
Învățare eficientă: viitorul apropiat al AI
Publicat: 2017-11-09Aceste tehnici eficiente de învățare nu sunt noi tehnici de învățare profundă/învățare automată, ci sporesc tehnicile existente ca hack-uri
Cu siguranță nu există nicio îndoială că viitorul suprem al inteligenței artificiale este atingerea și depășirea inteligenței umane. Dar aceasta este o ispravă exagerată de realizat. Chiar și cei mai optimiști dintre noi au pariat că AI la nivel uman (AGI sau ASI) va fi până la 10-15 ani de acum înainte, cu scepticii chiar dispuși să parieze că va dura secole, dacă este posibil. Ei bine, nu despre asta este vorba în postare.
Aici vom vorbi despre un viitor mai tangibil și mai apropiat și vom discuta despre algoritmii și tehnicile AI emergente și puternice care, în opinia noastră, vor modela viitorul apropiat al AI.
AI a început să îmbunătățească oamenii în câteva sarcini selectate și specifice. De exemplu, învingerea medicilor la diagnosticarea cancerului de piele și înfrângerea jucătorilor Go la campionatul mondial. Dar aceleași sisteme și modele vor eșua în îndeplinirea sarcinilor diferite de cele pe care au fost instruiți să le rezolve. Acesta este motivul pentru care, pe termen lung, un sistem în general inteligent, care îndeplinește un set de sarcini eficient, fără a fi nevoie de reevaluare, este numit viitorul AI.
Dar, în viitorul apropiat al AI, cu mult înainte de apariția AGI, cum vor face oamenii de știință posibil ca algoritmul alimentat de AI să depășească problemele cu care se confruntă astăzi pentru a ieși din laboratoare și a deveni obiecte de uz zilnic?
Când te uiți în jur, AI câștigă câte un castel la un moment dat (citește postările noastre despre cum AI depășește oamenii, partea întâi și partea a doua). Ce ar putea merge prost într-un astfel de joc câștig-câștig? Oamenii produc din ce în ce mai multe date (care este hrana pe care o consumă AI) cu timpul și capacitățile noastre hardware devin tot mai bune. La urma urmei, datele și calculele mai bune sunt motivele pentru care revoluția Deep Learning a început în 2012, nu? Adevărul este că mai rapid decât creșterea datelor și a calculelor este creșterea așteptărilor umane. Oamenii de știință ar trebui să se gândească la soluții dincolo de ceea ce există acum pentru a rezolva problemele din lumea reală. De exemplu, clasificarea imaginilor, așa cum ar crede majoritatea oamenilor, este o problemă rezolvată din punct de vedere științific (dacă rezistăm impulsului de a spune acuratețe 100% sau GTFO).
Putem clasifica imagini (să spunem în imagini cu pisici sau imagini cu câini) care se potrivesc cu capacitatea umană folosind AI. Dar poate fi folosit deja pentru cazuri de utilizare din lumea reală? Poate AI să ofere o soluție pentru problemele mai practice cu care se confruntă oamenii? În unele cazuri, da, dar în multe cazuri nu suntem încă acolo.
Vă vom prezenta provocările care sunt principalele obstacole pentru dezvoltarea unei soluții reale folosind AI. Să presupunem că doriți să clasificați imagini cu pisici și câini. Vom folosi acest exemplu pe tot parcursul postării.

Exemplul nostru de algoritm: Clasificarea imaginilor cu pisici și câini
Graficul de mai jos rezumă provocările:

Provocări implicate în dezvoltarea unei IA din lumea reală
Să discutăm în detaliu aceste provocări:
Învățare cu mai puține date
- Datele de antrenament pe care le consumă cei mai de succes algoritmi de învățare profundă necesită ca acestea să fie etichetate în funcție de conținutul/funcția pe care o conține. Acest proces se numește adnotare.
- Algoritmii nu pot folosi datele găsite în mod natural în jurul tău. Adnotarea a câteva sute (sau câteva mii de puncte de date) este ușoară, dar algoritmul nostru de clasificare a imaginilor la nivel uman a avut nevoie de un milion de imagini adnotate pentru a învăța bine.
- Deci întrebarea este dacă adnotarea unui milion de imagini este posibilă? Dacă nu, atunci cum se poate scala AI cu o cantitate mai mică de date adnotate?
Rezolvarea diverselor probleme din lumea reală
- În timp ce seturile de date sunt fixe, utilizarea în lumea reală este mai diversă (să spunem, de exemplu, algoritmul antrenat pe imagini colorate ar putea eșua grav pe imaginile în tonuri de gri, spre deosebire de oameni).
- În timp ce am îmbunătățit algoritmii de computer Vision pentru a detecta obiecte care să se potrivească cu oamenii. Dar, așa cum am menționat mai devreme, acești algoritmi rezolvă o problemă foarte specifică în comparație cu inteligența umană, care este mult mai generică în multe sensuri.
- Exemplul nostru de algoritm AI, care clasifică pisicile și câinii, nu va putea identifica o specie rară de câini dacă nu este hrănit cu imagini ale acelei specii.
Ajustarea datelor incrementale
- O altă provocare majoră este datele incrementale. În exemplul nostru, dacă încercăm să recunoaștem pisicile și câinii, s-ar putea să ne antrenăm inteligența artificială pentru un număr de imagini de pisici și câini de diferite specii în timp ce vom implementa prima dată. Dar la descoperirea unei noi specii, trebuie să antrenăm algoritmul pentru a recunoaște „Kotpies” împreună cu speciile anterioare.
- În timp ce noile specii ar putea fi mai asemănătoare cu altele decât credem și pot fi antrenate cu ușurință pentru a adapta algoritmul, există puncte în care acest lucru este mai greu și necesită reantrenare și reevaluare completă.
- Întrebarea este că putem face AI cel puțin adaptabil la aceste mici schimbări?
Pentru a face AI imediat utilizabilă, ideea este de a rezolva provocările menționate mai sus printr-un set de abordări numite Învățare eficientă (vă rugăm să rețineți că nu este un termen oficial, îl inventez doar pentru a evita să scriu Meta-Learning, Transfer Learning, Few). Învățare prin shot, Învățare adversară și Învățare cu sarcini multiple de fiecare dată). Noi, cei de la ParallelDots, folosim acum aceste abordări pentru a rezolva probleme înguste cu AI, câștigând bătălii mici în timp ce ne pregătim pentru AI mai cuprinzătoare pentru a cuceri războaie mai mari. Permiteți-ne să vă prezentăm aceste tehnici pe rând.
În mod remarcabil, majoritatea acestor tehnici de învățare eficientă nu sunt ceva nou. Ei doar văd o renaștere acum. Cercetătorii SVM (Support Vector Machines) au folosit aceste tehnici de mult timp. Învățarea adversară, pe de altă parte, este ceva rezultat din munca recentă a lui Goodfellow în GAN-uri, iar raționamentul neuronal este un nou set de tehnici pentru care seturile de date au devenit disponibile foarte recent. Să analizăm în profunzime modul în care aceste tehnici vor ajuta la modelarea viitorului AI.
Transfer de învățare
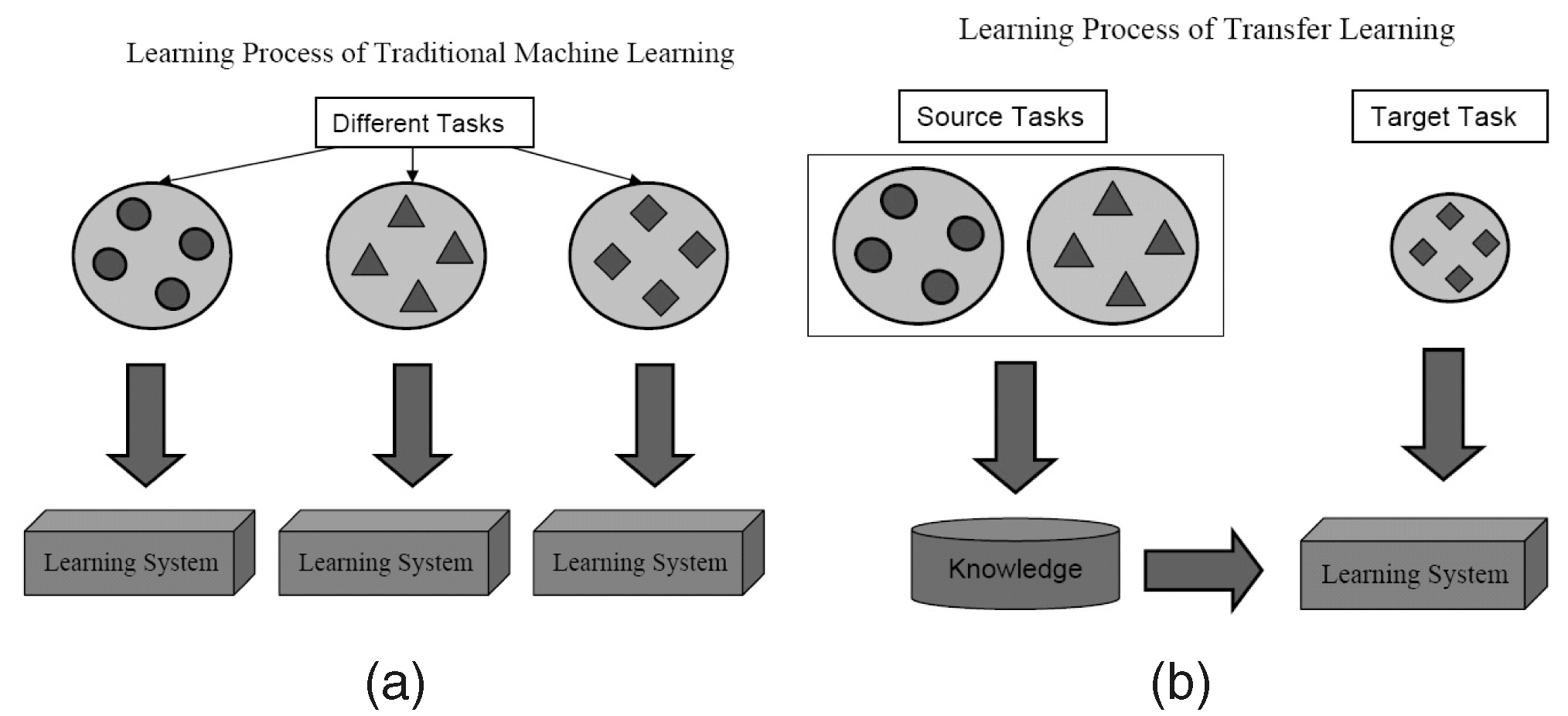
Ce este?
După cum sugerează și numele, învățarea este transferată de la o sarcină la alta în cadrul aceluiași algoritm în Transfer Learning. Algoritmii antrenați pentru o sarcină (sarcină sursă) cu un set de date mai mare pot fi transferați cu sau fără modificare ca parte a algoritmului care încearcă să învețe o sarcină diferită (sarcină țintă) pe un set de date (relativ) mai mic.
Cateva exemple
Utilizarea parametrilor unui algoritm de clasificare a imaginilor ca extract de caracteristici în diferite sarcini, cum ar fi detectarea obiectelor, este o aplicație simplă a Transfer Learning. În schimb, poate fi folosit și pentru a îndeplini sarcini complexe. Algoritmul dezvoltat de Google pentru a clasifica retinopatia diabetică mai bine decât medicii a fost realizat cu ajutorul Transfer Learning. În mod surprinzător, detectorul de retinopatie diabetică a fost de fapt un clasificator de imagini din lumea reală (clasificator de imagini câine/pisică) Transfer Learning pentru a clasifica scanările oculare.
Spune-mi mai multe!
Veți găsi oamenii de știință care apelează astfel de părți transferate ale rețelelor neuronale de la sursă la sarcina țintă ca rețele pregătite în literatura de specialitate. Reglarea fină este atunci când erorile de sarcină țintă sunt ușor retropropagate în rețeaua preantrenată în loc să utilizeze rețeaua preantrenată nemodificată. O bună introducere tehnică la Transfer Learning in Computer Vision poate fi văzută aici. Acest concept simplu de învățare prin transfer este foarte important în setul nostru de metodologii de învățare eficientă.
Recomandat pentru tine:

Cum va transforma Metaverse industria auto din India

Ce înseamnă prevederea anti-Profiteering pentru startup-urile indiene?

Cum startup-urile Edtech ajută forța de muncă din India să își îmbunătățească abilitățile și să devină pregătite pentru viitor...

Stocuri de tehnologie New-Age săptămâna aceasta: problemele Zomato continuă, EaseMyTrip postează Stro...

Startup-urile indiene iau comenzi rapide în căutarea finanțării

Platforma de marketing digital Logicserve are finanțare de 80 INR Cr, rebrand-urile ca LS Dig...
Învățare cu mai multe sarcini
Ce este?
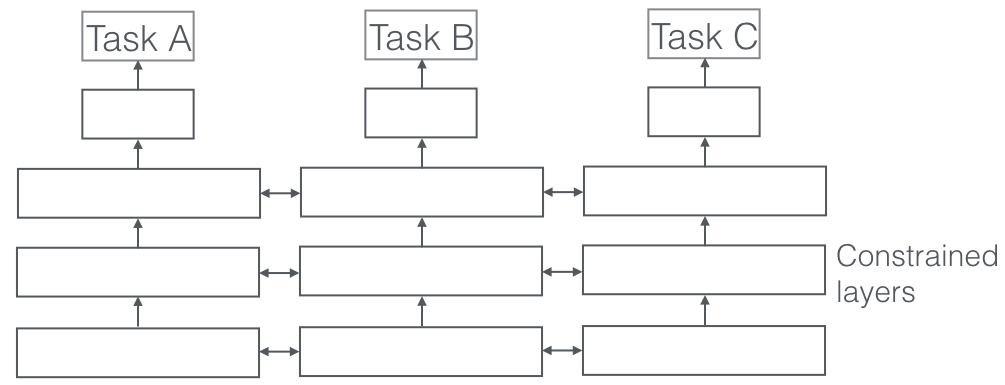

În Multi-Task Learning, mai multe sarcini de învățare sunt rezolvate în același timp, exploatând în același timp punctele comune și diferențele dintre sarcini. Este surprinzător, dar uneori învățarea a două sau mai multe sarcini împreună (numite și sarcini principale și sarcini auxiliare) poate face rezultate mai bune pentru sarcini. Vă rugăm să rețineți că nu fiecare pereche sau triplet sau cvartet de sarcini poate fi considerată auxiliară. Dar când funcționează, este o creștere gratuită a preciziei.
Cateva exemple
De exemplu, la ParallelDots, clasificatorii noștri de detectare a sentimentelor, intenției și emoțiilor au fost instruiți ca învățare cu sarcini multiple, ceea ce le-a crescut acuratețea în comparație cu dacă i-am antrena separat. Cel mai bun sistem de etichetare semantică a rolurilor și etichetare POS din NLP pe care îl cunoaștem este un sistem de învățare cu sarcini multiple, deci este unul dintre cele mai bune sisteme pentru segmentarea semantică și a instanțelor în Computer Vision. Google a venit cu Multi-Task Learners multimodali (un model care să-i conducă pe toți) care pot învăța atât din seturi de date vizuale, cât și din text în aceeași fotografie.
Spune-mi mai multe!
Un aspect foarte important al învățării cu sarcini multiple, care se vede în aplicațiile din lumea reală, este acela în care antrenarea oricărei sarcini pentru a deveni antiglonț, trebuie să respectăm multe domenii din care provin datele (numită și adaptare de domeniu). Un exemplu în cazurile noastre de utilizare pentru pisici și câini va fi un algoritm care poate recunoaște imagini din diferite surse (să zicem camere VGA și camere HD sau chiar camere cu infraroșu). În astfel de cazuri, o pierdere auxiliară a clasificării domeniului (de unde au venit imaginile) poate fi adăugată la orice sarcină și apoi mașina învață astfel încât algoritmul continuă să se îmbunătățească la sarcina principală (clasificarea imaginilor în imagini de pisică sau câine), dar înrăutățirea intenționată la sarcina auxiliară (acest lucru se face prin propagarea inversă a gradientului de eroare din sarcina de clasificare a domeniului). Ideea este că algoritmul învață caracteristici discriminatorii pentru sarcina principală, dar uită caracteristici care diferențiază domeniile și acest lucru l-ar îmbunătăți. Multi-Task Learning și verii săi de adaptare la domenii sunt una dintre cele mai de succes tehnici de învățare eficientă pe care le cunoaștem și au un rol important de jucat în modelarea viitorului AI.
Învățare adversară
Ce este?
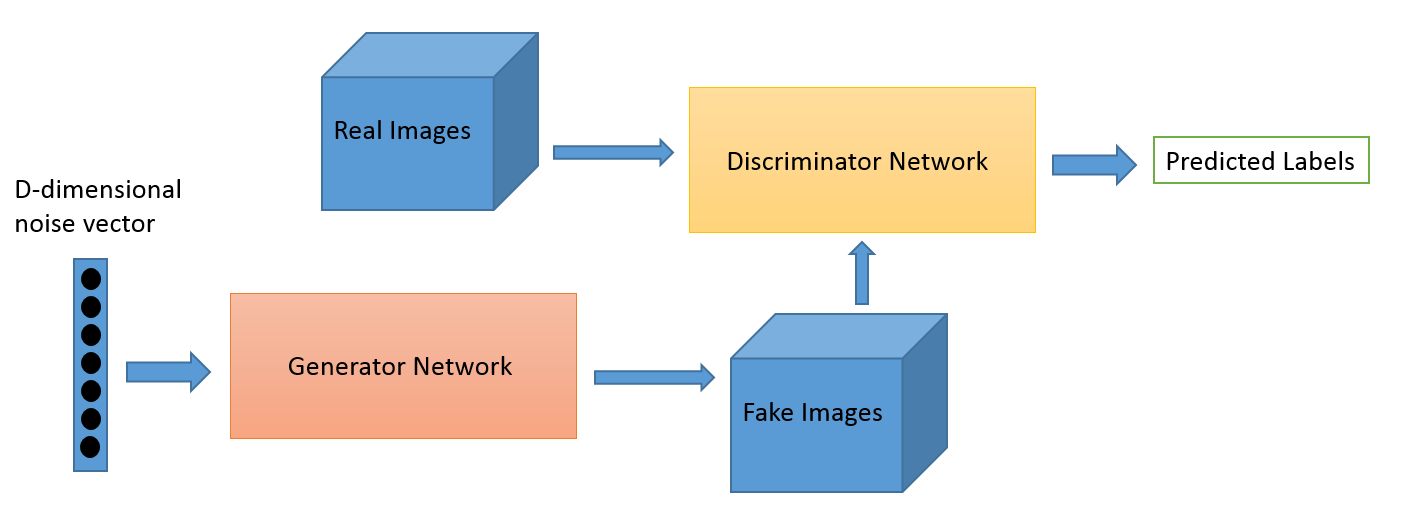
Învățarea adversară ca domeniu a evoluat din munca de cercetare a lui Ian Goodfellow. În timp ce cele mai populare aplicații ale învățării adversare sunt, fără îndoială, rețelele generative adversare (GAN), care pot fi utilizate pentru a genera imagini uimitoare, există mai multe alte moduri în acest set de tehnici. De obicei, această tehnică inspirată de teoria jocurilor are doi algoritmi, un generator și un discriminator, al căror scop este să se păcălească reciproc în timp ce se antrenează. Generatorul poate fi folosit pentru a genera noi imagini noi, așa cum am discutat, dar poate genera și reprezentări ale oricăror alte date pentru a ascunde detaliile de discriminator. Acesta din urmă este motivul pentru care acest concept ne interesează atât de mult.
Cateva exemple
Acesta este un domeniu nou și capacitatea de generare a imaginii este probabil pe care se concentrează cei mai mulți oameni interesați, precum astronomii. Dar credem că acest lucru va dezvolta și cazuri de utilizare mai noi, așa cum vom spune mai târziu.
Spune-mi mai multe!
Jocul de adaptare a domeniului poate fi îmbunătățit folosind pierderea GAN. Pierderea auxiliară aici este un sistem GAN în loc de clasificarea pur domeniului, în care un discriminator încearcă să clasifice din ce domeniu provin datele și o componentă generatoare încearcă să-l păcălească prezentând zgomot aleatoriu ca date. Din experiența noastră, acest lucru funcționează mai bine decât adaptarea unui domeniu simplu (care este, de asemenea, mai neregulată pentru cod).
Puțini Shot Learning
Ce este?
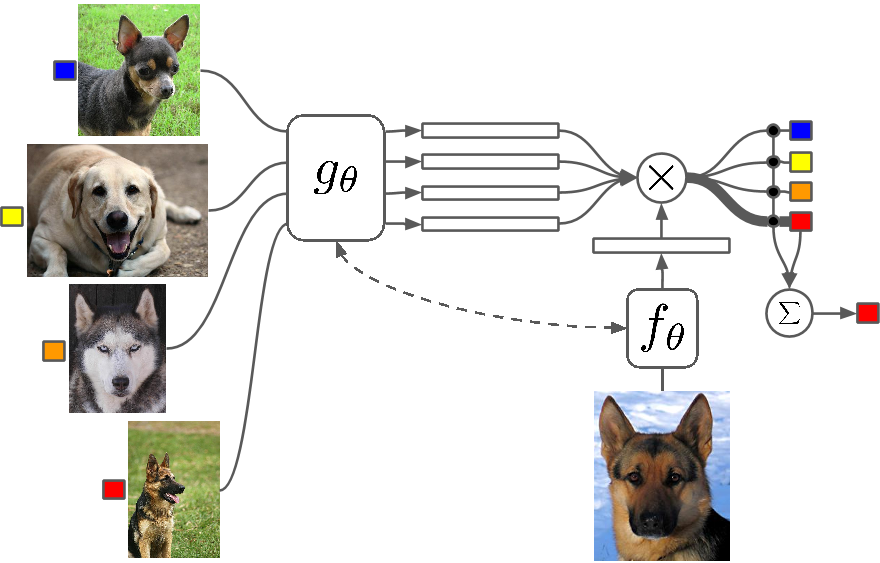
Few Shot Learning este un studiu al tehnicilor care fac ca algoritmii de învățare profundă (sau orice algoritm de învățare automată) să învețe cu un număr mai mic de exemple în comparație cu ceea ce ar face un algoritm tradițional. Învățarea One Shot înseamnă în principiu învățarea cu un exemplu de categorie, în mod inductiv învățarea k-shot înseamnă învățarea cu k exemple din fiecare categorie.
Cateva exemple
Puțini Shot Learning ca domeniu înregistrează un aflux de lucrări în toate conferințele majore de Deep Learning și acum există seturi de date specifice pentru a evalua rezultatele, la fel cum sunt MNIST și CIFAR pentru învățarea automată normală. One-shot Learning vede o serie de aplicații în anumite sarcini de clasificare a imaginilor, cum ar fi detectarea și reprezentarea caracteristicilor.
Spune-mi mai multe!
Există mai multe metode care sunt utilizate pentru învățarea Few Shot, inclusiv Transfer Learning, Multi-Task Learning, precum și Meta-Learning ca tot sau parțial algoritm. Există și alte moduri, cum ar fi să aveți o funcție inteligentă de pierdere, să folosiți arhitecturi dinamice sau să folosiți hack-uri de optimizare. Zero Shot Learning, o clasă de algoritmi care pretind că prezică răspunsuri pentru categorii pe care algoritmul nici nu le-a văzut, sunt practic algoritmi care pot scala cu un nou tip de date.
Meta-învățare
Ce este?

Meta-Learning este exact ceea ce sună, un algoritm care se antrenează astfel încât, la vizualizarea unui set de date, produce un nou predictor de învățare automată pentru acel set de date. Definiția este foarte futuristă dacă îi arunci o primă privire. Simți „hoa! asta face un Data Scientist” și automatizează „cea mai sexy slujbă din secolul 21”, iar în anumite sensuri, Meta-Learners au început să facă asta.
Cateva exemple
Meta-Learning a devenit recent un subiect fierbinte în Deep Learning, cu o mulțime de lucrări de cercetare care au apărut, cel mai frecvent utilizând tehnica de optimizare a hiperparametrilor și a rețelelor neuronale, găsirea unor arhitecturi bune de rețea, recunoașterea imaginilor Few-Shot și învățarea rapidă de consolidare.
Spune-mi mai multe!
Unii oameni se referă la această automatizare completă a deciziei atât a parametrilor, cât și a hiperparametrilor, cum ar fi arhitectura de rețea, ca autoML și s-ar putea să găsiți oameni care se referă la Meta Learning și AutoML ca domenii diferite. În ciuda tuturor hype-ului din jurul lor, adevărul este că Meta Learners sunt încă algoritmi și căi de scalare a Machine Learning, cu complexitatea și varietatea datelor în creștere.
Cele mai multe lucrări de Meta-Learning sunt hack-uri inteligente, care, conform Wikipedia, au următoarele proprietăți:
- Sistemul trebuie să includă un subsistem de învățare, care se adaptează cu experiența.
- Experiența este câștigată prin exploatarea meta-cunoștințelor extrase fie într-un episod de învățare anterior pe un singur set de date, fie din domenii sau probleme diferite.
- Prejudecățile de învățare trebuie alese dinamic.
Subsistemul este practic o configurație care se adaptează atunci când metadatele unui domeniu (sau un domeniu complet nou) sunt introduse în el. Aceste metadate pot spune despre creșterea numărului de clase, complexitate, modificarea culorilor și texturilor și obiectelor (în imagini), stiluri, modele de limbaj (limbaj natural) și alte caracteristici similare. Consultați câteva lucrări super cool aici: Meta-Learning Shared Hierarchies și Meta-Learning Using Temporal Convolutions. De asemenea, puteți construi algoritmi Few Shot sau Zero Shot folosind arhitecturi Meta-Learning. Meta-Learning este una dintre cele mai promițătoare tehnici care va ajuta la modelarea viitorului AI.
Raționamentul neuronal
Ce este?

Raționamentul neuronal este următorul lucru important în problemele de clasificare a imaginilor. Raționamentul neuronal este un pas deasupra recunoașterii modelelor în care algoritmii trec dincolo de ideea de a identifica și clasifica pur și simplu textul sau imaginile. Raționamentul neuronal rezolvă întrebări mai generice în analiza textului sau a analizei vizuale. De exemplu, imaginea de mai jos reprezintă un set de întrebări la care Raționamentul Neural poate răspunde dintr-o imagine.
Spune-mi mai multe!
Acest nou set de tehnici apare după lansarea setului de date bAbi de la Facebook sau a setului de date recent CLEVR. Tehnicile care vin pentru a descifra relațiile și nu doar modelele au un potențial imens de a rezolva nu doar raționamentul neuronal, ci și multe alte probleme dificile, inclusiv problemele de învățare Few Shot.
Mă întorc
Acum că știm care sunt tehnicile, să ne întoarcem și să vedem cum rezolvă problemele de bază cu care am început. Tabelul de mai jos oferă o imagine instantanee a capacităților tehnicilor de învățare eficientă pentru a face față provocărilor:
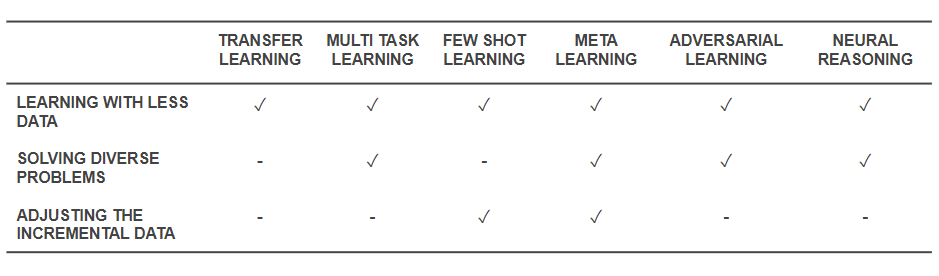
Capabilități ale tehnicilor de învățare eficientă
- Toate tehnicile menționate mai sus ajută la rezolvarea antrenamentului cu o cantitate mai mică de date într-un fel sau altul. În timp ce Meta-Learning ar oferi arhitecturi care s-ar modela doar cu date, Transfer Learning face cunoștințele din alt domeniu utile pentru a compensa mai puține date. Few Shot Learning este dedicat problemei ca disciplină științifică. Învățarea adversară poate ajuta la îmbunătățirea setului de date.
- Adaptarea domeniului (un tip de învățare cu sarcini multiple), învățarea adversară și (uneori) arhitecturile meta-învățare ajută la rezolvarea problemelor care decurg din diversitatea datelor.
- Meta-Learning și Few Shot Learning ajută la rezolvarea problemelor de date incrementale.
- Algoritmii de raționament neuronal au un potențial imens de a rezolva probleme din lumea reală atunci când sunt încorporați ca Meta-Learners sau Few Shot Learners.
Vă rugăm să rețineți că aceste tehnici de învățare eficientă nu sunt noi tehnici de învățare profundă/învățare automată, ci sporesc tehnicile existente sub formă de hack -uri, făcându-le mai avantajoase. Prin urmare, veți vedea în continuare instrumentele noastre obișnuite, cum ar fi rețelele neuronale convoluționale și LSTM-urile în acțiune, dar cu condimentele adăugate. Aceste tehnici de învățare eficientă, care funcționează cu mai puține date și realizează multe sarcini dintr-o dată, pot ajuta la producția și comercializarea mai ușoară a produselor și serviciilor bazate pe inteligență artificială. La ParallelDots, recunoaștem puterea învățării eficiente și o încorporăm ca una dintre principalele caracteristici ale filozofiei noastre de cercetare.
Această postare a lui Parth Shrivastava a apărut pentru prima dată pe blogul ParallelDots și a fost reprodusă cu permisiunea.