
Noindex Nofollow i Disallow: Dyrektywy robotów wyszukiwania
Opublikowany: 2022-12-01Istnieją trzy dyrektywy (polecenia), których możesz użyć, aby określić, w jaki sposób wyszukiwarki mają odkrywać, przechowywać i udostępniać informacje z Twojej witryny jako wyniki wyszukiwania:
- NoIndex: Nie dodawaj mojej strony do wyników wyszukiwania.
- NoFollow: Nie patrz na linki na tej stronie.
- Nie zezwalaj: w ogóle nie przeglądaj tej strony.
Te dyrektywy pozwalają kontrolować, które strony Twojej witryny mogą być indeksowane przez wyszukiwarki i pojawiać się w wynikach wyszukiwania.
Co oznacza brak indeksu?
Dyrektywa noindex mówi robotom indeksującym, takim jak Googlebot, aby nie uwzględniały strony internetowej w swoich wynikach wyszukiwania.

Jak oznaczyć stronę NoIndex?
Istnieją dwa sposoby wydania dyrektywy noindex :
- Dodaj metatag noindex do kodu HTML strony
- Zwróć nagłówek noindex w żądaniu HTTP
Używając metatagu „no index” dla strony lub jako nagłówka odpowiedzi HTTP, zasadniczo ukrywasz stronę przed wyszukiwaniem.
Dyrektywy noindex można również użyć do zablokowania tylko określonych wyszukiwarek. Na przykład możesz zablokować indeksowanie strony przez Google, ale nadal zezwalać Bing:
Przykład: blokowanie większości wyszukiwarek*
<meta name=”roboty” content=”noindex”>
Przykład: Blokowanie tylko Google
<meta name=”googlebot” content=”noindex”>
Uwaga: od września 2019 r. Google nie przestrzega już dyrektyw noindex w pliku robots.txt . Noindex MUSI być teraz wydawany za pomocą metatagu HTML lub nagłówka odpowiedzi HTTP. W przypadku bardziej zaawansowanych użytkowników opcja „ nie zezwalaj ” nadal działa, chociaż nie we wszystkich przypadkach użycia.
Jaka jest różnica między noindex a nofollow?
Istnieje różnica między przechowywaniem treści a odkrywaniem treści:
noindex jest stosowany na poziomie strony i mówi robotowi indeksującemu wyszukiwarki, aby nie indeksował i nie wyświetlał strony w wynikach wyszukiwania.
Nofollow jest stosowane na poziomie strony lub linku i mówi robotowi wyszukiwarki, aby nie podążał (odkrywał) linków.
Zasadniczo tag noindex usuwa stronę z indeksu wyszukiwania, a atrybut nofollow usuwa link z wykresu linków wyszukiwarki.
NoFollow jako atrybut strony
Używanie nofollow na poziomie strony oznacza, że roboty indeksujące nie będą podążać za żadnymi linkami na tej stronie w celu odkrycia dodatkowej treści, a roboty indeksujące nie będą używać linków jako sygnałów rankingowych dla witryn docelowych.
<meta name=”roboty” content=”nofollow”>
NoFollow jako atrybut linku
Używanie nofollow na poziomie linku uniemożliwia robotom indeksującym przeglądanie linku do reklamy i zapobiega wykorzystywaniu tego linku jako sygnału rankingowego.
Dyrektywa nofollow jest stosowana na poziomie łącza przy użyciu atrybutu rel w tagu href:
<a href=”https://domena.com” rel=”nofollow”>
W szczególności w przypadku Google użycie atrybutu linku nofollow uniemożliwi Twojej witrynie przekazywanie PageRank do docelowych adresów URL.
Dlaczego warto oznaczyć stronę jako NoFollow?
W większości przypadków użycia nie należy oznaczać całej strony jako nofollow – wystarczy zaznaczyć poszczególne linki jako nofollow.
Oznaczysz całą stronę jako nofollow , jeśli nie chcesz, aby Google wyświetlał linki na stronie lub jeśli uważasz, że linki na stronie mogą zaszkodzić Twojej witrynie.
W większości przypadków ogólne dyrektywy nofollow na poziomie strony są używane, gdy nie masz kontroli nad treścią publikowaną na stronie Niektórzy wydawcy z wyższej półki również powszechnie stosują dyrektywę nofollow na swoich stronach, aby odwieść ich autorów od umieszczania linków sponsorowanych w ich treści.
Jak korzystać ze stron NoIndex?
Oznacz strony jako noindex, które prawdopodobnie nie będą wartościowe dla użytkowników i nie powinny pojawiać się w wynikach wyszukiwania. Na przykład jest mało prawdopodobne, aby strony, które istnieją do podziału na strony, miały tę samą treść wyświetlaną w miarę upływu czasu.
Domain.com/category/resultspage=2 raczej nie pokaże użytkownikowi lepszych wyników niż domain.com/category/resultspage=1 , a te dwie strony będą konkurować tylko ze sobą w wyszukiwaniu. Najlepiej nie indeksować stron, których jedynym celem jest paginacja.
Oto typy stron, które warto rozważyć bez indeksowania:
- Strony używane do paginacji
- Wewnętrzne strony wyszukiwania
- Strony docelowe zoptymalizowane pod kątem reklam
- Np.: wyświetla tylko prezentację i formularz rejestracji, bez głównej nawigacji
- Np.: zduplikowane odmiany tej samej treści, używane tylko w reklamach
- Zarchiwizowane strony autorskie
- Strony w przepływach kasowych
- Strony potwierdzenia
- Np .: strony z podziękowaniami
- Np.: Zamów kompletne strony
- Np.: Sukces! Strony
- Niektóre strony generowane przez wtyczki, które nie są powiązane z Twoją witryną (np. jeśli używasz wtyczki handlowej, ale nie korzystasz ze zwykłych stron produktów)
- Strony administratora i strony logowania administratora
Oznaczanie strony Noindex i Nofollow
Strona oznaczona zarówno jako noindex, jak i nofollow zablokuje robotowi indeksowanie tej strony i uniemożliwi robotowi przeglądanie linków na stronie.
Zasadniczo poniższy obraz pokazuje, co wyszukiwarka zobaczy na stronie internetowej w zależności od sposobu użycia dyrektyw noindex i nofollow:

Oznaczanie już zaindeksowanej strony jako NoIndex
Jeśli wyszukiwarka już zaindeksowała stronę, a Ty oznaczysz ją jako noindex , to przy następnym indeksowaniu strona zostanie usunięta z wyników wyszukiwania Aby ta metoda usuwania strony z indeksu działała, nie możesz blokować (odrzucać) robota za pomocą pliku robots.txt.
Jeśli powiesz robotowi indeksującemu, aby nie czytał strony, nigdy nie zobaczy znacznika noindex , a strona pozostanie zindeksowana, chociaż jej zawartość nie zostanie odświeżona.
Jak powstrzymać wyszukiwarki przed indeksowaniem mojej witryny?
Jeśli chcesz usunąć stronę z indeksu wyszukiwania po jej zaindeksowaniu, możesz wykonać następujące czynności:
- Zastosuj dyrektywę noindex Dodaj atrybut noindex do metatagu lub nagłówka odpowiedzi HTTP
- Poproś wyszukiwarkę o zaindeksowanie strony W przypadku Google możesz to zrobić w konsoli wyszukiwania, poproś Google o ponowne zindeksowanie strony. Spowoduje to zaindeksowanie strony przez Googlebota, podczas którego Googlebot wykryje dyrektywę noindex. Musisz to zrobić dla każdej wyszukiwarki, z której chcesz usunąć stronę.
- Potwierdź, że strona została usunięta z wyszukiwania Po poproszeniu robota indeksującego o ponowne odwiedzenie Twojej strony internetowej, daj mu trochę czasu, a następnie potwierdź, że Twoja strona została usunięta z wyników wyszukiwania. Możesz to zrobić, przechodząc do dowolnej wyszukiwarki i wprowadzając docelowy adres URL dwukropka witryny, jak na obrazku poniżej.
Jeśli wyszukiwanie nie zwróci żadnych wyników, oznacza to, że Twoja strona została usunięta z tego indeksu wyszukiwania. - Jeśli strona nie została usunięta Sprawdź, czy plik robots.txt nie zawiera dyrektywy „disallow”. Google i inne wyszukiwarki nie mogą odczytać dyrektywy noindex, jeśli nie mogą zaindeksować strony. Jeśli to zrobisz, usuń dyrektywę disallow dla strony docelowej, a następnie poproś o ponowne zaindeksowanie.
- Ustaw dyrektywę disallow dla strony docelowej w pliku robots.txt Disallow: /page$
Musisz umieścić znak dolara na końcu adresu URL w pliku robots.txt, w przeciwnym razie możesz przypadkowo odrzucić wszystkie strony znajdujące się pod tą stroną, a także wszystkie strony zaczynające się od tego samego ciągu. Np. Disallow: /sweater zablokuje również /sweater-weather i /sweater/green, ale Disallow: /sweater$ zablokuje tylko dokładną stronę /sweater.
Jak aby usunąć stronę z wyszukiwarki Google
Jeśli strona, którą chcesz usunąć z wyszukiwania, znajduje się w witrynie, której jesteś właścicielem lub którą zarządzasz, większość witryn może korzystać z narzędzia do usuwania adresów URL dla webmasterów.
Narzędzie do usuwania adresów URL dla webmasterów usuwa treść z wyszukiwania tylko na około 90 dni. Jeśli potrzebujesz bardziej trwałego rozwiązania, musisz użyć dyrektywy noindex, zabronić indeksowania z pliku robots.txt lub usunąć stronę ze swojej witryny. Google udostępnia tutaj dodatkowe instrukcje dotyczące trwałego usuwania adresów URL.

Jeśli chcesz usunąć z wyszukiwania stronę witryny, która nie należy do Ciebie, możesz poprosić Google o usunięcie strony z wyszukiwania, jeśli spełnia ona następujące kryteria:
- Wyświetla dane osobowe, takie jak karta kredytowa lub numer ubezpieczenia społecznego
- Ta strona jest częścią złośliwego oprogramowania lub phishingu
- Strona narusza prawo
- Strona narusza prawa autorskie
Jeśli strona nie spełnia jednego z powyższych kryteriów, możesz skontaktować się z firmą SEO lub PR w celu uzyskania pomocy w zarządzaniu reputacją online.
Czy powinieneś noindexować strony kategorii?
Zwykle nie jest to zalecane dla stron kategorii noindex, chyba że jesteś organizacją na poziomie przedsiębiorstwa, która programowo rozwija strony kategorii na podstawie wyszukiwań lub tagów generowanych przez użytkowników, a zduplikowana treść staje się nieporęczna.
W większości przypadków, jeśli inteligentnie tagujesz swoje treści, w sposób, który pomaga użytkownikom lepiej poruszać się po witrynie i znajdować to, czego potrzebują, wszystko będzie w porządku.
W rzeczywistości strony kategorii mogą być kopalniami złota dla SEO, ponieważ zazwyczaj pokazują głębię treści pod tematami kategorii.
Przyjrzyj się tej analizie, którą przeprowadziliśmy w grudniu 2018 r., aby określić ilościowo wartość stron kategorii dla kilku publikacji internetowych.
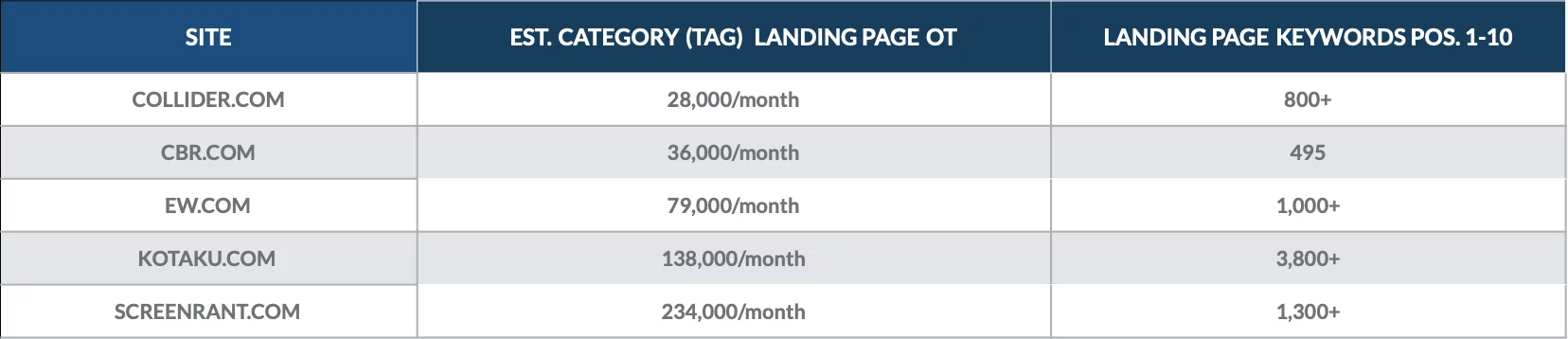
Odkryliśmy, że strony docelowe kategorii uzyskały ranking setek słów kluczowych na stronie 1 i przyciągały tysiące organicznych użytkowników każdego miesiąca.
Najcenniejsze strony kategorii dla każdej witryny często przyciągały tysiące organicznych użytkowników.
Spójrz na EW.com poniżej, zmierzyliśmy ruch na każdej stronie (reprezentowany przez rozmiar koła) i wartość ruchu na każdej stronie (reprezentowany przez kolor koła).
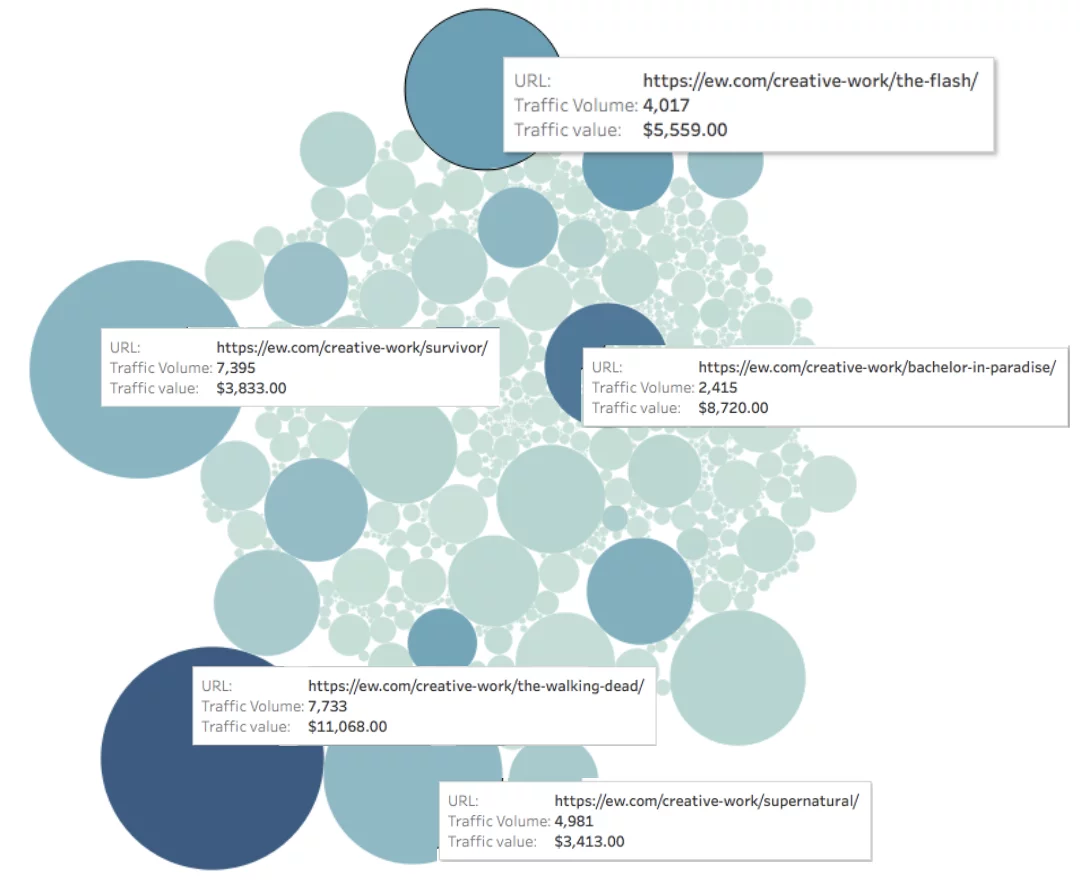
Miesięczna wartość organiczna strony = głębia koloru
Teraz wyobraź sobie te same wykresy, ale dla witryn opartych na produktach, w przypadku których odwiedzający prawdopodobnie dokonują aktywnych zakupów.
Biorąc to pod uwagę, jeśli Twoje kategorie są wystarczająco podobne, aby powodować zamieszanie wśród użytkowników lub konkurować ze sobą w wyszukiwaniu, może być konieczne wprowadzenie zmiany:
- Jeśli samodzielnie ustawiasz kategorie, zalecamy migrację treści z jednej kategorii do drugiej i zmniejszenie ogólnej liczby kategorii.
- Jeśli pozwalasz użytkownikom na rozwijanie kategorii, możesz chcieć nieindeksować stron kategorii tworzonych przez użytkowników, przynajmniej do czasu, gdy nowe kategorie przejdą proces recenzji.
Jak powstrzymać Google przed indeksowaniem subdomen?
Istnieje kilka sposobów powstrzymania Google przed indeksowaniem subdomen:
- Możesz dodać hasło za pomocą pliku .htpasswd
- Możesz zabronić robotom indeksującym za pomocą pliku robots.txt
- Możesz dodać dyrektywę noindex do każdej strony w subdomenie
- Możesz 404 wszystkich stron subdomeny
Dodawanie hasła w celu zablokowania indeksowania
Jeśli Twoje subdomeny są przeznaczone do celów programistycznych, dodanie pliku .htpasswd do katalogu głównego Twojej subdomeny jest idealną opcją. Ściana logowania zapobiegnie indeksowaniu treści w subdomenie przez roboty indeksujące i uniemożliwi nieautoryzowany dostęp użytkowników.
Przykładowe przypadki użycia:
- Dev.domena.com
- Staging.domena.com
- Testowanie.domena.com
- QA.domena.com
- UAT.domena.com
Używanie pliku robots.txt do blokowania indeksowania
Jeśli Twoje subdomeny służą innym celom, możesz dodać plik robots.txt do katalogu głównego swojej subdomeny. Powinien być wtedy dostępny w następujący sposób:
https://subdomena.domena.com/robots.txt
Musisz dodać plik robots.txt do każdej subdomeny, którą próbujesz zablokować w wyszukiwaniu. Przykład:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
W każdym przypadku plik robots.txt powinien blokować roboty indeksujące. Aby zablokować większość robotów pojedynczym poleceniem, użyj następującego kodu:
Agent użytkownika: *
Uniemożliwić: /
Gwiazdka * po agencie użytkownika: nazywana jest symbolem wieloznacznym, będzie pasować do dowolnej sekwencji znaków. Użycie symbolu wieloznacznego spowoduje wysłanie następującej dyrektywy disallow do wszystkich programów użytkownika niezależnie od ich nazwy, od googlebota po yandex.
Ukośnik odwrotny informuje robota indeksującego, że wszystkie strony spoza subdomeny są objęte dyrektywą disallow.
Jak selektywnie blokować indeksowanie stron subdomen
Jeśli chcesz, aby niektóre strony z subdomeny pojawiały się w wynikach wyszukiwania, a inne nie, masz dwie możliwości:
- Użyj dyrektyw noindex na poziomie strony
- Użyj dyrektyw zakazu na poziomie folderu lub katalogu
Dyrektywy noindex na poziomie strony będą bardziej kłopotliwe do wdrożenia, ponieważ dyrektywa musi zostać dodana do kodu HTML lub nagłówka każdej strony. Jednak dyrektywy noindex powstrzymają Google przed indeksowaniem subdomeny, niezależnie od tego, czy subdomena została już zindeksowana, czy nie.
Dyrektywy zakazu na poziomie katalogu są łatwiejsze do wdrożenia, ale będą działać tylko wtedy, gdy strony subdomeny nie znajdują się już w indeksie wyszukiwania. Po prostu zaktualizuj plik robots.txt subdomeny, aby uniemożliwić indeksowanie odpowiednich katalogów lub podfolderów.
Skąd mam wiedzieć, czy moje strony są NoIndexed?
Przypadkowe dodanie stron z dyrektywą no index w Twojej witrynie może mieć drastyczne konsekwencje dla Twoich rankingów wyszukiwania i widoczności wyszukiwania.
Jeśli okaże się, że strona nie generuje ruchu organicznego pomimo dobrej zawartości i linków zwrotnych, najpierw sprawdź, czy nie zablokowałeś przypadkowo robotów indeksujących w pliku robots.txt. Jeśli to nie rozwiąże problemu, musisz sprawdzić poszczególne strony pod kątem dyrektyw noindex.
Sprawdzanie NoIndex na stronach WordPress
WordPress ułatwia dodawanie lub usuwanie tego tagu na twoich stronach. Pierwszym krokiem w sprawdzaniu nofollow na twoich stronach jest po prostu przełączenie ustawienia Widoczności w wyszukiwarkach w zakładce „Czytanie” w menu „Ustawienia”.
To prawdopodobnie rozwiąże problem, jednak to ustawienie działa raczej jako „sugestia” niż reguła, a niektóre treści i tak mogą zostać zindeksowane.
Aby zapewnić całkowitą prywatność swoich plików i treści, będziesz musiał zrobić ostatni krok albo zabezpieczyć swoją witrynę hasłem za pomocą narzędzi do zarządzania cPanel, jeśli są dostępne, albo za pomocą prostej wtyczki.
Podobnie usunięcie tego tagu z treści można wykonać, usuwając ochronę hasłem i odznaczając ustawienie widoczności.
Sprawdzanie NoIndex na Squarespace
Strony Squarespace są również łatwo NoIndexed przy użyciu funkcji Code Injection platformy. Podobnie jak WordPress, Squarespace można łatwo zablokować przed rutynowymi wyszukiwaniami za pomocą ochrony hasłem, jednak platforma odradza również podejmowanie tego kroku w celu ochrony integralności treści.
Dodając linię kodu NoIndex na każdej stronie, którą chcesz ukryć przed wyszukiwarkami internetowymi i na każdej podstronie poniżej, możesz zapewnić bezpieczeństwo zabezpieczonych treści, które powinny być zablokowane przed publicznym dostępem. Podobnie jak w przypadku innych platform, usunięcie tego tagu jest również dość proste: wystarczy użyć funkcji Code Injection, aby wycofać kod.
Squarespace jest wyjątkowy, ponieważ jego konkurenci oferują tę opcję przede wszystkim jako część zestawu ustawień w narzędziach do zarządzania stroną. Squarespace odchodzi tutaj, pozwalając na osobistą manipulację kodem. Jest to interesujące, ponieważ możesz zobaczyć zmianę, którą wprowadzasz w treści swojej strony, w przeciwieństwie do innych w tej przestrzeni.
Sprawdzanie NoIndex na Wix
Wix pozwala również na prostą i szybką naprawę problemów z NoIndexing. W ustawieniach „Menu i strony” możesz po prostu dezaktywować opcję „pokazuj tę stronę w wynikach wyszukiwania”, jeśli chcesz NoIndex pojedynczej strony w swojej witrynie.
Podobnie jak w przypadku konkurencji, Wix sugeruje również hasło chroniące Twoje strony lub całą witrynę w celu zapewnienia dodatkowej prywatności. Jednak Wix różni się od innych tym, że zespół wsparcia nie zaleca równoległych działań na obu frontach w celu zabezpieczenia treści przed robotem indeksującym. Wix zwraca szczególną uwagę na różnicę między ukrywaniem strony w menu a ukrywaniem jej przed kryteriami wyszukiwania.
Jest to szczególnie przydatna rada dla mniej doświadczonych twórców witryn, którzy początkowo mogą nie rozumieć różnicy, biorąc pod uwagę, że usunięcie z menu witryny powoduje, że strona jest niedostępna z witryny, ale nie z ostrożnego wyszukiwania w Google.