
Jakie są składniki danych o zdarzeniach?
Opublikowany: 2022-05-12To jest część czwarta z pięcioczęściowej serii poświęconej Danym klienta. Oto części pierwsza, druga i trzecia.
Dane klienta obejmują dane zdarzenia i dane podmiotu — już to wiesz, jeśli przeszedłeś przez część pierwszą (Czym są dane klienta?).
W tym przewodniku poznasz składniki danych o zdarzeniach, preferowaną konwencję nazewnictwa do definiowania zdarzeń, kategorie danych encji oraz dwa główne typy encji.
Dane zdarzenia
Ponieważ prawdopodobnie kupiłeś rzeczy online, zacznijmy od przykładu e-commerce.
Podczas interakcji z aplikacją e-commerce (internetową lub mobilną) zazwyczaj kupujesz produkt, dodając go do koszyka, przechodząc do kasy i dokonując płatności — są to zdarzenia, które wykonujesz, przechodząc przez proces kupowania przedmiotu na Aplikacja.
Droga kupującego nie jest jednak taka prosta i może mieć miejsce kilka innych wydarzeń, takich jak:
- Produkt jest oglądany
- Koszyk jest oglądany
- Produkt jest usuwany z koszyka
- Zastosowano kupon
- Wybrano adres
- Wybrano metodę płatności
- Zamówienie zakończone
I tak dalej.
Typowe zdarzenia, takie jak Dodaj do koszyka, Przejdź do kasy i Dokonaj płatności , przychodzą na myśl od razu, ale aby zrozumieć zachowanie użytkownika, należy również śledzić inne zdarzenia, takie jak te wymienione powyżej.
Decydowanie, które zdarzenia śledzić i nazywanie zdarzeń przy użyciu odpowiedniej konwencji nazewnictwa to dwa pierwsze kroki w procesie zbierania danych o zdarzeniach.
Jakie są następne dwa kroki?
Cieszę się, że zapytałeś!
Każdemu zdarzeniu towarzyszą właściwości zdarzenia (lub atrybuty zdarzenia ), które zapewniają więcej kontekstu na temat zdarzenia. Podjęcie decyzji, które właściwości skojarzyć ze zdarzeniem i nazwanie tych właściwości to kolejne dwa kroki w procesie zbierania danych o zdarzeniach.
Co jest w imieniu?
Jeśli chodzi o dane, wszystko.
Właściwa konwencja lub taksonomia nazewnictwa odróżnia dobre dane od złych i umożliwia interesariuszom zrozumienie tego, na co patrzą. Z drugiej strony nieutrzymywanie znormalizowanej taksonomii jest jedną z głównych przyczyn przekrzywienia lub rozdęcia zbiorów danych z powodu nadmiarowości.
Ponadto podczas pracy z danymi klientów nieutrzymywanie jednolitej wielkości liter podczas nazywania zdarzeń i właściwości zdarzeń jest jednym z największych błędów, jakie można popełnić — takim, który może mieć długoterminowe konsekwencje. Dobrej konwencji nazewnictwa powinny zawsze towarzyszyć ścisłe wytyczne dotyczące wielkości liter.
Dlatego:
Add to Cart, added_to_cart, productAdded, add to cart, Added to cart, Product Added to różne sposoby definiowania tego samego zdarzenia.
Chociaż żadna z tych rzeczy nie jest błędna sama w sobie i nie ma ustalonych zasad dotyczących nazewnictwa zdarzeń i właściwości, istnieją najlepsze praktyki, których należy rozważyć.
Konwencja nazewnictwa obiektu-akcji stała się w zasadzie standardem branżowym i nie bez powodu — jasno opisuje akcję, która już miała miejsce. Produkt Dodany zdecydowanie oznacza, że po obiekcie (produkt) następuje akcja (dodanie).
Dowiedz się więcej o konfigurowaniu spójnej taksonomii wydarzeń .
Składniki danych o zdarzeniach
Istnieją dwa kluczowe składniki zdarzenia — jednostka (co najmniej jedna) i właściwości zdarzenia.
Powiązanie danych encji, takich jak user_id ze zdarzeniem, dostarcza informacji o użytkowniku, który wykonał zdarzenie.
W przypadku braku unikalnego identyfikatora, takiego jak user_id , dane zdarzenia pozostaną anonimowe i nie będzie możliwości dowiedzenia się, kto je wykonał. Podobnie w kontekście B2B SaaS, gdzie użytkownik może potencjalnie należeć do wielu organizacji, identyfikator Organization_id musi być powiązany ze zdarzeniami, aby wiedzieć, gdzie mają miejsce zdarzenia.
Oprócz encji istnieją inne informacje, które można zebrać w celu analizy i segmentacji, gdy mają miejsce zdarzenia.
Wracając do przykładu z e-commerce, kiedy produkt jest kupowany, oprócz wiedzy o tym, kto dokonał zakupu, musisz także wiedzieć, jaki produkt został kupiony, w jakiej cenie i kiedy .
Te dodatkowe informacje są gromadzone w postaci właściwości zdarzenia .
W pierwszej części tej serii wspomniano, że dane o zdarzeniach składają się z trzech kluczowych elementów:
- Akcja lub wydarzenie, które miało miejsce
- Znacznik czasu lub dokładna data i godzina wydarzenia
- Stan lub wszystkie inne właściwości powiązane ze zdarzeniem (nazywane właściwościami zdarzenia)
Przyjrzyjmy się zdarzeniu Product Added (nazwa we właściwym przypadku zgodnie ze strukturą obiektu-akcji dla zdarzenia Add to Cart ) i załóżmy, że zostało ono wykonane przez użytkownika 1 stycznia 2020 r. o godzinie 10:00 czasu UTC. Dane zebrane podczas wydarzenia obejmują:
- Akcja: Dodano produkt
- Sygnatura czasowa: 1577872800 (sygnatura czasowa Unix dla ABZ 7.99 ( Stan: 0123 ABZ 7,99 ( Jak w tym przykładzie, właściwości skojarzone ze zdarzeniem Dodany produkt to user_id, product_id, price, i ilość , z których każda zawiera więcej informacji o zdarzeniu. Znacznik czasu jest powiązany ze zdarzeniem, aby wiedzieć, kiedy miało ono miejsce.
Przydatne jest również określenie nazwy znacznika czasu, która zasadniczo jest właściwością zdarzenia. Nie jest to obowiązkowe, ponieważ standardową praktyką jest kojarzenie znacznika czasu jako znacznika czasu z każdym zdarzeniem podczas wysyłania danych do narzędzi innych firm; jednak określenie odrębnej nazwy dla właściwości, która przechowuje sygnaturę czasową, może być przydatne na dłuższą metę, gdy trzeba pracować z danymi historycznymi zdarzeń.
Zalecaną taksonomią dla znaczników czasu jest nazwa zdarzenia, po której następuje „at”: product_added_at dla zdarzenia Dodano produkt.
Być może już zauważyłeś, że snake_case jest używane do definiowania właściwości zdarzeń, co ułatwia odróżnienie nazw zdarzeń od właściwości zdarzeń. To powiedziawszy, pamiętaj, że nie ma tutaj wstępnie zdefiniowanych reguł i powinieneś wybrać to, co najlepiej pasuje do Ciebie i Twojego zespołu.
Oto ostateczne spojrzenie na właściwości powiązane ze zdarzeniem Dodano produkt oraz typy danych każdej z tych właściwości:

Określenie typu danych dla każdej właściwości zapewnia spójność danych i ułatwia proces instrumentacji.
Uwaga dodatkowa: warto pamiętać, że Teraz powinno być jasne, że zbieranie danych o zdarzeniach obejmuje następujące kroki:

- Decydowanie, które zdarzenia śledzić
- Nazywanie tych zdarzeń przy użyciu odpowiedniej konwencji nazewnictwa
- Decydowanie, które właściwości powiązać z każdym zdarzeniem
- Nazywanie tych właściwości przy użyciu odpowiedniej konwencji nazewnictwa
Kolejna (i ostatnia) część tej serii obejmuje proces decydowania, które zdarzenia należy śledzić i jakie dane należy zbierać.
Jednak powinieneś dobrze wiedzieć, czego się spodziewać, patrząc na dane o zdarzeniach (w planie śledzenia przed oprzyrządowaniem lub w miejscu docelowym danych, takim jak narzędzie do analizy produktów).
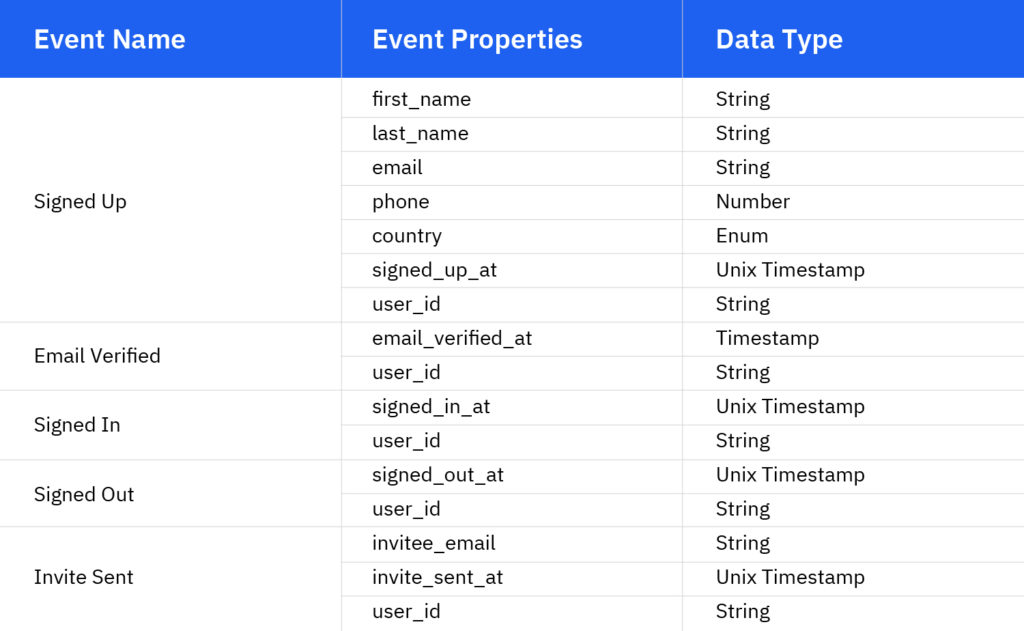
Niektóre typowe zdarzenia i ich właściwości
Zanim przejdziesz dalej, spójrz na kilka typowych zdarzeń i właściwości, które są śledzone przez większość produktów technologicznych.
Typy jednostek
Nadszedł czas, aby dogłębnie przyjrzeć się różnym podmiotom i ich właściwościom. Jeśli jeszcze tego nie zrobiłeś, zapoznaj się z tym przewodnikiem, aby zrozumieć, w jaki sposób dane encji odnoszą się do danych zdarzeń.
W pierwszej części tej serii wspomniano, że dane udostępniane przez użytkowników należą do danych podmiotowych. Chociaż to prawda, nie wszystkie dane encji są udostępniane przez samych użytkowników — można również generować dane encji.
Dane encji obejmują właściwości powiązane z encją – jeśli Użytkownik jest encją, wszystkie informacje o użytkowniku są gromadzone w postaci właściwości użytkownika.
User_id jest domyślnie generowany dla każdego użytkownika w celu identyfikacji użytkowników (i pełni rolę identyfikatora zdarzeń).
To powiedziawszy, na razie zapomnij o wydarzeniach i pomyśl o różnych informacjach, które odnoszą się wyłącznie do użytkowników i mówią o ich cechach.
Rodzaje danych podmiotu
Dane jednostki można podzielić na następujące kategorie (wymienione również w części 3 tej serii):
- Informacje umożliwiające identyfikację , takie jak Dane demograficzne , takie jak Persona , taka jak Preferencje , takie jak Dane specyficzne dla produktu, takie jak Fragmenty danych w każdym zasobniku podlegają właściwościom użytkownika. Innymi słowy, właściwości użytkownika przechowują różne szczegóły i cechy użytkowników, umożliwiając ich identyfikację i dowiedzenie się o nich więcej.
Chociaż większość informacji pochodzi bezpośrednio od użytkownika, niektóre właściwości użytkownika są generowane automatycznie w wyniku korzystania z produktu.
Ale czy dane o zdarzeniach nie są również generowane w związku z użyciem produktu?
Z pewnością tak — właściwości użytkownika to dodatkowe szczegóły związane ze zdarzeniem zebrane, gdy zdarzenie ma miejsce. Rzućmy okiem na wydarzenie Rejestracja i jego właściwości:
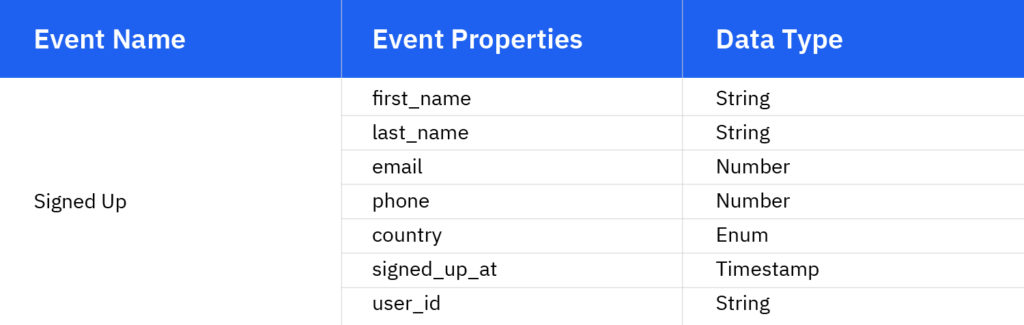
Jak widać, wszystkie właściwości powiązane z tym zdarzeniem zawierają szczegółowe informacje o użytkownikach — szczegóły, które są udostępniane przez samych użytkowników ( imię, nazwisko , e-mail, telefon, kraj ) lub szczegóły generowane automatycznie ( podpis_w_at, identyfikator_użytkownika ).
Warto pamiętać o następujących kwestiach:
- Niektóre zdarzenia, takie jak Rejestracja czy Zweryfikowany Większość właściwości użytkownika z wyłączeniem sygnatur czasowych i identyfikatorów może ulec zmianie. Użytkownik może zmienić swoje imię i nazwisko, adres e-mail, telefon, lokalizację, branżę, stanowisko itp. Jednak czas rejestracji (signed_up_at) lub unikalny identyfikator (user_id) nie może zostać zmieniony przez użytkownika.
Właściwości użytkownika a właściwości organizacji
W przypadku aplikacji konsumenckich czas spędzony, zakupione produkty, odtwarzane utwory lub oglądane filmy są właściwościami powiązanymi z użytkownikiem przechowywanymi jako właściwości użytkownika, których wartości są stale aktualizowane wraz ze wzrostem użycia.
W kontekście B2B SaaS, Użytkownik i Organizacja są głównymi podmiotami, a zebrane zdarzenia są powiązane z użytkownikiem lub organizacją (lub obiema).
Mogą istnieć inne jednostki grupowe, takie jak zespół lub projekt , z powiązanymi z nimi określonymi fragmentami danych, tak jak w przypadku większości narzędzi zwiększających produktywność — proces gromadzenia danych organizacji ma również zastosowanie w takich przypadkach.
Przyjrzyjmy się niektórym typowym właściwościom użytkownika dotyczącym produktów B2B SaaS:
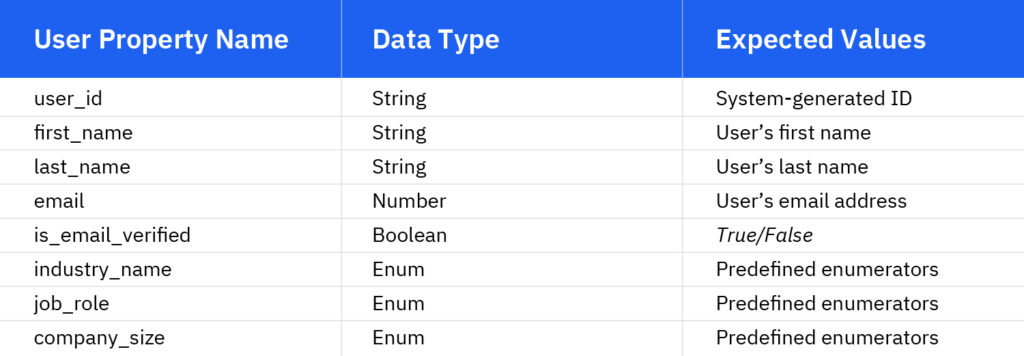
Gdy użytkownik należy do organizacji , wiele ważnych informacji jest powiązanych z organizacją, a nie użytkownikiem.
Niektóre typowe właściwości organizacji (nazywane również właściwościami grupy ) są następujące:
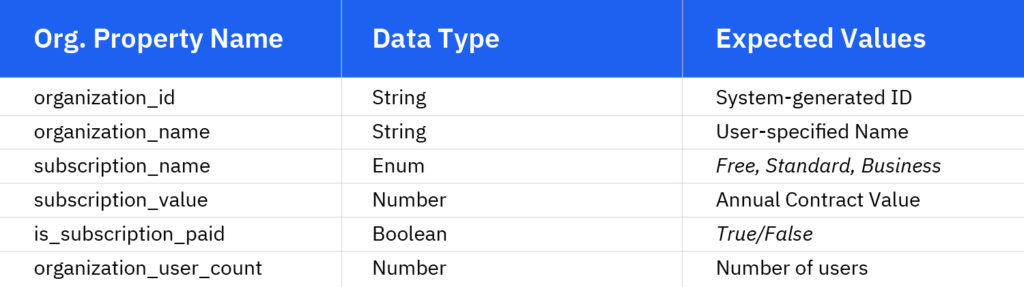
Należy pamiętać, że identyfikator_organizacji działa również jako identyfikator i powinien być powiązany ze zdarzeniami, aby wiedzieć, pod jaką organizacją miało miejsce dane zdarzenie.
Pamiętaj o następujących stwierdzeniach, które mogą pomóc w rozróżnieniu między właściwościami użytkownika a właściwościami organizacji:
- Każda informacja, która pomaga zdefiniować kohorty użytkowników — skąd pochodzą, kim są, jaki jest ich cel lub co robią w produkcie — jest przechowywana jako właściwość użytkownika .
- Każda informacja, która pomaga segmentować konta lub organizacje — typ konta, generowane przez nie przychody, używane produkty lub funkcje, zużywane zasoby lub liczba użytkowników, którzy są jego częścią — jest przechowywana jako właściwość organizacji ( lub grupy własności).
Gdy już rozróżnisz powyższe, łatwo będzie dodać nowe jednostki (takie jak zespoły lub projekty) do miksu.
Następne kroki
Powinieneś teraz dobrze rozumieć, jak definiować zdarzenia i skojarzone z nimi właściwości, a także określać właściwości każdej jednostki (użytkownika i organizacji).
Aby zacząć definiować zdarzenia i organizować swoje dane już dziś, zacznij od bezpłatnego konta Amplitude.
