
Identificarea atributelor subiective ale entităților
Publicat: 2022-05-13Identificarea atributelor subiective UGC ale entităților
Acest brevet recent acordat se referă la identificarea atributelor subiective ale entităților.
Nu am văzut un brevet despre atributele subiective ale entităților sau răspunsurile la acele entități.
Un aspect critic al acestuia este că este conținut generat de utilizatori.
Ni se spune că conținutul generat de utilizatori (UGC) devine din ce în ce mai comun pe web din cauza popularității tot mai mari a rețelelor sociale, blogurilor, site-urilor de recenzii etc.
Adesea vedem conținut generat de utilizatori sub formă de comentarii, cum ar fi:
- Un comentariu al unui prim utilizator despre conținutul partajat de un al doilea utilizator într-o rețea socială
- Utilizatorul comentează ca răspuns la un articol din blogul unui editorialist
- Un comentariu dintr-un videoclip postat pe un site web de găzduire de conținut
- Recenzii (cum ar fi produse, filme)
- Acțiuni (cum ar fi Îmi place!, Nu îmi place!, +1, distribuire, marcare, playlisting etc.)
- Si asa mai departe
Sub acest brevet, este oferită o modalitate de a identifica și prezice atribute subiective pentru entități (cum ar fi clipuri media, imagini, articole din ziare, articole de blog, persoane, organizații, afaceri comerciale etc.).
Începe cu:
- Identificarea unui prim set de atribute subiective pentru o primă entitate pe baza unei reacții la prima entitate (cum ar fi comentarii pe un site web, o demonstrație de aprobare a primei entități (cum ar fi „Like! etc.)
- Partajarea primei entitati
- Marcarea primei entitati
- Adăugarea primei entități la o listă de redare
- Antrenarea unui clasificator (cum ar fi o mașină de vector de suport, AdaBoost, o rețea neuronală, un arbore de decizie pe un set de mapări de intrare-ieșire, unde setul de mapări de intrare-ieșire cuprinde o mapare de intrare-ieșire a cărei intrare este Furnizarea unui vector caracteristic pentru prima entitate, a cărei rezultate se bazează pe primul set de atribute subiective
- Furnizarea unui vector de caracteristici pentru o a doua entitate către clasificatorul antrenat pentru a obține un al doilea set de atribute subiective pentru a doua entitate
O memorie și un procesor sunt furnizate pentru a identifica și prezice atribute subiective pentru entități.
Un mediu de stocare care poate fi citit de calculator are instrucțiuni care determină ca un sistem computer să efectueze operațiuni, inclusiv:
- Identificarea unui prim set de atribute subiective pentru o primă entitate pe baza unei reacții la prima entitate
- Obținerea unui prim vector caracteristic pentru prima entitate
- Antrenarea unui clasificator pe un set de mapări de intrare-ieșire, în care setul de mapări de intrare-ieșire cuprinde o mapare de intrare-ieșire a cărei intrare se bazează pe primul vector caracteristic și a cărei ieșire se bazează pe primul set de atribute subiective
- Obținerea unui al doilea vector caracteristic pentru o a doua entitate
- Furnizarea clasificatorului, după antrenament, a celui de-al doilea vector caracteristic pentru a obține un al doilea set de atribute subiective pentru a doua entitate
Acest brevet privind densificarea atributelor subiective pentru entități = se găsește la:
Identificarea atributelor subiective prin analiza semnalelor de curatare
Inventatori: Hrishikesh Aradhye și Sanketh Shetty
Cesionar: Google LLC
Brevet SUA: 11.328.218
Acordat: 10 mai 2022
Depus: 6 noiembrie 2017
Abstract:
Un sistem și o metodă pentru identificarea și prezicerea atributelor subiective pentru entități (cum ar fi clipuri media, filme, emisiuni de televiziune, imagini, articole din ziare, articole de blog, persoane, organizații, afaceri comerciale etc.) sunt dezvăluite.
Într-un aspect, atributele subiective pentru un prim articol media sunt identificate pe baza unei reacții la primul element media, iar scorurile de relevanță pentru calitățile personale cu aproximativ primul articol media sunt determinate.
Un clasificator este antrenat folosind (i) o intrare de antrenament care cuprinde un set de caracteristici pentru primul element media și o ieșire țintă pentru intrarea de antrenament, ieșirea țintă cuprinzând scorurile de relevanță respective pentru atributele subiective ale primului articol media.
Identificarea și predicția atributelor subiective pentru entități
Modalități de identificare și predicție a atributelor subiective pentru entități (cum ar fi clipuri media, imagini, articole din ziare, articole de blog, persoane, organizații, afaceri comerciale etc.).
Atributele subiective (cum ar fi „drăguț”, „amuzant”, „superb” etc.) sunt definite, iar atributele subiective pentru o anumită entitate sunt identificate pe baza reacției utilizatorului la entitate, cum ar fi:
- Comentarii pe un site web
- Ca!
- Partajarea primei entitati cu alți utilizatori
- Boomarking prima entitate
- Adăugarea primei entități la o listă de redare
- etc
Scorurile de relevanță pentru atributele subiective sunt determinate despre entitate
Dacă atributul subiectiv „drăguț” apare într-o proporție semnificativă de comentarii pentru un videoclip, atunci „drăguț” i se poate atribui un scor de relevanță ridicat.
Entitatea este apoi asociată cu atributele subiective identificate și scorurile de relevanță (cum ar fi prin etichete aplicate entității, prin intrări dintr-un tabel al unei baze de date relaționale etc.).
Procedura de mai sus este efectuată pentru fiecare entitate dintr-un anumit set de entități (cum ar fi clipuri video dintr-un depozit de clipuri video etc.), iar o mapare inversă de la atributele subiective la entitățile din grup este generată pe baza calităților personale și a scorurilor de relevanță. .
Maparea inversă poate fi folosită apoi pentru a identifica toate entitățile din mulțime care se potrivesc cu un anumit atribut subiectiv (cum ar fi toate entitățile care au fost asociate cu atributul subiectiv „amuzant”, etc.), permițând astfel:
- Preluare rapidă a entităților relevante pentru procesarea căutărilor de cuvinte cheie
- Se completează listele de redare
- Livrarea de reclame
- Generarea de seturi de antrenament pentru clasificator
- Si asa mai departe
Un clasificator (cum ar fi o mașină vectorială de suport [SVM], AdaBoost, o rețea neuronală, un arbore de decizie etc.) este antrenat prin furnizarea unui set de exemple de antrenament, în care intrarea pentru un exemplu de antrenament cuprinde un vector caracteristică obținut dintr-un o anumită entitate (cum ar fi un vector caracteristic pentru un clip video.
Poate conține valori numerice despre:
- Culoare
- Textură
- Intensitate
- Etichete de metadate asociate cu videoclipul
- etc
Rezultatul are scoruri de relevanță pentru fiecare atribut subiectiv din vocabularul pentru o entitate particulară.
Clasificatorul antrenat poate prezice apoi atribute subiective pentru entitățile care nu fac parte din setul de antrenament (cum ar fi un videoclip nou încărcat, un articol de știri care nu a primit încă comentarii etc.).
Acest brevet poate clasifica entitățile în funcție de atribute subiective, cum ar fi „amuzant”, „drăguț” etc., pe baza reacției utilizatorului la entități.
Acest brevet poate îmbunătăți calitatea descrierilor entităților, cum ar fi etichetele pentru un videoclip, îmbunătățind calitatea căutărilor și direcționarea reclamelor.
O arhitectură de sistem pentru a identifica atributele subiective
Arhitectura sistemului include:
- Mașină server
- Magazin de entitate
- Mașinile client sunt conectate la o rețea
Rețeaua poate fi publică (cum ar fi Internetul), o rețea privată (cum ar fi o rețea locală (LAN) sau o rețea vastă (WAN)) sau o combinație a acestora.
Mașinile client pot fi terminale fără fir (smartphone-uri etc.), computere personale (PC), laptopuri, tablete sau orice alte dispozitive de calcul sau de comunicare.
Mașinile client pot rula un sistem de operare (OS) care gestionează hardware-ul și software-ul mașinilor client.
Un browser (neprezentat) poate rula pe mașinile client (cum ar fi pe sistemul de operare al mașinilor client).
Browserul poate fi un browser web care poate accesa pagini web și conținut deservit de un server web.
Mașinile client pot încărca și:
- pagini web
- Clipuri media
- Intrări pe blog
- link-uri către articole
- Si asa mai departe
Mașina server include un server web și un manager de atribute subiective. Serverul web și managerul de atribute emoționale pot rula pe diferite dispozitive.
Magazinul de entități este stocare persistentă care este capabilă să stocheze entități precum clipuri media (cum ar fi clipuri video, clipuri audio, clipuri care conțin atât video, cât și audio, imagini etc.) și alte tipuri de elemente de conținut (cum ar fi pagini web, documente bazate pe restaurante, recenzii de restaurante, recenzii de filme etc.), precum și structuri de date pentru etichetarea, organizarea și indexarea entităților.
Magazinul de entitate poate fi găzduit de dispozitive de stocare, cum ar fi memoria principală, discuri bazate pe stocare magnetică sau optică, benzi sau hard disk, NAS, SAN etc.
Magazinul de entități poate fi găzduit de un server de fișiere atașat la rețea. În contrast, în alte implementări, depozitul de entități poate fi găzduit de un alt tip de stocare persistentă, cum ar fi cel al mașinii server sau mașini diferite cuplate la mașina server prin intermediul rețelei.
Entitățile stocate în magazinul de entități pot include conținut generat de utilizatori care este încărcat de computerele client și pot include conținut furnizat de furnizorii de servicii, cum ar fi:
- Organizații de știri
- Editorii
- Biblioteci
- Curând
Serverul poate servi pagini web și conținut din magazinele de entitate către clienți.
Managerul de atribute subiective:
- Identifică atributele subiective pentru entități pe baza reacției utilizatorului (cum ar fi comentarii, Like!, partajare, marcare, playlisting etc.)
- Determină scorurile de relevanță pentru atributele subiective despre entități
- Asociază atributele subiective și scorurile de relevanță cu entitățile
- Extrage caracteristici precum caracteristicile imaginii, cum ar fi culoarea, textura și intensitatea; caracteristici audio cum ar fi amplitudinea, rapoartele coeficientului spectral; caracteristici textuale cum ar fi frecvențele cuvintelor, lungimea medie a propoziției, parametrii de formatare; metadate asociate cu entitatea; etc.) de la entități pentru a genera vectori de caracteristici
- Antrenează un clasificator bazat pe vectorii caracteristici și scorurile de relevanță ale atributelor subiective
- Folosește clasificatorul antrenat pentru a prezice atribute subiective pentru entități noi pe baza vectorilor de caracteristici ai noilor entități
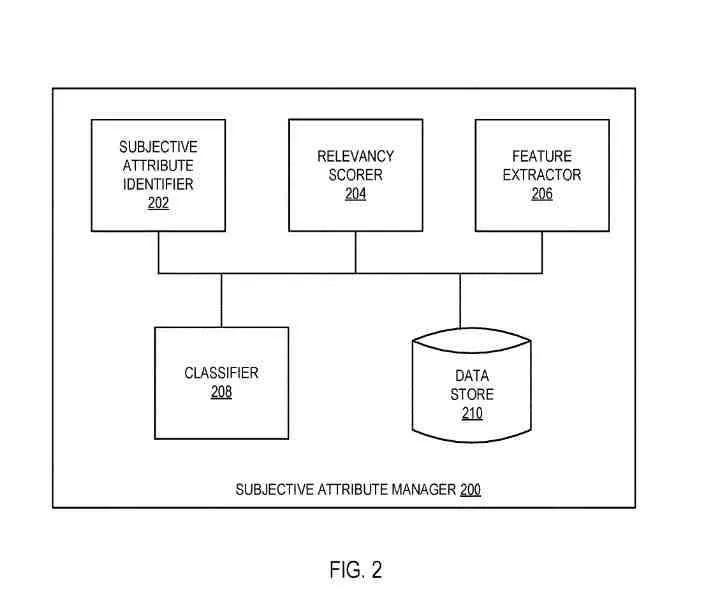
Un manager de atribute subiective
Managerul de atribute subiective poate fi același cu managerul de atribute subiective și poate include:
- Identificator de atribut subiectiv
- Marcator de relevanță
- Extractor de caracteristici
- Clasificator
- Magazin de date
.
Componentele pot fi combinate sau separate în detalii suplimentare.
Magazinul de date poate fi același cu depozitul de entități sau cu un alt depozit de date (cum ar fi un buffer temporar sau un depozit de date permanent) pentru a păstra un vocabular de atribute personale, entități care urmează să fie procesate, vectori de caracteristici asociați cu entități, atribute personale și scorurile de relevanță legate de entități sau o combinație a acestor date.
Depozitul de date poate fi găzduit de dispozitive de stocare, cum ar fi memoria principală, discuri bazate pe stocare magnetică sau optică, benzi sau hard disk-uri etc.
Managerul de atribute subiective informează utilizatorii despre tipurile de informații stocate în depozitul de date și în depozitul de entități și permite utilizatorilor să aleagă să nu fie colectate și partajate astfel de informații cu managerul de atribute subiective.
Identificatorul de atribut subiectiv
Identificatorul de atribut personal identifică atributele subiective pentru entități pe baza reacției utilizatorului la entități.
Identificatorul de atribut personal poate identifica atribute subiective prin procesarea textului comentariilor utilizatorilor către o entitate postată de un utilizator pe un site web de rețea socială.
Identificatorul de atribut subiectiv poate identifica atribute subiective pentru entități pe baza altor tipuri de reacții ale utilizatorilor la entități, cum ar fi:
- 'Ca!' sau „Nu-mi place!”
- Partajarea entității
- Marcarea entității
- Adăugarea entității la o listă de redare
- Si asa mai departe
Identificatorul de atribut personal poate aplica praguri pentru a determina ce atribute sunt asociate cu o entitate (cum ar fi un atribut subiectiv ar trebui să apară în cel puțin N comentarii etc.).
Scorul de relevanță determină scorurile de relevanță pentru atributele subiective despre entități.
De exemplu, atunci când identificatorul de atribut subiectiv a identificat atributele subiective „drăguț”, „amuzant” și „superb” pe baza comentariilor la un clip media postat pe un site web de rețea socială, scorul de relevanță poate determina scorurile de relevanță pentru fiecare dintre aceste trei subiecte. atribute bazate pe:
- Frecvența cu care apar aceste atribute subiective în comentarii
- Utilizatorii specifici care au furnizat atributele subiective
- Si asa mai departe
De exemplu, dacă există 40 de comentarii și „drăguț” apare în 20 de cuvinte și „superb” apare în 8 comentarii, atunci „drăguț” i se poate atribui un scor de relevanță mai mare decât „superb”.
Scorurile de relevanță pot fi atribuite pe baza proporției de comentarii în care apare un atribut subiectiv (cum ar fi un scor de 0,5 pentru „drăguț” și un scor de 0,2 pentru „superb” etc.).
Marcatorul de relevanță poate păstra doar k atribute subiective cele mai relevante și poate elimina alte atribute personale.
De exemplu, să presupunem că identificatorul de atribut personal identifică șapte atribute emoționale care apar în comentariile utilizatorilor de cel puțin trei ori. În acest caz, marcatorul de relevanță poate, de exemplu, să rețină doar cele cinci atribute subiective cu cele mai mari scoruri de relevanță și să renunțe la celelalte două atribute emoționale (cum ar fi stabilirea scorurilor de relevanță la zero etc.).
Un scor de relevanță este un număr natural între 0,0 și 1,0 inclusiv.
Extractorul de caracteristici obține un vector de caracteristici pentru o entitate folosind tehnici precum:
- Analiza componentelor principale
- Înglobări semidefinite
- Izomape
- Cele mai mici pătrate parțiale
- Si asa mai departe
Calculele asociate cu extragerea caracteristicilor unei entități sunt efectuate de extractorul de caracteristici însuși.

În alte aspecte, aceste calcule sunt efectuate de o altă entitate, cum ar fi o bibliotecă executabilă de:
- Rutine de procesare a imaginilor găzduite de mașina server [nu sunt prezentate în figuri]
- Rutine de procesare audio
- Rutine de procesare a textului
- etc
Rezultatele sunt furnizate extractorului de caracteristici.
Clasificatorul este o mașină de învățare (cum ar fi mașinile de suport vector [SVM], AdaBoost, rețele neuronale, arbori de decizie etc.) care acceptă ca intrare un vector caracteristic asociat cu o entitate și emite scoruri de relevanță (cum ar fi un număr real între 0). și 1 inclusiv etc.) pentru fiecare atribut subiectiv al vocabularului de atribut personal.
Clasificatorul constă dintr-un singur clasificator.
Clasificatorul poate include mai mulți clasificatori (cum ar fi un clasificator pentru fiecare atribut subiectiv din vocabularul atributelor personale etc.).
Un set de exemple pozitive și criterii negative sunt asamblate pentru fiecare atribut subiectiv din vocabularul atributelor personale.
Setul de exemple pozitive pentru un atribut subiectiv poate include vectori de caracteristici pentru entitățile asociate cu acel atribut personal particular.
Setul de exemple negative pentru un atribut subiectiv poate include vectori de caracteristici pentru entități care nu au fost asociate cu acel atribut personal anume.
Când setul de exemple pozitive și setul de criterii negative sunt inegale ca mărime, setul mai extins poate fi eșantionat pentru a se potrivi cu dimensiunea grupului mai mic.
După antrenament, clasificatorul poate prezice atribute subiective pentru alte entități care nu sunt în setul de antrenament, furnizând vectori de caracteristici pentru aceste entități ca intrare în clasificator.
Un set de atribute subiective poate fi obținut din rezultatul clasificatorului prin includerea tuturor atributelor emoționale cu scoruri de relevanță diferite de zero. Un grup de puncte subiective poate fi obținut prin aplicarea celui mai mic prag la scorurile numerice (prin luarea în considerare a tuturor atributelor personale care au un scor de cel puțin, să zicem, 0,2 ca fiind membre ale setului).
Identificarea atributelor subiective ale entităților
Metoda este realizată prin logica de procesare care poate cuprinde hardware (circuite, logică dedicată etc.), software (cum ar fi rulat pe un sistem informatic de uz general sau o mașină dedicată) sau ambele.
Metoda este realizată de mașina server, în timp ce alte implementări pot fi efectuate de un alt dispozitiv.
Diverse componente ale managerilor de atribute subiective pot rula pe mașini separate (cum ar fi identificatorul de atribut personal și scorul de relevanță pot rula pe un dispozitiv, în timp ce extractorul de caracteristici și clasificatorul rulează pe alt dispozitiv etc.).
Pentru simplitatea explicației, metoda este descrisă și descrisă ca o serie de acte.
Dar actele pot avea loc în diverse ordine și și cu alte acte care nu sunt prezentate și descrise aici.
În plus, nu toate actele ilustrate pot fi necesare pentru instalarea metodelor în funcție de subiectul dezvăluit.
în plus, specialiştii în domeniu vor înţelege şi aprecia că metoda poate fi reprezentată ca o serie de stări interconectate printr-o diagramă de stări sau evenimente.
în plus, ar trebui să fie apreciat că metodele dezvăluite în această specificaţie sunt capabile să fie stocate pe un articol de fabricaţie pentru a uşura transportul şi transferul unor astfel de metodologii către dispozitive de calcul.
Termenul articol de fabricație, așa cum este utilizat aici, este destinat să cuprindă un program de calculator accesibil de pe orice dispozitiv care poate fi citit de computer sau mediu de stocare.
Se generează un vocabular de atribute subiective.
În unele aspecte, vocabularul atributelor subiective poate fi definit. În schimb, în alți factori, vocabularul atributelor personale poate fi generat într-un mod automat prin colectarea de termeni și expresii care sunt folosite în reacțiile utilizatorilor la entități. În schimb, în alte aspecte, vocabularul poate fi generat de o combinație de tehnici manuale și automate.
Vocabularul este însămânțat cu un număr mic de atribute subiective care se așteaptă să se aplice entităților. Vocabularul se extinde în timp pe măsură ce mai mulți termeni sau expresii care apar în reacțiile utilizatorilor sunt identificați prin procesarea automată a răspunsurilor.
Vocabularul atributelor subiective poate fi organizat ierarhic, posibil pe baza „meta-atributelor” asociate cu atributele personale (cum ar fi atributul personal „amuzant” poate avea un meta-atribut „pozitiv”, în timp ce punctul subiectiv „dezgustător” poate avea un meta-atribut „negativ” etc.).
Un set S de entități (cum ar fi toate entitățile din depozitul de entități, un subset de entități din depozitul de entități etc.) este preprocesat.
Sub un aspect, preprocesarea entităților cuprinde identificarea reacțiilor utilizatorilor la entități și apoi formarea unui clasificator pe baza răspunsurilor.
Când o entitate este o entitate fizică reală
Trebuie remarcat faptul că, atunci când o entitate este o entitate fizică reală (cum ar fi o persoană, un restaurant etc.), preprocesarea entității este efectuată prin intermediul unui „proxy cibernetic” asociat cu entitatea fizică (cum ar fi un pagina de fani pentru un actor pe un site de rețea socială, o recenzie a unui restaurant pe un site web etc.); dar, atributele subiective sunt considerate a fi asociate cu entitatea în sine (cum ar fi actorul sau restaurantul, nu pagina de fani a actorului sau recenzia restaurantului).
Un exemplu de metodă de efectuare este descris în detaliu.
Este primită entitatea E care nu se află în setul S (cum ar fi un videoclip nou încărcat, un articol de știri care nu a primit încă niciun comentariu, o entitate din magazinul de entități care nu a fost inclusă în setul de instruire etc.).
Se obțin atributele subiectului și scorurile de relevanță pentru entitatea E.
O implementare a unui prim exemplu de metodă este descrisă în detaliu mai jos și este descrisă performanța unui al doilea exemplu de metodă.
Atributele subiective și scorurile de relevanță obținute sunt asociate cu entitatea E (cum ar fi prin aplicarea etichetelor corespunzătoare entității, adăugarea unei înregistrări într-un tabel al bazei de date relaționale etc.).
Execuția continuă înapoi.
Trebuie remarcat faptul că clasificatorul poate fi reantrenat (cum ar fi după fiecare 100 de iterații ale buclei, la fiecare N zile etc.) printr-un proces de re-antrenare care se poate executa concomitent.
Preprocesarea unui set de entități
Metoda este realizată prin logica de procesare care poate cuprinde hardware (circuite, logică dedicată etc.), software (cum ar fi rulat pe un sistem informatic de uz general sau o mașină dedicată) sau ambele.
Metoda este realizată, în timp ce în alte implementări pot fi efectuate de o altă mașină.
Setul de antrenament este inițializat la setul gol. O entitate E este selectată și eliminată din setul S de entități.
Atributele subiective pentru entitatea E sunt identificate pe baza reacțiilor utilizatorilor la entitatea E (cum ar fi comentariile utilizatorilor, Like!, marcaj, partajare, adăugare la o listă de redare etc.).
Identificarea atributelor subiective include efectuarea procesării comentariilor utilizatorilor, cum ar fi:
- Potrivirea cuvintelor din comentariile utilizatorilor cu atributele subiective din vocabular
- Combinând potrivirea cuvintelor și alte tehnici de procesare a limbajului natural, cum ar fi analiza sintactică și semantică
- etc
Entități care apar în apropierea locațiilor
Reacțiile utilizatorilor pot fi agregate pentru entitățile care apar în multe locații, cum ar fi:
- Entități care apar în listele de redare ale multor utilizatori
- Entități care au fost partajate și care apar într-o multitudine de „newsfeed-uri” ale utilizatorilor pe un site web de rețea socială
- etc
Diferitele locații pot fi ponderate în contribuția lor la scorurile de relevanță pe baza unei varietăți de factori, cum ar fi:
Utilizatorul anume asociat locației (cum ar fi un anumit utilizator poate fi o autoritate în domeniul muzicii clasice și, prin urmare, comentariile despre o entitate din fluxul lor de știri pot fi ponderate mai mult decât comentariile dintr-un alt flux de știri etc.), reacțiile utilizatorului non-textual (cum ar fi precum „Îmi place!”, „Nu-mi place!”, „+1”, etc.).
În plus, numărul de locații în care apare entitatea poate fi, de asemenea, utilizat pentru a determina atributele subiective și scorurile de relevanță (cum ar fi scorurile de relevanță pentru un clip video pot fi crescute atunci când videoclipul se află în sute de liste de redare ale utilizatorilor etc.).
Blocul este realizat prin identificatorul de atribut subiectiv.
Scorurile de relevanță pentru atributele subiective sunt determinate de entitatea E.
Un scor de relevanță este determinat pentru un anumit atribut subiectiv pe baza frecvenței cu care atributul personal apare în comentariile utilizatorilor, utilizatorii specifici care au furnizat detaliile subiective în cuvintele lor (cum ar fi unii utilizatori pot fi cunoscuți din experiență că sunt mai exacti în comentariile lor decât alți utilizatori etc.).
De exemplu, dacă există 40 de comentarii și „drăguț” apare în 20 de cuvinte și „superb” apare în 8 comentarii, atunci „drăguț” i se poate atribui un scor de relevanță mai mare decât „superb”.
Scorurile de relevanță pot fi atribuite pe baza proporției de comentarii în care apare un atribut subiectiv (cum ar fi un scor de 0,5 pentru „drăguț” și un scor de 0,2 pentru „superb” etc.).
Sub un aspect, scorurile de relevanță se normalizează pentru a scădea în intervale [0, 1].
Din unele aspecte, atributele subiective identificate pot fi eliminate pe baza scorurilor lor de relevanță (cum ar fi reținerea k atributelor emoționale cu cele mai mari scoruri de relevanță, eliminarea oricărui atribut personal al cărui scor de relevanță este sub un prag etc.).
Trebuie remarcat faptul că un atribut subiectiv poate fi eliminat prin stabilirea scorului său de relevanță la zero în unele aspecte.
Atributele subiective și scorurile de relevanță sunt asociate cu entitățile
Atributele subiective și scorurile de relevanță sunt asociate cu entitățile (cum ar fi prin etichetare, intrări într-un tabel dintr-o bază de date relațională etc.).
Se obține un vector caracteristic pentru entitatea E.
Într-un aspect, vectorul caracteristic pentru un clip video sau o imagine statică poate conține valori numerice despre culoare, textură, intensitate etc., în timp ce vectorul caracteristic pentru un clip audio (sau un clip video cu sunet) poate include valori numerice despre amplitudine. , coeficienți spectrale etc., în timp ce vectorul caracteristic pentru un document text poate include:
- Valori numerice despre frecvențele cuvintelor
- Lungimea medie a propoziției
- Parametrii de formatare
- Si asa mai departe
Acest lucru poate fi realizat de extractorul de caracteristici.
Vectorul de caracteristică și scorurile de relevanță obținute sunt adăugate la setul de antrenament.
Bock-ul verifică dacă setul S de entități este gol; dacă S este nevid, execuția continuă, în caz contrar execuția continuă.
Clasificatorul este antrenat pe toate exemplele setului de antrenament, astfel încât vectorul de caracteristică al unui exemplu de antrenament este furnizat ca intrare în clasificator, iar scorurile de relevanță ale atributului subiectiv sunt furnizate ca rezultat.
Obținerea atributelor subiective și a scorurilor de relevanță pentru o entitate
Este generat un vector caracteristic pentru entitatea E.
După cum este descris mai sus, vectorul caracteristic pentru un clip video sau o imagine statică poate conține valori numerice despre culoare, textură, intensitate etc.. În schimb, vectorul caracteristic pentru un clip audio (sau un clip video cu sunet) poate include valori numerice despre amplitudine, coeficienți spectrali etc.. În schimb, vectorul caracteristic pentru un document text poate include valori numerice despre frecvențele cuvintelor, lungimea medie a propoziției, parametrii de formatare și așa mai departe.
Clasificatorul antrenat oferă vectorul de caracteristici pentru a obține atribute subiective prezise și scoruri de relevanță pentru entitatea E.
Atributele subiective prezise și scorurile de relevanță sunt asociate cu entitatea E (cum ar fi prin etichete aplicate entității E, prin intrări dintr-un tabel al unei baze de date relaționale etc.).
O a doua metodă pentru obținerea atributelor subiective și a scorurilor de relevanță pentru o entitate
Metoda este realizată prin procesarea logicii care poate cuprinde hardware (circuite, logică dedicată etc.), software sau o combinație a ambelor.
Metoda este realizată de mașina server, în timp ce altele pot fi efectuate de un alt dispozitiv.
Este generat un vector caracteristic pentru entitatea E. Clasificatorul antrenat oferă vectorul de caracteristici pentru a obține atribute subiective prezise și scoruri de relevanță pentru entitatea E.
Atributele subiective prezise obținute sunt sugerate unui utilizator (cum ar fi utilizatorul care a încărcat entitatea. Un set rafinat de atribute personale este obținut de la utilizator, cum ar fi printr-o pagină web în care utilizatorul selectează dintre atributele sugerate și, eventual, adaugă noi atribute etc.).
Un scor de relevanță implicit pentru entități
Un scor de relevanță implicit este atribuit oricăror atribute subiective noi care au fost adăugate de utilizator.
Scorul de relevanță implicit poate fi de 1,0 pe o scară de la 0,0 la 1,0, scorul de relevanță implicit poate fi bazat pe utilizatorul anume (cum ar fi un scor de 1,0 atunci când utilizatorul este cunoscut din istoria trecută că este foarte bun în a sugera atribute, un scor de 0,8 atunci când utilizatorul este cunoscut că este oarecum bun la sugerarea atributelor etc.).
Ramurile Block se bazează pe dacă utilizatorul a eliminat oricare dintre atributele subiective sugerate (cum ar fi neselectarea atributului).
Entitatea E este stocată ca exemplu negativ al atributelor eliminate pentru reantrenarea viitoare a clasificatorului. Setul rafinat de atribute subiective și scorurile de relevanță corespunzătoare sunt asociate cu entitatea E (cum ar fi prin etichete aplicate entității E, prin intrări dintr-un tabel al unei baze de date relaționale etc.).