
Alcançando a resiliência com filas: construindo um sistema que nunca perde uma batida em um bilhão
Publicados: 2018-12-21A Braze processa bilhões e bilhões de eventos por dia em nome de seus clientes, resultando em bilhões de mensagens personalizadas e hiperfocadas enviadas a seus usuários finais. Deixar de enviar uma dessas mensagens tem consequências, seja um recebimento perdido ou - pior ainda - uma notificação perdida informando ao usuário que sua comida está pronta. Para garantir que essas mensagens-chave estejam sempre corretas e sempre pontuais, a Braze adota uma abordagem estratégica de como alavancamos as filas de tarefas.
O que é uma fila de tarefas?
Uma fila de tarefas típica é um padrão de arquitetura em que os processos enviam tarefas de computação para uma fila e outros processos realmente executam as tarefas. Isso geralmente é uma coisa boa — quando usado corretamente, oferece graus de simultaneidade, escalabilidade e redundância que você não consegue com um paradigma tradicional de solicitação-resposta. Muitos trabalhadores podem estar executando diferentes trabalhos simultaneamente em vários processos, várias máquinas ou até vários data centers para simultaneidade de pico. Você pode designar determinados nós do trabalhador para trabalhar em determinadas filas e enviar tarefas específicas para filas específicas, permitindo dimensionar recursos conforme necessário. Se um processo de trabalho falhar ou um datacenter ficar offline, outros trabalhadores poderão executar os trabalhos restantes.
Embora você certamente possa aplicar esses princípios e executar um sistema de enfileiramento de tarefas facilmente em pequena escala, as costuras começam a aparecer (e até estourar) quando você está processando bilhões e bilhões de tarefas. Vamos dar uma olhada em alguns problemas que a Braze enfrentou à medida que crescemos do processamento de milhares, para milhões e agora bilhões de empregos por dia.
A falta de consistência é uma fraqueza
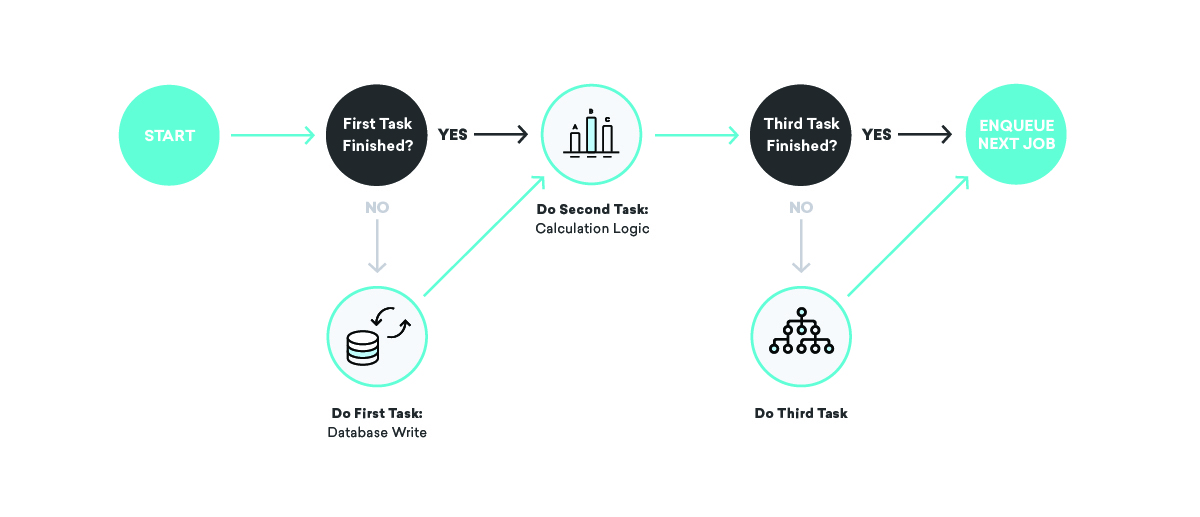
O que acontece se enviarmos uma mensagem, mas falharmos antes de registrar o fato de que acabamos de enviar essa mensagem?
Alguns resultados ruins diferentes são possíveis aqui. Primeiro, você pode reprogramar o trabalho com falha e enviar a mensagem novamente. Isso não é o ideal: ninguém quer receber a mesma coisa duas vezes. Em vez disso, considere não reagendá-lo. Nesse caso, nossa contabilidade interna estará incorreta, portanto, atribuições, conversões e todo tipo de outras coisas não estarão corretas no futuro.
Como corrigimos isso? Ao escrever nossas definições de trabalho, pensamos muito sobre idempotência e comportamento de repetição.
Quando você está falando sobre filas, idempotência significa que um único trabalho pode ser encerrado em um ponto arbitrário, o trabalho reenfileirado novamente em sua totalidade e o resultado final será o mesmo que se tivéssemos executado com êxito exatamente um trabalho Tempo. Isso está intimamente ligado ao nosso comportamento de escolha de repetição – entrega pelo menos uma vez. Tendo em mente que todos os nossos trabalhos serão executados pelo menos uma vez, e talvez várias vezes, podemos escrever definições de trabalho idempotentes que garantem consistência mesmo diante de falhas aleatórias.
Voltando ao nosso exemplo de envio de mensagens, como podemos usar esses conceitos para garantir consistência? Nesse caso, podemos dividir o trabalho em duas partes, com a primeira enviando a mensagem e enfileirando a segunda, e a segunda gravando no banco de dados. Nesse cenário, podemos tentar novamente qualquer trabalho quantas vezes quisermos — se o provedor de envio de mensagens estiver inativo ou o banco de dados de contabilidade interno estiver inativo, tentaremos novamente até que tenhamos sucesso!
Boas cercas fazem bons vizinhos
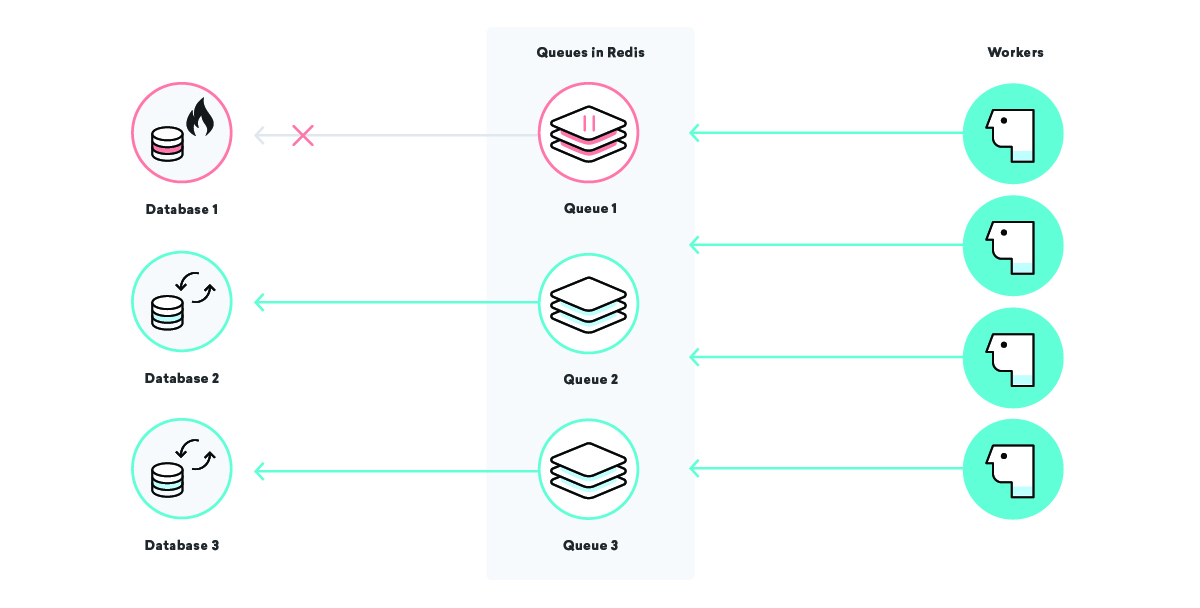
O que acontece com o processamento de dados da nossa empresa de exemplo Consolidated Widgets quando o banco de dados do Global Gizmos está inativo?
Nesse cenário, se nossa estratégia de entrega pelo menos uma vez estiver em jogo, esperaríamos que todos os trabalhos de processamento de dados do Global Gizmos fossem repetidos várias vezes até serem bem-sucedidos. Isso é ótimo - não perderemos nenhum dado mesmo enquanto o banco de dados estiver inativo. Para Consolidated Widgets, no entanto, pode não ser tão grande: se os trabalhadores estão constantemente tentando e falhando, eles podem estar muito ocupados para processar o trabalho dos Consolidated Widgets em tempo hábil.
Podemos corrigir isso usando nomes de filas bem escolhidos e pausando determinadas filas conforme necessário. Com isso em nosso cinto de ferramentas, podemos aliviar a tensão em peças de infraestrutura de maneira cirúrgica. Em nosso cenário acima, uma vez que sabemos que o banco de dados da Global Gizmos está inativo, podemos pausar sua fila de processamento de dados até sabermos que está de volta, garantindo que uma interrupção específica não afete nenhum outro cliente!

Esperar é doloroso
E se Consolidated Widgets e Global Gizmos enviarem campanhas de e-mail para 50 milhões de usuários cada, com 5 minutos de intervalo? Quem vai primeiro?
Os sistemas simples de enfileiramento de tarefas têm uma fila simples de "trabalho" da qual os funcionários extraem os trabalhos. Uma vez que você tenha uma boa variedade de trabalhos e tipos de trabalho, você provavelmente passará a ter vários tipos de filas, cada uma com diferentes prioridades ou tipos de trabalhadores puxando dessas filas. Nesse sentido, temos uma variedade de filas simples para processamento de dados, mensagens e várias tarefas de manutenção.
Avançando para quando você estiver enviando bilhões de mensagens personalizadas por dia, uma fila de "mensagens" não será suficiente - o que acontece quando essa fila fica extremamente grande, como em nosso exemplo acima? Priorizamos os trabalhos que chegaram primeiro?
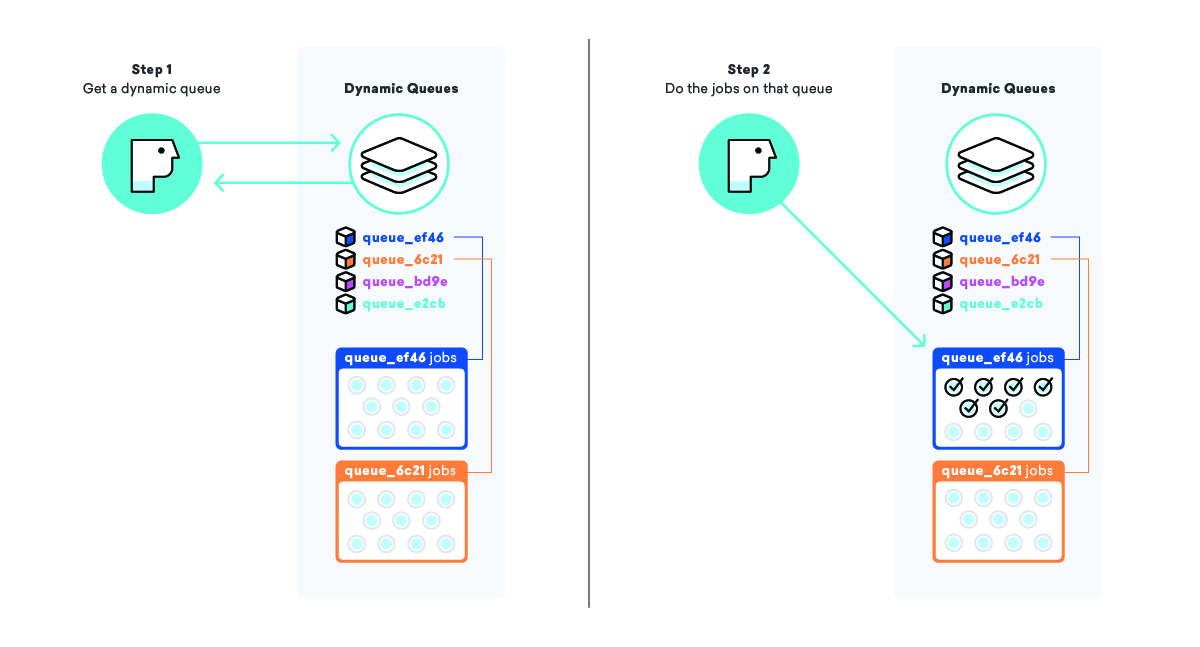
Nosso sistema de enfileiramento dinâmico procura abordar um fenômeno chamado de inanição de tarefas, em que uma tarefa que está pronta para ser executada aguarda muito tempo antes de ser executada, geralmente devido a algum tipo de prioridade. Em uma fila de "mensagem" simples, a prioridade é simplesmente a hora em que o trabalho entrou na fila, o que significa que os trabalhos adicionados ao final de uma grande fila podem acabar esperando por muito tempo.
Quando vamos enfileirar uma campanha e todas as suas mensagens, em vez de adicionar os jobs a uma grande fila de "mensagens", criamos uma fila totalmente nova apenas para esta campanha, completa com um nome especial para sabermos o que é e como encontrá-lo. Depois de adicionar os trabalhos à fila, pegamos nossa lista de “filas dinâmicas” e adicionamos esse novo nome de fila ao final.
Ao empregar essa estratégia, podemos instruir os trabalhadores a selecionar o nome de uma fila dinâmica da lista de “filas dinâmicas” e, em seguida, processar todos os trabalhos nessa fila específica. Isso nos permite garantir que as mensagens sejam enviadas o mais rápido possível E que todos os nossos clientes sejam tratados com a mesma prioridade.
Consequentemente, isso tem outros benefícios, como taxas de acerto de cache mais altas e menos conexões de banco de dados, devido ao aumento da localidade de trabalho para determinados trabalhadores. Todos ganham!
Tenha sempre um plano de backup
O que acontece quando um banco de dados está inativo, algumas filas são pausadas e as filas de trabalhos começam a ser preenchidas?
Às vezes, peças importantes de infraestrutura simplesmente morrem em você. Temos secundários e backups instalados, mas o tempo que leva para promover a infraestrutura de backup quase nunca é zero. Ter várias camadas de filas em toda a infraestrutura do aplicativo pode ser muito útil para mitigar o impacto desses tipos de eventos.
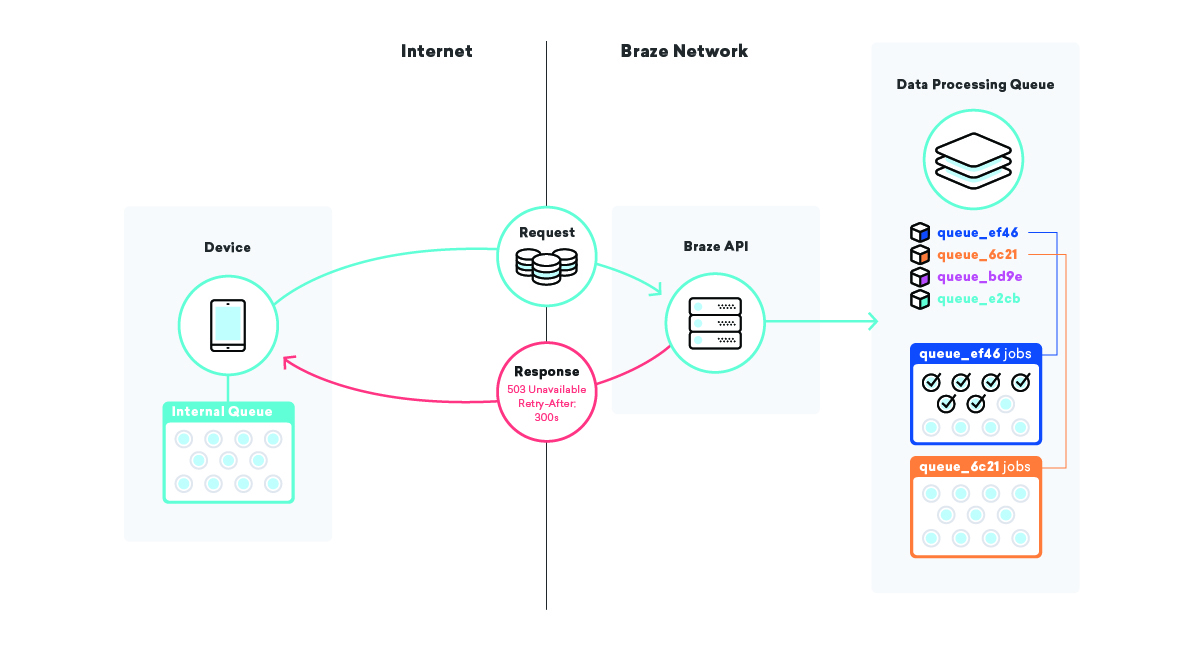
Uma dessas estratégias que empregamos é enfileirar nos próprios dispositivos. Milhões e milhões de dispositivos têm aplicativos diferentes usando um SDK Braze e, nesses aplicativos, utilizamos uma fila para enviar dados para nossas APIs.
Quando nosso SDK envia esses dados e falha, por qualquer motivo, o SDK enfileira uma nova tentativa usando um algoritmo de recuo exponencial até que seja bem-sucedido. Essa estratégia minimiza o impacto de falhas de infraestrutura ou de código, pois os dispositivos simplesmente enfileirarão seus próprios dados e os enviarão para o Braze quando tudo estiver online novamente.
Movendo-se rápido e não quebrando as coisas
No final das contas, nosso objetivo é enviar mensagens personalizadas e hiperfocadas melhor do que qualquer outra pessoa, e isso envolve agir rapidamente, ser resiliente e fazer tudo certo. As filas de tarefas estão no centro da infraestrutura da Braze, por isso estamos sempre observando nosso desempenho, empregando as melhores práticas e experimentando novas estratégias e técnicas avançadas para sermos os melhores no jogo.
Se esse tipo de engenharia de sistemas de alto desempenho e baixa latência no espaço de automação de marketing o excita, você deve definitivamente verificar nosso quadro de empregos!