
O estado do aprendizado profundo: de uma perspectiva de desenvolvedor e VC
Publicados: 2017-09-05Nikhil Kapur discute o estado do aprendizado profundo, primeiro como desenvolvedor estudante e agora como VC
Passei um sábado em um workshop de deep learning e TensorFlow no gigantesco escritório de nível 3 da Unilever Foundry e Padang.co. Foi um dia divertido estar imerso no mundo dos desenvolvedores novamente, e eu gostei de todas as conversas com meus colegas de mesa, um deles administrando uma empresa familiar e aprendendo ML/deep learning como hobby (ele é um entusiasta de programação) e o outro de Departamento de marketing da Zalora procurando aplicar alguma IA em seu trabalho.
Começamos configurando o TensorFlow e o Keras (uma abstração sobre o TensorFlow) em nossas máquinas e, em seguida, começamos a mexer em alguns dos problemas comuns de aprendizado profundo e exemplos, como o uso do conjunto de dados MNIST. Começando com um pequeno modelo simples de PNL para reconhecimento de texto, mergulhamos nas Redes Neurais Convolucionais , que acabou sendo muito divertida de se brincar.
Estávamos usando modelos pré-treinados prontos para uso, como o Inception V3, mas estávamos brincando com nossos próprios conjuntos de dados e treinando novamente o modelo para resolver problemas diferentes, como "Isso é um gato ou um cachorro?" O objetivo da aula era entender os fundamentos do aprendizado profundo e experimentar parâmetros e recursos. Se você já está com ciúmes, sugiro que vá brincar com o playground.tensorflow.org, foi a parte mais fácil do workshop!
Um enorme grito para Sam Witteveen e Martin Andrews por organizarem isso. Conto aqui algumas das perspectivas com as quais saí e onde vejo o aprendizado profundo e a IA em geral, especialmente do ponto de vista do VC.
Aprendizado profundo da perspectiva de um desenvolvedor
Para dar um pouco de fundo, eu tive minha boa exposição à “IA”. No segundo ano da faculdade, estagiei no braço de Consultoria de Tecnologia da Deloitte. Junto com meu amigo Ujjwal Dasgupta, que mais tarde acabou fazendo mestrado em ML e agora está no Google, passei alguns meses produzindo um processo ETL (Extract-Transform-Load) aprimorado no IBM Datastage, um software de Data Warehousing. Na época, Ujjwal, que sempre foi muito mais avançado do que eu, me apresentou à mineração de dados e comecei a acompanhar as palestras e cursos online de Andrew Ng.
No próximo verão, intrigado com o tempo que já havia dedicado ao assunto, quis mergulhar mais fundo no ML. Tive a sorte de ser designado para um projeto na Mozilla para melhorar o desempenho do Firefox usando um compilador baseado em aprendizado de máquina - Milespot GCC. Usando este compilador de ML, consegui compilar o código do Mozilla Firefox para resultar em cerca de 10% de melhoria no tempo de carregamento do programa.
E então, para minha tese final, não havia como deixar de lado o ML. Colaborei com o DFKI, o Instituto Alemão de Inteligência Artificial para trabalhar em um projeto extremamente desafiador, usando uma webcam simples para rastreamento ocular. A equipe da DFKI estava usando isso para um aplicativo específico, o Text 2.0. Eles estavam usando uma câmera HD especial para rastrear seus olhos e, consequentemente, aumentar o texto com recursos mega legais , como rolagem automática, tradução automática, dicionário pop-up, etc.
Decidimos fazer o mesmo com uma webcam simples porque ninguém na Índia tinha dinheiro para comprar aquela câmera HD especial. Para ser preciso, falhamos nisso, alcançando apenas cerca de 70% de precisão em nosso rastreamento. Mas foi um dos projetos mais emocionantes em que trabalhei.
Recomendado para você:

Como o Metaverse transformará a indústria automobilística indiana

O que significa a provisão antilucratividade para startups indianas?

Como as startups de Edtech estão ajudando a qualificação da força de trabalho da Índia e se preparando para o futuro

Ações de tecnologia da nova era esta semana: os problemas do Zomato continuam, EaseMyTrip publica...

Startups indianas pegam atalhos em busca de financiamento

Plataforma de marketing digital Logicserve Bags Financiamento de INR 80 Cr, renomeia como LS Dig...
Então, por que estou entediando você com os detalhes disso? Principalmente para dar a você um pouco da história de onde a IA estava quando eu estava trabalhando na minha engenharia. Mesmo décadas atrás, deep learning e ML já existiam, mas foi apenas nos últimos 10 anos que o campo viu sua maturidade. O que exatamente mudou nos últimos anos?

Bem, por um lado, a lei de Moore nos levou a um ponto em que o custo de armazenamento e processamento se tornou mínimo para alguém implementar ML em sua casa. Agora você pode executar praticamente todos os modelos básicos em sua própria máquina e, se comprar uma boa GPU (que não é mais tão cara), ela pode otimizar seu tempo de computação em quase 10 vezes para poder executar modelos complexos.
A revista Wired tem um ótimo artigo sobre essa mudança.
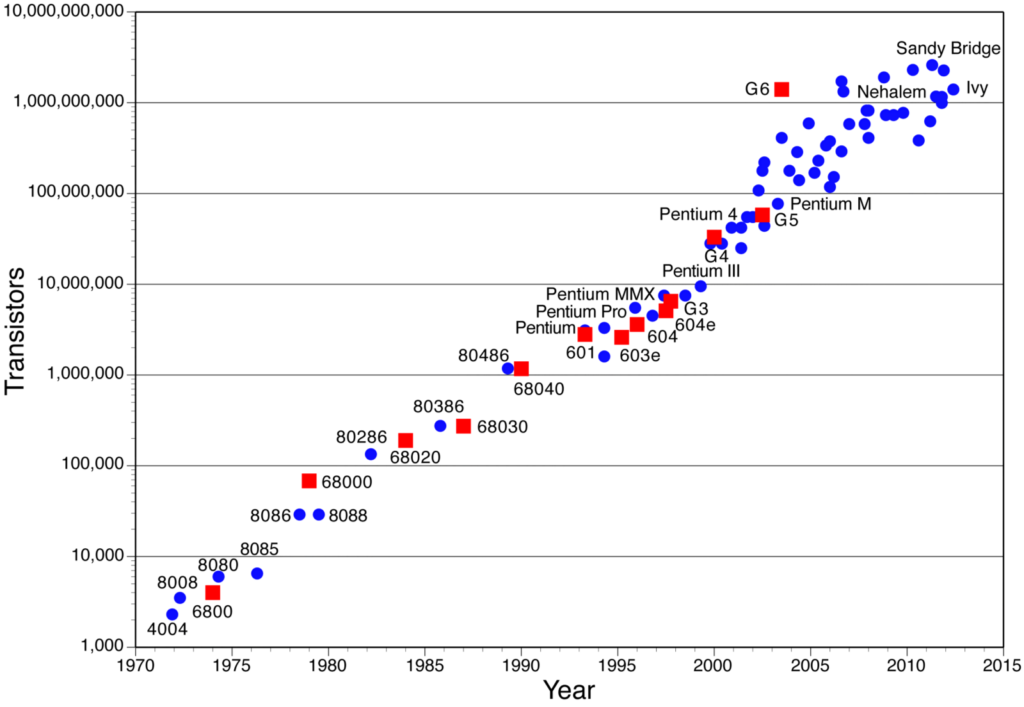
Número de transistores em chips ao longo do ano (observe que o eixo Y é escala logarítmica!). Fonte: Assured-Systems
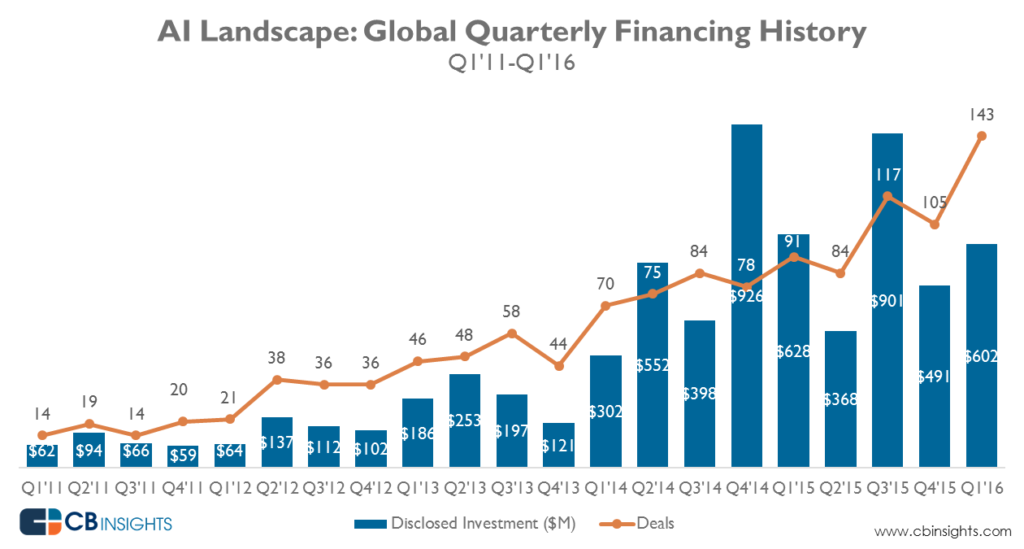
Outra coisa que mudou é que as empresas perceberam a necessidade de automatizar. Como resultado disso, embora a atividade de M&A no campo tenha aumentado tremendamente, os VCs vêm investindo dinheiro no campo nos últimos 5 anos.
Perspectivas do Investidor sobre Aprendizado Profundo
Então, onde estamos agora e como um investidor ou startup deve ver esse zumbido extremo da IA? A meu ver, existem quatro aspectos-chave para uma startup de IA, todos os quais precisam se unir para formar uma empresa forte.
- Talento: Tudo começa aqui. Enquanto em uma startup, a equipe é obviamente o aspecto mais importante, em uma startup de IA é o verdadeiro motor da empresa. O acesso a um forte talento em ciência de dados e engenharia de computação para ajustar esses modelos pré-construídos será fundamental para as startups de IA, e é por isso que as startups americanas e chinesas provavelmente liderarão em outras geografias. Cingapura tem uma pequena fatia de talento em ciência de dados e provavelmente será um bom lugar para configurar sua empresa de IA. Dito isso, os melhores talentos provavelmente acabarão indo para os gigantes da tecnologia de forma orgânica ou inorgânica. A aquisição da DeepMind pelo Google foi exatamente isso, uma jogada para adquirir algumas das melhores mentes em Deep Learning.
- Dados: se a equipe é o motor, os dados são a gasolina em uma inicialização de IA. Sem grandes quantidades de dados limpos e estruturados, é improvável que você consiga obter precisão do seu sistema treinado, prejudicando os aplicativos de negócios. Devido à dependência central dos recursos de previsão de um modelo nos dados alimentados, as empresas de grande porte provavelmente terão uma vantagem significativa sobre as startups de pequena escala na criação de sistemas melhores e mais precisos. Este é um pensamento preocupante e a única maneira de quebrar o molde será gerando e alavancando seus próprios dados proprietários. Um sistema de registros como o Salesforce será imensamente crítico nesse aspecto.
- Modelo: Todos os grandes gigantes da tecnologia estão atualmente lançando seus próprios sistemas de IA (plataforma de desenvolvimento, bibliotecas, modelos treinados) para criar a plataforma para o desenvolvimento de IA de amanhã. Ainda está para ser determinado quem vencerá a guerra, mas a necessidade de criar modelos do zero mais cedo ou mais tarde acabará. Apenas para sistemas realmente complexos haveria a necessidade de começar a construir seus modelos do básico, mas na maioria dos casos, seu cientista de dados poderá reutilizar modelos prontos para uso e treiná-los novamente usando seus próprios dados. Como você sabe que alcançou o melhor modelo possível? A Numerai, apoiada pela Union Square Ventures, está enfrentando esse problema de maneira muito inteligente, fazendo crowdsourcing para especialistas em ML e incentivando-os financeiramente a construir modelos melhores.
- Problema de negócios: é aqui que as coisas ficam interessantes. Em primeiro lugar, um usuário não se importa se seus sistemas são automatizados ou não. Os sistemas de IA destinam-se a otimizar sua própria organização e fazer com que uma máquina execute a tarefa de um humano, não para impressionar um usuário. Portanto, resolver um problema de negócios específico é fundamental para proporcionar uma boa experiência ao usuário e, portanto, aumentar a aderência.
Em segundo lugar, a maioria dos gigantes da tecnologia vai se restringir a construir uma plataforma ampla e genérica. Enquanto empresas de tecnologia como Salesforce, Hubspot, etc. estão pulando na IA, a delas provavelmente será uma rota de aquisição. A Salesforce já anunciou o Einstein (embora ainda não tenha cumprido adequadamente suas proclamações) e o Hubspot está escrevendo toda semana sobre IA em seu blog. Isso apenas mostra o quanto eles estão interessados no campo, mas também como é difícil para eles abordar problemas específicos. É aí que existem as lacunas que uma startup pode explorar e nossa empresa de portfólio, a Saleswhale, está exatamente seguindo esse caminho.
Aos meus olhos, se uma startup resolve através da automação um problema muito direcionado que afeta um número suficiente de pessoas usando dados proprietários que seus sistemas coletam no caminho, é provável que seja um negócio muito lucrativo com fortes barreiras à entrada. No entanto, até onde posso ver, é improvável que seja uma oportunidade do tamanho de um unicórnio na região, não enquanto os gigantes da tecnologia ainda estiverem vivos.
[Esta postagem de Nikhil Kapur apareceu pela primeira vez no Medium e foi reproduzida com permissão.]