
Modelowanie tematyczne za pomocą Word2Vec
Opublikowany: 2022-05-02Słowo jest definiowane przez firmę, którą prowadzi. Takie jest założenie Word2Vec, metody konwersji słów na liczby i przedstawiania ich w przestrzeni wielowymiarowej. Słowa często znajdowane blisko siebie w zbiorze dokumentów (korpusie) również pojawią się blisko siebie w tej przestrzeni. Mówi się, że są powiązane kontekstowo.
Word2Vec to metoda uczenia maszynowego, która wymaga korpusu i odpowiedniego przeszkolenia. Jakość obu wpływa na ich zdolność do dokładnego modelowania tematu. Wszelkie niedociągnięcia stają się łatwo widoczne podczas badania danych wyjściowych dla bardzo konkretnych i skomplikowanych tematów, ponieważ są one najtrudniejsze do precyzyjnego modelowania. Word2Vec może być używany samodzielnie, chociaż często łączy się go z innymi technikami modelowania, aby wyeliminować jego ograniczenia.
Pozostała część tego artykułu zawiera dodatkowe informacje na temat Word2Vec, sposobu jego działania, sposobu jego wykorzystania w modelowaniu tematów oraz niektórych związanych z nim wyzwań.
Co to jest Word2Vec?
We wrześniu 2013 r. badacze Google, Tomas Mikolov, Kai Chen, Greg Corrado i Jeffrey Dean, opublikowali artykuł „Efficient Estimation of Word Representations in Vector Space” (pdf). To właśnie nazywamy teraz Word2Vec. Celem artykułu było „przedstawienie technik, które można wykorzystać do uczenia się wysokiej jakości wektorów słów z ogromnych zbiorów danych zawierających miliardy słów i miliony słów w słowniku”.
Przed tym punktem wszelkie techniki przetwarzania języka naturalnego traktowały słowa jako pojedyncze jednostki. Nie brali pod uwagę żadnego podobieństwa między słowami. Chociaż istniały uzasadnione powody takiego podejścia, miało ono swoje ograniczenia. Zdarzały się sytuacje, w których skalowanie tych podstawowych technik nie mogło przynieść znaczącej poprawy. Stąd konieczność rozwijania zaawansowanych technologii.
Artykuł wykazał, że proste modele o niższych wymaganiach obliczeniowych mogą trenować wysokiej jakości wektory słów. Jak podsumowuje artykuł, „możliwe jest obliczenie bardzo dokładnych, wielowymiarowych wektorów słów ze znacznie większego zestawu danych”. Mówią o zbiorach dokumentów (korpusach) z bilionem słów zapewniających praktycznie nieograniczony rozmiar słownictwa.
Word2Vec to sposób zamiany słów na liczby, w tym przypadku wektory, dzięki czemu podobieństwa można odkryć matematycznie. Pomysł polega na tym, że wektory podobnych słów są grupowane w przestrzeni wektorowej.
Pomyśl o współrzędnych równoleżnikowych i podłużnych na mapie. Używając tego dwuwymiarowego wektora, możesz szybko określić, czy dwie lokalizacje są stosunkowo blisko siebie. Aby słowa były odpowiednio reprezentowane w przestrzeni wektorowej, dwa wymiary nie wystarczą. Tak więc wektory muszą zawierać wiele wymiarów.
Jak działa Word2Vec?
Word2Vec pobiera jako dane wejściowe duży korpus tekstu i wektoryzuje go za pomocą płytkiej sieci neuronowej. Wynikiem jest lista słów (słownictwa), każde z odpowiednim wektorem. Słowa o podobnym znaczeniu występują przestrzennie w bliskim sąsiedztwie. Matematycznie mierzy się to za pomocą podobieństwa cosinus, gdzie całkowite podobieństwo wyraża się jako kąt 0 stopni, podczas gdy brak podobieństwa jest wyrażany jako kąt 90 stopni.
Słowa mogą być kodowane jako wektory przy użyciu różnych typów modeli. W swoim artykule Mikolov i in. przyjrzano się dwóm istniejącym modelom: sprzężeniu w przód neuronowemu modelowi językowemu sieci (NNLM) i rekurencyjnemu neuronowemu modelowi językowemu sieciowemu (RNNLM). Ponadto proponują dwa nowe modele log-liniowe, ciągły worek słów (CBOW) i ciągły Skip-gram.
W ich porównaniach CBOW i Skip-gram wypadły lepiej, więc przyjrzyjmy się tym dwóm modelom.
CBOW jest podobny do NNLM i opiera się na kontekście w celu określenia słowa docelowego. Określa słowo docelowe na podstawie słów, które pojawiają się przed i po nim. Mikolov stwierdził, że najlepszy występ wystąpił z czterema słowami przyszłości i czterema słowami historycznymi. Nazywa się to workiem słów, ponieważ kolejność słów w historii nie ma wpływu na wynik. „Ciągły” w pojęciu CBOW odnosi się do użycia „ciągłej rozproszonej reprezentacji kontekstu”.
Skip-gram to odwrotność CBOW. Podane słowo przewiduje otaczające słowa w określonym zakresie. Większy zakres zapewnia lepszą jakość wektorów słów, ale zwiększa złożoność obliczeniową. Mniej wagi przywiązuje się do odległych terminów, ponieważ są one zwykle mniej związane z bieżącym słowem.
Porównując CBOW do Skip-gram, stwierdzono, że ten ostatni oferuje lepszą jakość wyników na dużych zbiorach danych. Chociaż CBOW jest szybszy, Skip-gram lepiej radzi sobie z rzadko używanymi słowami.
Podczas uczenia do każdego słowa przypisywany jest wektor. Składniki tego wektora są dopasowywane tak, aby podobne słowa (na podstawie ich kontekstu) były bliżej siebie. Pomyśl o tym jako o przeciąganiu liny, w którym słowa są popychane i ciągnięte w tym wielowymiarowym wektorze za każdym razem, gdy do przestrzeni dodawany jest inny termin.
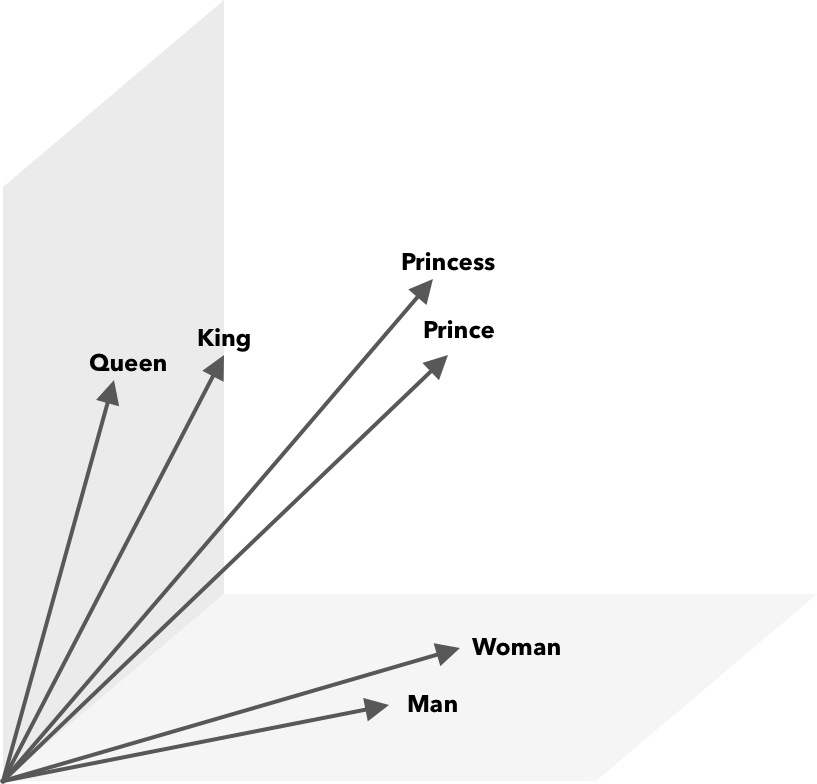
Operacje matematyczne, oprócz podobieństwa cosinusów, można wykonywać na wektorach słownych. Na przykład wektor(”Król”) – wektor(”Mężczyzna”) + wektor(”Kobieta”) daje wektor najbliższy temu, który reprezentuje słowo Królowa.

Word2Vec do modelowania tematów
Słownictwo utworzone przez Word2Vec można przeszukiwać bezpośrednio w celu wykrycia relacji między słowami lub wprowadzać do głębokiej sieci neuronowej. Jednym z problemów związanych z algorytmami Word2Vec, takimi jak CBOW i Skip-gram, jest to, że ważą one jednakowo każde słowo. Problem, który pojawia się podczas pracy z dokumentami, polega na tym, że słowa nie oddają w równym stopniu znaczenia zdania.
Niektóre słowa są ważniejsze niż inne. Dlatego też często stosuje się różne strategie ważenia, takie jak TF-IDF, aby poradzić sobie z sytuacją. Pomaga to również rozwiązać problem piasty, o którym mowa w następnej sekcji. Searchmetrics ContentExperience wykorzystuje kombinację TF-IDF i Word2Vec, o której możesz przeczytać tutaj w naszym porównaniu z MarketMuse.
Podczas gdy osadzania słów, takie jak Word2Vec, przechwytują informacje morfologiczne, semantyczne i składniowe, modelowanie tematów ma na celu odkrycie ukrytej struktury semantycznej lub tematów w korpusie.
Według Budhkara i Rudzicza (PDF), połączenie ukrytej alokacji Dirichleta (LDA) z Word2Vec może wytworzyć cechy rozróżniające, aby „rozwiązać problem spowodowany brakiem informacji kontekstowych osadzonych w tych modelach”. Łatwiejsze czytanie na LDA2vec można znaleźć w tym samouczku DataCamp.
Wyzwania Word2Vec
Istnieje kilka ogólnych problemów z osadzaniem słów, w tym Word2Vec. Dotkniemy niektórych z nich, aby uzyskać bardziej szczegółową analizę, zobacz „Ankieta metod oceny osadzania słów” (pdf) autorstwa Amira Bakarova. Korpus i jego wielkość, a także samo szkolenie będą miały znaczący wpływ na jakość wydruku.
Jak oceniasz wyniki?
Jak wyjaśnia Bakarov w swoim artykule, inżynier NLP zazwyczaj ocenia wydajność osadzania inaczej niż lingwista obliczeniowy lub marketer treści. Oto kilka dodatkowych kwestii cytowanych w artykule.
- Semantyka to niejasna idea. „Dobre” osadzenie słowa odzwierciedla nasze pojęcie semantyki. Jednak możemy nie być świadomi, czy nasze zrozumienie jest prawidłowe. Ponadto słowa mają różne typy relacji, takie jak pokrewieństwo semantyczne i podobieństwo semantyczne. Jaki rodzaj relacji powinno odzwierciedlać słowo „osadzenie”?
- Brak odpowiednich danych treningowych. Ucząc osadzenia słów, badacze często podnoszą ich jakość, dostosowując je do danych. To właśnie nazywamy dopasowaniem krzywej. Zamiast dopasowywać wynik do danych, badacze powinni spróbować uchwycić relacje między słowami.
- Brak korelacji między metodami wewnętrznymi i zewnętrznymi oznacza, że nie jest jasne, która klasa metody jest preferowana. Ocena zewnętrzna określa jakość wyjściową do dalszego wykorzystania w innych zadaniach przetwarzania języka naturalnego. Ocena wewnętrzna opiera się na ludzkim osądzie relacji słownych.
- Problem piasty. Huby, wektory słów reprezentujące zwykłe słowa, są blisko nadmiernej liczby innych wektorów słów. Ten szum może wpływać na ocenę.
Dodatkowo, w szczególności Word2Vec wiąże się z dwoma istotnymi wyzwaniami.
- Nie radzi sobie bardzo dobrze z niejasnościami. W rezultacie wektor słowa o wielu znaczeniach odzwierciedla średnią, która jest daleka od ideału.
- Word2Vec nie obsługuje słów spoza słownika (OOV) i słów podobnych morfologicznie. Kiedy model napotyka nową koncepcję, wykorzystuje losowy wektor, który nie jest dokładną reprezentacją.
Streszczenie
Używanie Word2Vec lub jakiegokolwiek innego osadzania słów nie gwarantuje sukcesu. Jakość wyników zależy od odpowiedniego szkolenia przy użyciu odpowiedniego i wystarczająco dużego korpusu.
Chociaż ocena jakości wyników może być kłopotliwa, oto proste rozwiązanie dla content marketerów. Następnym razem, gdy będziesz oceniać optymalizator treści, spróbuj użyć bardzo konkretnego tematu. Modele tematyczne niskiej jakości zawodzą, jeśli chodzi o testowanie w ten sposób. Są w porządku w przypadku ogólnych warunków, ale załamują się, gdy prośba staje się zbyt szczegółowa.
Tak więc, jeśli używasz tematu „jak uprawiać awokado”, upewnij się, że sugestie mają coś wspólnego z uprawą rośliny, a nie ogólnie z awokado.
Generowanie języka naturalnego w technologii MarketMuse NLG pomogło w stworzeniu tego artykułu.
Co powinieneś teraz zrobić
Kiedy będziesz gotowy… oto 3 sposoby, w jakie możemy pomóc Ci szybciej publikować lepsze treści:
- Zarezerwuj czas z MarketMuse Zaplanuj prezentację na żywo z jednym z naszych strategów, aby zobaczyć, jak MarketMuse może pomóc Twojemu zespołowi osiągnąć cele dotyczące treści.
- Jeśli chcesz dowiedzieć się, jak szybciej tworzyć lepsze treści, odwiedź naszego bloga. Jest pełen zasobów, które pomagają skalować zawartość.
- Jeśli znasz innego marketera, który chciałby przeczytać tę stronę, udostępnij mu ją za pośrednictwem poczty e-mail, LinkedIn, Twittera lub Facebooka.