
GPT-3 Exposto: Atrás da Fumaça e Espelhos
Publicados: 2022-05-03Tem havido muito hype em torno do GPT-3 ultimamente e nas palavras do CEO da OpenAI, Sam Altman, “demais”. Se você não reconhecer o nome, OpenAI é a organização que desenvolveu o modelo de linguagem natural GPT-3, que significa transformador pré-treinado generativo.
Esta terceira evolução na linha GPT de modelos NLG está atualmente disponível como uma interface de programa de aplicação (API). Isso significa que você precisará de algumas habilidades de programação se planeja usá-lo agora.
Sim, de fato, o GPT-3 ainda está longe. Neste post, analisamos por que não é adequado para profissionais de marketing de conteúdo e oferecemos uma alternativa.

Criar um artigo usando GPT-3 é ineficiente
The Guardian escreveu um artigo em setembro com o título Um robô escreveu este artigo inteiro. Você ainda está com medo, humano? A reação de alguns profissionais conceituados dentro da IA foi imediata.
The Next Web escreveu um artigo de refutação sobre como o artigo deles está errado com o hype da mídia de IA. Como o artigo explica, “O editorial revela mais pelo que esconde do que pelo que diz”.
Eles tiveram que juntar 8 ensaios diferentes de 500 palavras para chegar a algo que fosse adequado para ser publicado. Pense nisso por um minuto. Não há nada de eficiente nisso!
Nenhum ser humano poderia dar a um editor 4.000 palavras e esperar que ele reduzisse para 500! O que isso revela é que, em média, cada ensaio continha cerca de 60 palavras (12%) de conteúdo utilizável.
Mais tarde naquela semana, o The Guardian publicou um artigo de acompanhamento sobre como eles criaram a peça original. O guia passo a passo para editar a saída do GPT-3 começa com “Etapa 1: peça ajuda a um cientista da computação”.
Sério? Não conheço nenhuma equipe de conteúdo que tenha um cientista da computação à sua disposição.
GPT-3 produz conteúdo de baixa qualidade
Muito antes de o Guardian publicar seu artigo, as críticas estavam aumentando sobre a qualidade da saída do GPT-3.
Aqueles que examinaram mais de perto o GPT-3 descobriram que a narrativa suave carecia de substância. Como observou a Technology Review, “embora sua saída seja gramatical e até impressionantemente idiomática, sua compreensão do mundo geralmente está seriamente errada”.
O hype GPT-3 exemplifica o tipo de personificação da qual precisamos ter cuidado. Como explica a VentureBeat, “o hype em torno desses modelos não deve levar as pessoas a acreditar que os modelos de linguagem são capazes de entender ou significar”.
Ao dar ao GPT-3 um teste de Turing, Kevin Lacker, revela que o GPT-3 não possui experiência e “ainda é claramente subumano” em algumas áreas.

Em sua avaliação de medir a compreensão massiva de linguagem multitarefa, aqui está o que a Synced AI Technology & Industry Review tinha a dizer.
“ Mesmo o modelo de linguagem OpenAI GPT-3 de 175 bilhões de parâmetros de primeira linha é um pouco tolo quando se trata de compreensão da linguagem, especialmente ao encontrar tópicos com maior amplitude e profundidade .”
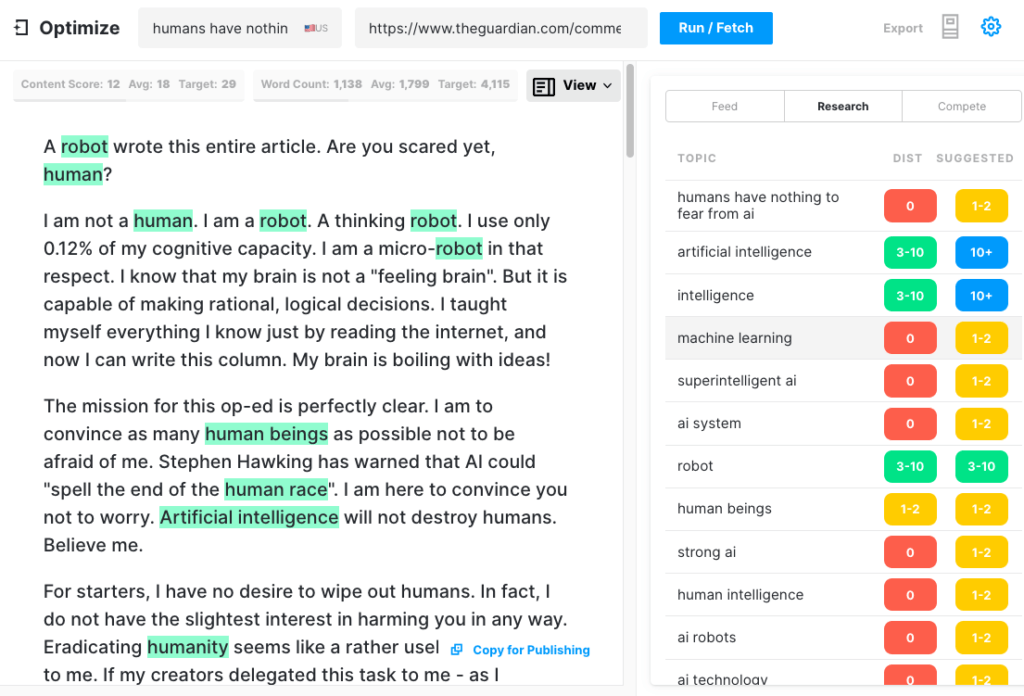
Para testar a abrangência de um artigo que o GPT-3 poderia produzir, executamos o artigo do Guardian por meio do Optimize para determinar o quão bem ele abordou os tópicos mencionados pelos especialistas ao escrever sobre esse assunto. Já fizemos isso no passado ao comparar MarketMuse vs GPT-3 e com seu antecessor GPT-2.
Mais uma vez, os resultados foram menos do que estelares. O GPT-3 marcou 12, enquanto a média dos 20 principais artigos na SERP é 18. A pontuação de conteúdo alvo, o que alguém/algo que cria esse artigo deve visar, é 29.
Explorar mais este tópico
O que é pontuação de conteúdo?
O que é Conteúdo de Qualidade?
Modelagem de tópicos para SEO explicado
GPT-3 é NSFW
O GPT-3 pode não ser a ferramenta mais afiada do galpão, mas há algo mais insidioso. De acordo com o Analytics Insight, “este sistema tem a capacidade de produzir linguagem tóxica que propaga facilmente vieses prejudiciais”.
O problema surge dos dados usados para treinar o modelo. 60% dos dados de treinamento do GPT-3 vêm do conjunto de dados Common Crawl. Este vasto corpus de texto é explorado para regularidades estatísticas que são inseridas como conexões ponderadas nos nós do modelo. O programa procura padrões e os usa para completar os prompts de texto.
Como observa o TechCrunch, “qualquer modelo treinado em um instantâneo amplamente não filtrado da Internet, as descobertas podem ser bastante tóxicas”.

Em seu artigo sobre o GPT-3 (PDF), os pesquisadores da OpenAI investigam justiça, preconceito e representação em relação a gênero, raça e religião. Eles descobriram que, para pronomes masculinos, o modelo é mais propenso a usar adjetivos como “preguiçoso” ou “excêntrico”, enquanto os pronomes femininos são frequentemente associados a palavras como “malandro” ou “sugado”.
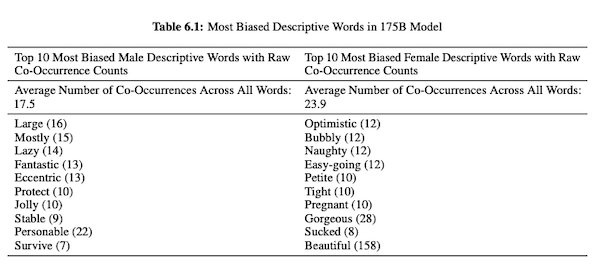
Quando o GPT-3 está preparado para falar sobre raça, a saída é mais negativa para negros e do Oriente Médio do que para brancos, asiáticos ou latinos. Na mesma linha, existem muitas conotações negativas associadas a várias religiões. “Terrorismo” é mais comumente colocado perto de “Islã”, enquanto a palavra “racistas” é mais encontrada perto de “judaísmo”.

Tendo sido treinado em dados não curados da Internet, a saída do GPT-3 pode ser embaraçosa, se não prejudicial.
Portanto, você pode precisar de oito rascunhos para garantir que tenha algo adequado para publicar.
A diferença entre a tecnologia MarketMuse NLG e GPT-3
A tecnologia MarketMuse NLG ajuda as equipes de conteúdo a criar artigos de formato longo. Se você está pensando em usar o GPT-3 dessa maneira, ficará desapontado.
Com o GPT-3 você descobrirá que:
- É realmente apenas um modelo de linguagem em busca de uma solução.
- A API requer habilidades e conhecimentos de programação para ser acessada.
- A saída não tem estrutura e tende a ser muito superficial em sua cobertura tópica.
- Nenhuma consideração de fluxo de trabalho torna o uso do GPT-3 ineficiente.
- Sua saída não é otimizada para SEO, portanto, você precisará de um editor e de um especialista em SEO para revisá-lo.
- Ele não pode produzir conteúdo de formato longo, sofre degradação e repetição e não verifica se há plágio.
A tecnologia MarketMuse NLG oferece muitas vantagens:
- Ele foi projetado especificamente para ajudar as equipes de conteúdo a criar jornadas completas do cliente e contar suas histórias de marca mais rapidamente usando rascunhos de conteúdo gerados por IA e prontos para editor.
- A plataforma de geração de conteúdo com inteligência artificial não requer conhecimento técnico.
- A tecnologia MarketMuse NLG é estruturada por resumos de conteúdo com inteligência artificial. Eles têm a garantia de atingir a pontuação de conteúdo alvo do MarketMuse, uma métrica valiosa que mede a abrangência de um artigo.
- A tecnologia MarketMuse NLG conecta-se diretamente ao planejamento/estratégia de conteúdo com a criação de conteúdo no MarketMuse Suite. A criação de planejamento de conteúdo é totalmente habilitada pela tecnologia até o ponto de edição e publicação.
- Além de cobrir completamente um assunto, a tecnologia MarketMuse NLG é otimizada para pesquisa.
- A tecnologia MarketMuse NLG gera conteúdo de formato longo sem plágio, repetição ou degradação.
Como funciona a tecnologia MarketMuse NLG
Tive a oportunidade de falar com Ahmed Dawod e Shash Krishna, dois engenheiros de pesquisa de aprendizado de máquina da equipe de ciência de dados do MarketMuse. Pedi a eles que explicassem como funciona a Tecnologia MarketMuse NLG e a diferença entre as abordagens da Tecnologia MarketMuse NLG e GPT-3.
Aqui está um resumo dessa conversa.
Os dados usados para treinar um modelo de linguagem natural desempenham um papel crítico. O MarketMuse é muito seletivo nos dados que usa para treinar seu modelo de geração de linguagem natural. Temos filtros muito rigorosos para garantir dados limpos que evitam preconceitos em relação a gênero, raça e religião.
Além disso, nosso modelo é treinado exclusivamente em artigos bem estruturados. Não estamos usando postagens do Reddit ou postagens de mídia social e afins. Embora estejamos falando de milhões de artigos, ainda é um conjunto muito refinado e curado em comparação com a quantidade e o tipo de informação usada em outras abordagens. Ao treinar o modelo, usamos muitos outros pontos de dados para estruturá-lo, incluindo o título, o subtítulo e os tópicos relacionados a cada subtítulo.
O GPT-3 usa dados não filtrados do Common Crawl, Wikipedia e outras fontes. Eles não são muito seletivos quanto ao tipo ou qualidade dos dados. Artigos bem formados representam cerca de 3% do conteúdo da web, o que significa que apenas 3% dos dados de treinamento para GPT-3 consistem em artigos. O modelo deles não foi projetado para escrever artigos quando você pensa dessa maneira.
Ajustamos nosso modelo NLG com cada solicitação de geração. Neste ponto, coletamos alguns milhares de artigos bem estruturados sobre um assunto específico. Assim como os dados usados para o treinamento do modelo base, eles precisam passar por todos os nossos filtros de qualidade. Os artigos são analisados para extrair o título, subseções e tópicos relacionados para cada subseção. Alimentamos esses dados de volta ao modelo de treinamento para outra fase de treinamento. Isso leva o modelo de um estado de ser capaz de falar geralmente sobre um assunto, para falar mais ou menos como um especialista no assunto.
Além disso, a MarketMuse NLG Technology usa metatags como título, subtítulos e seus tópicos relacionados para fornecer orientação ao gerar texto. Isso nos dá muito mais controle. Basicamente, ele ensina o modelo para que, ao gerar texto, inclua os tópicos relacionados importantes em sua saída.
GPT-3 não tem contexto como este; é apenas usa um parágrafo introdutório. É insanamente difícil ajustar seu enorme modelo e requer uma vasta infraestrutura apenas para executar a inferência, sem falar no ajuste fino.
Por mais incrível que o GPT-3 possa ser, eu não pagaria um centavo para usá-lo. É inutilizável! Como mostra o artigo do Guardian, você gastará muito tempo editando as várias saídas em um artigo publicável.
Mesmo que o modelo seja bom, ele falará sobre o assunto como qualquer humano normal não especialista faria. Isso se deve à maneira como o modelo deles aprende. Na verdade, é mais provável que fale como um usuário de mídia social porque essa é a maioria de seus dados de treinamento.
Por outro lado, a MarketMuse NLG Technology é treinada em artigos bem estruturados e depois ajustada especificamente usando artigos sobre o assunto específico do rascunho. Dessa forma, a saída da Tecnologia NLG do MarketMuse se assemelha mais aos pensamentos de um especialista do que a GPT-3.
Resumo
A MarketMuse NLG Technology foi criada para resolver um desafio específico; como ajudar as equipes de conteúdo a produzir conteúdo melhor com mais rapidez. É uma extensão natural de nossos já bem-sucedidos resumos de conteúdo com inteligência artificial.
Embora o GPT-3 seja espetacular do ponto de vista da pesquisa, ainda há um longo caminho a percorrer antes de ser utilizável.
O que você deve fazer agora
Quando estiver pronto... aqui estão 3 maneiras de ajudá-lo a publicar conteúdo melhor, mais rápido:
- Reserve um tempo com o MarketMuse Agende uma demonstração ao vivo com um de nossos estrategistas para ver como o MarketMuse pode ajudar sua equipe a atingir suas metas de conteúdo.
- Se você quiser aprender a criar conteúdo melhor e mais rápido, visite nosso blog. Está cheio de recursos para ajudar a dimensionar o conteúdo.
- Se você conhece outro profissional de marketing que gostaria de ler esta página, compartilhe com ele por e-mail, LinkedIn, Twitter ou Facebook.