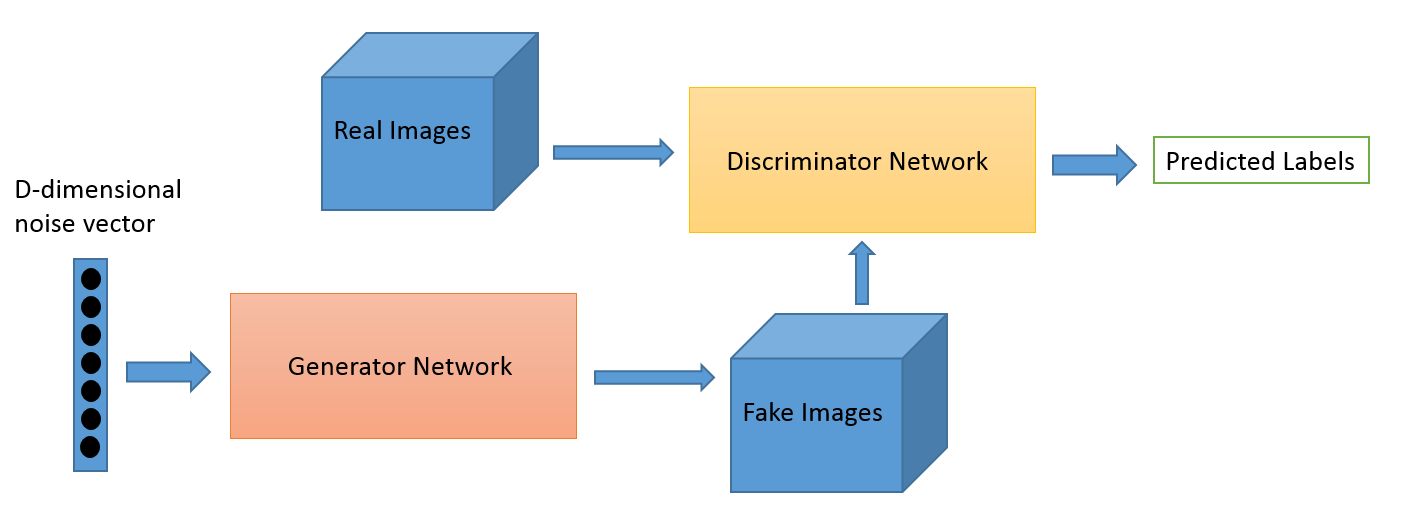
Adversarial Learning jako dziedzina wyewoluowało z prac badawczych Iana Goodfellowa. Podczas gdy najpopularniejszymi zastosowaniami Adversarial Learning są bez wątpienia Generative Adversarial Networks (GAN), które mogą być wykorzystywane do generowania oszałamiających obrazów, istnieje wiele innych sposobów wykorzystania tego zestawu technik. Zazwyczaj ta technika inspirowana teorią gier ma dwa algorytmy, generator i dyskryminator, których celem jest oszukiwanie się nawzajem podczas treningu. Generator może być używany do generowania nowych, nowatorskich obrazów, jak omówiliśmy, ale może również generować reprezentacje dowolnych innych danych, aby ukryć szczegóły przed dyskryminatorem. To właśnie dlatego ta koncepcja jest dla nas tak bardzo interesująca.
Kilka przykładów
Jest to nowa dziedzina, a zdolność generowania obrazu jest prawdopodobnie tym, na czym skupia się większość zainteresowanych, takich jak astronomowie. Ale wierzymy, że będzie to ewoluować również w nowszych przypadkach użycia, jak powiemy później.
Powiedz mi więcej!
Gra adaptacji domeny może zostać ulepszona za pomocą utraty GAN. Stratą pomocniczą jest tutaj system GAN zamiast czystej klasyfikacji domenowej, gdzie dyskryminator próbuje sklasyfikować, z której domeny pochodzą dane, a komponent generatora próbuje go oszukać, prezentując losowy szum jako dane. Z naszego doświadczenia wynika, że działa to lepiej niż zwykła adaptacja domeny (co jest również bardziej błędne w kodzie).
Nauka kilku strzałów
Co to jest?
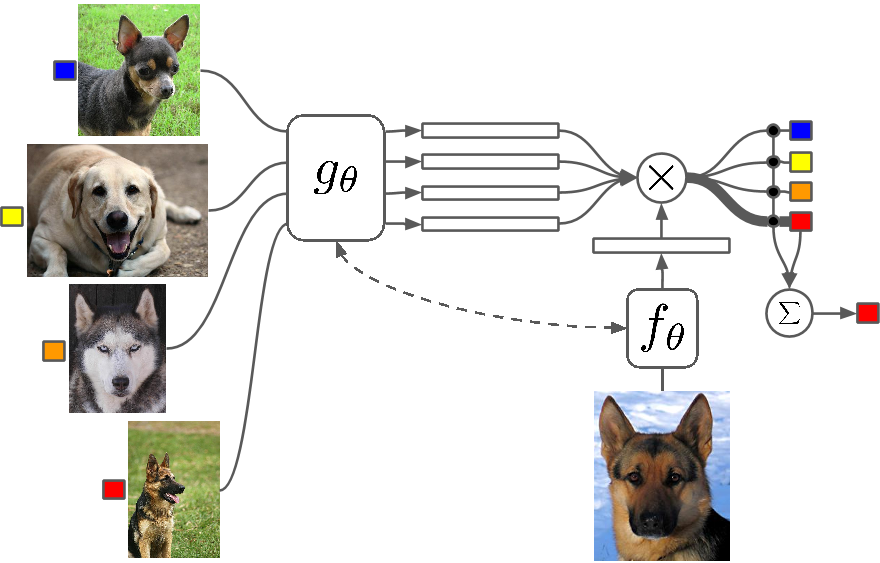
Few Shot Learning to studium technik, które sprawiają, że algorytmy Deep Learning (lub dowolny algorytm uczenia maszynowego) uczą się przy mniejszej liczbie przykładów w porównaniu z tym, co zrobiłby tradycyjny algorytm. One Shot Learning to zasadniczo uczenie się z jednym przykładem kategorii, indukcyjne uczenie k-shot oznacza uczenie się z k przykładami z każdej kategorii.
Kilka przykładów
Few Shot Learning jako dziedzina jest świadkiem napływu artykułów na wszystkich głównych konferencjach Deep Learning, a teraz istnieją określone zestawy danych, na których można porównywać wyniki, podobnie jak MNIST i CIFAR są przeznaczone do normalnego uczenia maszynowego. One-shot Learning obejmuje wiele zastosowań w niektórych zadaniach klasyfikacji obrazów, takich jak wykrywanie i reprezentacja funkcji.
Powiedz mi więcej!
Istnieje wiele metod, które są używane do uczenia się kilku strzałów, w tym uczenie transferu, uczenie wielozadaniowe, a także uczenie meta, jako całość lub część algorytmu. Istnieją inne sposoby, takie jak sprytna funkcja straty, użycie dynamicznych architektur lub użycie hacków optymalizacyjnych. Zero Shot Learning, klasa algorytmów, które twierdzą, że przewidują odpowiedzi dla kategorii, których algorytm nawet nie widział, to w zasadzie algorytmy, które można skalować z nowym typem danych.
Meta-nauka
Co to jest?

Meta-Learning jest dokładnie tym, na co wygląda, algorytmem, który trenuje w taki sposób, że po obejrzeniu zestawu danych daje nowy predyktor uczenia maszynowego dla tego konkretnego zestawu danych. Definicja jest bardzo futurystyczna, jeśli spojrzysz na nią na pierwszy rzut oka. Czujesz „wow! to właśnie robi Data Scientist” i automatyzuje „najseksowniejszą pracę XXI wieku”, i w pewnym sensie meta-uczący się zaczęli to robić.
Kilka przykładów
Meta-Learning stało się ostatnio gorącym tematem w Deep Learning, wraz z pojawieniem się wielu artykułów naukowych, najczęściej wykorzystujących technikę optymalizacji hiperparametrów i sieci neuronowych, znajdowanie dobrych architektur sieciowych, rozpoznawanie obrazów typu Few-Shot i szybkie uczenie ze wzmocnieniem.
Powiedz mi więcej!
Niektórzy ludzie odnoszą się do tej pełnej automatyzacji decydowania zarówno o parametrach, jak i hiperparametrach, takich jak architektura sieci, jako autoML, a ludzie mogą odnosić się do Meta Learning i AutoML jako różnych dziedzin. Pomimo całego szumu wokół nich, prawda jest taka, że Meta Learners wciąż są algorytmami i ścieżkami do skalowania uczenia maszynowego z rosnącą złożonością i różnorodnością danych.
Większość artykułów Meta-Learning to sprytne hacki, które według Wikipedii mają następujące właściwości:
- System musi zawierać podsystem uczenia się, który dostosowuje się wraz z doświadczeniem.
- Doświadczenie zdobywa się, wykorzystując meta-wiedzę wyodrębnioną w poprzednim epizodzie uczenia się na pojedynczym zbiorze danych lub z różnych dziedzin lub problemów.
- Stronniczość uczenia się należy wybierać dynamicznie.
Podsystem jest w zasadzie konfiguracją, która dostosowuje się, gdy wprowadzane są do niej metadane domeny (lub zupełnie nowej domeny). Te metadane mogą informować o rosnącej liczbie klas, złożoności, zmianie kolorów i tekstur oraz obiektów (na obrazach), stylach, wzorcach językowych (język naturalny) i innych podobnych cechach. Sprawdź kilka super fajnych artykułów tutaj: Meta-Learning Shared Hierarchies i Meta-Learning using Temporal Convolutions. Możesz także tworzyć algorytmy Few Shot lub Zero Shot przy użyciu architektur Meta-Learning. Meta-Learning to jedna z najbardziej obiecujących technik, która pomoże w kształtowaniu przyszłości AI.
Rozumowanie neuronowe
Co to jest?

Rozumowanie neuronowe to kolejna wielka rzecz w problemach klasyfikacji obrazów. Rozumowanie neuronowe to krok powyżej rozpoznawania wzorców, w którym algorytmy wykraczają poza ideę prostej identyfikacji i klasyfikowania tekstu lub obrazów. Rozumowanie neuronowe rozwiązuje bardziej ogólne pytania w analityce tekstu lub analityce wizualnej. Na przykład poniższy obraz przedstawia zestaw pytań, na które rozumowanie neuronowe może odpowiedzieć na podstawie obrazu.
Powiedz mi więcej!
Ten nowy zestaw technik pojawi się po opublikowaniu zestawu danych bAbi Facebooka lub najnowszego zestawu danych CLEVR. Techniki mające na celu odszyfrowanie relacji, a nie tylko wzorców, mają ogromny potencjał, aby rozwiązać nie tylko rozumowanie neuronowe, ale także wiele innych trudnych problemów, w tym problemy z nauką kilku rzutów.
Wracać
Teraz, gdy wiemy, jakie są techniki, wróćmy i zobaczmy, jak rozwiązują one podstawowe problemy, od których zaczęliśmy. Poniższa tabela przedstawia obraz możliwości technik efektywnego uczenia się w celu sprostania wyzwaniom:
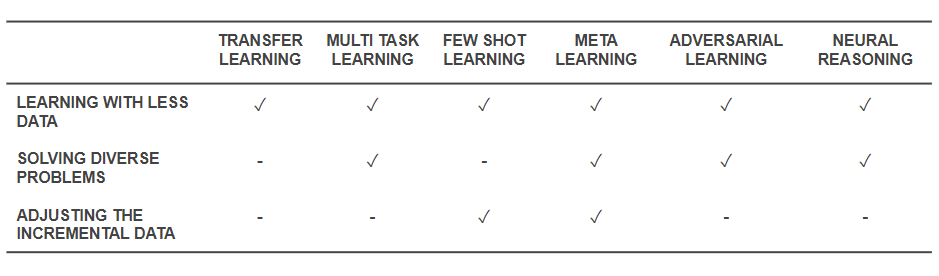
Możliwości technik efektywnego uczenia się
- Wszystkie wymienione powyżej techniki pomagają w ten czy inny sposób rozwiązać szkolenie z mniejszą ilością danych. Podczas gdy Meta-Learning dałoby architektury, które po prostu formowałyby się z danymi, Transfer Learning sprawia, że wiedza z innej dziedziny jest użyteczna, aby zrekompensować mniejszą ilość danych. Few Shot Learning poświęcony jest problemowi jako dyscyplinie naukowej. Nauka kontradyktoryjności może pomóc ulepszyć zbiory danych.
- Adaptacja domeny (rodzaj uczenia wielozadaniowego), uczenie się kontradyktoryjne i (czasami) architektury metauczenia pomagają rozwiązywać problemy wynikające z różnorodności danych.
- Meta-Learning i Few Shot Learning pomagają rozwiązywać problemy związane z danymi przyrostowymi.
- Algorytmy rozumowania neuronowego mają ogromny potencjał w rozwiązywaniu rzeczywistych problemów, gdy są włączone jako Meta-Learners lub Few Shot Learners.
Należy pamiętać, że te techniki efektywnego uczenia się nie są nowymi technikami głębokiego uczenia/uczenia maszynowego, ale rozszerzają istniejące techniki jako hacki , dzięki czemu są bardziej opłacalne. Dlatego nadal będziesz widzieć nasze zwykłe narzędzia, takie jak splotowe sieci neuronowe i LSTM w akcji, ale z dodanymi przyprawami. Te techniki efektywnego uczenia się, które działają z mniejszą ilością danych i wykonują wiele zadań za jednym razem, mogą pomóc w łatwiejszej produkcji i komercjalizacji produktów i usług opartych na sztucznej inteligencji. W ParallelDots dostrzegamy siłę efektywnego uczenia się i włączamy ją jako jedną z głównych cech naszej filozofii badań.
Ten post Parth Shrivastava po raz pierwszy pojawił się na blogu ParallelDots i został powielony za zgodą.