
Noindex Nofollow și Disallow: Căutați directive privind crawlerele
Publicat: 2022-12-01Există trei directive (comenzi) pe care le puteți folosi pentru a dicta modul în care motoarele de căutare descoperă, stochează și difuzează informații de pe site-ul dvs. ca rezultate de căutare:
- NoIndex: Nu adăugați pagina mea la rezultatele căutării.
- NoFollow: Nu vă uitați la linkurile de pe această pagină.
- Renunțați: nu vă uitați deloc la această pagină.
Aceste directive vă permit să controlați care dintre paginile site-ului dvs. pot fi accesate cu crawlere de motoarele de căutare și pot apărea în căutare.
Ce înseamnă Fără Index?
Directiva noindex le spune crawlerilor de căutare, cum ar fi googlebot, să nu includă o pagină web în rezultatele căutării.

Cum marcați o pagină fără index?
Există două moduri de a emite o directivă noindex :
- Adăugați o etichetă meta noindex la codul HTML al paginii
- Returnează un antet noindex în cererea HTTP
Folosind metaeticheta „fără index” pentru o pagină sau ca antet de răspuns HTTP, în esență ascundeți pagina de căutare.
Directiva noindex poate fi folosită și pentru a bloca doar anumite motoare de căutare. De exemplu, puteți bloca Google de la indexarea unei pagini, dar totuși permiteți Bing:
Exemplu: blocarea majorității motoarelor de căutare*
<meta name="roboți” content="noindex”>
Exemplu: blocarea numai Google
<meta name="googlebot” content="noindex”>
Vă rugăm să rețineți: din septembrie 2019, Google nu mai respectă directivele noindex din fișierul robots.txt . Acum Noindex TREBUIE să fie emis prin metaetichetă HTML sau antetul răspunsului HTTP. Pentru utilizatorii mai avansați, disallow încă funcționează deocamdată, deși nu pentru toate cazurile de utilizare.
Care este diferența dintre noindex și nofollow?
Este o diferență între stocarea conținutului și descoperirea conținutului:
noindex este aplicat la nivel de pagină și îi spune unui motor de căutare crawler să nu indexeze și să difuzeze o pagină în rezultatele căutării.
nofollow este aplicat la nivel de pagină sau link și îi spune unui motor de căutare crawler să nu urmărească (descoperă) legăturile.
În esență, eticheta noindex elimină o pagină din indexul de căutare, iar un atribut nofollow elimină un link din graficul de linkuri al motorului de căutare.
NoFollow ca atribut de pagină
Folosirea nofollow la nivel de pagină înseamnă că crawlerele nu vor urma niciunul dintre linkurile de pe pagina respectivă pentru a descoperi conținut suplimentar, iar crawlerele nu vor folosi linkurile ca semnale de clasare pentru site-urile țintă.
<meta name="roboți” conținut="nofollow”>
NoFollow ca atribut de legătură
Utilizarea nofollow la nivel de link împiedică crawlerele să exploreze linkul specific anunțului și împiedică utilizarea linkului ca semnal de clasare.
Directiva nofollow este aplicată la nivel de link folosind un atribut rel din eticheta a href:
<a href="https://domain.com” rel="nofollow”>
În special pentru Google, utilizarea atributului nofollow link va împiedica site-ul dvs. să treacă PageRank către adresele URL de destinație.
De ce ar trebui să marcați o pagină ca NoFollow?
Pentru majoritatea cazurilor de utilizare, nu ar trebui să marcați o pagină întreagă ca nofollow – marcarea linkurilor individuale ca nofollow va fi suficientă.
Ați marca o pagină întreagă ca nofollow dacă nu doriți ca Google să vadă linkurile de pe pagină sau dacă credeți că linkurile de pe pagină vă pot afecta site-ul.
În cele mai multe cazuri, directivele generale nofollow la nivel de pagină sunt utilizate atunci când nu aveți control asupra conținutului postat pe o pagină Unii editori de ultimă generație au aplicat, de asemenea, directiva nofollow paginilor lor pentru a-și descuraja scriitorii să plaseze linkuri sponsorizate în conținutul lor.
Cum folosesc paginile NoIndex?
Marcați paginile ca noindex care este puțin probabil să ofere valoare utilizatorilor și nu ar trebui să apară ca rezultate ale căutării. De exemplu, este puțin probabil ca paginile care există pentru paginare să aibă același conținut afișat în timp.
Este puțin probabil ca Domain.com/category/resultspage=2 să arate unui utilizator rezultate mai bune decât domain.com/category/resultspage=1 și cele două pagini ar concura doar una cu cealaltă în căutare. Cel mai bine este să nu indexați paginile al căror singur scop este paginarea.
Iată tipurile de pagini pe care ar trebui să nu le indexați:
- Pagini folosite pentru paginare
- Pagini de căutare interne
- Pagini de destinație optimizate pentru anunțuri
- Ex: Afișează doar un formular de prezentare și înscriere, fără navigare principală
- De exemplu: variații duplicate ale aceluiași conținut, utilizate numai pentru anunțuri
- Pagini de autor arhivate
- Paginile din fluxurile de plată
- Pagini de confirmare
- Ex: Mulțumesc pagini
- Ex: Comanda pagini complete
- Ex: Succes! Pagini
- Unele pagini generate de plugin care nu sunt relevante pentru site-ul dvs. (ex: dacă utilizați un plugin de comerț, dar nu folosiți paginile lor obișnuite de produse)
- Pagini de administrare și pagini de autentificare admin
Marcarea unei pagini Noindex și Nofollow
O pagină marcată atât cu noindex, cât și cu nofollow va bloca un crawler să indexeze pagina respectivă și va bloca un crawler să exploreze legăturile de pe pagină.
În esență, imaginea de mai jos demonstrează ce va vedea un motor de căutare pe o pagină web, în funcție de modul în care ați folosit directivele noindex și nofollow:

Marcarea unei pagini deja indexate ca NoIndex
Dacă un motor de căutare a indexat deja o pagină și o marcați ca noindex , atunci data viitoare când pagina este accesată cu crawlere, aceasta va fi eliminată din rezultatele căutării Pentru ca această metodă de eliminare a unei pagini din index să funcționeze, nu trebuie să blocați (dezactivați) crawler-ul cu fișierul robots.txt.
Dacă îi spuneți unui crawler să nu citească pagina, acesta nu va vedea niciodată marcatorul noindex și pagina va rămâne indexată, deși conținutul ei nu va fi reîmprospătat.
Cum opresc motoarele de căutare să-mi indexeze site-ul?
Dacă doriți să eliminați o pagină din indexul de căutare, după ce aceasta a fost deja indexată, puteți parcurge următorii pași:
- Aplicați directiva noindex Adăugați atributul noindex la metaeticheta sau la antetul răspunsului HTTP
- Solicitați motorului de căutare să acceseze cu crawlere pagina Pentru Google puteți face acest lucru în consola de căutare, solicitați ca Google să reindexeze pagina. Acest lucru va declanșa Googlebot să acceseze cu crawlere pagina, unde Googlebot va descoperi directiva noindex. Va trebui să faceți acest lucru pentru fiecare motor de căutare pe care doriți să îl eliminați.
- Confirmați că pagina a fost eliminată din căutare După ce ați solicitat crawler-ului să vă revadă pagina web, acordați-i ceva timp, apoi confirmați că pagina dvs. a fost eliminată din rezultatele căutării. Puteți face acest lucru accesând orice motor de căutare și introducând URL-ul țintă de două puncte ale site-ului, ca în imaginea de mai jos.
Dacă căutarea dvs. nu returnează niciun rezultat, atunci pagina dvs. a fost eliminată din acel index de căutare. - Dacă pagina nu a fost eliminată Verificați dacă nu aveți o directivă „disallow” în fișierul robots.txt. Google și alte motoare de căutare nu pot citi directiva noindex dacă nu au voie să acceseze cu crawlere pagina. Dacă o faceți, eliminați directiva disallow pentru pagina țintă și apoi solicitați din nou accesarea cu crawlere.
- Setați o directivă Disallow pentru pagina țintă în fișierul robots.txt Disallow: /page$
Va trebui să puneți semnul dolar la sfârșitul adresei URL din fișierul robots.txt sau puteți interzice accidental orice pagină de sub pagina respectivă, precum și orice pagină care încep cu același șir. Ex: Disallow: /sweater va interzice și /sweater-weather și /sweater/green, dar Disallow: /sweater$ va interzice doar pagina exactă /pulover.
Cum pentru a elimina o pagină din Căutarea Google
Dacă pagina pe care doriți să o eliminați din căutare se află pe un site pe care îl dețineți sau îl gestionați, majoritatea site-urilor pot folosi Instrumentul pentru eliminarea adreselor URL pentru webmasteri.
Instrumentul de eliminare a adreselor URL pentru webmasteri elimină conținutul din căutare doar timp de aproximativ 90 de zile; dacă doriți o soluție mai permanentă, va trebui să utilizați o directivă noindex, să interziceți accesarea cu crawlere din robots.txt sau să eliminați pagina de pe site. Google oferă instrucțiuni suplimentare pentru eliminarea definitivă a adreselor URL aici.

Dacă încercați să eliminați o pagină din căutare pentru un site pe care nu îl dețineți, puteți solicita Google să elimine pagina din căutare dacă îndeplinește următoarele criterii:
- Afișează informații personale, cum ar fi cardul dvs. de credit sau numărul de securitate socială
- Pagina face parte dintr-o schemă de malware sau phishing
- Pagina încalcă legea
- Pagina încalcă drepturile de autor
Dacă pagina nu îndeplinește unul dintre criteriile de mai sus, puteți contacta o firmă de SEO sau o companie de PR pentru ajutor cu gestionarea reputației online.
Ar trebui să nu indexați paginile categoriei?
De obicei, nu este recomandat să nu indexați paginile de categorii, cu excepția cazului în care sunteți o organizație la nivel de întreprindere care învârte pagini de categorii în mod programatic, pe baza căutărilor sau etichetelor generate de utilizatori, iar conținutul duplicat devine greu de utilizat.
În cea mai mare parte, dacă vă etichetați conținutul în mod inteligent, într-un mod care îi ajută pe utilizatori să navigheze mai bine pe site-ul dvs. și să găsească ceea ce au nevoie, atunci veți fi bine.
De fapt, paginile de categorii pot fi mine de aur pentru SEO, deoarece de obicei arată o profunzime de conținut sub subiectele categoriei.
Aruncă o privire la această analiză pe care am făcut-o în decembrie 2018 pentru a cuantifica valoarea paginilor de categorii pentru o mână de publicații online.
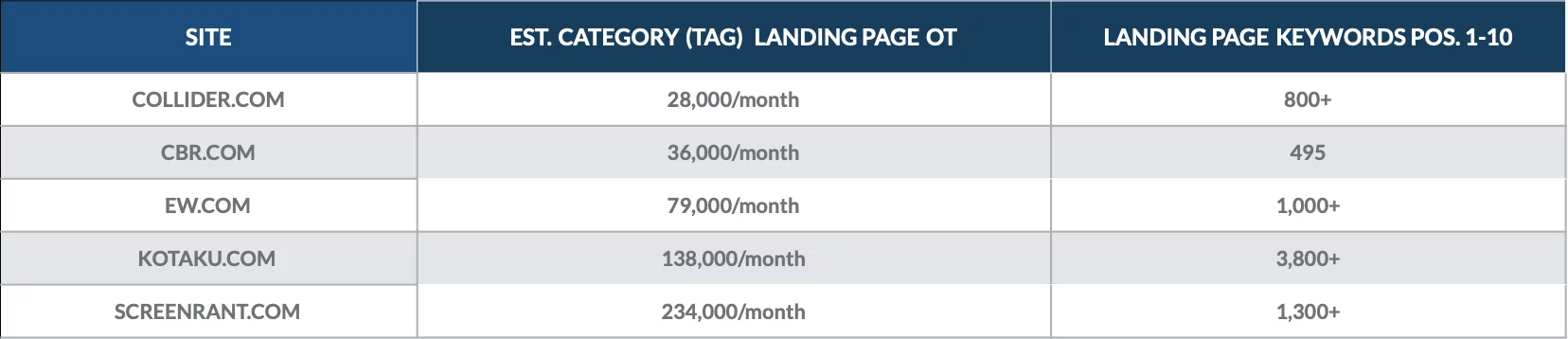
Am descoperit că paginile de destinație ale categoriei au fost clasate pentru sute de cuvinte cheie de pe pagina 1 și au adus mii de vizitatori organici în fiecare lună.
Cele mai valoroase pagini de categorii pentru fiecare site au adus adesea mii de vizitatori organici fiecare.
Aruncă o privire pe EW.com de mai jos, am măsurat traficul către fiecare pagină (reprezentat de dimensiunea cercului) și valoarea traficului către fiecare pagină (reprezentată de culoarea cercului).
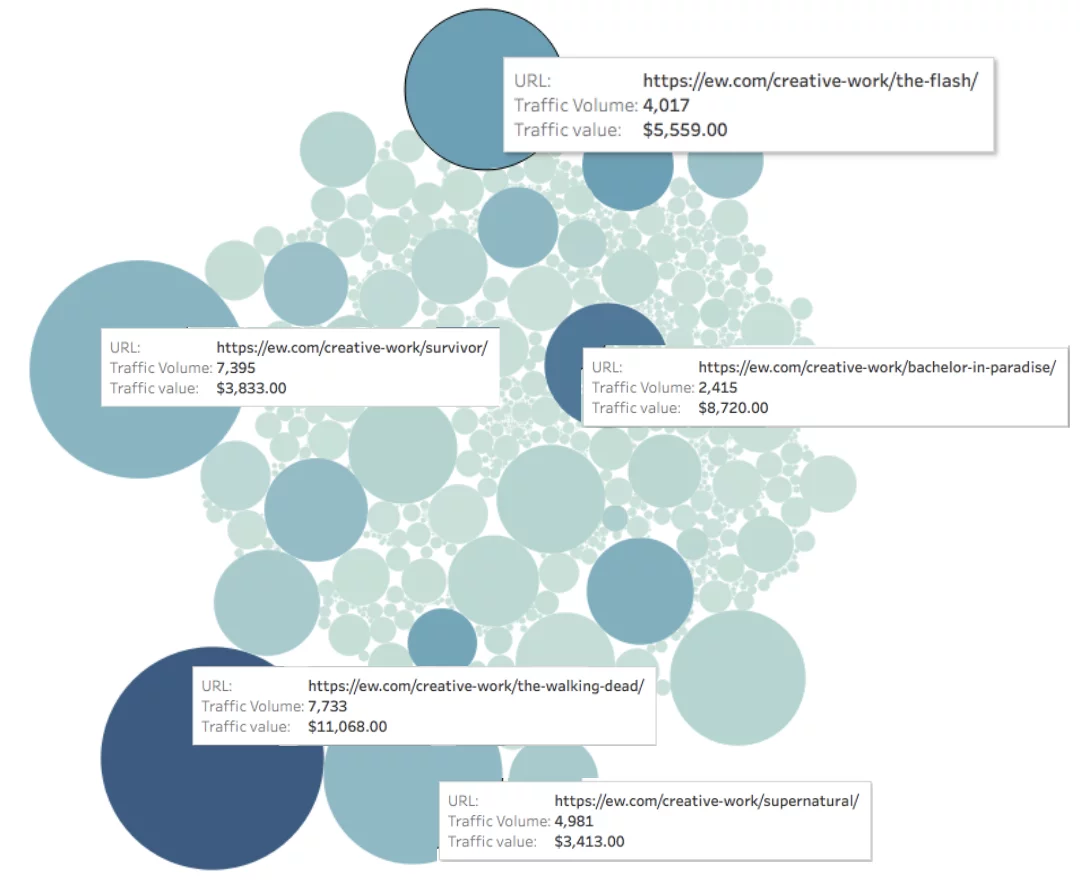
Valoarea organică lunară a paginii = Profunzimea culorii
Acum imaginați-vă aceleași diagrame, dar pentru site-uri bazate pe produse, unde vizitatorii sunt probabil să facă achiziții active.
Acestea fiind spuse, dacă categoriile dvs. sunt suficient de asemănătoare pentru a provoca confuzie utilizatorilor sau pentru a concura între ele în căutare, atunci poate fi necesar să faceți o modificare:
- Dacă setați singur categoriile, atunci vă recomandăm să migrați conținutul de la o categorie la alta și să reduceți numărul total de categorii pe care le aveți în general.
- Dacă permiteți utilizatorilor să creeze categorii, atunci este posibil să doriți să nu indexați paginile categoriilor generate de utilizator, cel puțin până când noile categorii au fost supuse unui proces de revizuire.
Cum opresc Google să indexeze subdomenii?
Există câteva opțiuni pentru a opri Google de la indexarea subdomeniilor:
- Puteți adăuga o parolă folosind un fișier .htpasswd
- Puteți interzice crawlerele cu un fișier robots.txt
- Puteți adăuga o directivă noindex la fiecare pagină din subdomeniu
- Puteți 404 toate paginile subdomeniului
Adăugarea unei parole pentru a bloca indexarea
Dacă subdomeniile dvs. sunt în scopuri de dezvoltare, atunci adăugarea unui fișier .htpasswd la directorul rădăcină al subdomeniului este opțiunea perfectă. Peretele de conectare va împiedica crawlerele pentru indexarea conținutului de pe subdomeniu și va împiedica accesul utilizatorilor neautorizați.
Exemple de cazuri de utilizare:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
Utilizarea robots.txt pentru a bloca indexarea
Dacă subdomeniile dvs. servesc altor scopuri, atunci puteți adăuga un fișier robots.txt în directorul rădăcină al subdomeniului dvs. Apoi ar trebui să fie accesibil după cum urmează:
https://subdomain.domain.com/robots.txt
Va trebui să adăugați un fișier robots.txt la fiecare subdomeniu pe care încercați să îl blocați de la căutare. Exemplu:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
În fiecare caz, fișierul robots.txt ar trebui să nu permită crawlerele, pentru a bloca majoritatea crawlerelor cu o singură comandă, utilizați următorul cod:
Agent utilizator: *
Nu permite: /
Steaua * după user-agent: se numește wildcard, se va potrivi cu orice secvență de caractere. Utilizarea unui wildcard va trimite următoarea directivă de respingere tuturor agenților utilizatori, indiferent de numele lor, de la googlebot la yandex.
Bara oblică inversă îi spune crawler-ului că toate paginile din subdomeniu sunt incluse în directiva disallow.
Cum să blocați selectiv indexarea paginilor subdomeniului
Dacă doriți ca unele pagini dintr-un subdomeniu să apară în căutare, dar nu altele, aveți două opțiuni:
- Utilizați directive noindex la nivel de pagină
- Utilizați directive de interdicție la nivel de folder sau director
Directivele noindex la nivel de pagină vor fi mai greoaie de implementat, deoarece directiva trebuie adăugată la HTML-ul sau la antetul fiecărei pagini. Cu toate acestea, directivele noindex vor împiedica Google să indexeze un subdomeniu, indiferent dacă subdomeniul a fost deja indexat sau nu.
Directivele de respingere la nivel de director sunt mai ușor de implementat, dar vor funcționa numai dacă paginile subdomeniului nu sunt deja în indexul de căutare. Pur și simplu actualizați fișierul robots.txt al subdomeniului pentru a nu permite accesarea cu crawlere a directoarelor sau subdosarelor aplicabile.
Cum știu dacă paginile mele nu sunt indexate?
Adăugarea accidentală a paginilor cu directive fără index pe site-ul dvs. poate avea consecințe drastice pentru clasarea căutării și vizibilitatea căutării.
Dacă descoperiți că o pagină nu vede trafic organic în ciuda conținutului bun și a backlink-urilor, verificați mai întâi dacă nu ați interzis accidental crawlerele din fișierul dvs. robots.txt. Dacă asta nu vă rezolvă problema, va trebui să verificați paginile individuale pentru directivele noindex.
Verificarea NoIndex pe paginile WordPress
WordPress facilitează adăugarea sau eliminarea acestei etichete în paginile dvs. Primul pas în verificarea nofollow-ului în paginile dvs. este pur și simplu comutarea setarii Vizibilitate motorului de căutare din fila „Citire” din meniul „Setări”.
Acest lucru va rezolva probabil problema, cu toate acestea, această setare funcționează mai degrabă ca o „sugestie” decât o regulă, iar o parte din conținutul dvs. poate ajunge oricum să fie indexat.
Pentru a asigura confidențialitatea absolută pentru fișierele și conținutul dvs., va trebui să faceți un ultim pas, fie protejarea prin parolă a site-ului dvs. folosind instrumente de management cPanel, dacă sunt disponibile, fie printr-un simplu plugin.
De asemenea, eliminarea acestei etichete din conținutul dvs. se poate face prin eliminarea protecției prin parolă și debifând setarea de vizibilitate.
Se verifică NoIndex pe Squarespace
Paginile Squarespace sunt, de asemenea, ușor NoIndexate folosind capacitatea de injectare de cod a platformei. La fel ca WordPress, Squarespace poate fi blocat cu ușurință de la căutările de rutină folosind protecția prin parolă, cu toate acestea, platforma sfătuiește să nu faceți acest pas pentru a vă proteja integritatea conținutului.
Adăugând linia de cod NoIndex în fiecare pagină pe care doriți să o ascundeți de motoarele de căutare de pe internet și la fiecare subpagină de sub aceasta, puteți asigura siguranța conținutului securizat care ar trebui să fie interzis accesului public. Ca și alte platforme, eliminarea acestei etichete este, de asemenea, destul de simplă: pur și simplu folosirea funcției de injectare de cod pentru a scoate codul înapoi este tot ce trebuie să faceți.
Squarespace este unic prin faptul că concurenții săi oferă această opțiune în primul rând ca parte a suitei de setări din instrumentele de gestionare a paginilor. Squarespace pleacă de aici, permițând manipularea personală a codului. Acest lucru este interesant deoarece puteți vedea modificarea pe care o faceți conținutului paginii dvs., spre deosebire de celelalte din acest spațiu.
Se verifică NoIndex pe Wix
Wix permite, de asemenea, o remediere simplă și rapidă pentru problemele de NoIndexing. În setările „Meniuri și pagini”, puteți pur și simplu să dezactivați opțiunea „afișați această pagină în rezultatele căutării” dacă doriți să nu indexați o singură pagină din site-ul dvs.
Ca și în cazul concurenților săi, Wix sugerează, de asemenea, protejarea prin parolă a paginilor sau a întregului site pentru un plus de confidențialitate. Cu toate acestea, Wix se îndepărtează de celelalte prin faptul că echipa de asistență nu prescrie acțiuni paralele pe ambele fronturi pentru a securiza conținutul din crawler. Wix face o notă specială despre diferența dintre ascunderea unei pagini din meniul dvs. și ascunderea acesteia de criteriile de căutare.
Acesta este un sfat deosebit de util pentru constructorii de site-uri web cu mai puțină experiență, care ar putea să nu înțeleagă inițial diferența, având în vedere că eliminarea din meniul site-ului dvs. face ca pagina să nu fie accesată de pe site, dar nu dintr-un termen prudent de căutare Google.