
Quais são os tipos de Big Data: características e definição
Publicados: 2023-10-06Resumo: Big data é composto por quatro tipos denominados dados estruturados, não estruturados, semiestruturados e quase estruturados. Vamos aprender sobre cada tipo de big data em detalhes abaixo!
A maioria das organizações depende dos conjuntos de dados para obter insights e aprender sobre seus clientes, setor e empresa. No entanto, quando os dados aumentam de tamanho, torna-se difícil manuseá-los e processá-los.
Esses conjuntos de dados são chamados de conjuntos de big data, que possuem uma maior variedade de dados e são enormes por natureza. Big data pode vir em diversas formas, como estruturado, não estruturado, semiestruturado e quase estruturado.
Vamos aprender mais sobre os diferentes tipos de conjuntos de big data no artigo abaixo.
Índice
Quais são os tipos populares de Big Data?
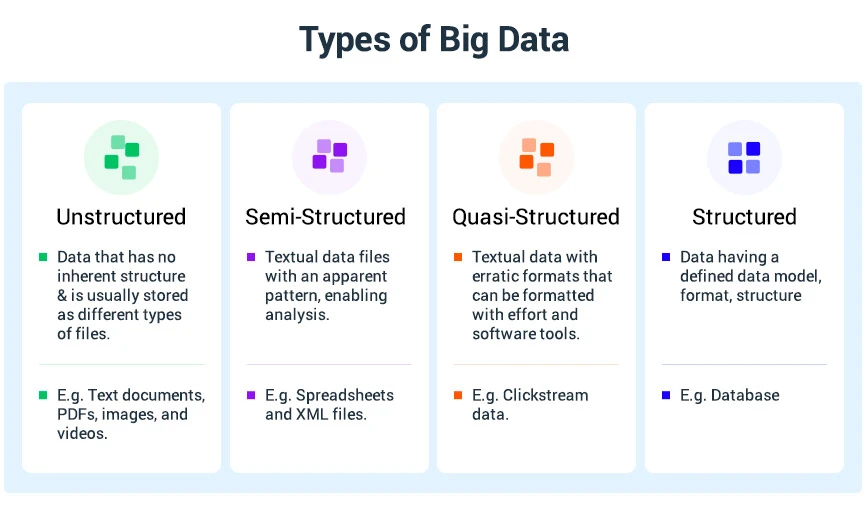
Big data é categorizado nestes quatro tipos principais, conforme enumerado abaixo:
Dados Estruturados
Dados estruturados são um tipo de dado que possui um formato padronizado que pode ser facilmente acessado pelo software e pelas pessoas. Geralmente está em formato tabular com várias linhas e colunas que destacam os atributos dos dados.
Os dados estruturados incluem dados quantitativos como idade, número de contato, números de cartão de crédito e assim por diante. Por ser de natureza quantitativa, o software pode processá-lo facilmente para obter insights valiosos.
Para processar os dados da estrutura, não é necessário colocar os dados em métricas relevantes. Além disso, os dados da estrutura não precisam ser convertidos e interpretados profundamente para obter insights valiosos.
Onde usar o tipo de dados estruturados?
- Gerenciando dados de clientes
- Manter detalhes das faturas
- Armazenando bancos de dados de produtos
- Gravando lista de contatos
Prós e contras dos dados estruturados
- Isso facilita o processamento dos dados porque eles são armazenados em um formato definido.
- Os dados são processados rapidamente em comparação com os dados não estruturados
- Pode não ser adequado para todos os tipos de informação porque os dados são armazenados num formato específico.
Dados não estruturados: XML, JSON, YAML

Dados não estruturados são um tipo de dados que não se limitam a um modelo de dados específico e a uma estrutura identificável que pode ser lida por um programa de computador. Este tipo de dados não está organizado de maneira devidamente definida e carece de qualquer sequência ou formato para processar os dados.
Em comparação com os dados estruturados, este tipo de dados não pode ser armazenado na forma de linhas e colunas. Um exemplo comum de dados não estruturados é um banco de dados heterogêneo que contém uma combinação de imagens, vídeos, arquivos de texto, etc.
Onde usar o tipo de dados não estruturados?
- Gerenciando dados de áudio e vídeo
- Lidando com respostas de pesquisas abertas
- Lidando com postagens em mídias sociais
- Gerenciando documentos comerciais
Prós e contras de dados não estruturados
- Como não existe uma estrutura definida, os dados podem ser coletados rapidamente.
- Pode ser usado para lidar com fontes de dados heterogêneas.
- Devido à falta de qualquer estrutura ou esquema, é mais difícil de gerenciar.
Dados semiestruturados
Dados semiestruturados são um tipo de dados que não estão estruturados adequadamente, mas ao mesmo tempo não são totalmente desestruturados. Esses dados não seguem o esquema rígido e o modelo de dados. Além disso, também pode conter componentes que não podem ser facilmente categorizados ou classificados.
Os dados semiestruturados são caracterizados por metadados e tags que fornecem informações extras sobre todos os elementos dos dados. Por exemplo, um arquivo XML pode conter tags que indicam a estrutura do documento e incluir tags extras que fornecem metadados sobre o conteúdo, como data ou palavras-chave.
Onde usar o tipo de dados semiestruturados?
- Analisando páginas da web por meio de HTML
- Usando dados de e-mails para obter insights sobre os clientes
- Categorizando e analisando vídeos e imagens
Prós e contras do tipo de dados semestruturados
- O esquema dos dados pode ser alterado.
- Este tipo de dados pode acomodar dados que podem não caber em um esquema predefinido.
- As consultas de dados são menos eficientes em comparação com dados estruturados.
Dados quase estruturados
Dados quase estruturados são um tipo de dados textuais que vêm com formatos de dados erráticos. Este tipo de dados pode ser formatado com diferentes ferramentas de análise de dados. Inclui dados como dados de clickstream da web.

Onde usar o tipo de dados quase estruturados?
- Pode ser usado para analisar os dados das páginas da web
Prós e contras do tipo de dados quase estruturados
- Os dados podem ser processados rapidamente.
- Este tipo de dados pode ser formatado rapidamente através de ferramentas de análise de dados.
- Pode levar algum tempo para carregar os dados.
Quais são os subtipos de dados?
Existem vários subtipos de dados que não são considerados big data, mas são importantes para análise. A origem de tais dados pode ser de mídia social, registro operacional, acionado por evento ou geoespacial. Também pode vir de sistemas de código aberto, dados transmitidos via API e dispositivos perdidos ou roubados.
Características do Big Data
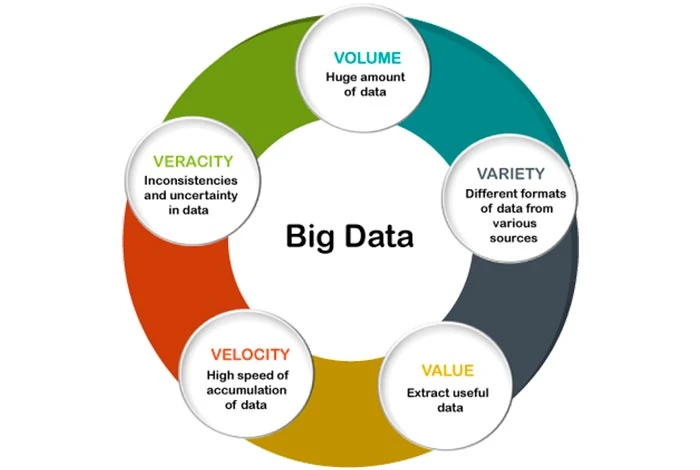
Existem cinco Vs que definem as características do big data. Essas características são enumeradas abaixo:
- Volume: A primeira característica do big data é o volume. Big data é o vasto “volume” de dados coletados de diversas fontes. As fontes podem incluir procedimentos comerciais, plataformas de mídia social, máquinas, interações humanas, etc.
- Veracidade: A veracidade pode ser definida como a qualidade e precisão dos dados fornecidos. Os dados extraídos podem ter alguns elementos faltantes ou podem não ser capazes de fornecer informações valiosas. Portanto, esta característica é útil para identificar a qualidade dos dados e obter insights.
- Variedade: A variedade pode ser definida como a diversidade de vários tipos de dados. Os dados podem ser obtidos de diversas fontes de dados que podem variar em valor. Os dados coletados podem ser estruturados, não estruturados ou semiestruturados. A variedade de dados pode estar na forma de PDFs, e-mails, fotos, áudios, etc.
- Valor: Pode ser definido como o valor que o big data pode fornecer. Extrair valor dos dados coletados é importante para obter insights valiosos deles. As organizações podem usar as mesmas ferramentas de análise de big data por meio das quais coletaram dados para analisá-los.
- Velocidade: Velocidade se refere à velocidade com que os dados são gerados e movidos. É um elemento importante para empresas que desejam que seus dados fluam rapidamente para que estejam disponíveis no momento certo para obter insights. Os dados podem fluir de várias fontes, como máquinas, smartphones, redes, etc. Uma vez coletados, os dados podem ser analisados rapidamente.
Setores que usam Big Data diariamente
O big data pode ser usado em vários setores, incluindo saúde, agricultura, educação, finanças e assim por diante. Vamos aprender detalhadamente sobre a aplicação de big data nos seguintes setores:
- Educação: No sector da educação, os professores podem analisar o desempenho dos alunos e as taxas de abandono para optimizar o currículo. Além disso, também pode auxiliar na identificação de áreas de melhoria por meio da análise do desempenho do aluno.
- E-Commerce: O setor de comércio eletrônico pode usar análises de big data para entender quais procedimentos da sua empresa estão indo bem ou quais deles precisam ser melhorados. Além disso, você também pode identificar o tipo de conteúdo que está gerando engajamento e quais canais estão gerando o maior tráfego.
- Cuidados de saúde: Nos cuidados de saúde, os grandes volumes de dados podem ser utilizados para obter conhecimentos de investigação biomédica e fornecer recomendações médicas personalizadas aos pacientes após a análise dos seus dados. Além disso, ao monitorar o estado do paciente em tempo real, podem enviar alertas à equipe médica.
- Governo: O governo pode usar big data para analisar os dados dos cidadãos em massa através de múltiplos parâmetros. Por exemplo, o big data do censo é analisado para saber o número de jovens no país ou a população de desempregados. As conclusões podem ajudá-los a desenvolver esquemas e planos para atingir o conjunto certo de cidadãos.
Leitura sugerida: Principais ferramentas de Business Intelligence (BI)
Conclusão
O big data tornou mais fácil para as empresas processar conjuntos de dados em massa. Quando os dados são classificados, organizados e analisados em massa, podem ajudar as empresas a obter insights valiosos. Cada vez mais indústrias dependem da análise de big data para processar dados complexos e aproveitar a inferência para obter vantagem competitiva.
Perguntas frequentes relacionadas a tipos de Big Data
O que é big data e que tipo de big data?
Big data é um tipo de dado que contém maior variedade, vem em maior volume e com mais velocidade. Os tipos de big data incluem estruturado, não estruturado e semiestruturado.
Quais são os três tipos de classificação de Big Data?
Os três tipos de classificação de Big Data são dados estruturados, não estruturados e semiestruturados.
Quais são os 4 componentes do Big Data?
Os quatro principais componentes do big data são volume, velocidade, variedade e veracidade.
Quais são as 6 características do Big Data?
O big data possui as seguintes características que auxiliam na análise dos dados: volume, variedade, veracidade, variabilidade, velocidade e valor.
Quais são as fontes de big data?
As principais fontes de big data podem ser agrupadas em sociais, máquinas e transacionais. As fontes sociais são as fontes de big data mais utilizadas pela organização. Inclui postagens em mídias sociais, vídeos postados, etc.