
Atingerea rezilienței cu cozi: construirea unui sistem care nu trece niciodată peste un miliard
Publicat: 2018-12-21Braze procesează miliarde și miliarde de evenimente pe zi în numele clienților săi, rezultând miliarde de mesaje personalizate super-concentrate trimise utilizatorilor finali. Eșecul de a trimite unul dintre aceste mesaje are consecințe, fie că este vorba despre o chitanță ratată sau, și mai rău, de o notificare ratată prin care utilizatorul știe că mâncarea este gata. Pentru a ne asigura că aceste mesaje cheie sunt întotdeauna corecte și întotdeauna la timp, Braze adoptă o abordare strategică a modului în care valorificăm cozile de locuri de muncă.
Ce este o coadă de locuri de muncă?
O coadă de joburi tipică este un model arhitectural în care procesele trimit joburi de calcul la o coadă și alte procese execută efectiv joburile. Acesta este de obicei un lucru bun - atunci când este utilizat corect, vă oferă grade de concurență, scalabilitate și redundanță pe care nu le puteți obține cu o paradigmă tradițională cerere-răspuns. Mulți lucrători pot executa diferite lucrări simultan în mai multe procese, mai multe mașini sau chiar mai multe centre de date pentru concurență maximă. Puteți atribui anumite noduri de lucru să lucreze pe anumite cozi și să trimiteți anumite joburi la anumite cozi, permițându-vă să scalați resursele după cum este necesar. Dacă un proces de lucru se blochează sau un centru de date este offline, alți lucrători pot executa sarcinile rămase.
Deși cu siguranță puteți aplica aceste principii și puteți rula cu ușurință un sistem de așteptare a locurilor de muncă la scară mică, cusăturile încep să se arate (și chiar să spargă) atunci când procesați miliarde și miliarde de joburi. Să aruncăm o privire la câteva probleme cu care s-a confruntat Braze pe măsură ce am trecut de la procesarea a mii, la milioane și acum miliarde de locuri de muncă pe zi.
Lipsa de consecvență este o slăbiciune
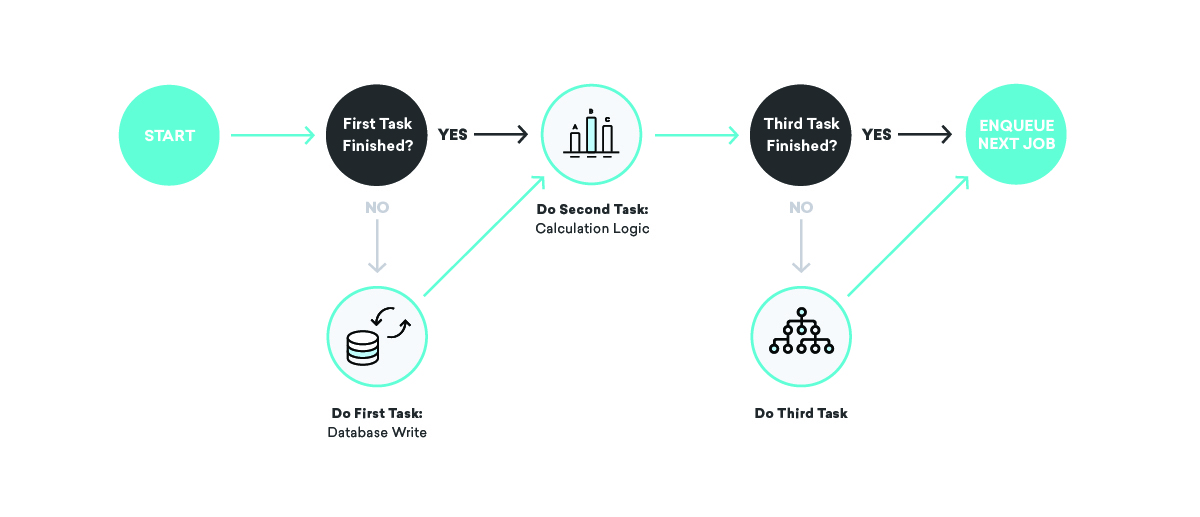
Ce se întâmplă dacă trimitem un mesaj, dar ne blocăm înainte de a înregistra faptul că tocmai am trimis acel mesaj?
Câteva rezultate proaste diferite sunt posibile aici. În primul rând, este posibil să reprogramați lucrarea eșuată și să trimiteți din nou mesajul. Asta... nu este ideal: nimeni nu vrea să primească același lucru de două ori. În schimb, luați în considerare să nu o reprogramați deloc. În acest caz, contabilitatea noastră internă va fi incorectă, astfel încât atribuțiile, conversiile și tot felul de alte lucruri nu vor fi corecte în continuare.
Cum remediam asta? Când ne scriem definițiile postului, ne gândim foarte bine la idempotenta și la comportamentul din nou.
Când vorbiți despre cozi, idempotenta înseamnă că un singur job poate fi terminat într-un punct arbitrar, jobul re-a reluat în întregime, iar rezultatul final va fi același ca și cum am fi executat cu succes jobul exact unul. timp. Acest lucru este strâns legat de comportamentul ales de noi în reîncercare - livrare cel puțin o dată. Ținând cont de faptul că toate joburile noastre vor fi executate cel puțin o dată, și poate de mai multe ori, putem scrie definiții de job idempotente care asigură consistența chiar și în fața unor eșecuri aleatorii.
Revenind la exemplul nostru de trimitere a mesajelor, cum am putea folosi aceste concepte pentru a asigura coerența? În acest caz, s-ar putea să împărțim lucrarea în două bucăți, prima trimițând mesajul și plasând-o în coadă, iar a doua scriind în baza de date. În acest scenariu, putem reîncerca oricare lucrare de câte ori vrem – dacă furnizorul de trimitere a mesajelor este inactiv sau baza de date de contabilitate internă este inactivă, vom reîncerca în mod corespunzător până când vom reuși!
Gardurile bune fac vecini buni
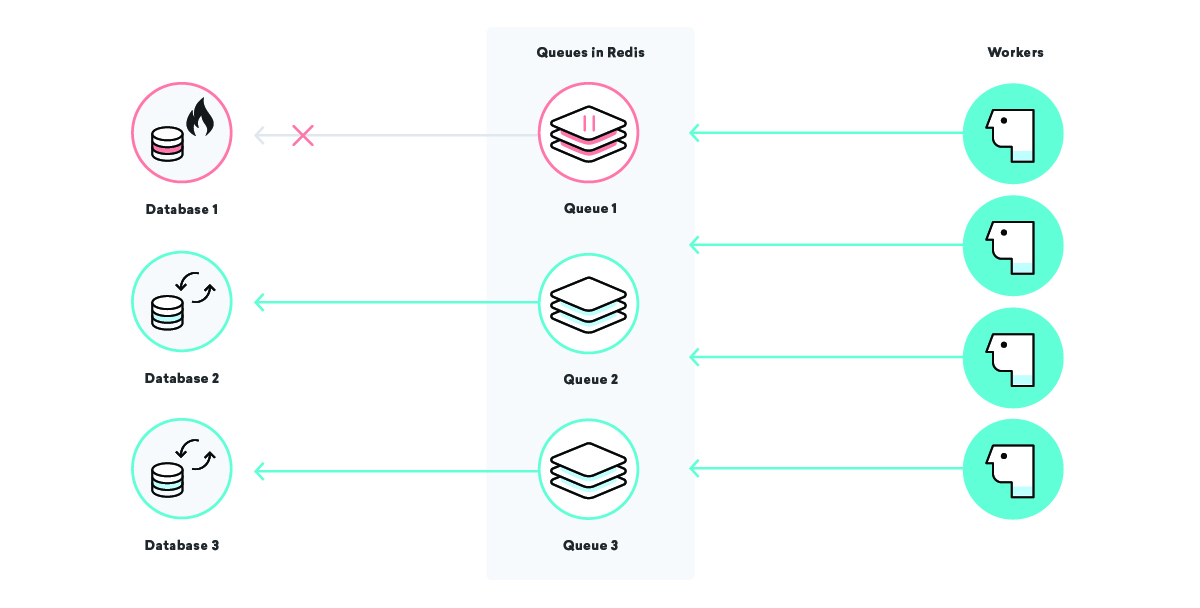
Ce se întâmplă cu prelucrarea datelor companiei noastre exemplu Consolidated Widgets atunci când baza de date pentru Global Gizmos este oprită?
În acest scenariu, dacă strategia noastră de livrare cel puțin o dată este în joc, ne-am aștepta ca toate joburile de procesare a datelor pentru Global Gizmos să reîncerce și din nou până când vor reuși. Acest lucru este grozav - nu vom pierde nicio dată chiar dacă baza lor de date este inactivă. Pentru Consolidated Widgets, totuși, s-ar putea să nu fie atât de grozav: dacă lucrătorii reîncearcă în mod constant și nu reușesc, ar putea fi prea ocupați pentru a procesa în timp util munca Consolidated Widgets.
Putem remedia acest lucru utilizând nume de cozi bine alese și întrerupând anumite cozi după cum este necesar. Cu acest lucru în centura noastră de instrumente, putem reduce presiunea asupra pieselor de infrastructură într-o manieră chirurgicală. În scenariul nostru de mai sus, odată ce știm că baza de date a Global Gizmos este oprită, putem întrerupe coada lor de procesare a datelor până când știm că este înapoi, asigurându-ne că o întrerupere anume nu afectează niciun alt client!

Așteptarea este dureroasă
Ce se întâmplă dacă Consolidated Widgets și Global Gizmos trimit campanii de e-mail la 50 de milioane de utilizatori fiecare, la 5 minute? Cine merge primul?
Sistemele simple de așteptare a locurilor de muncă au o coadă simplă „de lucru” din care lucrătorii scot joburi. Odată ce aveți o varietate bună de locuri de muncă și tipuri diferite de locuri de muncă, probabil că veți trece la mai multe tipuri de cozi, fiecare având priorități diferite sau tipuri de lucrători care trag din acele cozi. În acest sens, avem o varietate de cozi simple pentru procesarea datelor, mesagerie și diverse sarcini de întreținere.
Avansați rapid până când trimiteți miliarde de mesaje personalizate pe zi, o singură coadă de „mesajare” nu o va reduce – ce se întâmplă când acea coadă devine extrem de mare, ca în exemplul nostru de mai sus? Acordăm prioritate locurilor de muncă care au ajuns primele?
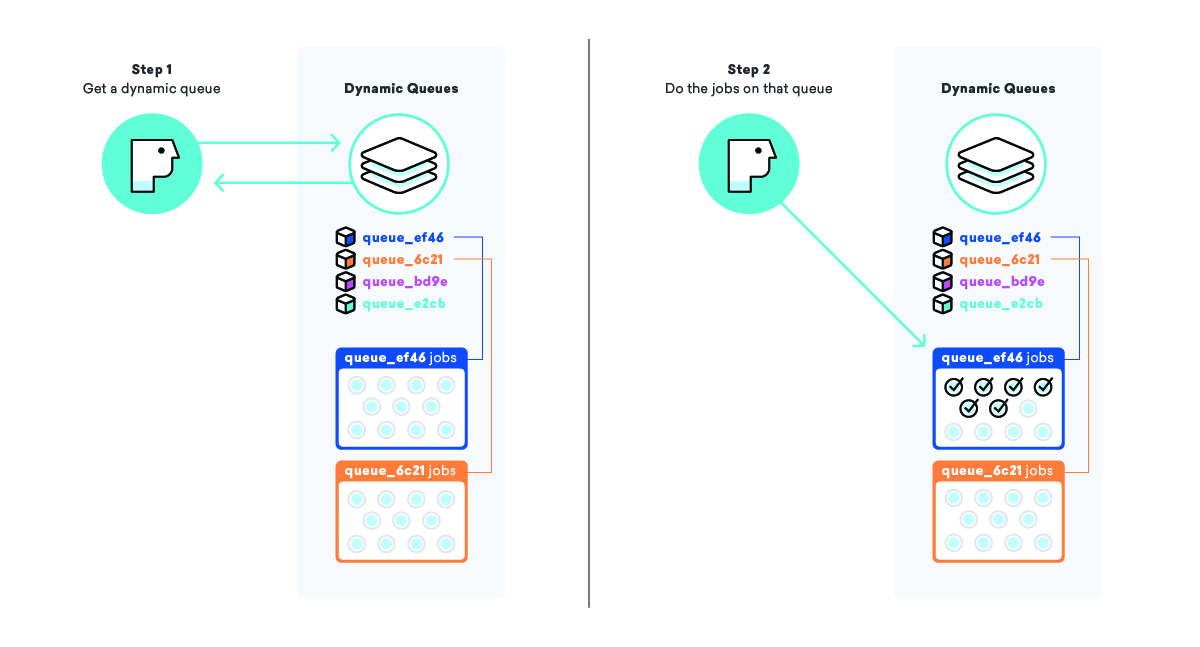
Sistemul nostru dinamic de așteptare caută să abordeze un fenomen numit înfometare de locuri de muncă, în care o lucrare care este gata de executare așteaptă mult timp înainte de a fi executată, de obicei din cauza unui fel de prioritate. Într-o coadă simplă de „mesajare”, prioritatea este pur și simplu momentul în care jobul a intrat în coadă, ceea ce înseamnă că joburile adăugate la sfârșitul unei cozi mari pot ajunge să aștepte foarte mult timp.
Când punem la coadă o campanie și toate mesajele acesteia, în loc să adăugăm joburile la o coadă mare de „mesaje”, creăm o coadă complet nouă doar pentru această campanie, completată cu un nume special, astfel încât să știm ce este și cum să-l găsesc. După adăugarea joburilor la coadă, luăm lista noastră de „cozi dinamice” și adăugăm acest nou nume de coadă la sfârșit.
Utilizând această strategie, putem instrui lucrătorii să preia numele unei cozi dinamice din lista „cozi dinamice”, apoi să proceseze toate joburile din acea coadă. Acest lucru ne permite să ne asigurăm că mesajele sunt trimise cât mai repede posibil ȘI că toți clienții noștri sunt tratați cu aceeași prioritate.
În consecință, acest lucru are alte beneficii, cum ar fi rate mai mari de accesare a cache-ului și mai puține conexiuni la baze de date, din cauza creșterii localității de lucru pentru anumiți lucrători. Toată lumea câștigă!
Aveți întotdeauna un plan de rezervă
Ce se întâmplă când o bază de date este oprită, unele cozi sunt întrerupte și cozile de joburi încep să se umple?
Uneori, piese importante de infrastructură pur și simplu mor pe tine. Avem elemente secundare și backup-uri, dar timpul necesar pentru a promova infrastructura de backup nu este aproape niciodată zero. A avea mai multe straturi de cozi în întreaga infrastructură a aplicațiilor poate fi foarte utilă în atenuarea impactului acestor tipuri de evenimente.
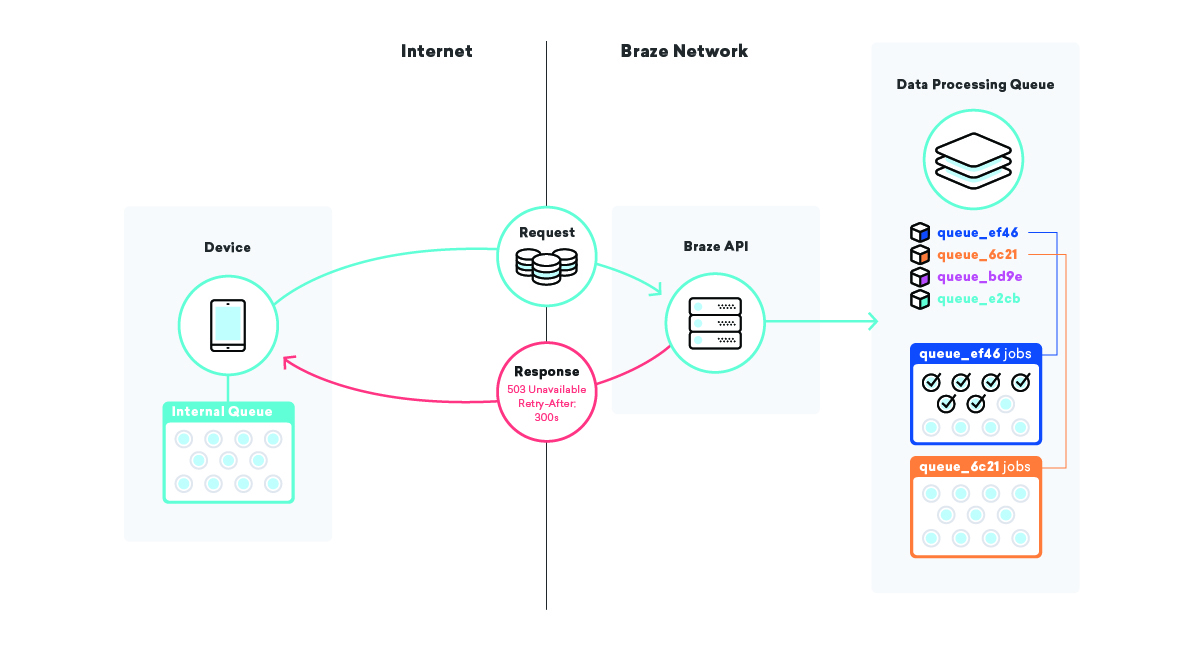
O astfel de strategie pe care o folosim este să stăm la coadă pe dispozitivele în sine. Milioane și milioane de dispozitive au aplicații diferite folosind un SDK Braze și, în aceste aplicații, utilizăm o coadă pentru trimiterea datelor către API-urile noastre.
Când SDK-ul nostru trimite acele date și nu reușește, indiferent de motiv, SDK-ul pune la coadă o reîncercare folosind un algoritm de backoff exponențial până când reușește. Această strategie minimizează impactul eșecurilor de infrastructură sau de cod, deoarece dispozitivele își vor pune pur și simplu în coadă propriile date și le vor trimite către Braze când totul este din nou online.
Mișcă rapid și nu sparge lucruri
La sfârșitul zilei, obiectivul nostru este să trimitem mesaje super-concentrate, personalizate mai bine decât oricine altcineva, iar asta presupune să ne mișcăm rapid, să fim rezistenți și să facem totul corect. Cozile de locuri de muncă sunt în centrul infrastructurii Braze, așa că urmărim mereu performanța noastră, utilizăm cele mai bune practici și experimentăm noi strategii și tehnici avansate pentru a fi cei mai buni în joc.
Dacă acest tip de inginerie de sisteme de înaltă performanță, cu latență scăzută în spațiul de automatizare a marketingului vă entuziasmează, atunci cu siguranță ar trebui să verificați forumul nostru de locuri de muncă!