
Jakie są rodzaje Big Data: charakterystyka i definicja
Opublikowany: 2023-10-06Podsumowanie: Duże dane składają się z czterech typów danych ustrukturyzowanych, nieustrukturyzowanych, częściowo ustrukturyzowanych i quasi-ustrukturyzowanych. Przyjrzyjmy się szczegółowo każdemu typowi dużych zbiorów danych poniżej!
Większość organizacji korzysta z zestawów danych, aby uzyskać wgląd i poznać swoich klientów, branżę i firmę. Jednak gdy dane stają się coraz większe, ich przetwarzanie i przetwarzanie staje się trudne.
Te zbiory danych nazywane są dużymi zbiorami danych, które charakteryzują się większą różnorodnością danych i mają ogromny charakter. Big data może występować w kilku postaciach, takich jak ustrukturyzowane, nieustrukturyzowane, częściowo ustrukturyzowane i quasi-strukturalne.
W poniższym artykule dowiemy się więcej o różnych typach dużych zbiorów danych.
Spis treści
Jakie są popularne typy Big Data?
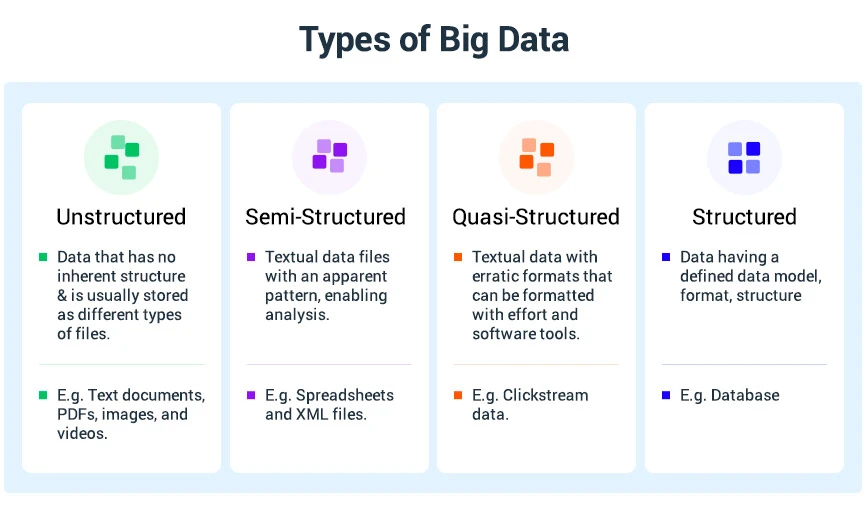
Big data dzieli się na cztery główne typy wymienione poniżej:
Dane strukturalne
Dane strukturalne to rodzaj danych, które mają ustandaryzowany format, do którego oprogramowanie i ludzie mogą łatwo uzyskać dostęp. Zwykle ma formę tabelaryczną z różnymi wierszami i kolumnami, które podkreślają atrybuty danych.
Dane strukturalne obejmują dane ilościowe, takie jak wiek, numer kontaktowy, numery kart kredytowych i tak dalej. Ponieważ ma ona charakter ilościowy, oprogramowanie może z łatwością je przetworzyć w celu uzyskania cennych informacji.
Aby przetworzyć dane konstrukcji, nie trzeba przypisywać danych do odpowiednich metryk. Co więcej, dane dotyczące konstrukcji nie wymagają głębokiej konwersji i interpretacji, aby uzyskać cenne informacje.
Gdzie używać strukturalnego typu danych?
- Zarządzanie danymi klientów
- Utrzymanie szczegółów faktur
- Przechowywanie baz danych produktów
- Nagrywanie listy kontaktów
Plusy i minusy danych strukturalnych
- Ułatwia to przetwarzanie danych, ponieważ są one przechowywane w określonym formacie.
- Dane są przetwarzane szybciej w porównaniu do danych nieustrukturyzowanych
- Może nie być odpowiedni dla wszystkich typów informacji, ponieważ dane są przechowywane w określonym formacie.
Dane niestrukturalne: XML, JSON, YAML

Dane nieustrukturyzowane to rodzaj danych, który nie ogranicza się do konkretnego modelu danych i możliwej do zidentyfikowania struktury, którą może odczytać program komputerowy. Tego typu dane nie są zorganizowane w odpowiednio zdefiniowany sposób i brakuje im kolejności lub formatu przetwarzania danych.
W porównaniu do danych strukturalnych, tego typu danych nie można przechowywać w formie wierszy i kolumn. Typowym przykładem danych nieustrukturyzowanych jest heterogeniczna baza danych zawierająca kombinację obrazów, filmów, plików tekstowych itp.
Gdzie używać nieustrukturyzowanego typu danych?
- Zarządzanie danymi audio i wideo
- Obsługa odpowiedzi na ankiety otwarte
- Obsługa wpisów w mediach społecznościowych
- Zarządzanie dokumentacją biznesową
Plusy i minusy nieustrukturyzowanych danych
- Ponieważ nie ma określonej struktury, dane można zebrać szybko.
- Można go używać do radzenia sobie z heterogenicznymi źródłami danych.
- Ze względu na brak jakiejkolwiek struktury i schematu trudniej jest nim zarządzać.
Dane półstrukturalne
Dane częściowo ustrukturyzowane to rodzaj danych, które nie mają odpowiedniej struktury, ale jednocześnie nie są całkowicie pozbawione struktury. Dane te nie trzymają się sztywnego schematu i modelu danych. Co więcej, może również zawierać elementy, których nie można łatwo sklasyfikować ani sklasyfikować.
Dane częściowo ustrukturyzowane charakteryzują się metadanymi i znacznikami, które dostarczają dodatkowych informacji o wszystkich elementach danych. Na przykład plik XML może zawierać znaczniki wskazujące strukturę dokumentu oraz dodatkowe znaczniki dostarczające metadanych o treści, takich jak data lub słowa kluczowe.
Gdzie stosować półstrukturalny typ danych?
- Analiza stron internetowych poprzez HTML
- Korzystanie z danych e-mailowych w celu uzyskania wglądu w klientów
- Kategoryzacja i analiza filmów i obrazów
Plusy i minusy półstrukturalnego typu danych
- Schemat danych można zmienić.
- Ten typ danych może pomieścić dane, które mogą nie pasować do wcześniej zdefiniowanego schematu.
- Zapytania o dane są mniej wydajne w porównaniu do danych strukturalnych.
Dane quasi-strukturalne
Dane quasi-strukturalne to rodzaj danych tekstowych, które mają błędne formaty danych. Tego typu dane można formatować za pomocą różnych narzędzi do analizy danych. Obejmuje dane takie jak dane dotyczące strumienia kliknięć w Internecie.

Gdzie używać quasi-strukturalnego typu danych?
- Można go wykorzystać do analizy danych stron internetowych
Plusy i minusy quasi-strukturalnego typu danych
- Dane można szybko przetworzyć.
- Tego typu dane można szybko sformatować za pomocą narzędzi do analizy danych.
- Załadowanie danych może zająć trochę czasu.
Jakie są podtypy danych?
Istnieje kilka podtypów danych, które nie są uważane za duże zbiory danych, ale są ważne dla analizy. Źródłem takich danych mogą być media społecznościowe, rejestrowanie operacyjne, zdarzenia wyzwalane lub dane geoprzestrzenne. Może również pochodzić z systemów typu open source, danych przesyłanych za pośrednictwem interfejsu API oraz zagubionych lub skradzionych urządzeń.
Charakterystyka Big Data
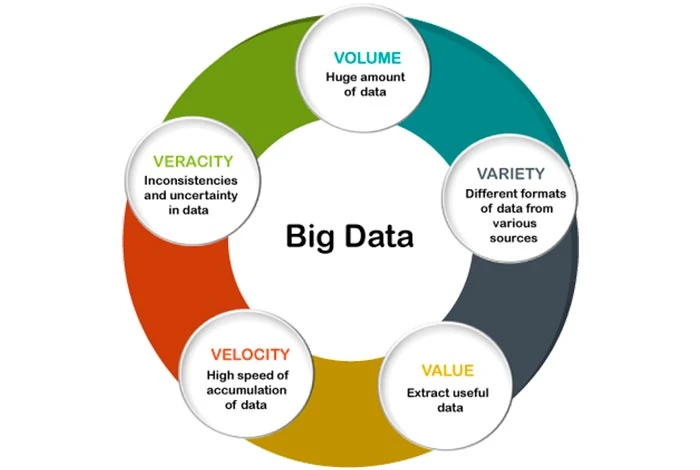
Istnieje pięć V , które definiują cechy dużych zbiorów danych. Te cechy są wymienione poniżej:
- Wolumen: Pierwszą cechą dużych zbiorów danych jest objętość. Big data to ogromna „ilość” danych zebranych z kilku źródeł. Źródła mogą obejmować procedury biznesowe, platformy mediów społecznościowych, maszyny, interakcje międzyludzkie itp.
- Prawdziwość: Prawdziwość można zdefiniować jako jakość i dokładność danych. Wyodrębnione dane mogą zawierać brakujące elementy lub mogą nie zapewniać cennych informacji. Dlatego ta cecha jest przydatna do identyfikowania jakości danych i uzyskiwania wglądu.
- Różnorodność: Różnorodność można zdefiniować jako różnorodność różnych typów danych. Dane można uzyskać z kilku źródeł danych, które mogą różnić się wartością. Zebrane dane mogą być ustrukturyzowane, nieustrukturyzowane lub częściowo ustrukturyzowane. Różnorodne dane mogą mieć formę plików PDF, e-maili, zdjęć, plików audio itp.
- Wartość: można ją zdefiniować jako wartość, jaką mogą zapewnić duże zbiory danych. Wyciąganie wartości z zebranych danych jest ważne, aby uzyskać z nich cenne spostrzeżenia. Organizacje mogą korzystać z tych samych narzędzi do analizy dużych zbiorów danych, za pomocą których zebrały dane do ich analizy.
- Prędkość: Prędkość odnosi się do szybkości generowania i przenoszenia danych. Jest to ważny element dla firm, którym zależy na szybkim przepływie danych, aby były dostępne we właściwym czasie i pozwalały na uzyskanie wglądu. Dane mogą pochodzić z różnych źródeł, takich jak maszyny, smartfony, sieci itp. Po zebraniu danych można je szybko przeanalizować.
Sektory korzystające na co dzień z Big Data
Big data może być wykorzystywany w wielu branżach, w tym w opiece zdrowotnej, rolnictwie, edukacji, finansach i tak dalej. Poniżej dowiemy się szczegółowo o zastosowaniu dużych zbiorów danych w następujących sektorach:
- Edukacja: W sektorze edukacji nauczyciele mogą analizować wyniki uczniów i wskaźniki porzucania nauki w celu optymalizacji programu nauczania. Co więcej, może również pomóc w identyfikacji obszarów wymagających poprawy poprzez analizę wyników ucznia.
- E-Commerce: Sektor e-commerce może wykorzystać analizę Big Data, aby zrozumieć, które procedury Twojej firmy radzą sobie dobrze, a które wymagają poprawy. Co więcej, możesz także zidentyfikować typ treści, który zwiększa zaangażowanie i które kanały generują największy ruch.
- Opieka zdrowotna: w opiece zdrowotnej duże zbiory danych można wykorzystać do uzyskania wniosków z badań biomedycznych i zapewnienia pacjentom spersonalizowanych zaleceń lekarskich po przeanalizowaniu ich danych. Co więcej, monitorując stan pacjenta w czasie rzeczywistym, mogą wysyłać powiadomienia do personelu medycznego.
- Rząd: rząd może wykorzystywać duże zbiory danych do zbiorczej analizy danych obywateli pod kątem wielu parametrów. Na przykład analizuje się duże zbiory spisu ludności, aby ustalić liczbę młodych ludzi w kraju lub populację bezrobotnych. Ustalenia te mogą pomóc im w opracowaniu programów i planów skierowanych do właściwej grupy obywateli.
Sugerowana lektura: Najlepsze narzędzia Business Intelligence (BI).
Wniosek
Big Data ułatwiło firmom przetwarzanie masowych zbiorów danych. Zbiorcze sortowanie, organizowanie i analizowanie danych może pomóc firmom uzyskać cenne informacje. Coraz więcej branż opiera się na analizie dużych zbiorów danych w celu przetwarzania złożonych danych i wykorzystywania wniosków w celu uzyskania przewagi konkurencyjnej.
Często zadawane pytania dotyczące typów dużych zbiorów danych
Co to jest big data i jaki rodzaj big data?
Big data to rodzaj danych, które charakteryzują się większą różnorodnością, większą objętością i większą szybkością. Rodzaje dużych zbiorów danych obejmują ustrukturyzowane, nieustrukturyzowane i częściowo ustrukturyzowane.
Jakie są trzy typy klasyfikacji Big Data?
Istnieją trzy typy klasyfikacji Big Data: dane ustrukturyzowane, nieustrukturyzowane i częściowo ustrukturyzowane.
Jakie są 4 elementy Big Data?
Cztery główne składniki dużych zbiorów danych to objętość, prędkość, różnorodność i prawdziwość.
Jakich jest 6 cech Big Data?
Big data ma następujące cechy, które pomagają analizować dane: objętość, różnorodność, prawdziwość, zmienność, prędkość i wartość.
Jakie są źródła big data?
Główne źródła dużych zbiorów danych można podzielić na społecznościowe, maszynowe i transakcyjne. Źródła społecznościowe są najczęściej używanymi źródłami dużych zbiorów danych w organizacji. Obejmuje posty w mediach społecznościowych, opublikowane filmy itp.