
Jak korzystać z NLP w marketingu treści
Opublikowany: 2022-05-02Chris Penn, współzałożyciel Trust Insights oraz współzałożyciel i dyrektor ds. produktów w MarketMuse, Jeff Coyle, omawiają uzasadnienie biznesowe dotyczące sztucznej inteligencji w marketingu. Po seminarium internetowym Paul wziął udział w sesji „zapytaj mnie o cokolwiek” w naszej społeczności Slack, The Content Strategy Collective (dołącz tutaj). Oto notatki z webinaru, po których następuje transkrypcja AMA.

Webinarium
Problem
Wraz z eksplozją treści mamy nowych pośredników. Nie są dziennikarzami ani influencerami w mediach społecznościowych. Są algorytmami; modele uczenia maszynowego, które dyktują wszystko, co stoi między Tobą a Twoimi odbiorcami.
Nie uwzględnij tego, a Twoje treści będą nadal pogrążone w mroku.
Rozwiązanie: przetwarzanie języka naturalnego
NLP to programowanie komputerów do przetwarzania i analizowania dużych ilości danych w języku naturalnym. Pochodzi z dokumentów, chatbotów, postów w mediach społecznościowych, stron w Twojej witrynie i wszystkiego innego, co jest zasadniczo stosem słów. NLP oparte na regułach było pierwsze, ale zostało zastąpione przez statystyczne przetwarzanie języka naturalnego.
Jak działa NLP
Trzy podstawowe zadania przetwarzania języka naturalnego to rozpoznawanie, rozumienie i generowanie.
Rozpoznawanie — komputery nie mogą przetwarzać tekstu jak ludzie. Mogą czytać tylko liczby. Pierwszym krokiem jest więc konwersja języka do formatu zrozumiałego dla komputera.
Zrozumienie — reprezentowanie tekstu jako liczb umożliwia algorytmom przeprowadzanie analizy statystycznej w celu określenia, które tematy są najczęściej wymieniane razem.
Generowanie – Po analizie i zrozumieniu matematycznym następnym logicznym krokiem w NLP jest generowanie tekstu. Maszyny można wykorzystać do sformułowania pytań, na które pisarz musi odpowiedzieć w ich treści. Na innym poziomie sztuczna inteligencja może generować briefy dotyczące treści, które zapewniają dodatkowy wgląd w tworzenie treści na poziomie eksperckim.
Narzędzia te są obecnie dostępne na rynku za pośrednictwem MarketMuse. Poza tym są modele generowania języka naturalnego, z którymi można się dziś bawić, ale nie są one w komercyjnej formie. Chociaż technologia MarketMuse NLG pojawi się już wkrótce.
Wspomniane dodatkowe zasoby
- przytulanie.co
- Pyton
- R
- Colab
- IBM Watson Studio

AMA
Czy masz jakieś artykuły lub rekomendacje dotyczące stron internetowych, aby nadążyć za trendami w branży AI?
Przeczytaj opublikowane tam badania naukowe. Wszystkie takie witryny świetnie sobie radzą z najnowszymi i najlepszymi.
- KDNuggets.com
- W kierunku nauki o danych
- Kaggle
To i główne ośrodki publikacji naukowych na Facebooku, Google, IBM, Microsoft i Amazon. Zobaczysz mnóstwo wspaniałych materiałów udostępnionych na tych stronach.
„Używam narzędzia do sprawdzania gęstości słów kluczowych dla wszystkich moich treści. Jak daleko jest to od bycia rozsądną strategią dzisiaj dla SEO?”
Gęstość słów kluczowych jest zasadniczo terminem zliczania częstotliwości. Ma swoje miejsce na zrozumienie bardzo surowej natury tekstu, ale brakuje mu jakiejkolwiek wiedzy semantycznej. Jeśli nie masz dostępu do narzędzi NLP, spójrz przynajmniej na treści typu „ludzie też szukali” w wybranym przez siebie narzędziu SEO.
Czy mógłbyś podać kilka konkretnych przykładów, w jaki sposób generujesz treści na… stronach internetowych? Posty? tweety?
Wyzwanie polega na tym, że te narzędzia są dokładnie tym – są narzędziami. To jak, jak zoperacjonalizować szpatułkę? To zależy od tego, co gotujesz. Możesz go użyć do mieszania zupy, a także przewracania naleśników. Sposób, w jaki możesz zacząć korzystać z tej wiedzy, zależy od Twojego poziomu umiejętności technicznych. Jeśli na przykład znasz się na notatnikach Python i Jupyter, możesz dosłownie zaimportować bibliotekę transformatorów, wprowadzić plik tekstowy do szkolenia i natychmiast rozpocząć generowanie. Zrobiłem to z tweetami pewnego polityka i zaczął wypluwać tweety, które rozpoczęły trzecią wojnę światową. Jeśli nie czujesz się komfortowo technicznie, zacznij szukać narzędzi takich jak MarketMuse. Pozwolę Jeffowi Coyle'owi zasugerować, jak zaczyna tam przeciętny marketer.
Jeśli spojrzysz poza narzędzia, ale bardziej na strategie, jaki może być przykład strategii, którą możesz wdrożyć, aby wykorzystać tę wiedzę?
Kilka szybkich trafień dotyczy takich rzeczy, jak metaopisy, klasyfikowanie stron lub bloków treści w taksonomię lub próba odgadnięcia pytań, które wymagają odpowiedzi – ale to naprawdę punktowe rozwiązania. Większa mądrość strategiczna pojawia się, gdy używasz tego, aby pokazać swoje obecne mocne strony, swoje luki i gdzie masz rozpęd. Od tego momentu podejmowanie decyzji o tym, co tworzyć, aktualizować, rozszerzać, staje się przełomowe dla firmy. Teraz wyobraź sobie, że robisz to samo przeciwko konkurentowi. Znajdowanie ich luk. spienić, spłukać, powtórzyć.
Strategia jest zawsze oparta na celu. Jaki cel próbujesz osiągnąć? Czy przyciągasz ruch w sieci wyszukiwania? Czy zajmujesz się generowaniem leadów? Zajmujesz się PR? NLP to zestaw narzędzi. Podobnie jak – strategia to menu. Podajesz śniadanie, obiad lub kolację? To, jakich narzędzi i przepisów użyjesz, będzie w dużym stopniu zależne od menu, które serwujesz. Garnek do zupy będzie całkowicie nieprzydatny, jeśli robisz spanakopita.
Jaki jest dobry punkt wyjścia dla kogoś, kto chce rozpocząć eksplorację danych w celu uzyskania wglądu?
Zacznij od metody naukowej.
- Na jakie pytanie chcesz odpowiedzieć?
- Jakich danych, procesów i narzędzi potrzebujesz, aby odpowiedzieć na to pytanie?
- Sformułuj hipotezę, jedno-warunkowe, dające się udowodnić prawdziwe lub fałszywe stwierdzenie, które możesz przetestować.
- Test.
- Przeanalizuj swoje dane testowe.
- Doprecyzuj lub odrzuć hipotezę.
W przypadku samych danych skorzystaj z naszej struktury danych 6C, aby ocenić jakość danych.
Jakie są, Twoim zdaniem, główne intencje użytkowników wyszukiwania, które marketerzy powinni wziąć pod uwagę?
Kroki na ścieżce klienta. Zaplanuj doświadczenie klienta od początku do końca – świadomość, rozważenie, zaangażowanie, zakup, własność, lojalność, ewangelizacja. Następnie zaplanuj, jakie prawdopodobnie będą intencje na każdym etapie. Na przykład w przypadku właściciela zamiary wyszukiwania z dużym prawdopodobieństwem są zorientowane na usługi. Przykładem jest „Jak naprawić trzaski w airpodach pro”. Wyzwaniem jest zbieranie danych na każdym etapie podróży i wykorzystywanie ich do trenowania/dostrajania.
Nie sądzisz, że może to być nieco niestabilne? Jeśli potrzebujemy czegoś bardziej stabilnego, aby zautomatyzować proces, musimy uogólnić rzeczy na wyższym poziomie.
Jeff Bezos powiedział, że skup się na tym, co się nie zmienia. Ogólna droga do posiadania nie zmienia się zbytnio – ktoś niezadowolony ze swojej paczki gumy do żucia doświadczy podobnych rzeczy, jak ktoś niezadowolony z nowego lotniskowca nuklearnego, który zamówił. Z pewnością szczegóły się zmieniają, ale zrozumienie, jakie rodzaje danych i intencji jest niezbędne, aby wiedzieć, gdzie ktoś jest emocjonalnie w podróży – i jak to przekazuje w języku.
W jakie pułapki prawdopodobnie wpadną ludzie, próbując przeprowadzić klasyfikację intencji użytkownika?
Zdecydowanie błąd potwierdzenia. Ludzie będą projektować własne założenia na doświadczenie klienta i interpretować dane klientów poprzez własne uprzedzenia. Sugerowałbym również, aby w miarę możliwości wykorzystywać dane dotyczące interakcji (otwarte wiadomości e-mail, stopy w drzwiach, telefony do call center itp.) w celu ich weryfikacji. Wiem, że niektóre miejsca, zwłaszcza większe organizacje, są wielkimi fanami modelowania ustrukturyzowanych równań, aby zrozumieć intencje użytkownika. Nie byłem takim fanem jak oni, ale to dodatkowe potencjalne podejście.
Jakie narzędzia lub produkty Twoim zdaniem dobrze sprawdzają się w określaniu intencji użytkownika w zapytaniu?
Wątek. Poza MarketMuse? Szczerze mówiąc, musiałem pracować z własnymi rzeczami, ponieważ nie znalazłem świetnych wyników, zwłaszcza z głównych narzędzi SEO. FastText do wektoryzacji, a następnie niestrukturalnego grupowania.
Z Twojego doświadczenia wynika, jak BERT zmienił wyszukiwarkę Google?
Głównym wkładem BERT jest kontekst, zwłaszcza modyfikatory. BERT pozwala Google zobaczyć kolejność słów i zinterpretować znaczenie. Wcześniej te dwa zapytania mogą być funkcjonalnie równoważne w modelu stylu torby słów:
- gdzie jest najlepsza kawiarnia
- gdzie jest najlepsze miejsce na zakupy na kawę?
Te dwa zapytania, choć bardzo podobne, mogą mieć drastycznie różne wyniki. Kawiarnia może nie być miejscem, w którym chcesz kupić ziarna. Walmart ZDECYDOWANIE nie jest miejscem, w którym chcesz pić kawę.
Czy myślisz, że sztuczna inteligencja lub ICT kiedykolwiek rozwiną świadomość/emocje/empatię jak ludzie? Jak je zaprogramujemy? Jak możemy uczłowieczyć sztuczną inteligencję?
Odpowiedź na to pytanie zależy od tego, co dzieje się z obliczeniami kwantowymi. Kwant pozwala na zmienne stany rozmyte i masowo równoległe przetwarzanie, które naśladuje to, co dzieje się w naszych mózgach. Twój mózg jest bardzo powolnym, masywnym procesorem równoległym opartym na chemikaliach. Jest naprawdę dobry w robieniu wielu rzeczy na raz, jeśli nie szybko. Kwant pozwoli komputerom robić to samo, ale znacznie, znacznie szybciej – a to otwiera drzwi do sztucznej ogólnej inteligencji. Oto moja troska, i to jest troska o sztuczną inteligencję już dziś, w wąskim użyciu: szkolimy ich w oparciu o nas. Ludzkość nie wykonała dobrej roboty, dobrze lecząc siebie lub planetę, na której żyjemy. Nie chcemy, żeby nasze komputery to naśladowały.
Podejrzewam, że na tyle, na ile pozwalają na to systemy, emocje komputerowe będą funkcjonalnie bardzo różne od naszych i będą się samoorganizować na podstawie ich danych, tak jak nasze emocje z naszych sieci neuronowych opartych na chemii. To z kolei oznacza, że mogą czuć się zupełnie inaczej niż my. Jeśli maszyny, oparte głównie na logice i danych, dokonują szczerej, obiektywnej oceny ludzkości, mogą stwierdzić, że szczerze mówiąc, sprawiamy więcej kłopotów, niż jesteśmy warci. I szczerze mówiąc, nie byliby w błędzie. Jako gatunek jesteśmy przez większość czasu barbarzyńskim bałaganem.
Twoim zdaniem, jak postrzegasz content marketerów integrujących/adoptujących Generowanie Języka Naturalnego do swoich codziennych przepływów pracy/procesów?
Marketerzy powinni już integrować jakąś formę tego, nawet jeśli jest to tylko odpowiadanie na pytania, takie jak pokazaliśmy w produkcie MarketMuse. Odpowiadanie na pytania, na których zależy widzom, to szybki i łatwy sposób na tworzenie sensownych treści. Mój przyjaciel Marcus Sheridan napisał świetną książkę „Pytają, ty odpowiadasz”, której, jak na ironię, nie musisz czytać, aby zrozumieć podstawową strategię dotyczącą klienta: odpowiadać na pytania innych. Jeśli nie masz jeszcze pytań przesłanych przez prawdziwych ludzi, użyj NLG, aby je zadać.
Jak widzisz rozwój AI i NLP w ciągu najbliższych 2 lat?
Gdybym o tym wiedział, nie byłoby mnie tutaj, ponieważ byłbym w twierdzy na szczycie góry, którą kupiłem za swoje zarobki. Ale z całą powagą, głównym punktem zwrotnym, jaki widzieliśmy w ciągu ostatnich 2 lat, i który nie wykazuje żadnych zmian, jest przejście od „wgrywania własnych” modeli do „pobierania wstępnie wytrenowanych i dopracowywania”. Myślę, że czeka nas kilka ekscytujących czasów w wideo i audio, ponieważ maszyny stają się coraz lepsze w syntezie. Zwłaszcza generowanie muzyki jest DOJRZAŁE do automatyzacji; obecnie maszyny generują całkowicie przeciętną muzykę w najlepszym razie, a w najgorszym – owrzodzenia uszu. To się szybko zmienia. Widzę więcej przykładów, takich jak łączenie transformatorów i autokoderów razem, tak jak zrobił to BART, jako główne kolejne kroki w rozwoju modelu i najnowocześniejszych wynikach.

Gdzie widzisz nagłówek badań Google w zakresie wyszukiwania informacji?
Wyzwaniem, przed którym wciąż stoi Google, i widać to w wielu swoich artykułach naukowych, jest skala. Są szczególnie kwestionowani z takimi rzeczami jak YouTube; fakt, że nadal w dużym stopniu polegają na bigramach, nie jest uszczerbkiem na ich wyrafinowaniu, jest to potwierdzenie, że cokolwiek więcej ma szalony koszt obliczeniowy. Wszelkie znaczące przełomy z nich nie będą dotyczyć poziomu modeli, ale skali, aby poradzić sobie z zalewem nowych, bogatych treści, które każdego dnia wlewają się do Internetu.
Jakie są niektóre z najciekawszych zastosowań sztucznej inteligencji, z którymi się spotkałeś?
Wszystko autonomiczne to obszar, który uważnie obserwuję. Podobnie głębokie podróbki. Są to przykłady tego, jak niebezpieczna jest droga przed nami, jeśli nie będziemy ostrożni. W szczególności w NLP pokolenie robi szybkie postępy i jest obszarem do obserwacji.
Gdzie widziałeś, jak SEO używa NLP w sposób, który nie działa lub nie działa?
Straciłem rachubę. Przez większość czasu ludzie używają narzędzia w sposób niezgodny z przeznaczeniem i uzyskują słabe wyniki. Jak wspomnieliśmy na webinarze, istnieją karty wyników dla różnych najnowocześniejszych testów modeli, a ludzie, którzy używają narzędzia w obszarze, w którym nie jest to mocne narzędzie, zazwyczaj nie cieszą się z wyników. To powiedziawszy… większość praktyków SEO nie używa żadnego rodzaju NLP poza tym, co oferują im dostawcy, a wielu dostawców wciąż utknęło w 2015 roku. To wszystko listy słów kluczowych, cały czas.
Gdzie widzisz wideo (YouTube) i wyszukiwanie grafiki w Google? Czy uważasz, że technologie wdrożone przez Google używane do wszystkich typów wyszukiwań są bardzo podobne lub różnią się od siebie?
Wszystkie technologie Google są oparte na ich infrastrukturze i wykorzystują ich technologię. Tak wiele jest zbudowanych na TensorFlow i nie bez powodu — jest super solidny i skalowalny. Różnice polegają na tym, jak Google korzysta z różnych narzędzi. TensorFlow do rozpoznawania obrazów z natury ma bardzo różne dane wejściowe i warstwy niż TensorFlow do porównywania w parach i przetwarzania języka. Ale jeśli wiesz, jak korzystać z TensorFlow i różnych modeli, możesz samodzielnie osiągnąć całkiem fajne rzeczy.
W jaki sposób możemy dostosować/nadążyć za postępami w AI i NLP?
Czytaj dalej, badaj i testuj. Nic nie zastąpi ubrudzenia sobie rąk, przynajmniej trochę. Załóż bezpłatne konto Google Colab i wypróbuj różne rzeczy. Naucz się trochę Pythona. Skopiuj i wklej przykłady kodu z przepełnienia stosu. Nie musisz znać każdego wewnętrznego działania silnika spalinowego, aby prowadzić samochód, ale kiedy coś pójdzie nie tak, odrobina wiedzy zajdzie daleko. To samo dotyczy AI i NLP – nawet możliwość wezwania dostawcy do BS jest cenną umiejętnością. To jeden z powodów, dla których lubię pracować z ludźmi z MarketMuse. Właściwie wiedzą, co robią, a ich praca nad sztuczną inteligencją nie jest BS.
Co powiedziałbyś ludziom, którzy martwią się, że sztuczna inteligencja zabierze im pracę? Na przykład pisarze, którzy widzą technologię taką jak NLG i martwią się, że będą bez pracy, jeśli sztuczna inteligencja może być „wystarczająco dobra”, aby redaktor po prostu trochę uporządkował tekst.
„AI zastąpi zadania, a nie miejsca pracy” – Brookings Institute I to absolutnie prawda. Ale miejsca pracy netto zostaną utracone, ponieważ oto, co się stanie. Załóżmy, że twoja praca składa się z 50 zadań. AI robi 30 z nich. Świetnie, masz teraz 20 zadań. Jeśli jesteś jedyną osobą, która to robi, to jesteś w nirwanie, ponieważ masz 30 jednostek czasu więcej na ciekawszą, zabawniejszą pracę. To właśnie obiecują optymiści AI. Sprawdzenie rzeczywistości: jeśli 5 osób wykonuje te 50 jednostek, a AI 30, to AI wykonuje teraz 150/250 jednostek pracy. Oznacza to, że pozostało 100 jednostek pracy dla ludzi, a korporacje, które są tym, czym są, natychmiast zmniejszą 3 stanowiska, ponieważ 100 jednostek pracy mogą wykonać 2 osoby. Czy powinieneś się martwić, że AI zajmie pracę? To zależy od pracy. Jeśli praca, którą wykonujesz, jest niewiarygodnie powtarzalna, absolutnie się martw. W mojej starej agencji był biedny drań, którego zadaniem było kopiowanie i wklejanie wyników wyszukiwania do arkusza kalkulacyjnego dla klientów (pracowałem w firmie PR, niezbyt zaawansowanym technologicznie miejscu) 8 godzin dziennie. Ta praca jest w bezpośrednim niebezpieczeństwie i szczerze mówiąc powinna być przez lata. Powtarzanie = automatyzacja = AI = utrata zadań. Im mniej powtarzalna jest Twoja praca, tym bezpieczniejszy jesteś.
Każda zmiana powodowała także coraz większe nierówności dochodowe. Jesteśmy teraz w niebezpiecznym punkcie, w którym maszyny – które nie wydają, nie są konsumentami – wykonują coraz więcej pracy ludzi, którzy wydają, którzy konsumują, i widzimy to w ogromnej dominacji bogactwa w technologii. To problem społeczny, z którym będziemy musieli się w pewnym momencie uporać.
A wyzwaniem z tym jest postęp, to władza. Jak napisał Robert Ingersoll (i później błędnie przypisywano go Abrahamowi Lincolnowi): „Prawie wszyscy ludzie mogą znosić przeciwności losu, ale jeśli chcesz sprawdzić charakter człowieka, daj mu władzę”. Widzimy, jak ludzie dzisiaj radzą sobie z władzą.
Jak mogę sparować dane Google Analytics z NLP Research?
GA wskazuje kierunek, a następnie NLP wskazuje tworzenie. Co jest popularne? Przed chwilą zrobiłem to dla klienta. Mają tysiące stron internetowych i sesji czatów. Użyliśmy GA do przeanalizowania, które kategorie rozwijały się najszybciej w ich witrynie, a następnie wykorzystaliśmy NLP do przetworzenia tych dzienników czatów, aby pokazać im, co jest trendy i czego potrzebowali do tworzenia treści.
Google Analytics świetnie informuje nas, CO się wydarzyło. NLP może zacząć wyjaśniać trochę DLACZEGO, a następnie uzupełniamy to badaniem rynku.
Widziałem, jak używałeś Talkwalkera jako źródła danych w wielu swoich badaniach. Jakie inne źródła i przypadki użycia należy wziąć pod uwagę do analizy?
Tak wielu. Data.gov. Talkwalker. MarketMuse. Otter.ai do transkrypcji dźwięku. Jądra Kaggle. Wyszukiwarka danych Google – która notabene jest ZŁOTA i jeśli jej nie używasz, to zdecydowanie powinieneś nią być. Wiadomości Google i GDELT. Istnieje tak wiele wspaniałych źródeł.
Jak wygląda dla Ciebie idealna współpraca między zespołem ds. marketingu i analityki danych?
Nie żartuję; jednym z największych błędów, które z Katie Robbert widzimy cały czas u klientów, są silosy organizacyjne. Lewa ręka nie ma pojęcia, co robi prawa ręka, i wszędzie panuje gorący bałagan. Spotkanie ludzi, dzielenie się pomysłami, dzielenie się listami rzeczy do zrobienia, wspólne działania, uczenie się nawzajem – funkcjonalnie bycie „jednym zespołem, jedno marzenie” to idealna współpraca, do punktu, w którym nie trzeba już używać słowa „współpraca” . Ludzie po prostu pracują razem i wykorzystują wszystkie swoje umiejętności do stołu.
Czy możesz przejrzeć raport MVP, którego często przeglądasz w swoich prezentacjach i jak to działa?
Raport MVP oznacza najbardziej wartościowe strony. Sposób, w jaki to działa, polega na wyodrębnieniu danych o ścieżce z Google Analytics, zsekwencjonowaniu ich, a następnie poddaniu ich przez model łańcucha Markowa, aby ustalić, które strony z największym prawdopodobieństwem wspomagają konwersje.
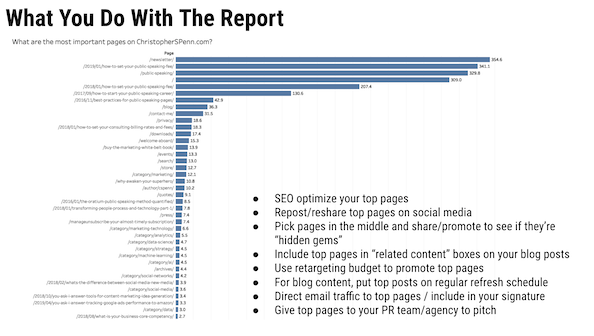
A jeśli chcesz dłuższego wyjaśnienia.
Czy możesz podać więcej informacji na temat stronniczości danych? Jakie kwestie należy wziąć pod uwagę podczas budowania modeli NLP lub NLG?
O tak. Jest tu tyle do powiedzenia. Najpierw musimy ustalić, czym jest uprzedzenie, ponieważ istnieją dwa podstawowe rodzaje.
Powszechnie przyjmuje się, że ludzkie uprzedzenie definiuje się jako „Uprzedzenie na korzyść lub przeciwko czemuś w porównaniu z innym, zwykle w sposób uważany za niesprawiedliwy”.
Następnie istnieje błąd matematyczny, ogólnie przyjęty jako „statystyka jest stronnicza, jeśli jest obliczana w taki sposób, że systematycznie różni się od szacowanego parametru populacji”.
Są różne, ale powiązane. Matematyczne nastawienie niekoniecznie jest złe; na przykład absolutnie chcesz być stronniczy na korzyść swoich najbardziej lojalnych klientów, jeśli masz jakiekolwiek wyczucie biznesowe. Stronniczość człowieka jest domyślnie zła w sensie niesprawiedliwości, zwłaszcza wobec wszystkiego, co jest uważane za klasę chronioną: wiek, płeć, orientacja seksualna, tożsamość płciowa, rasa/pochodzenie etniczne, status weterana, niepełnosprawność itp. To są klasy, których NIE WOLNO dyskryminować.
Uprzedzenie człowieka rodzi stronniczość danych, zwykle w 6 miejscach: ludzie, strategia, dane, algorytmy, modele i działania. Zatrudniamy stronniczych ludzi – wystarczy spojrzeć na kadrę kierowniczą lub zarząd firmy, aby ustalić, jakie są jej uprzedzenia. Pewnego dnia widziałem agencję PR reklamującą swoje zaangażowanie w różnorodność i jedno kliknięcie do zespołu wykonawczego, a wszyscy są jedną grupą etniczną, wszyscy 15.
Mógłbym poświęcić trochę czasu na ten temat, ale sugeruję, abyś wziął udział w opracowanym przeze mnie kursie na ten temat w Marketing AI Institute. W przypadku modeli NLG i NLP musimy zrobić kilka rzeczy.
Najpierw musimy zweryfikować nasze dane. Czy jest w tym uprzedzenie, a jeśli tak, czy dyskryminuje klasę chronioną? Po drugie, jeśli jest dyskryminujący, czy można go złagodzić, czy też musimy wyrzucić dane?
Powszechną taktyką jest zamiana metadanych na debia. Jeśli masz na przykład zestaw danych, który zawiera 60% mężczyzn i 40% kobiet, przekodowujesz 10% mężczyzn na kobiety, aby zrównoważyć go na potrzeby uczenia modeli. To jest niedoskonałe i ma pewne problemy, ale lepsze to niż pozwolenie na jazdę stronniczością.
W idealnym przypadku wbudowaliśmy w nasze modele interpretację, która pozwala nam na przeprowadzanie kontroli w trakcie procesu, a następnie weryfikację wyników (wyjaśnialność) post hoc. Oba są niezbędne, jeśli chcesz przejść audyt potwierdzający, że nie wbudowujesz stronniczości w swoje modele. Biada jest firmie, która ma tylko wyjaśnienia post hoc.
I wreszcie, aby zweryfikować wyniki, absolutnie potrzebny jest ludzki nadzór nad zróżnicowanym i integracyjnym zespołem. Najlepiej, jeśli korzystasz z usług strony trzeciej, ale zaufana strona wewnętrzna jest w porządku. Czy model i jego wyniki przedstawiają wypaczone wyniki, niż można by uzyskać z samej populacji?
Na przykład, jeśli tworzyłeś treści dla osób w wieku 16-22 lat i ani razu nie widziałeś w wygenerowanym tekście terminów takich jak martwy dupek, wilgotny, niski klucz itp., nie udało Ci się przechwycić żadnych danych po stronie wejściowej które uczyłyby modela dokładnego używania ich języka.
Największym głównym wyzwaniem jest tutaj radzenie sobie z tym wszystkim poprzez nieustrukturyzowane dane. To jest powód, dla którego rodowód jest TAK ważny. Bez rodowodu nie można udowodnić, że prawidłowo pobrałeś próbki z populacji. Lineage to Twoja dokumentacja tego, czym jest źródło danych, skąd pochodzą, w jaki sposób zostały zebrane, czy mają do niego zastosowanie jakiekolwiek wymogi prawne lub ujawnienia.
Co powinieneś teraz zrobić
Kiedy będziesz gotowy… oto 3 sposoby, w jakie możemy pomóc Ci szybciej publikować lepsze treści:
- Zarezerwuj czas z MarketMuse Zaplanuj prezentację na żywo z jednym z naszych strategów, aby zobaczyć, jak MarketMuse może pomóc Twojemu zespołowi osiągnąć cele dotyczące treści.
- Jeśli chcesz dowiedzieć się, jak szybciej tworzyć lepsze treści, odwiedź naszego bloga. Jest pełen zasobów, które pomagają skalować zawartość.
- Jeśli znasz innego marketera, który chciałby przeczytać tę stronę, udostępnij mu ją za pośrednictwem poczty e-mail, LinkedIn, Twittera lub Facebooka.