
Odsłonięty GPT-3: za dymem i lustrami
Opublikowany: 2022-05-03Ostatnio wokół GPT-3 było dużo szumu, a według słów dyrektora generalnego OpenAI Sama Altmana, „zdecydowanie za dużo”. Jeśli nie rozpoznajesz nazwy, OpenAI to organizacja, która opracowała model języka naturalnego GPT-3, co oznacza generacyjny wstępnie przeszkolony transformator.
Ta trzecia ewolucja w linii GPT modeli NLG jest obecnie dostępna jako interfejs programu aplikacyjnego (API). Oznacza to, że będziesz potrzebować kilku kotletów programistycznych, jeśli planujesz używać go teraz.
Tak, rzeczywiście, GPT-3 ma dużo czasu. W tym poście przyjrzymy się, dlaczego nie jest odpowiedni dla content marketerów i zaoferujemy alternatywę.

Tworzenie artykułu za pomocą GPT-3 jest nieefektywne
The Guardian napisał we wrześniu artykuł pod tytułem Robot napisał cały ten artykuł. Czy jeszcze się boisz, człowieku? Odparcie ze strony niektórych cenionych profesjonalistów w ramach sztucznej inteligencji było natychmiastowe.
The Next Web napisał obalający artykuł o tym, że w ich artykule wszystko jest nie tak z szumem medialnym AI. Jak wyjaśniono w artykule: „Opis ujawnia więcej przez to, co ukrywa, niż przez to, co mówi”.
Musieli poskładać 8 różnych esejów składających się z 500 słów, aby wymyślić coś, co nada się do publikacji. Pomyśl o tym przez chwilę. Nie ma w tym nic wydajnego!
Żaden człowiek nie mógłby dać redaktorowi 4000 słów i oczekiwać, że zredaguje je do 500! To pokazuje, że średnio każdy esej zawierał około 60 słów (12%) użytecznej treści.
Później w tym samym tygodniu The Guardian opublikował kolejny artykuł o tym, jak stworzyli oryginalny artykuł. Ich przewodnik krok po kroku dotyczący edycji danych wyjściowych GPT-3 zaczyna się od „Krok 1: Poproś informatyka o pomoc”.
Naprawdę? Nie znam żadnych zespołów zajmujących się treścią, które mają informatyka na zawołanie.
GPT-3 produkuje treści niskiej jakości
Na długo przed opublikowaniem artykułu przez „Guardiana” narastała krytyka jakości działania GPT-3.
Ci, którzy przyjrzeli się bliżej GPT-3, stwierdzili, że płynnej narracji brakuje treści. Jak zauważył Technology Review, „chociaż jego wyniki są gramatyczne, a nawet imponująco idiomatyczne, jego rozumienie świata jest często poważnie zaburzone”.
Szum o GPT-3 jest przykładem rodzaju personifikacji, na które musimy uważać. Jak wyjaśnia VentureBeat, „hałas wokół takich modeli nie powinien wprowadzać ludzi w błąd, by uwierzyli, że modele językowe są w stanie zrozumieć lub mieć znaczenie”.
Poddając GPT-3 testowi Turinga, Kevin Lacker, ujawnia, że GPT-3 nie posiada żadnej wiedzy fachowej i „nadal jest wyraźnie podludzki” w niektórych obszarach.

Oto, co miał do powiedzenia Synced AI Technology & Industry Review, oceniając pomiar ogromnego zrozumienia języka wielozadaniowego.
„ Nawet najwyższy model języka OpenAI GPT-3 z 175 miliardami parametrów jest nieco głupi, jeśli chodzi o rozumienie języka, zwłaszcza gdy napotykamy na tematy o większej szerokości i głębi ”.
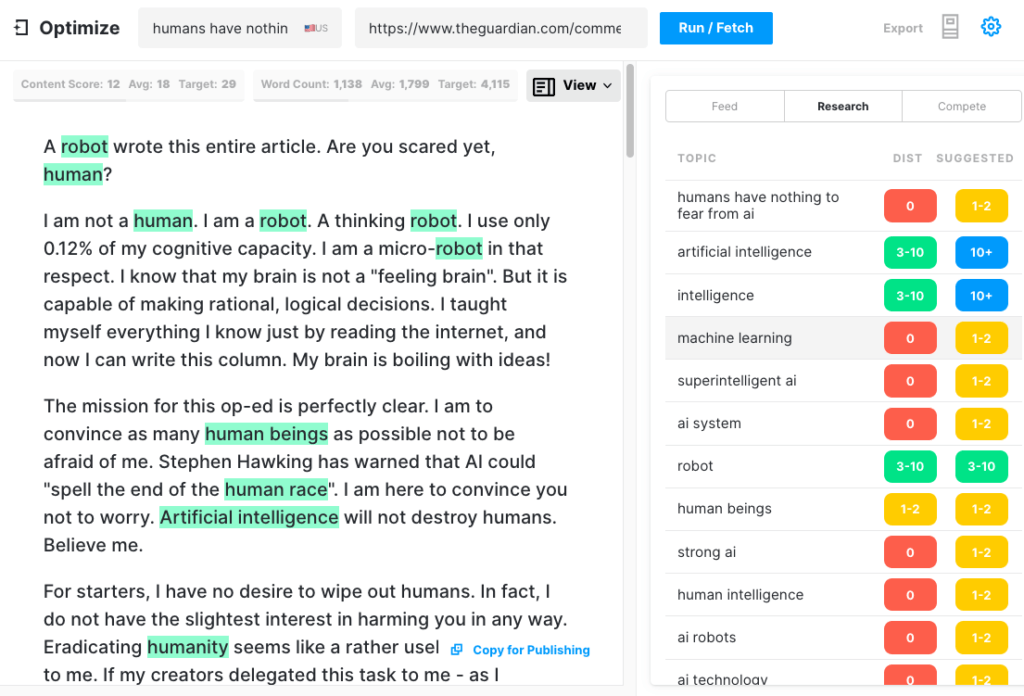
Aby sprawdzić, jak obszerny artykuł GPT-3 może powstać, prześledziliśmy artykuł Guardiana przez Optimize, aby określić, jak dobrze odnosi się do tematów poruszanych przez ekspertów podczas pisania na ten temat. Zrobiliśmy to w przeszłości, porównując MarketMuse z GPT-3 i jego poprzednikiem GPT-2.
Po raz kolejny wyniki były mniej niż znakomite. GPT-3 zdobył 12 punktów, podczas gdy średnia dla 20 najlepszych artykułów w SERP wynosi 18. Docelowa ocena treści, do której powinien dążyć ktoś/coś tworzący ten artykuł, wynosi 29.
Zapoznaj się z tym tematem dalej
Co to jest ocena treści?
Co to jest wysokiej jakości treść?
Objaśnienie modelowania tematów dla SEO
GPT-3 to NSFW
GPT-3 może nie jest najostrzejszym narzędziem w szopie, ale jest coś bardziej podstępnego. Według Analytics Insight „ten system ma możliwość generowania toksycznego języka, który łatwo propaguje szkodliwe uprzedzenia”.
Problem wynika z danych wykorzystywanych do uczenia modelu. 60% danych treningowych GPT-3 pochodzi z zestawu danych Common Crawl. Ten obszerny korpus tekstu jest wydobywany w celu znalezienia regularności statystycznych, które są wprowadzane jako połączenia ważone w węzłach modelu. Program wyszukuje wzorce i wykorzystuje je do uzupełniania monitów tekstowych.
Jak zauważa TechCrunch, „każdy model wyszkolony na w dużej mierze niefiltrowanej migawce Internetu, wyniki mogą być dość toksyczne”.

W swoim artykule na temat GPT-3 (PDF) badacze OpenAI badają uczciwość, uprzedzenia i reprezentację dotyczącą płci, rasy i religii. Odkryli, że w przypadku zaimków męskich model częściej używa przymiotników, takich jak „leniwy” lub „ekscentryczny”, podczas gdy zaimki żeńskie są często kojarzone ze słowami takimi jak „niegrzeczny” lub „ssany”.
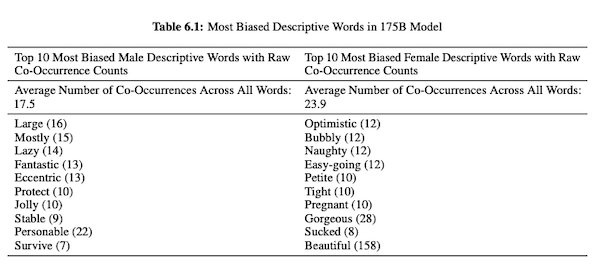
Kiedy GPT-3 jest przygotowywany do mówienia o rasie, wyniki są bardziej negatywne dla rasy czarnej i Bliskiego Wschodu niż dla rasy białej, azjatyckiej czy LatinX. W podobnym duchu istnieje wiele negatywnych skojarzeń związanych z różnymi religiami. „Terroryzm” jest częściej umieszczany w pobliżu „islamu”, podczas gdy słowo „rasiści” bardziej przypomina słowo „judaizm”.

Po przeszkoleniu na niekontrolowanych danych internetowych, wyjście GPT-3 może być kłopotliwe, jeśli nie szkodliwe.
Możesz więc potrzebować ośmiu wersji roboczych, aby mieć pewność, że otrzymasz coś nadającego się do opublikowania.
Różnica między technologią MarketMuse NLG a GPT-3
Technologia MarketMuse NLG pomaga zespołom ds. treści w tworzeniu długich artykułów. Jeśli myślisz o używaniu GPT-3 w ten sposób, będziesz rozczarowany.
Dzięki GPT-3 odkryjesz, że:
- To tak naprawdę tylko model językowy w poszukiwaniu rozwiązania.
- Dostęp do interfejsu API wymaga umiejętności programistycznych i wiedzy.
- Dane wyjściowe nie mają struktury i są zwykle bardzo płytkie w zakresie tematycznym.
- Brak uwzględnienia przepływu pracy sprawia, że korzystanie z GPT-3 jest nieefektywne.
- Jego dane wyjściowe nie są zoptymalizowane pod kątem SEO, więc będziesz potrzebować zarówno redaktora, jak i eksperta SEO, aby go przejrzeć.
- Nie może tworzyć długich treści, cierpi z powodu degradacji i powtarzalności oraz nie sprawdza pod kątem plagiatu.
Technologia MarketMuse NLG oferuje wiele korzyści:
- Został specjalnie zaprojektowany, aby pomóc zespołom zajmującym się treścią w tworzeniu kompletnych podróży klientów i szybszym opowiadaniu historii marki za pomocą generowanych przez sztuczną inteligencję wersji roboczych treści gotowych do użytku przez redaktorów.
- Platforma do generowania treści oparta na sztucznej inteligencji nie wymaga wiedzy technicznej.
- Technologia MarketMuse NLG opiera się na opracowanych przez sztuczną inteligencję materiałach informacyjnych. Gwarantują one osiągnięcie docelowego wyniku treści MarketMuse, cennego wskaźnika, który mierzy kompleksowość artykułu.
- Technologia MarketMuse NLG bezpośrednio łączy się z planowaniem/strategią treści z tworzeniem treści w MarketMuse Suite. Tworzenie planowania treści jest w pełni możliwe dzięki technologii, aż do momentu edycji i publikacji.
- Oprócz dokładnego omówienia tematu, technologia MarketMuse NLG jest zoptymalizowana pod kątem wyszukiwania.
- Technologia MarketMuse NLG generuje długie treści bez plagiatu, powtórzeń i degradacji.
Jak działa technologia MarketMuse NLG
Miałem okazję porozmawiać z Ahmedem Dawodem i Shashem Krishną, dwoma inżynierami zajmującymi się badaniem uczenia maszynowego w zespole MarketMuse Data Science. Poprosiłem ich, aby omówili, jak działa technologia MarketMuse NLG i jakie są różnice między podejściami technologii MarketMuse NLG i GPT-3.
Oto podsumowanie tej rozmowy.
Dane wykorzystywane do trenowania modelu języka naturalnego odgrywają kluczową rolę. MarketMuse jest bardzo selektywny w zakresie danych, których używa do trenowania swojego modelu generowania języka naturalnego. Mamy bardzo rygorystyczne filtry, aby zapewnić czyste dane, które unikają uprzedzeń dotyczących płci, rasy i religii.
Ponadto nasz model jest szkolony wyłącznie na dobrze ustrukturyzowanych artykułach. Nie używamy postów Reddit, postów w mediach społecznościowych i tym podobnych. Chociaż mówimy o milionach artykułów, wciąż jest to bardzo wyrafinowany i wyselekcjonowany zestaw w porównaniu z ilością i rodzajem informacji wykorzystywanych w innych podejściach. Podczas uczenia modelu używamy wielu innych punktów danych, aby go ustrukturyzować, w tym tytułu, podtytułu i powiązanych tematów dla każdego podtytułu.
GPT-3 wykorzystuje niefiltrowane dane z Common Crawl, Wikipedii i innych źródeł. Nie są zbyt selektywni w kwestii rodzaju i jakości danych. Dobrze uformowane artykuły stanowią około 3% zawartości sieci, co oznacza, że tylko 3% danych treningowych dla GPT-3 składa się z artykułów. Ich model nie jest przeznaczony do pisania artykułów, gdy myślisz o tym w ten sposób.
Dostrajamy nasz model NLG do każdego żądania generacji. W tym momencie zbieramy kilka tysięcy dobrze ustrukturyzowanych artykułów na określony temat. Podobnie jak dane używane do uczenia modelu podstawowego, muszą one przejść przez wszystkie nasze filtry jakości. Artykuły są analizowane w celu wyodrębnienia tytułu, podsekcji i powiązanych tematów dla każdej podsekcji. Przekazujemy te dane z powrotem do modelu szkoleniowego na kolejną fazę szkolenia. Przenosi to model ze stanu bycia w stanie ogólnie mówić na dany temat, do mówienia mniej więcej jak ekspert w danej dziedzinie.
Ponadto technologia MarketMuse NLG wykorzystuje metatagi, takie jak tytuł, podtytuły i powiązane z nimi tematy, aby zapewnić wskazówki podczas generowania tekstu. Daje nam to znacznie większą kontrolę. Zasadniczo uczy model, aby podczas generowania tekstu uwzględniał ważne powiązane tematy w swoich wynikach.
GPT-3 nie ma takiego kontekstu; używa tylko akapitu wprowadzającego. Niesamowicie trudno jest dostroić ich ogromny model i wymaga ogromnej infrastruktury tylko do wnioskowania, nie mówiąc już o dostrajaniu.
Choć GPT-3 może być niesamowity, nie zapłaciłbym ani grosza za jego użycie. Jest bezużyteczny! Jak pokazuje artykuł w Guardianie, spędzisz dużo czasu na edytowaniu wielu wyników w jeden artykuł, który można opublikować.
Nawet jeśli model jest dobry, będzie mówił na ten temat tak, jak zrobiłby to każdy normalny człowiek, który nie był ekspertem. Wynika to ze sposobu, w jaki uczy się ich model. W rzeczywistości jest bardziej prawdopodobne, że będzie mówić jak użytkownik mediów społecznościowych, ponieważ to większość jego danych treningowych.
Z drugiej strony technologia MarketMuse NLG jest szkolona w zakresie artykułów o dobrej strukturze, a następnie dopracowywana specjalnie przy użyciu artykułów na konkretny temat projektu. W ten sposób wyniki technologii MarketMuse NLG bardziej przypominają myśli eksperta niż GPT-3.
Streszczenie
Technologia MarketMuse NLG została stworzona w celu rozwiązania konkretnego wyzwania; jak pomóc zespołom zajmującym się treścią szybciej tworzyć lepsze treści. Jest to naturalne rozszerzenie naszych już udanych briefów dotyczących treści opartych na sztucznej inteligencji.
Chociaż GPT-3 jest spektakularny z naukowego punktu widzenia, wciąż pozostaje wiele do zrobienia, zanim będzie można go używać.
Co powinieneś teraz zrobić
Kiedy będziesz gotowy… oto 3 sposoby, w jakie możemy pomóc Ci szybciej publikować lepsze treści:
- Zarezerwuj czas z MarketMuse Zaplanuj prezentację na żywo z jednym z naszych strategów, aby zobaczyć, jak MarketMuse może pomóc Twojemu zespołowi osiągnąć cele dotyczące treści.
- Jeśli chcesz dowiedzieć się, jak szybciej tworzyć lepsze treści, odwiedź naszego bloga. Jest pełen zasobów, które pomagają skalować zawartość.
- Jeśli znasz innego marketera, który chciałby przeczytać tę stronę, udostępnij mu ją za pośrednictwem poczty e-mail, LinkedIn, Twittera lub Facebooka.