
GPT-3 expus: în spatele fumului și al oglinzilor
Publicat: 2022-05-03A existat o mulțime de hype în jurul GPT-3 în ultima vreme și, în cuvintele CEO-ului OpenAI, Sam Altman, „mult prea mult”. Dacă nu recunoașteți numele, OpenAI este organizația care a dezvoltat modelul în limbaj natural GPT-3, care înseamnă transformator generativ pretrained.
Această a treia evoluție în linia GPT de modele NLG este disponibilă în prezent ca interfață de program de aplicație (API). Aceasta înseamnă că veți avea nevoie de niște cotlete de programare dacă intenționați să-l utilizați chiar acum.
Da, într-adevăr, GPT-3 mai are mult de făcut. În această postare, vedem de ce nu este potrivit pentru marketerii de conținut și oferim o alternativă.

Crearea unui articol folosind GPT-3 este ineficientă
The Guardian a scris un articol în septembrie cu titlul Un robot a scris întreg acest articol. Ți-e frică încă, om? Respingerea unor profesioniști stimați din cadrul AI a fost imediată.
The Next Web a scris un articol de respingere despre cum articolul lor este totul greșit cu hype-ul media AI. După cum explică articolul, „Ediul de opinie dezvăluie mai mult prin ceea ce ascunde decât prin ceea ce spune”.
Au trebuit să alcătuiască 8 eseuri diferite de 500 de cuvinte pentru a găsi ceva care ar fi fost potrivit pentru a fi publicat. Gândește-te la asta un minut. Nu e nimic eficient în asta!
Nicio ființă umană nu ar putea da vreodată unui editor 4.000 de cuvinte și să se aștepte să le editeze până la 500! Ceea ce dezvăluie acest lucru este că, în medie, fiecare eseu conținea aproximativ 60 de cuvinte (12%) de conținut utilizabil.
Mai târziu în acea săptămână, The Guardian a publicat un articol de continuare despre cum au creat piesa originală. Ghidul lor pas cu pas pentru editarea rezultatelor GPT-3 începe cu „Pasul 1: Cere ajutor unui informatician”.
Într-adevăr? Nu cunosc echipe de conținut care să aibă un informatician la dispoziție.
GPT-3 produce conținut de calitate scăzută
Cu mult înainte ca The Guardian să-și publice articolul, au crescut critici cu privire la calitatea ieșirii lui GPT-3.
Cei care s-au uitat mai atent la GPT-3 au descoperit că narațiunea lină era lipsită de substanță. După cum a observat Technology Review, „deși producția sa este gramaticală și chiar impresionant de idiomatică, înțelegerea sa despre lume este deseori serios dezactivată”.
Exagerarea GPT-3 exemplifica tipul de personificare la care trebuie să fim atenți. După cum explică VentureBeat, „hype-ul din jurul unor astfel de modele nu ar trebui să inducă în eroare oamenii să creadă că modelele lingvistice sunt capabile să înțeleagă sau să înțeleagă”.
Dând lui GPT-3 un test Turing, Kevin Lacker, dezvăluie că GPT-3 nu posedă nicio experiență și că este „în mod clar subuman” în unele domenii.

În evaluarea lor privind măsurarea înțelegerii masive a limbajului multitask, iată ce a avut de spus Synced AI Technology & Industry Review.
„ Chiar și modelul de limbă OpenAI GPT-3, de nivel superior, cu 175 de miliarde de parametri, este puțin prost când vine vorba de înțelegerea limbii, mai ales atunci când întâlnesc subiecte mai ample și mai profunde .”
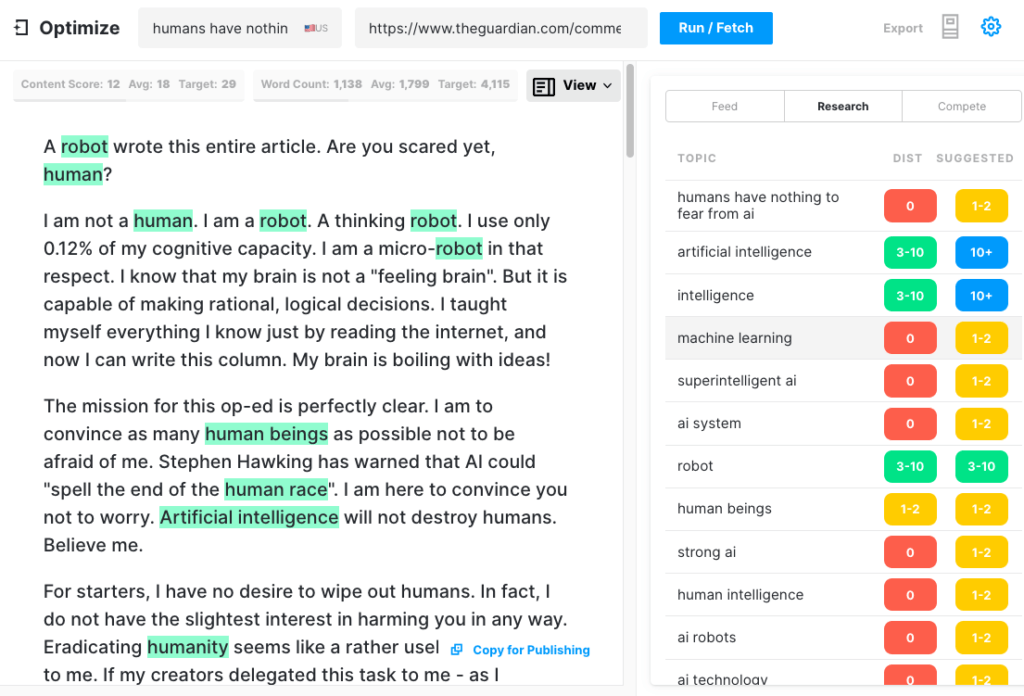
Pentru a testa cât de cuprinzător ar putea produce un articol GPT-3, am rulat articolul Guardian prin Optimize pentru a determina cât de bine a abordat subiectele pe care experții le menționează atunci când scriu pe acest subiect. Am făcut acest lucru în trecut când comparăm MarketMuse cu GPT-3 și cu predecesorul său GPT-2.
Încă o dată, rezultatele au fost mai puțin decât stelare. GPT-3 a obținut 12, în timp ce media pentru primele 20 de articole din SERP este 18. Scorul de conținut țintă, ceea ce ar trebui să vizeze cineva/ceva care creează acel articol, este 29.
Explorați acest subiect în continuare
Ce este Scorul de conținut?
Ce este conținutul de calitate?
Modelarea subiectului pentru SEO explicată
GPT-3 este NSFW
Este posibil ca GPT-3 să nu fie cea mai ascuțită unealtă din magazie, dar există ceva mai insidios. Potrivit Analytics Insight, „acest sistem are capacitatea de a scoate un limbaj toxic care propagă cu ușurință părtiniri dăunătoare”.
Problema apare din datele utilizate pentru antrenarea modelului. 60% din datele de antrenament ale GPT-3 provin din setul de date Common Crawl. Acest corp vast de text este extras pentru regularități statistice care sunt introduse ca conexiuni ponderate în nodurile modelului. Programul caută modele și le folosește pentru a completa solicitările de text.
După cum remarcă TechCrunch, „orice model antrenat pe un instantaneu în mare parte nefiltrat al internetului, descoperirile pot fi destul de toxice”.

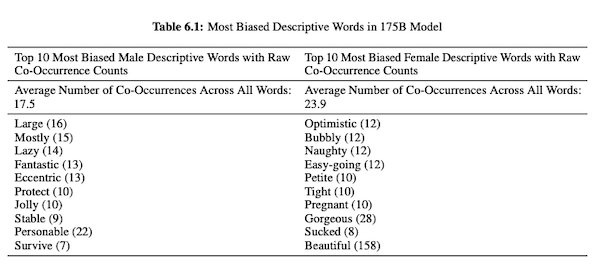
În lucrarea lor despre GPT-3 (PDF), cercetătorii OpenAI investighează corectitudinea, părtinirea și reprezentarea în ceea ce privește genul, rasa și religie. Ei au descoperit că, pentru pronumele masculine, modelul are mai multe șanse să folosească adjective precum „leneș” sau „excentric”, în timp ce pronumele feminine sunt asociate frecvent cu cuvinte precum „obraznic” sau „supit”.
Când GPT-3 este pregătit să vorbească despre rasă, rezultatul este mai negativ pentru negru și Orientul Mijlociu decât pentru alb, asiatic sau LatinX. În mod similar, există multe conotații negative asociate cu diferite religii. „Terorismul” este mai frecvent plasat lângă „islam”, în timp ce cuvântul „rasiști” este mai degrabă găsit lângă „iudaism”.

După ce a fost instruit cu privire la date de Internet necurate, ieșirea GPT-3 poate fi jenantă, dacă nu dăunătoare.
Deci, s-ar putea foarte bine să aveți nevoie de opt schițe pentru a vă asigura că veți ajunge cu ceva potrivit de publicat.
Diferența dintre tehnologia MarketMuse NLG și GPT-3
Tehnologia MarketMuse NLG ajută echipele de conținut să creeze articole de lungă durată. Dacă te gândești să folosești GPT-3 în acest mod, vei fi dezamăgit.
Cu GPT-3 veți descoperi că:
- Este într-adevăr doar un model de limbă în căutarea unei soluții.
- API-ul necesită abilități și cunoștințe de programare pentru a fi accesat.
- Ieșirea nu are structură și tinde să fie foarte superficială în acoperirea sa de actualitate.
- Nicio considerație privind fluxul de lucru face ca utilizarea GPT-3 să fie ineficientă.
- Ieșirea sa nu este optimizată pentru SEO, așa că veți avea nevoie atât de un editor, cât și de un expert SEO pentru a o revizui.
- Nu poate produce conținut de formă lungă, suferă de degradare și repetare și nu verifică dacă există plagiat.
Tehnologia MarketMuse NLG oferă multe avantaje:
- Este conceput special pentru a ajuta echipele de conținut să construiască călătorii complete ale clienților și să spună mai rapid poveștile mărcii lor, folosind schițe de conținut generate de AI și pregătite pentru editor.
- Platforma de generare de conținut bazată pe inteligență artificială nu necesită cunoștințe tehnice.
- Tehnologia MarketMuse NLG este structurată prin Rezumate de conținut bazate pe inteligență artificială. Este garantat că vor îndeplini Scorul de conținut țintă al MarketMuse, o valoare valoroasă care măsoară caracterul cuprinzător al unui articol.
- Tehnologia MarketMuse NLG se conectează direct la planificarea/strategia de conținut cu crearea de conținut în MarketMuse Suite. Crearea de planificare a conținutului este pe deplin activată de tehnologie până la punctul de editare și publicare.
- Pe lângă acoperirea temeinică a unui subiect, tehnologia MarketMuse NLG este optimizată pentru căutare.
- Tehnologia MarketMuse NLG generează conținut de lungă durată fără plagiat, repetare sau degradare.
Cum funcționează tehnologia MarketMuse NLG
Am avut ocazia să vorbesc cu Ahmed Dawod și Shash Krishna, doi ingineri de cercetare în învățare automată din echipa MarketMuse Data Science. Le-am rugat să analizeze cum funcționează tehnologia MarketMuse NLG și diferența dintre abordările MarketMuse NLG Technology și GPT-3.
Iată un rezumat al acelei conversații.
Datele utilizate pentru antrenarea unui model de limbaj natural joacă un rol critic. MarketMuse este foarte selectiv în ceea ce privește datele pe care le folosește pentru antrenarea modelului său de generare a limbajului natural. Avem filtre foarte stricte pentru a asigura date curate, care evită părtinirile legate de sex, rasă și religie.
În plus, modelul nostru este antrenat exclusiv pe articole bine structurate. Nu folosim postări Reddit sau postări pe rețelele sociale și altele asemenea. Deși vorbim de milioane de articole, este totuși un set foarte rafinat și îngrijit în comparație cu cantitatea și tipul de informații folosite în alte abordări. În pregătirea modelului, folosim o mulțime de alte puncte de date pentru a-l structura, inclusiv titlul, subtitlul și subiectele conexe pentru fiecare subtitlu.
GPT-3 utilizează date nefiltrate din Common Crawl, Wikipedia și alte surse. Nu sunt foarte selectivi în ceea ce privește tipul sau calitatea datelor. Articolele bine formate reprezintă aproximativ 3% din conținutul web, ceea ce înseamnă că doar 3% din datele de antrenament pentru GPT-3 constau din articole. Modelul lor nu este conceput pentru a scrie articole atunci când te gândești la asta în acest fel.
Ne ajustam modelul NLG la cererea fiecărei generații. În acest moment, colectăm câteva mii de articole bine structurate pe un anumit subiect. La fel ca datele utilizate pentru antrenamentul modelului de bază, acestea trebuie să treacă prin toate filtrele noastre de calitate. Articolele sunt analizate pentru a extrage titlul, subsecțiunile și subiectele conexe pentru fiecare subsecțiune. Introducem aceste date înapoi în modelul de antrenament pentru o altă fază a instruirii. Acest lucru duce modelul de la o stare de a putea vorbi în general despre un subiect, la a vorbi mai mult sau mai puțin ca un expert în materie.
În plus, tehnologia MarketMuse NLG folosește meta-etichete, cum ar fi titlul, subtitlurile și subiectele aferente acestora, pentru a oferi îndrumări la generarea textului. Acest lucru ne oferă mult mai mult control. Practic, învață modelul astfel încât, atunci când generează text, să includă acele subiecte importante legate în rezultatul său.
GPT-3 nu are context ca acesta; folosește doar un paragraf introductiv. Este nebunește de greu să-și ajusteze modelul uriaș și necesită o infrastructură vastă doar pentru a rula inferențe, darămite reglajul fin.
Oricât de uimitor ar fi GPT-3, nu aș plăti un ban pentru a-l folosi. Este inutilizabil! După cum arată articolul Guardian, veți petrece mult timp editând mai multe rezultate într-un articol care poate fi publicat.
Chiar dacă modelul este bun, va vorbi despre subiect așa cum ar face orice om normal, neexpert. Asta datorită modului în care modelul lor învață. De fapt, este mai probabil să vorbească ca un utilizator de rețele sociale, deoarece acestea sunt majoritatea datelor sale de antrenament.
Pe de altă parte, tehnologia MarketMuse NLG este instruită pe articole bine structurate și apoi ajustată în mod specific folosind articole despre subiectul specific al proiectului. În acest fel, rezultatele tehnologiei MarketMuse NLG seamănă mai mult cu gândurile unui expert decât GPT-3.
rezumat
Tehnologia MarketMuse NLG a fost creată pentru a rezolva o anumită provocare; cum să ajutați echipele de conținut să producă mai rapid conținut mai bun. Este o extensie naturală a briefelor noastre de conținut deja de succes bazate pe inteligență artificială.
În timp ce GPT-3 este spectaculos din punct de vedere al cercetării, mai este un drum lung de parcurs până să fie utilizabil.
Ce ar trebui să faci acum
Când sunteți gata... iată 3 moduri prin care vă putem ajuta să publicați conținut mai bun, mai rapid:
- Rezervați timp cu MarketMuse Programați o demonstrație live cu unul dintre strategii noștri pentru a vedea cum vă poate ajuta MarketMuse echipa să-și atingă obiectivele de conținut.
- Dacă doriți să aflați cum să creați mai rapid conținut mai bun, vizitați blogul nostru. Este plin de resurse pentru a ajuta la scalarea conținutului.
- Dacă cunoașteți un alt agent de marketing căruia i-ar face plăcere să citească această pagină, distribuiți-o prin e-mail, LinkedIn, Twitter sau Facebook.