
Modelagem de tópicos com Word2Vec
Publicados: 2022-05-02Uma palavra é definida pela empresa que mantém. Essa é a premissa por trás do Word2Vec, um método de converter palavras em números e representá-los em um espaço multidimensional. Palavras frequentemente encontradas juntas em uma coleção de documentos (corpus) também aparecerão juntas neste espaço. Dizem que estão relacionados contextualmente.
Word2Vec é um método de aprendizado de máquina que requer um corpus e treinamento adequado. A qualidade de ambos afeta sua capacidade de modelar um tópico com precisão. Quaisquer deficiências tornam-se prontamente aparentes ao examinar a saída para tópicos muito específicos e complicados, pois esses são os mais difíceis de modelar com precisão. O Word2Vec pode ser usado sozinho, embora seja frequentemente combinado com outras técnicas de modelagem para lidar com suas limitações.
O restante deste artigo fornece informações adicionais sobre o Word2Vec, como ele funciona, como é usado na modelagem de tópicos e alguns dos desafios que ele apresenta.
O que é Word2Vec?
Em setembro de 2013, os pesquisadores do Google, Tomas Mikolov, Kai Chen, Greg Corrado e Jeffrey Dean, publicaram o artigo 'Efficient Estimation of Word Representations in Vector Space' (pdf). Isso é o que agora chamamos de Word2Vec. O objetivo do artigo era “introduzir técnicas que podem ser usadas para aprender vetores de palavras de alta qualidade a partir de enormes conjuntos de dados com bilhões de palavras e com milhões de palavras no vocabulário”.
Antes deste ponto, quaisquer técnicas de processamento de linguagem natural tratavam as palavras como unidades singulares. Eles não levaram em conta nenhuma semelhança entre as palavras. Embora houvesse razões válidas para essa abordagem, ela tinha suas limitações. Houve situações em que o dimensionamento dessas técnicas básicas não poderia oferecer melhorias significativas. Daí a necessidade de desenvolver tecnologias avançadas.
O artigo mostrou que modelos simples, com seus menores requisitos computacionais, podem treinar vetores de palavras de alta qualidade. Como o artigo conclui, é “possível calcular vetores de palavras de alta dimensão muito precisos a partir de um conjunto de dados muito maior”. Eles estão falando de coleções de documentos (corpora) com um trilhão de palavras fornecendo um tamanho virtualmente ilimitado de vocabulário.
Word2Vec é uma forma de converter palavras em números, neste caso vetores, para que as semelhanças possam ser descobertas matematicamente. A ideia é que vetores de palavras semelhantes sejam agrupados dentro do espaço vetorial.
Pense nas coordenadas latitudinais e longitudinais em um mapa. Usando esse vetor bidimensional, você pode determinar rapidamente se dois locais estão relativamente próximos. Para que as palavras sejam representadas apropriadamente em um espaço vetorial, duas dimensões não são suficientes. Assim, os vetores precisam incorporar muitas dimensões.
Como funciona o Word2Vec?
O Word2Vec recebe como entrada um grande corpus de texto e o vetoriza usando uma rede neural rasa. A saída é uma lista de palavras (vocabulário), cada uma com um vetor correspondente. Palavras com significado semelhante ocorrem espacialmente nas proximidades. Matematicamente, isso é medido pela similaridade do cosseno, onde a similaridade total é expressa como um ângulo de 0 graus, enquanto nenhuma similaridade é expressa como um ângulo de 90 graus.
As palavras podem ser codificadas como vetores usando diferentes tipos de modelos. Em seu artigo, Mikolov et al. olhou para dois modelos existentes, modelo de linguagem de rede neural feedforward (NNLM) e modelo de linguagem de rede neural recorrente (RNNLM). Além disso, eles propõem dois novos modelos log-lineares, saco de palavras contínuo (CBOW) e Skip-gram contínuo.
Em suas comparações, CBOW e Skip-gram tiveram melhor desempenho, então vamos examinar esses dois modelos.
O CBOW é semelhante ao NNLM e depende do contexto para determinar uma palavra de destino. Ele determina a palavra alvo com base nas palavras que vêm antes e depois dela. Mikolov descobriu que o melhor desempenho ocorreu com quatro palavras futuras e quatro palavras históricas. É chamado de 'saco de palavras' porque a ordem das palavras na história não influencia na saída. 'Contínuo' no termo CBOW refere-se ao seu uso de “representação distribuída contínua do contexto”.
Skip-gram é o inverso de CBOW. Dada uma palavra, ele prevê palavras ao redor dentro de um intervalo específico. Um intervalo maior fornece vetores de palavras de melhor qualidade, mas aumenta a complexidade computacional. Menos peso é dado a termos distantes porque eles geralmente são menos relacionados à palavra atual.
Ao comparar o CBOW com o Skip-gram, este último oferece resultados de melhor qualidade em grandes conjuntos de dados. Embora o CBOW seja mais rápido, o Skip-gram lida melhor com palavras pouco usadas.
Durante o treinamento, um vetor é atribuído a cada palavra. Os componentes desse vetor são ajustados para que palavras semelhantes (com base em seu contexto) fiquem mais próximas. Pense nisso como um cabo de guerra, onde as palavras estão sendo empurradas e puxadas nesse vetor multidimensional toda vez que outro termo é adicionado ao espaço.
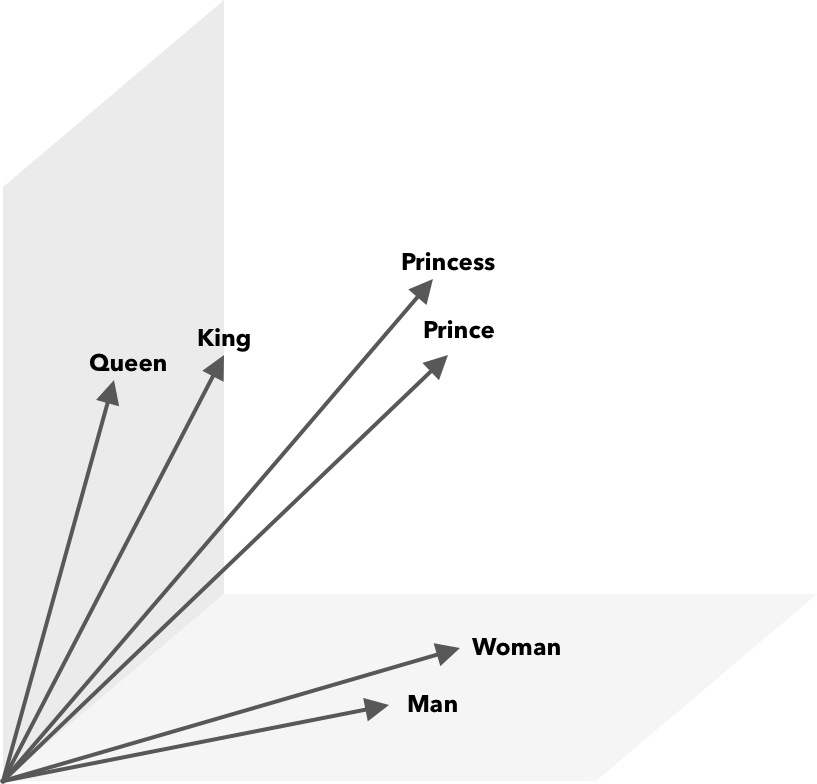
Operações matemáticas, além da similaridade de cosseno, podem ser realizadas em vetores de palavras. Por exemplo, o vetor(”Rei”) – vetor(”Homem”) + vetor(”Mulher”) resulta em um vetor mais próximo daquele que representa a palavra Rainha.

Word2Vec para modelagem de tópicos
O vocabulário criado pelo Word2Vec pode ser consultado diretamente para detectar relacionamentos entre palavras ou alimentado em uma rede neural de aprendizado profundo. Um problema com algoritmos Word2Vec como CBOW e Skip-gram é que eles pesam cada palavra igualmente. O problema que surge ao trabalhar com documentos é que as palavras não representam igualmente o significado de uma frase.
Algumas palavras são mais importantes que outras. Assim, diferentes estratégias de ponderação, como o TF-IDF, são frequentemente empregadas para lidar com a situação. Isso também ajuda a resolver o problema de hubness mencionado na próxima seção. O Searchmetrics ContentExperience usa uma combinação de TF-IDF e Word2Vec, sobre os quais você pode ler aqui em nossa comparação com o MarketMuse.
Enquanto as incorporações de palavras como o Word2Vec capturam informações morfológicas, semânticas e sintáticas, a modelagem de tópicos visa descobrir a estrutura semântica latente ou tópicos em um corpus.
De acordo com Budhkar e Rudzicz (PDF), combinar alocação de Dirichlet latente (LDA) com Word2Vec pode produzir recursos discriminativos para “resolver o problema causado pela ausência de informações contextuais incorporadas nesses modelos”. Uma leitura mais fácil no LDA2vec pode ser encontrada neste tutorial do DataCamp.
Desafios do Word2Vec
Existem vários problemas com incorporações de palavras em geral, incluindo Word2Vec. Abordaremos alguns deles, para uma análise mais detalhada, consulte 'A Survey of Word Embedding Evaluation Methods' (pdf) por Amir Bakarov. O corpus e seu tamanho, bem como o próprio treinamento, impactarão significativamente na qualidade do resultado.
Como você avalia a saída?
Como Bakarov explica em seu artigo, um engenheiro de PNL normalmente avaliará o desempenho de embeddings de maneira diferente de um linguista computacional ou de um profissional de marketing de conteúdo. Aqui estão algumas questões adicionais citadas no artigo.
- Semântica é uma ideia vaga. Uma “boa” incorporação de palavras reflete nossa noção de semântica. No entanto, podemos não estar cientes se nosso entendimento está correto. Além disso, as palavras têm diferentes tipos de relações, como parentesco semântico e semelhança semântica. Que tipo de relação a palavra incorporação deve refletir?
- Falta de dados de treinamento adequados. Ao treinar incorporações de palavras, os pesquisadores frequentemente aumentam sua qualidade ajustando-as aos dados. Isso é o que chamamos de ajuste de curva. Em vez de fazer com que o resultado se ajuste aos dados, os pesquisadores devem tentar capturar as relações entre as palavras.
- A ausência de correlação entre métodos intrínsecos e extrínsecos significa que não está claro qual classe de método é preferida. A avaliação extrínseca determina a qualidade de saída para uso posterior em outras tarefas de processamento de linguagem natural. A avaliação intrínseca depende do julgamento humano das relações de palavras.
- O problema do hubness. Hubs, vetores de palavras que representam palavras comuns, estão próximos de um número excessivo de outros vetores de palavras. Este ruído pode influenciar a avaliação.
Além disso, existem dois desafios significativos com o Word2Vec em particular.
- Não consegue lidar muito bem com ambiguidades. Como resultado, o vetor de uma palavra com múltiplos significados reflete a média, que está longe do ideal.
- Word2Vec não pode lidar com palavras fora do vocabulário (OOV) e palavras morfologicamente semelhantes. Quando o modelo encontra um novo conceito, ele recorre ao uso de um vetor aleatório, que não é uma representação precisa.
Resumo
Usar Word2Vec ou qualquer outra incorporação de palavras não é garantia de sucesso. A qualidade da produção é baseada no treinamento adequado usando um corpus apropriado e suficientemente grande.
Embora avaliar a qualidade da saída possa ser complicado, aqui está uma solução simples para profissionais de marketing de conteúdo. Na próxima vez que você estiver avaliando um otimizador de conteúdo, tente usar um tópico muito específico. Modelos de tópicos de baixa qualidade falham quando se trata de testar dessa maneira. Eles são adequados para termos gerais, mas são interrompidos quando a solicitação se torna muito específica.
Portanto, se você usar o tópico 'como cultivar abacates', certifique-se de que as sugestões tenham algo a ver com o cultivo da planta e não com abacates em geral.
A geração de linguagem natural da MarketMuse NLG Technology ajudou a criar este artigo.
O que você deve fazer agora
Quando estiver pronto... aqui estão 3 maneiras de ajudá-lo a publicar conteúdo melhor, mais rápido:
- Reserve um tempo com o MarketMuse Agende uma demonstração ao vivo com um de nossos estrategistas para ver como o MarketMuse pode ajudar sua equipe a atingir suas metas de conteúdo.
- Se você quiser aprender a criar conteúdo melhor e mais rápido, visite nosso blog. Está cheio de recursos para ajudar a dimensionar o conteúdo.
- Se você conhece outro profissional de marketing que gostaria de ler esta página, compartilhe com ele por e-mail, LinkedIn, Twitter ou Facebook.