
Czym jest budżet indeksowania i jak go mądrze zoptymalizować?
Opublikowany: 2021-08-19Spis treści
Analiza budżetu indeksowania należy do obowiązków każdego eksperta SEO (zwłaszcza jeśli ma do czynienia z dużymi witrynami internetowymi). Ważne zadanie, przyzwoicie opisane w materiałach dostarczonych przez Google. Jednak, jak widać na Twitterze, nawet pracownicy Google bagatelizują rolę crawl budget w pozyskiwaniu lepszego ruchu i rankingów:

Czy mają rację w tej sprawie?
Jak Google działa i zbiera dane?
Gdy poruszamy ten temat, przypomnijmy sobie, jak wyszukiwarka zbiera, indeksuje i porządkuje informacje. Trzymanie tych trzech kroków w kąciku umysłu jest niezbędne podczas późniejszej pracy ze stroną internetową:
Krok 1: Indeksowanie . Przeszukiwanie zasobów online w celu odnajdywania i poruszania się po wszystkich istniejących łączach, plikach i danych. Ogólnie rzecz biorąc, Google zaczyna od najpopularniejszych miejsc w sieci, a następnie przechodzi do skanowania innych, mniej popularnych zasobów.
Krok 2: Indeksowanie . Google stara się ustalić, o czym jest strona i czy analizowana treść/dokument stanowi materiał unikalny czy duplikat. Na tym etapie Google grupuje treść i ustala kolejność ważności (czytając sugestie w tagach rel="canonical" lub rel="alternate" lub w inny sposób).
Krok 3: Podawanie . Po podzieleniu na segmenty i zindeksowaniu dane są wyświetlane w odpowiedzi na zapytania użytkowników. Dzieje się tak również wtedy, gdy Google odpowiednio sortuje dane, biorąc pod uwagę takie czynniki, jak lokalizacja użytkownika.
Ważne: wiele dostępnych materiałów pomija Krok 4: renderowanie treści . Domyślnie Googlebot indeksuje treść tekstową. Jednak w miarę rozwoju technologii internetowych Google musiał opracować nowe rozwiązania, aby przestać tylko „czytać” i zacząć „widzieć”. Na tym polega renderowanie. Służy Google do znacznego zwiększenia zasięgu wśród nowo uruchamianych witryn i rozszerzenia indeksu.
Uwaga : problemy z renderowaniem treści mogą być przyczyną niewypłacalności budżetu indeksowania.
Jaki jest budżet indeksowania?
Budżet indeksowania to nic innego jak częstotliwość, z jaką roboty i boty wyszukiwarek mogą indeksować Twoją witrynę, a także całkowita liczba adresów URL, do których mogą uzyskać dostęp podczas jednego indeksowania. Wyobraź sobie budżet indeksowania jako środki, które możesz wydać na usługę lub aplikację. Jeśli nie pamiętasz, aby „naładować” budżet na indeksowanie, robot zwolni i odwiedzi mniej.
W SEO „ładowanie” odnosi się do pracy włożonej w pozyskiwanie linków zwrotnych lub poprawę ogólnej popularności strony internetowej. W związku z tym budżet indeksowania jest integralną częścią całego ekosystemu sieci Web. Gdy dobrze sobie radzisz z treścią i linkami zwrotnymi, zwiększasz limit dostępnego budżetu indeksowania.
W swoich zasobach Google nie podejmuje ryzyka, aby jednoznacznie określić budżet indeksowania. Zamiast tego wskazuje na dwa podstawowe elementy indeksowania, które wpływają na dokładność działania Googlebota i częstotliwość jego wizyt:
- limit szybkości indeksowania;
- żądanie indeksowania.
Jaki jest limit szybkości indeksowania i jak go sprawdzić?
Najprościej mówiąc, limit szybkości indeksowania to liczba jednoczesnych połączeń, które Googlebot może nawiązać podczas indeksowania Twojej witryny. Ponieważ Google nie chce szkodzić użytkownikom, ogranicza liczbę połączeń, aby utrzymać płynną wydajność Twojej witryny/serwera. Krótko mówiąc, im wolniejsza witryna, tym mniejszy limit szybkości indeksowania.
Ważne: Limit indeksowania zależy również od ogólnej kondycji SEO Twojej witryny — jeśli witryna powoduje wiele przekierowań, błędy 404/410 lub jeśli serwer często zwraca kod stanu 500, liczba połączeń również się zmniejszy.
Dane o limicie szybkości indeksowania można analizować, korzystając z informacji dostępnych w Google Search Console w raporcie Statystyki indeksowania .
Popyt na indeksowanie, czyli popularność witryny
Podczas gdy limit szybkości indeksowania wymaga dopracowania szczegółów technicznych witryny, zapotrzebowanie na indeksowanie nagradza Cię za popularność witryny. Z grubsza rzecz biorąc, im większy szum wokół Twojej witryny (i na niej), tym większe jest jej zapotrzebowanie na indeksowanie.
W tym przypadku Google podsumowuje dwa problemy:
- Ogólna popularność – Google chętniej przeprowadza częste indeksowania adresów URL, które są ogólnie popularne w Internecie (niekoniecznie tych z linkami zwrotnymi z największej liczby adresów URL).
- Aktualność danych indeksowych – Google stara się prezentować tylko najnowsze informacje. Ważne: tworzenie coraz większej liczby nowych treści nie oznacza, że ogólny limit budżetu indeksowania rośnie.
Czynniki wpływające na budżet indeksowania
W poprzedniej sekcji zdefiniowaliśmy budżet indeksowania jako połączenie limitu szybkości indeksowania i żądania indeksowania. Pamiętaj, że musisz zadbać o oba jednocześnie, aby zapewnić prawidłowe indeksowanie (a tym samym indeksowanie) Twojej witryny.
Poniżej znajdziesz prostą listę punktów, które należy wziąć pod uwagę podczas optymalizacji budżetu indeksowania
- Serwer – głównym problemem jest wydajność. Im niższa prędkość, tym większe ryzyko, że Google przeznaczy mniej zasobów na indeksowanie nowych treści.
- Kody odpowiedzi serwera – im większa liczba przekierowań 301 i błędów 404/410 na Twojej stronie, tym gorsze wyniki indeksowania uzyskasz. Ważne: Uważaj na pętle przekierowań – każdy „przeskok” zmniejsza limit szybkości indeksowania Twojej witryny przy następnej wizycie bota.
- Bloki w pliku robots.txt — jeśli opierasz swoje dyrektywy w pliku robots.txt na przeczuciu, możesz stworzyć wąskie gardła indeksowania. Wynik: wyczyścisz indeks, ale kosztem skuteczności indeksowania nowych stron (kiedy zablokowane adresy URL były mocno osadzone w strukturze całej witryny).
- Nawigacja fasetowa / identyfikatory sesji / dowolne parametry w adresach URL – przede wszystkim uważaj na sytuacje, w których adres z jednym parametrem może być dalej sparametryzowany, bez żadnych ograniczeń. Jeśli tak się stanie, Google dotrze do nieskończonej liczby adresów, wydając wszystkie dostępne zasoby na mniej znaczące części naszej witryny.
- Zduplikowana treść – skopiowana treść (poza kanibalizacją) znacząco obniża skuteczność indeksowania nowej treści.
- Cienka treść – występuje, gdy strona ma bardzo niski stosunek tekstu do HTML. W rezultacie Google może zidentyfikować stronę jako tzw. Soft 404 i ograniczyć indeksację jej treści (nawet jeśli treść jest sensowna, co może mieć miejsce np. na stronie producenta prezentującej pojedynczy produkt, a nie unikalny treść tekstowa).
- Słabe linkowanie wewnętrzne lub jego brak .
Przydatne narzędzia do analizy budżetu indeksowania
Ponieważ nie ma benchmarku dla budżetu indeksowania (co oznacza, że trudno jest porównywać limity między stronami), przygotuj się na zestaw narzędzi zaprojektowanych w celu ułatwienia zbierania i analizy danych.
Konsola wyszukiwania Google
GSC ładnie dorosło przez lata. Podczas analizy budżetu indeksowania należy przyjrzeć się dwóm głównym raportom: Pokrycie indeksu i Statystyki indeksowania.
Pokrycie indeksu w SGR
Raport jest ogromnym źródłem danych. Sprawdźmy informacje o adresach URL wykluczonych z indeksowania. To świetny sposób na zrozumienie skali problemu, z którym się zmagasz.
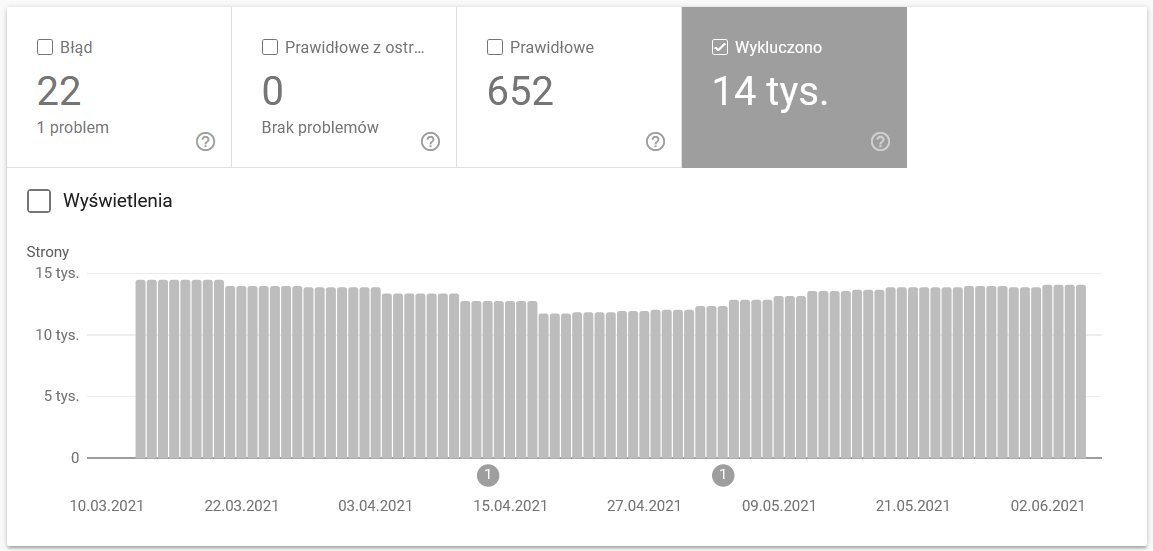
Całość raportu zasługuje na osobny artykuł, więc na razie skupmy się na następujących informacjach:
- Wykluczone przez tag „noindex” — ogólnie więcej stron noindex oznacza mniejszy ruch. Co nasuwa pytanie – po co trzymać je na stronie? Jak ograniczyć dostęp do tych stron?
- Zindeksowana – obecnie nieindeksowana – jeśli to widzisz, sprawdź, czy treść renderuje się poprawnie w oczach Googlebota. Pamiętaj, że każdy adres URL z tym statusem marnuje budżet na indeksowanie, ponieważ nie generuje ruchu organicznego.
- Odkryty – obecnie nieindeksowany – jeden z bardziej niepokojących problemów, które warto umieścić na szczycie listy priorytetów.
- Duplikuj bez wybranych przez użytkownika kanonów – wszystkie zduplikowane strony są niezwykle niebezpieczne, ponieważ nie tylko szkodzą Twojemu budżetowi indeksowania, ale także zwiększają ryzyko kanibalizacji.
- Duplikat, Google wybrał inny kanoniczny niż użytkownik – teoretycznie nie ma się czym martwić. W końcu Google powinien być na tyle sprytny, aby podjąć rozsądną decyzję za nas. Otóż w rzeczywistości Google wybiera swoje kanoniczne elementy dość losowo – często odcinając wartościowe strony z kanonicznym wskazującym na stronę główną.
- Soft 404 – wszystkie „miękkie” błędy są bardzo niebezpieczne, ponieważ mogą prowadzić do usunięcia krytycznych stron z indeksu.
- Zduplikowany, przesłany adres URL, który nie został wybrany jako kanoniczny – podobny do raportowania stanu dotyczącego braku wybranych przez użytkownika znaków kanonicznych.
Statystyki indeksowania
Raport nie jest doskonały i jeśli chodzi o rekomendacje, zdecydowanie sugeruję grać także ze starymi dobrymi logami serwera, które dają głębszy wgląd w dane (i więcej opcji modelowania).
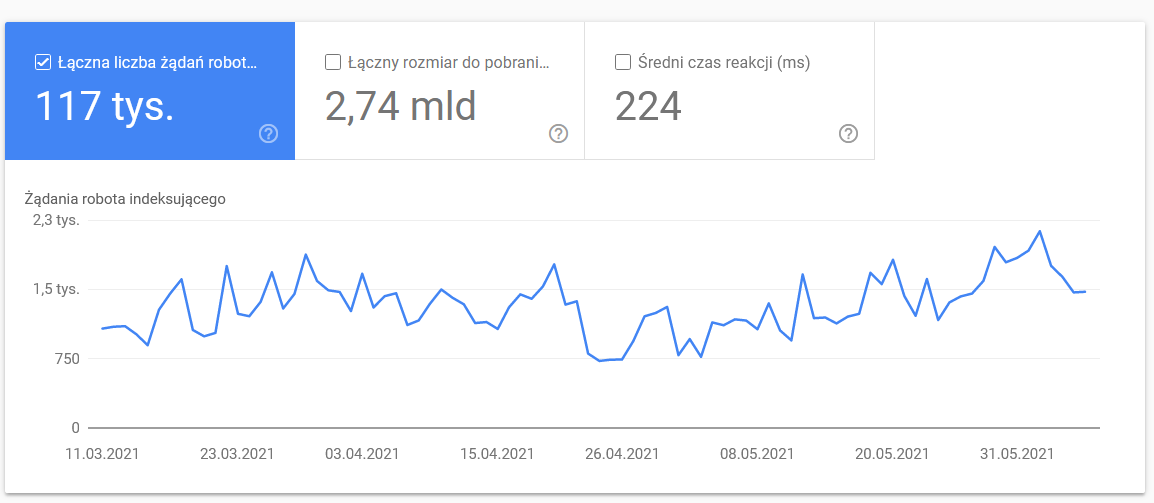
Jak już powiedziałem, trudno będzie Ci znaleźć punkty odniesienia dla powyższych liczb. Warto jednak przyjrzeć się bliżej:
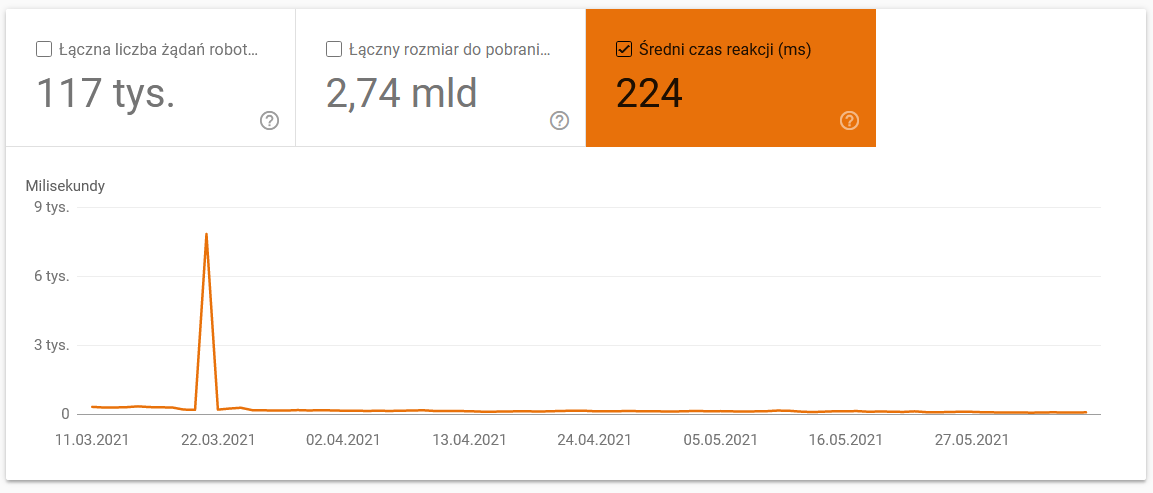
- Średni czas pobierania. Poniższy zrzut ekranu pokazuje, że średni czas odpowiedzi znacznie się zmniejszył, co było spowodowane problemami związanymi z serwerem:
- Odpowiedzi indeksowania. Spójrz na raport, aby ogólnie sprawdzić, czy masz problem ze swoją witryną, czy nie. Zwróć szczególną uwagę na nietypowe kody stanu serwera, takie jak 304 poniżej. Te adresy URL nie służą żadnemu celowi funkcjonalnemu, ale Google marnuje swoje zasoby na indeksowanie ich zawartości.

- Cel indeksowania. Generalnie dane te w dużej mierze zależą od ilości nowych treści na stronie. Różnice między informacjami gromadzonymi przez Google a użytkownikiem mogą być dość fascynujące:
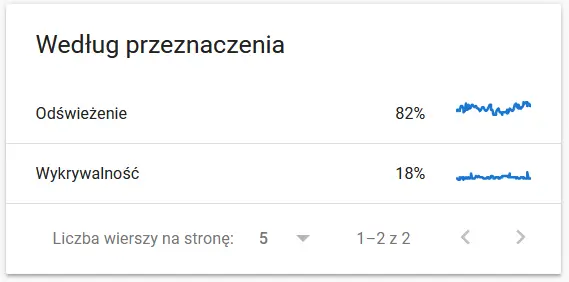
Treść ponownie zindeksowanego adresu URL w oczach Google:
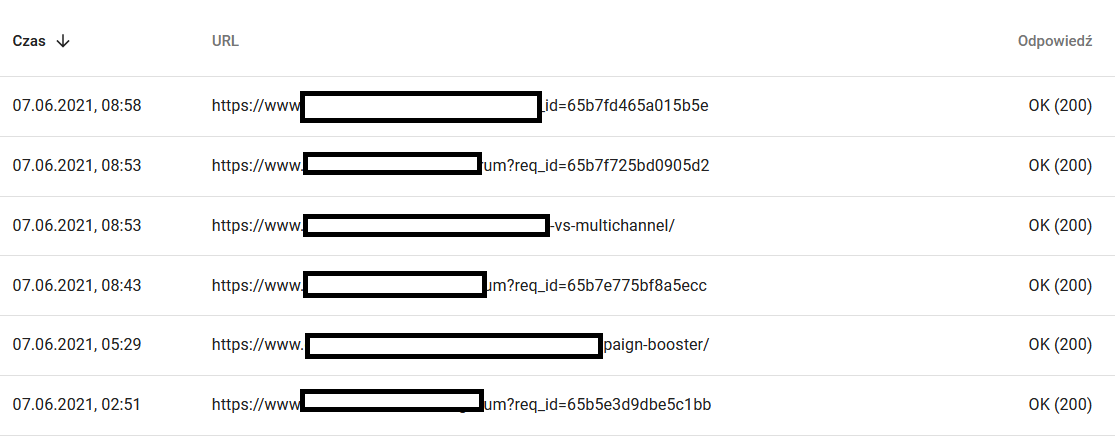
Tymczasem oto, co użytkownik widzi w przeglądarce:
Zdecydowanie powód do przemyśleń i analizy :)
- Typ Googlebota . Tutaj masz boty odwiedzające Twoją stronę na srebrnej tacy, wraz z ich motywacjami do parsowania treści. Poniższy zrzut ekranu pokazuje, że 22% żądań dotyczy ładowania zasobów strony.
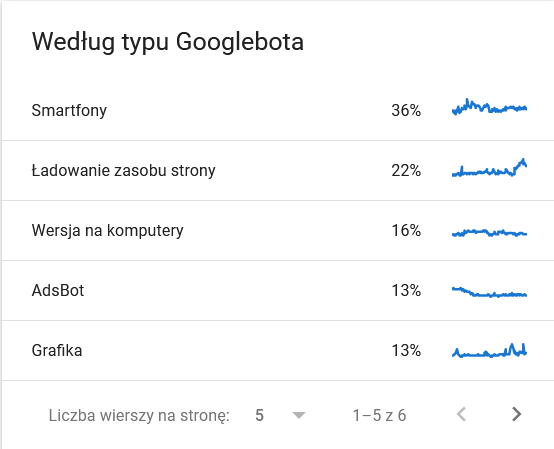
Suma wzrosła w ostatnich dniach tego przedziału czasowego:
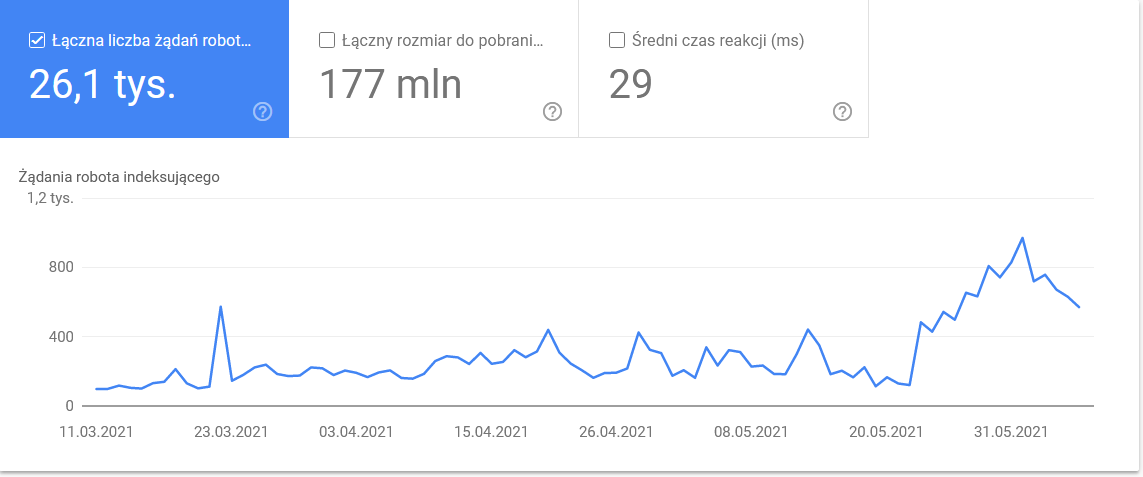
Spojrzenie na szczegóły ujawnia adresy URL, które wymagają bliższej uwagi:
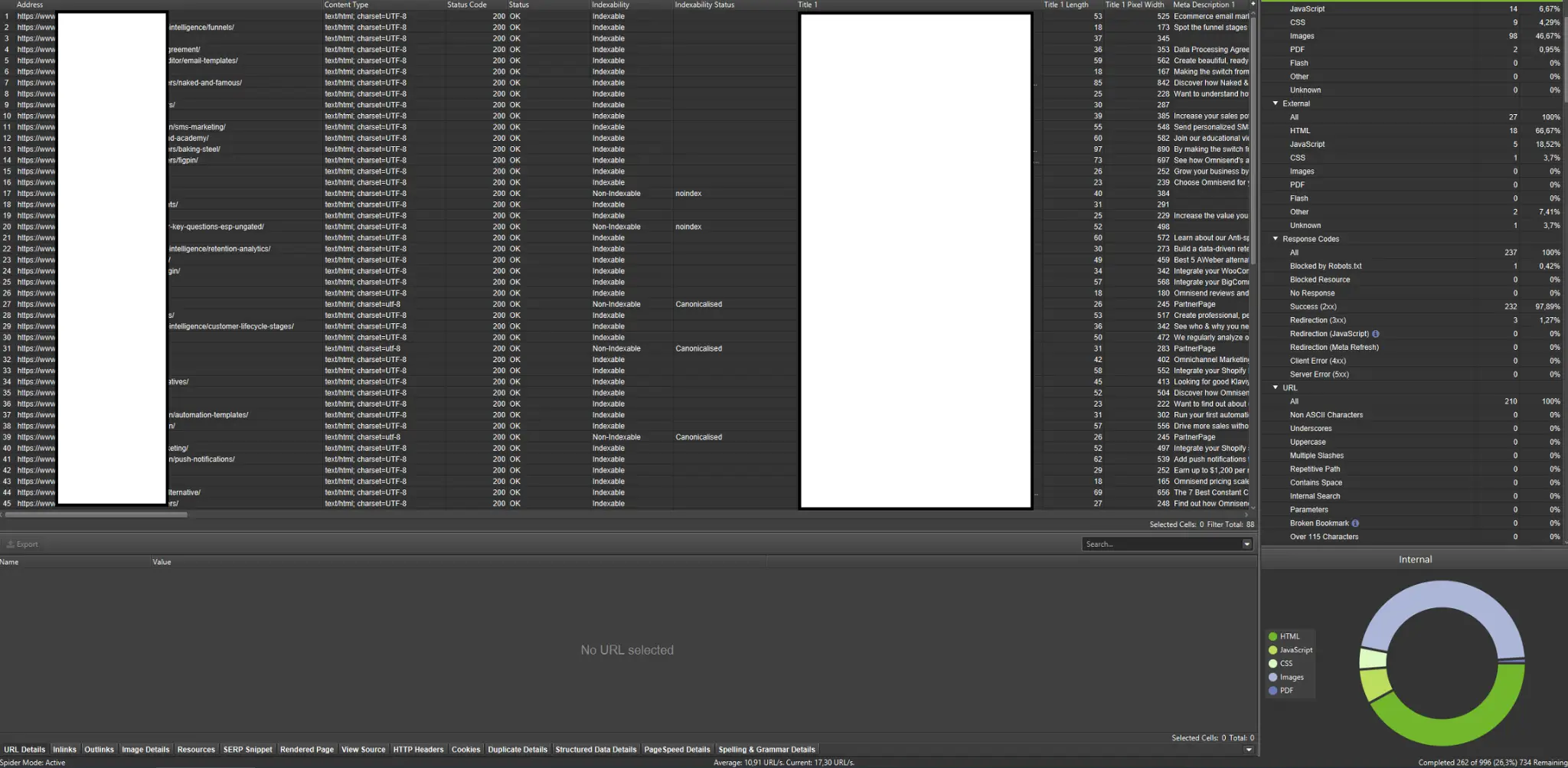
Zewnętrzne roboty indeksujące (przykłady z Screaming Frog SEO Spider)
Roboty indeksujące są jednymi z najważniejszych narzędzi do analizy budżetu indeksowania Twojej witryny. Ich głównym celem jest naśladowanie ruchów robotów indeksujących w witrynie. Symulacja pokazuje na pierwszy rzut oka, czy wszystko idzie płynnie.
Jeśli jesteś wizualnym uczniem, powinieneś wiedzieć, że większość rozwiązań dostępnych na rynku oferuje wizualizacje danych.
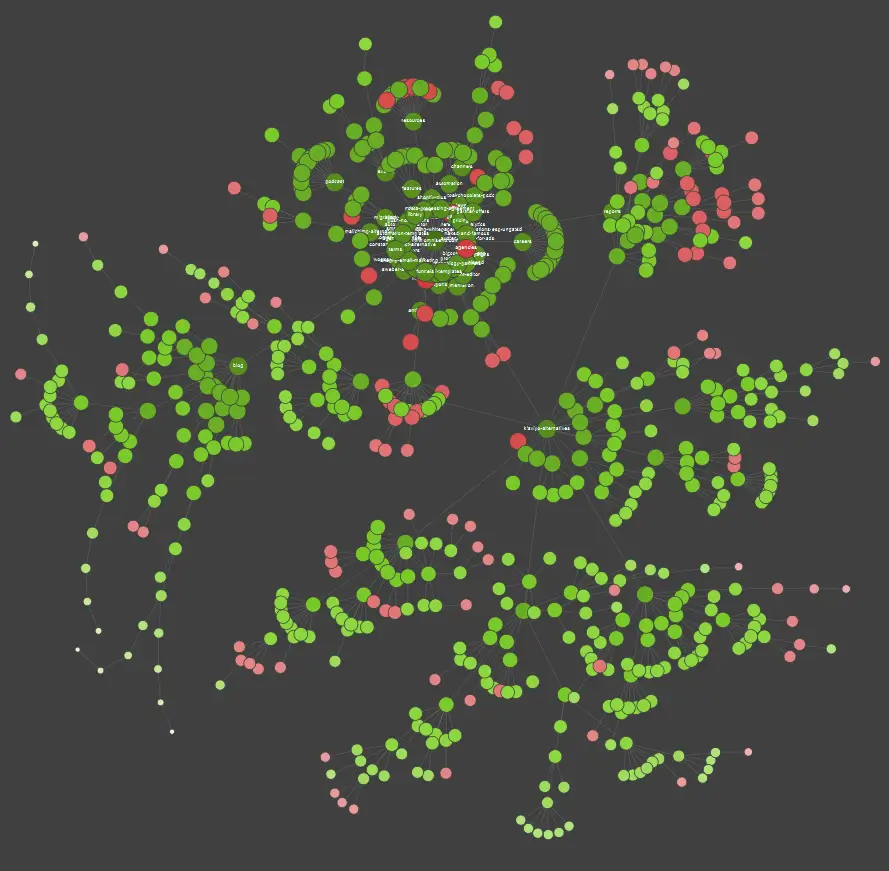
W powyższym przykładzie czerwone kropki oznaczają strony nieindeksowane. Poświęć chwilę na rozważenie ich przydatności i wpływu na działanie serwisu. Jeśli dzienniki serwera ujawniają, że te strony marnują dużo czasu Google, nie dodając żadnej wartości – czas poważnie przeanalizować kwestię utrzymywania ich w witrynie.
Ważne : jeśli chcemy jak najdokładniej odtworzyć zachowanie Googlebota, konieczne są odpowiednie ustawienia. Tutaj możesz zobaczyć przykładowe ustawienia z mojego komputera:
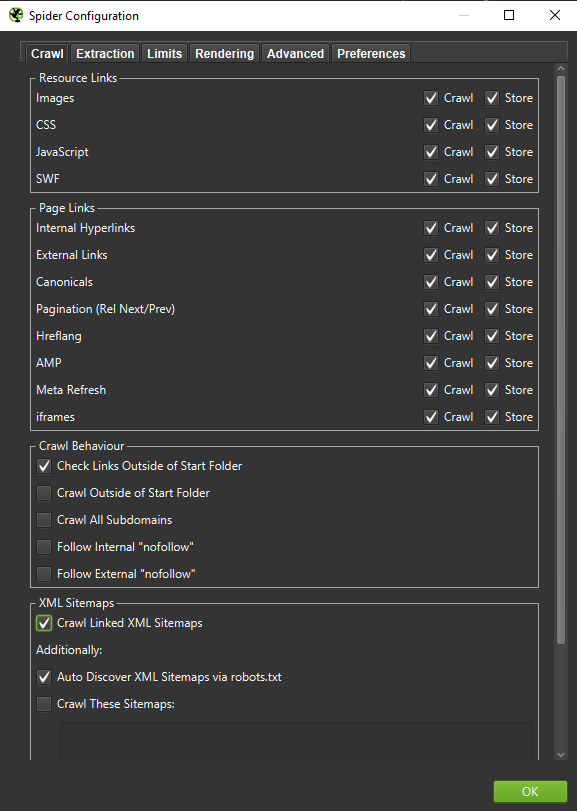
Przeprowadzając dogłębną analizę, dobrze jest przetestować dwa tryby – Tylko tekst, ale także JavaScript – aby porównać różnice (jeśli występują).

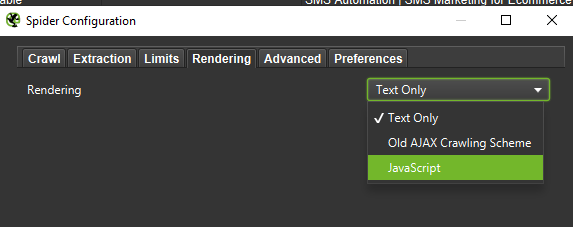
Wreszcie, nigdy nie zaszkodzi przetestować konfigurację przedstawioną powyżej na dwóch różnych agentach użytkownika:
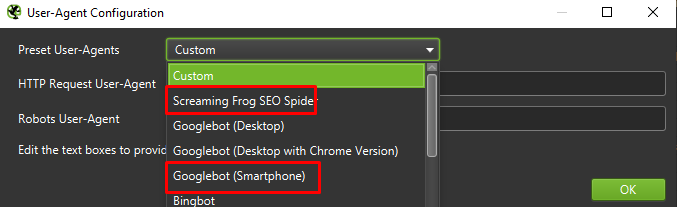
W większości przypadków wystarczy skupić się na wynikach zindeksowanych/renderowanych przez agenta mobilnego.
Ważne: Proponuję również skorzystać z możliwości, jaką daje Screaming Frog i nakarmić swojego robota danymi z GA i Google Search Console. Integracja to szybki sposób na zidentyfikowanie marnotrawstwa budżetu indeksowania, takich jak znaczna część potencjalnie nadmiarowych adresów URL, które nie otrzymują żadnego ruchu.
Narzędzia do analizy logów (Screaming Frog Logfile i inne)
Wybór analizatora logów serwera jest kwestią osobistych preferencji. Moim głównym narzędziem jest Analizator plików dziennika Screaming Frog. Może nie jest to najwydajniejsze rozwiązanie (załadowanie ogromnej paczki logów = zawieszenie aplikacji), ale interfejs mi się podoba. Ważną częścią jest nakazanie systemowi wyświetlania tylko zweryfikowanych Googlebotów.
Narzędzia do śledzenia widoczności
Pomocna pomoc, ponieważ pozwalają zidentyfikować najlepsze strony. Jeśli strona jest wysoko w rankingu dla wielu słów kluczowych w Google (= otrzymuje duży ruch), może potencjalnie mieć większe zapotrzebowanie na indeksowanie (sprawdź to w logach – czy Google naprawdę generuje więcej odwiedzin dla tej konkretnej strony?).
Do naszych celów będziemy potrzebować raportów ogólnych w Senuto — Ścieżki i adresy URL — do dalszego sprawdzania w przyszłości. Oba raporty są dostępne w Analizie widoczności, w zakładce Przekroje. Spójrz:
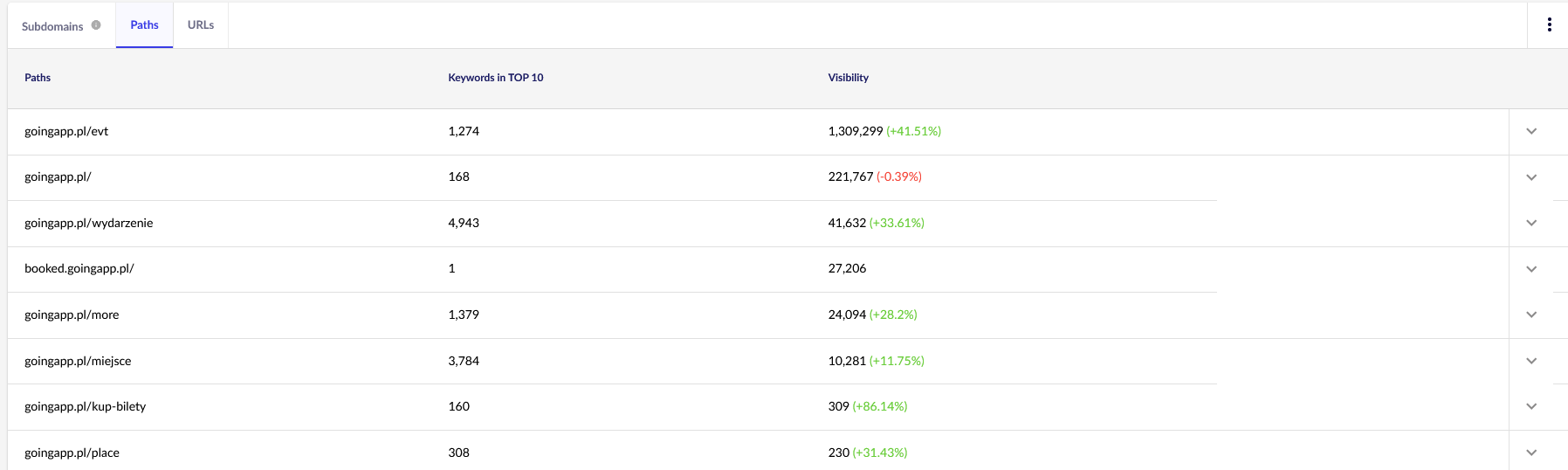
Naszym głównym punktem zainteresowania jest drugi raport. Posortujmy to pod kątem widoczności naszych słów kluczowych (lista i łączna liczba słów kluczowych, na które nasza strona plasuje się w TOP 10). Wyniki posłużą nam do określenia głównej osi stymulacji (i efektywnej alokacji) naszego budżetu indeksowania.
Narzędzia do analizy linków zwrotnych (Ahrefs, Majestic)
Jeśli jedna z Twoich stron ma dużą liczbę linków przychodzących, użyj jej jako filaru strategii optymalizacji budżetu indeksowania. Popularne strony mogą przejąć rolę hubów, które dalej przenoszą sok. Dodatkowo popularna strona z przyzwoitą pulą wartościowych linków ma większą szansę na przyciągnięcie częstych indeksowań.
W Ahrefs potrzebujemy raportu Pages, a dokładnie jego części zatytułowanej: „Best by links”:
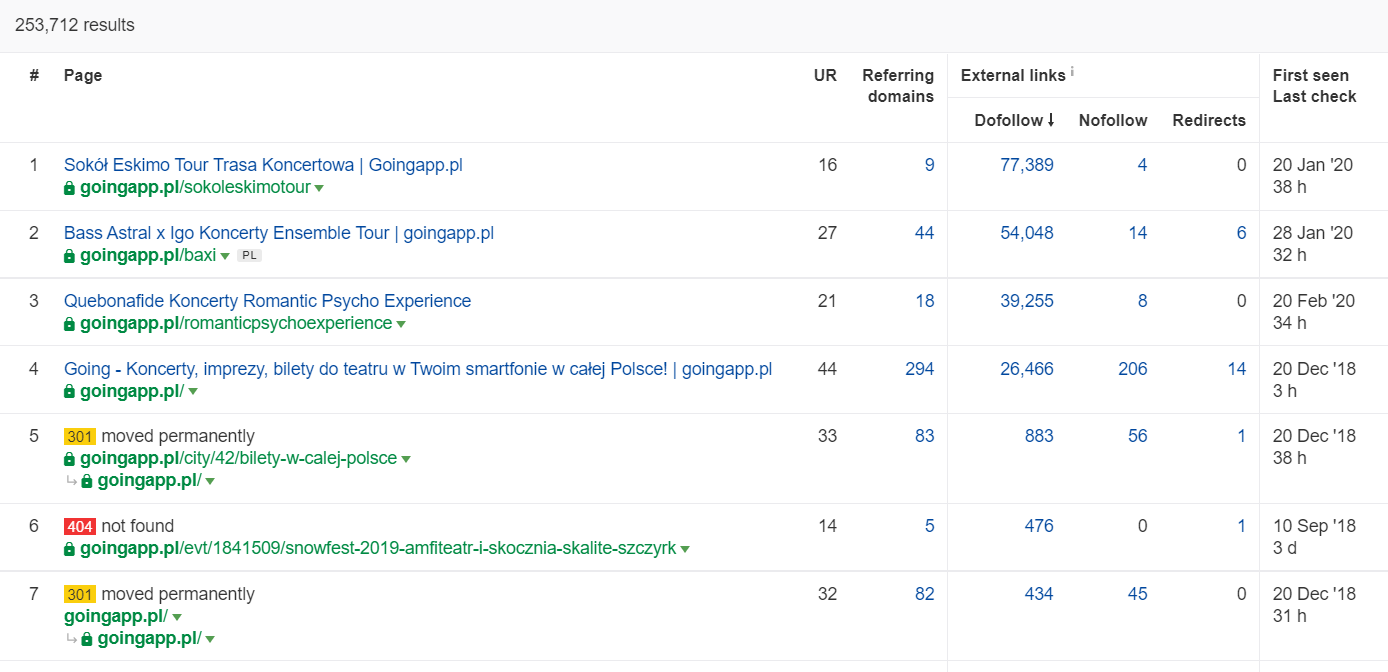
Powyższy przykład pokazuje, że niektóre płyty LP związane z koncertami nadal generowały solidne statystyki dla linków zwrotnych. Nawet jeśli wszystkie koncerty zostały odwołane z powodu pandemii, nadal opłaca się używać historycznie potężnych stron, aby wzbudzić ciekawość pełzających botów i rozprzestrzenić sok w głębsze zakamarki swojej witryny.
Jakie są wymowne oznaki problemu z budżetem indeksowania?
Uświadomienie sobie, że masz do czynienia z problematycznym (zbyt niskim) budżetem na indeksowanie, nie przychodzi łatwo. Czemu? Przede wszystkim dlatego, że SEO to niezwykle złożone przedsięwzięcie. Niskie pozycje lub problemy z indeksowaniem mogą być równie dobrze konsekwencją przeciętnego profilu linków lub braku odpowiedniej treści na stronie.
Zazwyczaj diagnostyka budżetu indeksowania obejmuje sprawdzenie:
- Ile czasu mija od publikacji do indeksacji nowych stron (postów na blogu/produktów), zakładając, że nie żądasz indeksowania przez Google Search Console?
- Jak długo Google przechowuje nieprawidłowe adresy URL w swoim indeksie? Uwaga: przekierowane adresy są wyjątkiem – Google przechowuje je celowo.
- Czy masz strony, które trafiają do indeksu tylko po to, aby później zniknąć?
- Ile czasu spędza Google na stronach, które nie generują wartości (ruchu)? Przejdź do analizy logów, aby się dowiedzieć.
Jak analizować i optymalizować budżet indeksowania?
Decyzja o pogrążeniu się w optymalizacji budżetu indeksowania jest podyktowana głównie rozmiarem Twojej witryny. Google sugeruje, że ogólnie rzecz biorąc, witryny zawierające mniej niż 1000 stron nie powinny zadręczać się maksymalnym wykorzystaniem dostępnych limitów indeksowania. W mojej książce powinieneś zacząć walczyć o wydajniejsze i skuteczniejsze indeksowanie, jeśli Twoja witryna zawiera ponad 300 stron, a zawartość dynamicznie się zmienia (na przykład ciągle dodajesz nowe strony / posty na blogu).
Czemu? To kwestia higieny SEO. Wdrażaj dobre nawyki optymalizacyjne i rozsądne zarządzanie budżetem indeksowania na początku, a w przyszłości będziesz mieć mniej do poprawienia i przeprojektowania.
Optymalizacja budżetu indeksowania. Standardowa procedura
Ogólnie praca nad analizą i optymalizacją Craw Budget składa się z trzech etapów:
- Zbieranie danych, czyli proces kompilowania wszystkiego, co wiemy o serwisie – zarówno od webmasterów, jak i narzędzi zewnętrznych.
- Analiza widoczności i identyfikacja nisko wiszących owoców. Co działa jak w zegarku? Co mogło być lepiej? Jakie obszary mają największy potencjał wzrostu?
- Zalecenia dotyczące budżetu indeksowania.
Zbieranie danych do audytu budżetu indeksowania
1. Pełne indeksowanie witryny za pomocą jednego z dostępnych na rynku narzędzi. Celem jest wykonanie co najmniej dwóch indeksowań: pierwsze symuluje Googlebota, a drugie pobiera witrynę jako domyślny klient użytkownika (zrobi to klient użytkownika przeglądarki). Na tym etapie interesuje Cię jedynie pobranie 100% zawartości . Jeśli zauważysz, że crawler wpadł w pętlę (gdy po dniu indeksowania nadal mamy na dysku tylko 10% strony) – daj znać, że wystąpił problem i możesz zatrzymać indeksowanie. Rozsądna liczba adresów URL do analizy w przypadku dużych serwisów to około 250-300 tys. stron.
a) To, czego szukamy, to głównie wewnętrzne przekierowania 301, błędy 404, ale także sytuacje, w których Twoje teksty mogą zostać sklasyfikowane jako cienkie treści. Screaming Frog ma opcję wykrywania prawie zduplikowanych treści:
2. Dzienniki serwera . Idealny przedział czasowy to ostatni miesiąc, jednak w przypadku dużych serwisów wystarczą dwa ostatnie tygodnie. W najlepszym przypadku powinniśmy mieć dostęp do historycznych dzienników serwera, aby porównać ruchy Googlebota w czasie, gdy wszystko szło gładko.
3. Eksport danych z Google Search Console . W połączeniu z punktami 1 i 2 powyżej, dane z Indeksu Pokrycia i Statystyk Indeksowania powinny dać Ci dość obszerny opis wszystkich wydarzeń na Twojej stronie.
4. Organiczne dane o ruchu . Najpopularniejsze strony według Google Search Console, Google Analytics, a także Senuto i Ahrefs. Chcemy zidentyfikować wszystkie strony, które wyróżniają się z tłumu dzięki statystykom wysokiej widoczności, natężeniu ruchu lub liczbie linków zwrotnych. Te strony powinny stać się podstawą Twojej pracy nad budżetem indeksowania. Wykorzystamy je, aby usprawnić indeksowanie najważniejszych stron.
5. Ręczny przegląd indeksu . W niektórych przypadkach najlepszy przyjaciel eksperta SEO to proste rozwiązanie. W tym przypadku: przegląd danych zaczerpniętych prosto z indeksu! Warto sprawdzić swoją stronę za pomocą kombinacji inurl: + site: operatorzy.Na koniec musimy scalić wszystkie zebrane dane. Zazwyczaj korzystamy z zewnętrznego robota indeksującego z funkcjami umożliwiającymi import danych zewnętrznych (dane GSC, dzienniki serwera i dane o ruchu organicznym).
Analiza widoczności i nisko wiszące owoce
Proces wymaga osobnego artykułu, ale naszym dzisiejszym celem jest uzyskanie widoku z lotu ptaka na nasze cele dotyczące strony internetowej i poczynione postępy. Interesuje nas wszystko, co niezwykłe: nagłe spadki ruchu (którego nie da się wytłumaczyć sezonowymi trendami) i jednoczesne zmiany widoczności organicznej. Sprawdzamy, które grupy stron są najsilniejsze, ponieważ staną się one naszymi HUBAMI do wpychania Googlebota głębiej w naszą witrynę.
W idealnym świecie taka kontrola powinna objąć całą historię naszego serwisu od momentu jego uruchomienia. Ponieważ jednak ilość danych rośnie z każdym miesiącem, skupmy się na analizie widoczności i ruchu organicznego z ostatnich 12 miesięcy.
Budżet indeksowania – nasze rekomendacje
Wymienione powyżej działania będą się różnić w zależności od wielkości pozycjonowanej strony. Są to jednak najważniejsze elementy, które zawsze uwzględniam podczas analizy budżetu indeksowania. Nadrzędnym celem jest wyeliminowanie wąskich gardeł w Twojej witrynie. Innymi słowy, aby zagwarantować maksymalne indeksowanie robotom Google (lub innym agentom indeksującym).
1. Zacznijmy od podstaw – eliminacja wszelkiego rodzaju błędów 404/410, analiza wewnętrznych przekierowań i ich usunięcie z linkowania wewnętrznego . Powinniśmy zakończyć naszą pracę ostatnim indeksowaniem. Tym razem wszystkie linki powinny zwracać kod odpowiedzi 200, bez wewnętrznych przekierowań i błędów 404.
- Na tym etapie dobrym pomysłem jest skorygowanie wszystkich łańcuchów przekierowań wykrytych w raporcie linków zwrotnych.
2. Po zindeksowaniu upewnij się, że struktura naszej witryny nie zawiera rażących duplikatów .
- Sprawdź również pod kątem potencjalnej kanibalizacji – poza problemami wynikającymi z kierowania tego samego słowa kluczowego na wiele stron (w skrócie, przestajesz kontrolować, która strona zostanie wyświetlona przez Google), kanibalizacja negatywnie wpływa na cały budżet indeksowania.
- Skonsoliduj zidentyfikowane duplikaty w jeden adres URL (zwykle ten, który ma wyższą pozycję w rankingu).
3. Sprawdź, ile adresów URL ma tag noindex . Jak wiemy, Google nadal może poruszać się po tych stronach. Po prostu nie pojawiają się w wynikach wyszukiwania. Staramy się minimalizować udział tagów noindex w strukturze naszej witryny.
- Przykład – blog porządkuje swoją strukturę za pomocą tagów; autorzy twierdzą, że rozwiązanie jest podyktowane wygodą użytkownika. Każdy post jest oznaczony 3–5 tagami, przypisanymi niespójnie i nieindeksowanymi. Analiza logów pokazuje, że jest to trzecia najczęściej indeksowana struktura na stronie.
4. Przejrzyj plik robots.txt . Pamiętaj, że wdrożenie robots.txt nie oznacza, że Google nie wyświetli adresu w indeksie.
- Sprawdź, które z zablokowanych struktur adresowych są nadal indeksowane. Może ich odcięcie powoduje wąskie gardło?
- Usuń nieaktualne/niepotrzebne dyrektywy.
5. Przeanalizuj ilość niekanonicznych adresów URL w Twojej witrynie. Google przestał uważać rel="canonical" za twardą dyrektywę. W wielu przypadkach atrybut jest wręcz ignorowany przez wyszukiwarkę (sortowanie parametrów w indeksie – wciąż koszmar).
6. Analizuj filtry i mechanizm ich działania . Filtrowanie ofert to największy problem związany z optymalizacją budżetu indeksowania. Właściciele firm e-commerce nalegają na wdrażanie filtrów mających zastosowanie w dowolnej kombinacji (na przykład filtrowanie według koloru + materiału + rozmiaru + dostępności… do entuzjastycznego razu). Rozwiązanie nie jest optymalne i powinno być ograniczone do minimum.
7. Architektura informacji w serwisie – uwzględniająca cele biznesowe, potencjał ruchu i aktualny profil linków. Przyjmijmy założenie, że link do treści krytycznych dla naszych celów biznesowych powinien być widoczny w całej witrynie (na wszystkich stronach) lub na stronie głównej. Upraszczamy tutaj oczywiście, ale strona główna i górne menu / linki w całej witrynie są najpotężniejszymi wskaźnikami budowania wartości z linków wewnętrznych. Jednocześnie staramy się osiągnąć optymalny rozkład domeny: naszym celem jest sytuacja, w której możemy rozpocząć indeksowanie z dowolnej strony i nadal docierać do tej samej liczby stron (każdy URL powinien mieć jeden link przychodzący NA MINIMUM) .
- Praca nad solidną architekturą informacji jest jednym z kluczowych elementów optymalizacji budżetu indeksowania. Pozwala nam uwolnić część zasobów bota z jednej lokalizacji i przekierować je do innej. To także jedno z największych wyzwań, gdyż wymaga współpracy interesariuszy biznesowych – co często prowadzi do ogromnych batalii i krytyki podważającej rekomendacje SEO.
8. Renderowanie treści. Krytyczne w przypadku stron internetowych, które mają oprzeć swoje wewnętrzne linkowanie na systemach rekomendujących wychwytujących zachowanie użytkowników. Przede wszystkim większość z tych narzędzi opiera się na plikach cookie. Google nie przechowuje plików cookie, więc nie otrzymuje spersonalizowanych wyników. Wynik: Google zawsze widzi te same treści lub w ogóle ich nie widzi.
- Częstym błędem jest uniemożliwienie Googlebotowi dostępu do krytycznej zawartości JS/CSS. Ten ruch może prowadzić do problemów z indeksowaniem stron (i marnować czas Google na renderowanie niedostępnych treści).
9. Wydajność strony internetowej – podstawowe wskaźniki internetowe . Choć podchodzę sceptycznie do wpływu CWV na rankingi witryn (z wielu powodów, w tym różnorodności dostępnych komercyjnie urządzeń i różnej szybkości łącza internetowego), jest to jeden z parametrów, który najbardziej warto omówić z koderem.
10. Sitemap.xml – sprawdź, czy działa i zawiera wszystkie kluczowe elementy (nic poza kanonicznymi adresami URL zwracającymi kod statusu 200).
- Moją pierwszą rekomendacją do optymalizacji sitemap.xml jest podzielenie stron według typu lub – jeśli to możliwe – kategorii. Podział da Ci pełną kontrolę nad ruchami Google i indeksacją treści.