
Noindex Nofollow e Disallow: Diretivas do rastreador de pesquisa
Publicados: 2022-12-01Existem três diretivas (comandos) que você pode usar para determinar como os mecanismos de pesquisa descobrem, armazenam e fornecem informações do seu site como resultados de pesquisa:
- NoIndex: Não adicione minha página aos resultados da pesquisa.
- NoFollow: Não olhe para os links desta página.
- Proibir: Não olhe para esta página.
Essas diretivas permitem que você controle quais páginas do seu site podem ser rastreadas pelos mecanismos de pesquisa e aparecer na pesquisa.
O que significa Sem Índice?
A diretiva noindex informa aos rastreadores de pesquisa, como o googlebot, para não incluir uma página da web em seus resultados de pesquisa.

Como você marca uma página como NoIndex?
Existem duas maneiras de emitir uma diretiva noindex :
- Adicione uma meta tag noindex ao código HTML da página
- Retorne um cabeçalho noindex na solicitação HTTP
Ao usar a meta tag “sem índice” para uma página ou como um cabeçalho de resposta HTTP, você basicamente oculta a página da pesquisa.
A diretiva noindex também pode ser usada para bloquear apenas mecanismos de pesquisa específicos. Por exemplo, você pode bloquear o Google de indexar uma página, mas ainda permitir o Bing:
Exemplo: bloqueio da maioria dos mecanismos de pesquisa*
<meta name=”robôs” conteúdo=”noindex”>
Exemplo: Bloquear apenas o Google
<meta name=”googlebot” content=”noindex”>
Observação: desde setembro de 2019, o Google não respeita mais as diretivas noindex no arquivo robots.txt . Noindex agora DEVE ser emitido via meta tag HTML ou cabeçalho de resposta HTTP. Para usuários mais avançados, proibir ainda funciona por enquanto, embora não para todos os casos de uso.
Qual é a diferença entre noindex e nofollow?
É uma diferença entre armazenar conteúdo e descobrir conteúdo:
noindex é aplicado no nível da página e informa ao rastreador do mecanismo de pesquisa para não indexar e exibir uma página nos resultados da pesquisa.
nofollow é aplicado no nível da página ou do link e diz ao rastreador do mecanismo de pesquisa para não seguir (descobrir) os links.
Essencialmente, a tag noindex remove uma página do índice de pesquisa e um atributo nofollow remove um link do gráfico de links do mecanismo de pesquisa.
NoFollow como um atributo de página
Usar nofollow em um nível de página significa que os rastreadores não seguirão nenhum dos links dessa página para descobrir conteúdo adicional e os rastreadores não usarão os links como sinais de classificação para os sites de destino.
<meta name=”robots” content=”nofollow”>
NoFollow como um atributo de link
O uso de nofollow em um nível de link impede que os rastreadores explorem o link específico do anúncio e impede que esse link seja usado como um sinal de classificação.
A diretiva nofollow é aplicada em um nível de link usando um atributo rel dentro da tag a href:
<a href=”https://domain.com” rel=”nofollow”>
Para o Google especificamente, usar o atributo de link nofollow impedirá que seu site passe o PageRank para os URLs de destino.
Por que você deve marcar uma página como NoFollow?
Para a maioria dos casos de uso, você não deve marcar uma página inteira como nofollow – marcar links individuais como nofollow será suficiente.
Você marcaria uma página inteira como nofollow se não quisesse que o Google visualizasse os links da página ou se achasse que os links da página poderiam prejudicar seu site.
Na maioria dos casos, diretivas gerais nofollow no nível da página são usadas quando você não tem controle sobre o conteúdo que está sendo postado em uma página Alguns editores sofisticados também têm aplicado a diretiva nofollow em suas páginas para dissuadir seus escritores de colocar links patrocinados em seu conteúdo.
Como faço para usar páginas NoIndex?
Marque as páginas como noindex que provavelmente não agregarão valor aos usuários e não devem aparecer como resultados de pesquisa. Por exemplo, é improvável que as páginas que existem para paginação tenham o mesmo conteúdo exibido nelas ao longo do tempo.
É improvável que Domain.com/category/resultspage=2 mostre a um usuário resultados melhores do que domain.com/category/resultspage=1 e as duas páginas competiriam apenas entre si na pesquisa. É melhor não indexar páginas cuja única finalidade seja a paginação.
Aqui estão os tipos de páginas que você deve considerar sem indexação:
- Páginas usadas para paginação
- Páginas de pesquisa interna
- Páginas de destino otimizadas para anúncios
- Ex: exibe apenas um formulário de apresentação e inscrição, sem navegação principal
- Ex: Variações duplicadas do mesmo conteúdo, usadas apenas para anúncios
- Páginas de autor arquivadas
- Páginas em fluxos de checkout
- Páginas de confirmação
- Ex: páginas de agradecimento
- Ex: Ordenar páginas completas
- Exemplo: Sucesso! Páginas
- Algumas páginas geradas por plug-in que não são relevantes para o seu site (por exemplo: se você usa um plug-in de comércio, mas não usa as páginas de produtos regulares)
- Páginas de administração e páginas de login do administrador
Marcando uma página como Noindex e Nofollow
Uma página marcada como noindex e nofollow impedirá um rastreador de indexar essa página e impedirá que um rastreador explore os links na página.
Essencialmente, a imagem abaixo demonstra o que um mecanismo de pesquisa verá em uma página da Web, dependendo de como você usou as diretivas noindex e nofollow:

Marcando uma página já indexada como NoIndex
Se um mecanismo de pesquisa já indexou uma página e você a marcou como noindex , na próxima vez que a página for rastreada, ela será removida dos resultados da pesquisa Para que esse método de remoção de uma página do índice funcione, você não deve bloquear (desautorizar) o rastreador com seu arquivo robots.txt.
Se você estiver dizendo a um rastreador para não ler a página, ele nunca verá o marcador noindex e a página permanecerá indexada, embora seu conteúdo não seja atualizado.
Como faço para impedir que os mecanismos de pesquisa indexem meu site?
Se você deseja remover uma página do índice de pesquisa, depois que ela já foi indexada, você pode concluir as seguintes etapas:
- Aplique a diretiva noindex Adicione o atributo noindex à meta tag ou cabeçalho de resposta HTTP
- Solicite que o mecanismo de pesquisa rastreie a página Para o Google, você pode fazer isso no console de pesquisa, solicite que o Google reindexe a página. Isso acionará o rastreamento da página pelo Googlebot, onde o Googlebot descobrirá a diretiva noindex. Você precisará fazer isso para cada mecanismo de pesquisa que deseja remover da página.
- Confirme se a página foi removida da pesquisa Depois de solicitar que o rastreador revisite sua página da Web, espere um pouco e confirme se sua página foi removida dos resultados da pesquisa. Você pode fazer isso acessando qualquer mecanismo de pesquisa e digitando o URL de destino do site com dois pontos, como na imagem abaixo.
Se sua pesquisa não retornar resultados, sua página foi removida desse índice de pesquisa. - Se a página não foi removida Verifique se você não tem uma diretiva “proibir” em seu arquivo robots.txt. O Google e outros mecanismos de pesquisa não podem ler a diretiva noindex se não tiverem permissão para rastrear a página. Se o fizer, remova a diretiva de bloqueio da página de destino e solicite o rastreamento novamente.
- Defina uma diretiva de proibição para a página de destino em seu arquivo robots.txt Disallow: /page$
Você precisará colocar o cifrão no final do URL em seu arquivo robots.txt ou poderá acidentalmente desabilitar quaisquer páginas dessa página, bem como quaisquer páginas que comecem com a mesma string. Ex: Proibir: /sweater também não permitirá /sweater-weather e /sweater/green, mas Disallow: /sweater$ só não permitirá a página exata /sweater.
Quão remover uma página da pesquisa do Google
Se a página que você deseja remover da pesquisa estiver em um site que você possui ou gerencia, a maioria dos sites pode usar a Ferramenta de remoção de URL do webmaster.
A ferramenta de remoção de URL do webmaster apenas remove o conteúdo da pesquisa por cerca de 90 dias. Se você quiser uma solução mais permanente, precisará usar uma diretiva noindex, proibir o rastreamento do seu robots.txt ou remover a página do seu site. O Google fornece instruções adicionais para remoção permanente de URL aqui.

Se você está tentando remover uma página da pesquisa de um site que não é seu, pode solicitar que o Google remova a página da pesquisa se ela atender aos seguintes critérios:
- Exibe informações pessoais como seu cartão de crédito ou número do seguro social
- A página faz parte de um esquema de malware ou phishing
- A página viola a lei
- A página viola direitos autorais
Se a página não atender a um dos critérios acima, você pode entrar em contato com uma empresa de SEO ou relações públicas para obter ajuda com o gerenciamento de reputação online.
Você deve noindex páginas de categoria?
Geralmente, não é recomendado não indexar páginas de categoria, a menos que você seja uma organização de nível empresarial que gira páginas de categoria programaticamente com base em pesquisas ou tags geradas pelo usuário e o conteúdo duplicado está ficando pesado.
Na maioria das vezes, se você estiver marcando seu conteúdo de maneira inteligente, de uma forma que ajude os usuários a navegar melhor em seu site e encontrar o que precisam, você ficará bem.
Na verdade, as páginas de categoria podem ser minas de ouro para SEO, pois normalmente mostram uma profundidade de conteúdo nos tópicos da categoria.
Dê uma olhada nesta análise que fizemos em dezembro de 2018 para quantificar o valor das páginas de categoria para um punhado de publicações online.
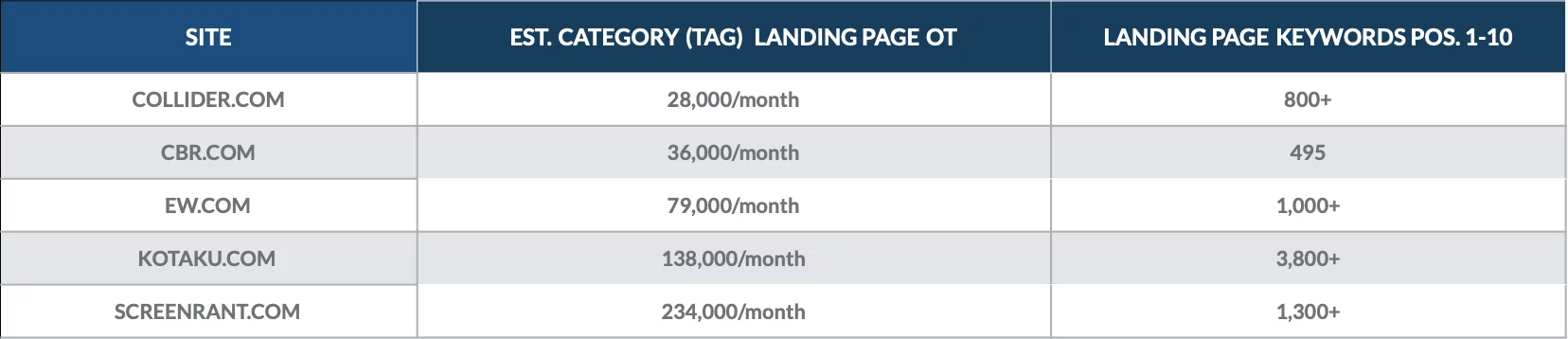
Descobrimos que as páginas de destino da categoria foram classificadas para centenas de palavras-chave da página 1 e trouxeram milhares de visitantes orgânicos a cada mês.
As páginas de categoria mais valiosas para cada site geralmente traziam milhares de visitantes orgânicos cada.
Dê uma olhada no EW.com abaixo, medimos o tráfego para cada página (representado pelo tamanho do círculo) e o valor do tráfego para cada página (representado pela cor do círculo).
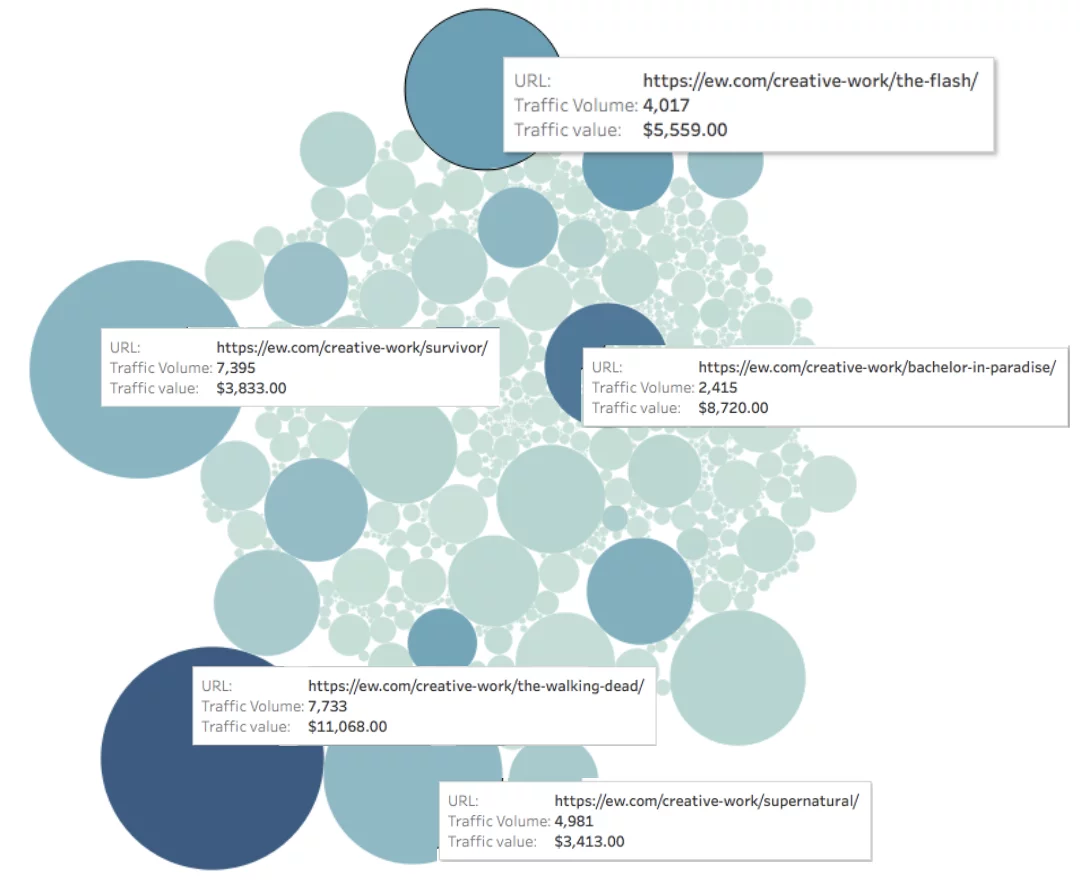
Valor orgânico mensal da página = profundidade da cor
Agora imagine os mesmos gráficos, mas para sites baseados em produtos nos quais os visitantes provavelmente farão compras ativas.
Dito isso, se suas categorias forem semelhantes o suficiente para confundir o usuário ou competir entre si na pesquisa, talvez seja necessário fazer uma alteração:
- Se você mesmo estiver definindo as categorias, recomendamos migrar o conteúdo de uma categoria para outra e reduzir o número total de categorias gerais.
- Se você está permitindo que os usuários criem categorias, você pode querer não indexar as páginas de categoria geradas pelo usuário, pelo menos até que as novas categorias tenham passado por um processo de revisão.
Como faço para impedir que o Google indexe subdomínios?
Existem algumas opções para impedir que o Google indexe subdomínios:
- Você pode adicionar uma senha usando um arquivo .htpasswd
- Você pode proibir rastreadores com um arquivo robots.txt
- Você pode adicionar uma diretiva noindex a todas as páginas do subdomínio
- Você pode 404 todas as páginas do subdomínio
Adicionando uma senha para bloquear a indexação
Se seus subdomínios forem para fins de desenvolvimento, adicionar um arquivo .htpasswd ao diretório raiz de seu subdomínio é a opção perfeita. A parede de login impedirá que rastreadores indexem conteúdo no subdomínio e impedirá o acesso de usuários não autorizados.
Exemplos de casos de uso:
- dev.domain.com
- Staging.domain.com
- testing.domain.com
- QA.domain.com
- UAT.dominio.com
Usando robots.txt para bloquear a indexação
Se seus subdomínios servirem a outras finalidades, você poderá adicionar um arquivo robots.txt ao diretório raiz de seu subdomínio. Deve então ser acessível da seguinte forma:
https://subdomain.domain.com/robots.txt
Você precisará adicionar um arquivo robots.txt a cada subdomínio que está tentando bloquear da pesquisa. Exemplo:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
Em cada caso, o arquivo robots.txt deve desabilitar rastreadores, para bloquear a maioria dos rastreadores com um único comando, use o seguinte código:
Agente de usuário: *
Não permitir: /
A estrela * após user-agent: é chamada de curinga, corresponderá a qualquer sequência de caracteres. O uso de um curinga enviará a seguinte diretiva de proibição a todos os agentes de usuário, independentemente de seus nomes, de googlebot a yandex.
A barra invertida informa ao rastreador que todas as páginas fora do subdomínio estão incluídas na diretiva de proibição.
Como bloquear seletivamente a indexação de páginas de subdomínio
Se você deseja que algumas páginas de um subdomínio apareçam na pesquisa, mas não outras, você tem duas opções:
- Use diretivas noindex no nível da página
- Use diretivas de bloqueio de nível de pasta ou diretório
As diretivas noindex no nível da página serão mais complicadas de implementar, pois a diretiva precisa ser adicionada ao HTML ou ao cabeçalho de cada página. No entanto, as diretivas noindex impedirão o Google de indexar um subdomínio, independentemente de o subdomínio já ter sido indexado ou não.
As diretivas de proibição no nível do diretório são mais fáceis de implementar, mas funcionarão apenas se as páginas do subdomínio ainda não estiverem no índice de pesquisa. Simplesmente atualize o arquivo robots.txt do subdomínio para impedir o rastreamento dos diretórios ou subpastas aplicáveis.
Como sei se minhas páginas são NoIndexed?
A adição acidental de páginas de diretiva sem índice em seu site pode ter consequências drásticas para suas classificações de pesquisa e visibilidade de pesquisa.
Se você descobrir que uma página não está obtendo nenhum tráfego orgânico, apesar do bom conteúdo e backlinks, primeiro verifique se você não desativou acidentalmente os rastreadores do seu arquivo robots.txt. Se isso não resolver seu problema, você precisará verificar as páginas individuais em busca de diretivas noindex.
Verificando NoIndex em páginas do WordPress
O WordPress facilita a adição ou remoção dessa tag em suas páginas. O primeiro passo para verificar se há nofollow em suas páginas é simplesmente alternar a configuração de visibilidade do mecanismo de pesquisa na guia “Leitura” do menu “Configurações”.
Isso provavelmente resolverá o problema, no entanto, essa configuração funciona como uma 'sugestão' e não como uma regra, e parte do seu conteúdo pode acabar sendo indexado de qualquer maneira.
Para garantir a privacidade absoluta de seus arquivos e conteúdo, você terá que dar um passo final para proteger seu site com senha usando as ferramentas de gerenciamento do cPanel, se disponíveis, ou por meio de um plugin simples.
Da mesma forma, remover essa tag do seu conteúdo pode ser feito removendo a proteção por senha e desmarcando a configuração de visibilidade.
Verificando NoIndex no Squarespace
As páginas do Squarespace também são facilmente classificadas como NoIndexed usando o recurso de injeção de código da plataforma. Assim como o WordPress, o Squarespace pode ser facilmente bloqueado de pesquisas de rotina usando proteção por senha, mas a plataforma também desaconselha essa etapa para proteger a integridade do seu conteúdo.
Ao adicionar a linha de código NoIndex em cada página que você deseja ocultar dos mecanismos de pesquisa da Internet e em cada subpágina abaixo dela, você pode garantir a segurança do conteúdo protegido que deve ser impedido de acesso público. Como em outras plataformas, a remoção dessa tag também é bastante direta: basta usar o recurso de injeção de código para retirar o código de volta.
O Squarespace é único porque seus concorrentes oferecem essa opção principalmente como parte do conjunto de configurações nas ferramentas de gerenciamento de páginas. O Squarespace parte daqui, permitindo a manipulação pessoal do código. Isso é interessante porque você consegue ver a alteração que está fazendo no conteúdo da sua página, ao contrário dos outros neste espaço.
Verificando NoIndex no Wix
O Wix também permite uma correção simples e rápida para problemas de NoIndexing. Nas configurações de “Menus e Páginas”, você pode simplesmente desativar a opção de 'mostrar esta página nos resultados da pesquisa' se quiser NoIndexar uma única página em seu site.
Assim como seus concorrentes, o Wix também sugere proteger com senha suas páginas ou todo o site para privacidade extra. No entanto, o Wix se diferencia dos outros porque a equipe de suporte não prescreve ações paralelas em ambas as frentes para proteger o conteúdo do rastreador. O Wix faz uma observação específica sobre a diferença entre ocultar uma página do seu menu e ocultá-la dos critérios de pesquisa.
Este é um conselho particularmente útil para criadores de sites menos experientes que podem não entender inicialmente a diferença, considerando que a remoção do menu do site torna a página inacessível a partir do site, mas não a partir de um termo de pesquisa prudente do Google.