
Ce este bugetul de accesare cu crawlere și cum să-l optimizezi în mod inteligent?
Publicat: 2021-08-19Cuprins
Analiza bugetului cu crawl se numără printre sarcinile oricărui expert SEO (mai ales dacă are de-a face cu site-uri web mari). O sarcină importantă, acoperită decent în materialele oferite de Google. Cu toate acestea, după cum puteți vedea pe Twitter, chiar și angajații Google minimiză rolul bugetului de accesare cu crawlere în obținerea de trafic și clasamente mai bune:

Au dreptate în privința asta?
Cum funcționează Google și cum colectează date?
Pe măsură ce abordăm subiectul, să ne amintim modul în care motorul de căutare colectează, indexează și organizează informații. Păstrarea acestor trei pași în colțul minții este esențială în timpul lucrării tale ulterioare pe site:
Pasul 1: Crawling . Cercetarea resurselor online cu scopul de a descoperi – și de a naviga prin – toate linkurile, fișierele și datele existente. În general, Google începe cu cele mai populare locuri de pe Web, apoi continuă să scaneze alte resurse, mai puțin populare.
Pasul 2: Indexarea . Google încearcă să stabilească despre ce este pagina și dacă conținutul/documentul analizat constituie material unic sau duplicat. În această etapă, Google grupează conținutul și stabilește o ordine de importanță (prin citirea sugestiilor în etichetele rel=”canonic” sau rel=”alternate” sau altfel).
Pasul 3: Servire . Odată segmentate și indexate, datele sunt afișate ca răspuns la interogările utilizatorilor. Acesta este și momentul în care Google sortează datele după caz, luând în considerare factori precum locația utilizatorului.
Important: multe dintre materialele disponibile trec cu vederea Pasul 4: redarea conținutului . În mod implicit, Googlebot indexează conținutul text. Cu toate acestea, pe măsură ce tehnologiile web continuă să evolueze, Google a trebuit să elaboreze noi soluții pentru a nu mai „citi” și pentru a începe, de asemenea, să „vadă”. Despre asta este redarea. Acesta servește Google pentru a-și îmbunătăți în mod substanțial acoperirea printre site-urile web recent lansate și pentru a extinde indexul.
Notă : problemele cu redarea conținutului pot fi cauza unui buget de accesare cu crawlere eșuat.
Care este bugetul crawl?
Bugetul de accesare cu crawlere nu este altceva decât frecvența cu care crawlerele și roboții motoarelor de căutare vă pot indexa site-ul web, precum și numărul total de adrese URL pe care le pot accesa într-o singură accesare cu crawlere. Imaginează-ți bugetul de accesare cu crawlere ca credite pe care le poți cheltui într-un serviciu sau într-o aplicație. Dacă nu vă amintiți să vă „încărcați” bugetul de accesare cu crawlere, robotul va încetini și vă va plăti mai puține vizite.
În SEO, „încărcare” se referă la munca depusă în obținerea de backlink-uri sau îmbunătățirea popularității generale a unui site web. În consecință, bugetul de crawl este o parte integrantă a întregului ecosistem Web. Când faceți o treabă bună cu conținutul și backlink-urile, creșteți limita bugetului disponibil pentru accesare cu crawlere.
În resursele sale, Google nu se aventurează să definească în mod explicit bugetul de accesare cu crawlere. În schimb, indică două componente fundamentale ale accesării cu crawlere care afectează exhaustivitatea Googlebot și frecvența vizitelor acestuia:
- limita ratei de crawl;
- cererea de crawl.
Care este limita ratei de accesare cu crawlere și cum se verifică?
În cei mai simpli termeni, limita ratei de accesare cu crawlere este numărul de conexiuni simultane pe care Googlebot le poate stabili atunci când vă accesează cu crawlere site-ul. Deoarece Google nu dorește să afecteze experiența utilizatorului, limitează numărul de conexiuni pentru a menține o performanță bună a site-ului/serverului dvs. Pe scurt, cu cât site-ul dvs. este mai lent, cu atât limita ratei de accesare cu crawlere este mai mică.
Important: limita de accesare cu crawlere depinde și de sănătatea generală SEO a site-ului dvs. - dacă site-ul dvs. declanșează multe redirecționări, erori 404/410 sau dacă serverul returnează adesea un cod de stare 500, numărul de conexiuni va scădea și el.
Puteți analiza datele privind limita ratei de accesare cu crawlere cu informațiile disponibile în Google Search Console, în raportul Statistici de accesare cu crawlere .
Cererea de accesare cu crawlere sau popularitatea site-ului web
În timp ce limita ratei de accesare cu crawlere necesită să lustruiți detaliile tehnice ale site-ului dvs., cererea de accesare cu crawlere vă recompensează pentru popularitatea site-ului dvs. În linii mari, cu cât este mai mare zgomotul în jurul site-ului dvs. (și pe acesta), cu atât este mai mare cererea de accesare cu crawlere.
În acest caz, Google analizează două probleme:
- Popularitate generală – Google este mai dornic să ruleze cu crawlere frecvente adresele URL care sunt în general populare pe Internet (nu neapărat cele cu backlink-uri de la cel mai mare număr de adrese URL).
- Actualitatea datelor indexate – Google se străduiește să prezinte doar cele mai recente informații. Important: crearea din ce în ce mai mult conținut nou nu înseamnă că limita bugetului general pentru accesare cu crawlere crește.
Factori care afectează bugetul crawl
În secțiunea anterioară, am definit bugetul de accesare cu crawlere ca o combinație între limita ratei de accesare cu crawlere și cererea de accesare cu crawlere. Rețineți că trebuie să aveți grijă de ambele, simultan, pentru a asigura accesarea cu crawlere (și, prin urmare, indexarea) corespunzătoare a site-ului dvs.
Mai jos veți găsi o listă simplă de puncte de luat în considerare în timpul optimizării bugetului de accesare cu crawlere
- Server – principala problemă este performanța. Cu cât viteza este mai mică, cu atât este mai mare riscul ca Google să aloce mai puține resurse pentru indexarea noului conținut.
- Codurile de răspuns ale serverului – cu cât numărul de redirecționări 301 și erori 404/410 de pe site-ul dvs. web este mai mare, cu atât veți obține rezultate de indexare mai proaste. Important: fiți atenți la buclele de redirecționare – fiecare „hop” reduce limita ratei de accesare cu crawlere a site-ului dvs. pentru următoarea vizită a botului.
- Blocuri în robots.txt – dacă vă bazați directivele robots.txt pe sentimente, este posibil să ajungeți să creați blocaje de indexare. Rezultatul: veți curăța indexul, dar în detrimentul eficienței dvs. de indexare pentru pagini noi (când URL-urile blocate erau ferm încorporate în structura întregului site web).
- Navigare fațetă / identificatori de sesiune / orice parametri din URL -uri – cel mai important, aveți grijă la situațiile în care o adresă cu un parametru poate fi parametrizată în continuare, fără restricții. Dacă acest lucru s-ar întâmpla, Google va ajunge la un număr infinit de adrese, cheltuind toate resursele disponibile pe părțile mai puțin semnificative ale site-ului nostru.
- Conținut duplicat – conținutul copiat (în afară de canibalizare) afectează semnificativ eficiența indexării noului conținut.
- Conținut subțire – care apare atunci când o pagină are un raport text/HTML foarte scăzut. Drept urmare, Google poate identifica pagina ca așa-numit Soft 404 și poate restricționa indexarea conținutului acesteia (chiar și atunci când conținutul este semnificativ, ceea ce poate fi cazul, de exemplu, pe pagina unui producător care prezintă un singur produs și nu este unic). conținutul textului).
- Legătura internă slabă sau lipsa acesteia .
Instrumente utile pentru analiza bugetului cu crawlere
Deoarece nu există un punct de referință pentru bugetul de accesare cu crawlere (ceea ce înseamnă că este greu să comparați limitele între site-uri web), pregătiți-vă cu un set de instrumente concepute pentru a facilita colectarea și analiza datelor.
Google Search Console
GSC a crescut frumos de-a lungul anilor. În timpul unei analize a bugetului de accesare cu crawlere, există două rapoarte principale pe care ar trebui să le analizăm: Acoperirea indexului și Statisticile de accesare cu crawlere.
Acoperirea indicelui în GSC
Raportul este o sursă masivă de date. Să verificăm informațiile despre adresele URL excluse din indexare. Este o modalitate excelentă de a înțelege amploarea problemei cu care te confrunți.
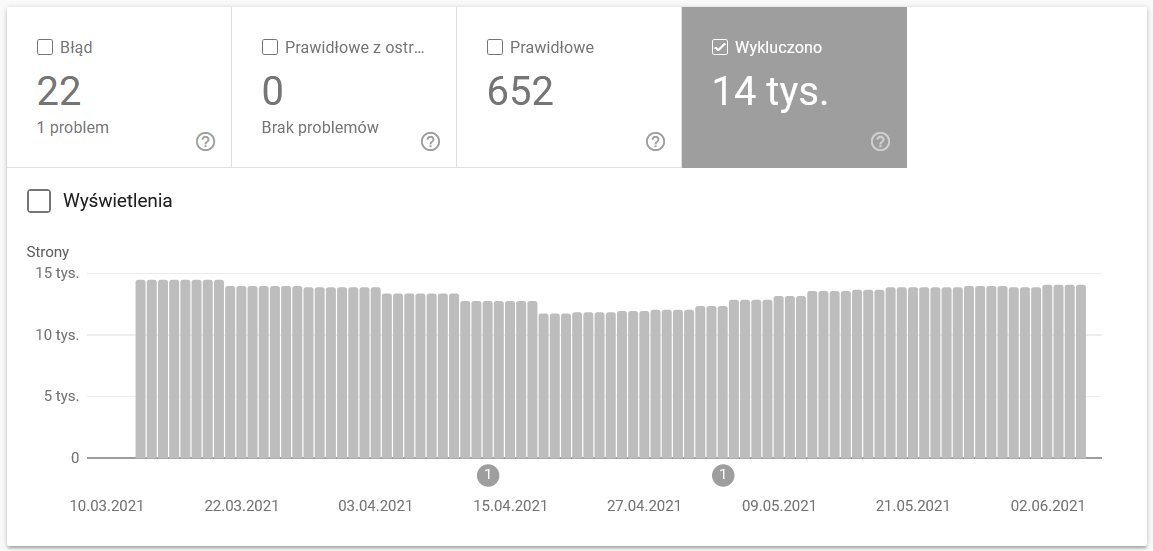
Întregul rapoarte necesită un articol separat, așa că, deocamdată, să ne concentrăm pe următoarele informații:
- Exclus prin eticheta „noindex” – În general, mai multe pagini noindex înseamnă mai puțin trafic. Ceea ce ridică întrebarea – ce rost are să le păstrăm pe site? Cum se restricționează accesul la aceste pagini?
- Accesat cu crawlere – momentan neindexat – dacă vedeți asta, verificați dacă conținutul este redat corect în ochii Googlebot. Rețineți că fiecare adresă URL cu această stare irosește bugetul de accesare cu crawlere, deoarece nu generează trafic organic.
- A fost descoperită – în prezent neindexată – una dintre cele mai alarmante probleme care merită puse în fruntea listei de priorități.
- Duplicați fără canonice selectate de utilizator – toate paginile duplicate sunt extrem de periculoase, deoarece nu numai că vă afectează bugetul de accesare cu crawlere, dar cresc și riscul de canibalizare.
- Duplicat, Google a ales diferit canonic decât utilizator - teoretic, nu este nevoie să vă faceți griji. La urma urmei, Google ar trebui să fie suficient de inteligent pentru a lua o decizie corectă în locul nostru. Ei bine, în realitate, Google își selectează elementele canonice destul de aleatoriu - deseori tăind paginile valoroase cu un punct canonic către pagina de pornire.
- Soft 404 – toate erorile „soft” sunt extrem de periculoase, deoarece pot duce la eliminarea paginilor critice din index.
- Adresa URL trimisă duplicat, neselectată ca canonică – similar cu raportarea de stare privind lipsa de canonice selectate de utilizator.
Statistici de accesare cu crawlere
Raportul nu este perfect și, în ceea ce privește recomandările, vă sugerez insistent să vă jucați și cu vechile jurnalele de server bune, care oferă o perspectivă mai profundă asupra datelor (și mai multe opțiuni de modelare).
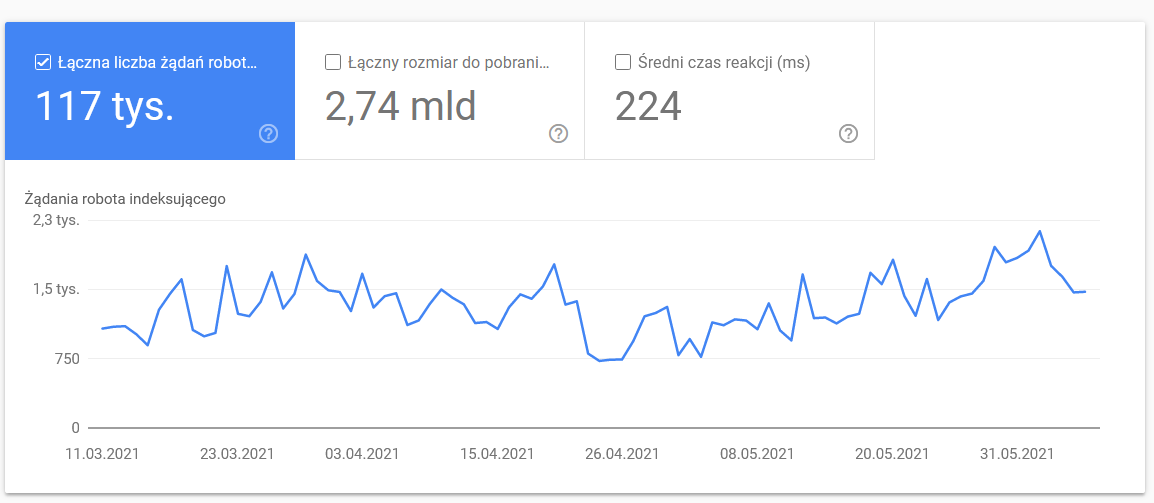
După cum am spus deja, veți avea dificultăți să căutați puncte de referință pentru cifrele de mai sus. Cu toate acestea, este un apel bun să aruncați o privire mai atentă la:
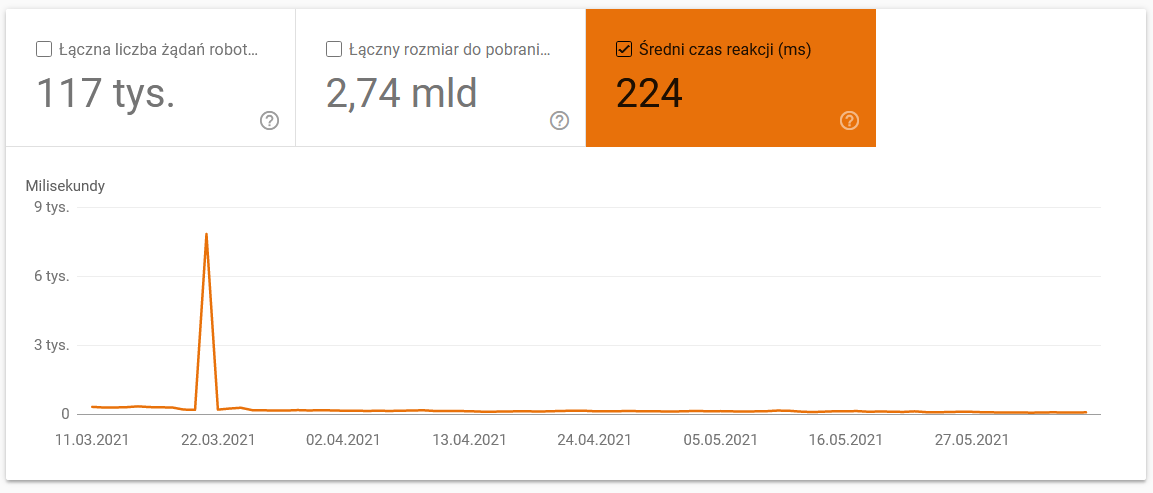
- Timp mediu de descărcare. Captura de ecran de mai jos arată că timpul mediu de răspuns a avut un impact dramatic, care s-a datorat unor probleme legate de server:
- Răspunsuri cu crawlere. Priviți raportul pentru a vedea, în general, dacă aveți sau nu o problemă cu site-ul dvs. web. Acordați o atenție deosebită codurilor de stare de server atipice, cum ar fi 304s de mai jos. Aceste adrese URL nu au niciun scop funcțional, dar Google își irosește resursele accesând cu crawlere conținutul lor.

- Scopul târârii. În general, aceste date depind în mare măsură de volumul de conținut nou de pe site. Diferențele dintre informațiile culese de Google și utilizator pot fi destul de fascinante:
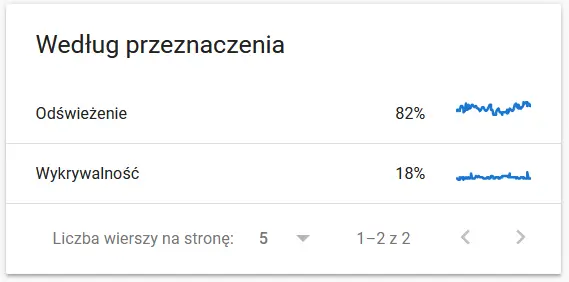
Conținutul unei adrese URL accesate din nou cu crawlere în ochii Google:
Între timp, iată ce vede utilizatorul în browser:
Cu siguranta un motiv de gandire si analiza :)
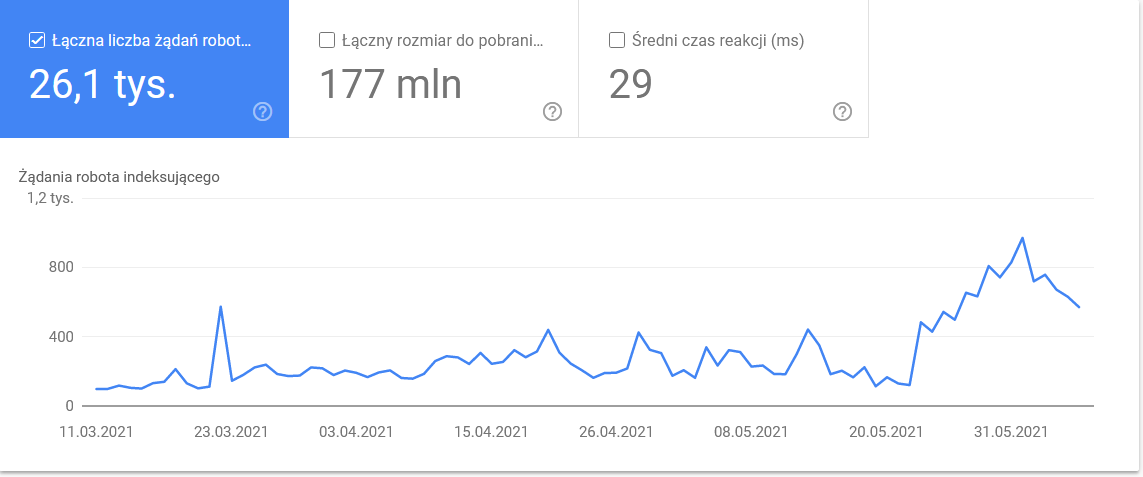
- Tip Googlebot . Aici aveți roboții care vă vizitează site-ul pe un platou de argint, împreună cu motivațiile lor pentru a vă analiza conținutul. Captura de ecran de mai jos arată că 22% dintre solicitări se referă la încărcarea resurselor paginii.
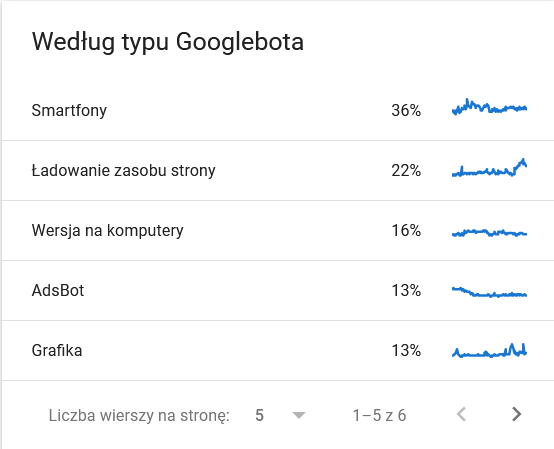
Totalul balonat în ultimele zile ale intervalului de timp:
O privire asupra detaliilor dezvăluie adresele URL care necesită o atenție sporită:
Crawler-uri externe (cu exemple din Screaming Frog SEO Spider)
Crawlerele sunt printre cele mai importante instrumente de analiză a bugetului de accesare cu crawlere al site-ului dvs. web. Scopul lor principal este de a imita mișcările roboților cu crawlere pe site. Simularea vă arată dintr-o privire dacă totul merge bine.
Dacă sunteți un cursant vizual, ar trebui să știți că majoritatea soluțiilor disponibile pe piață oferă vizualizări de date.
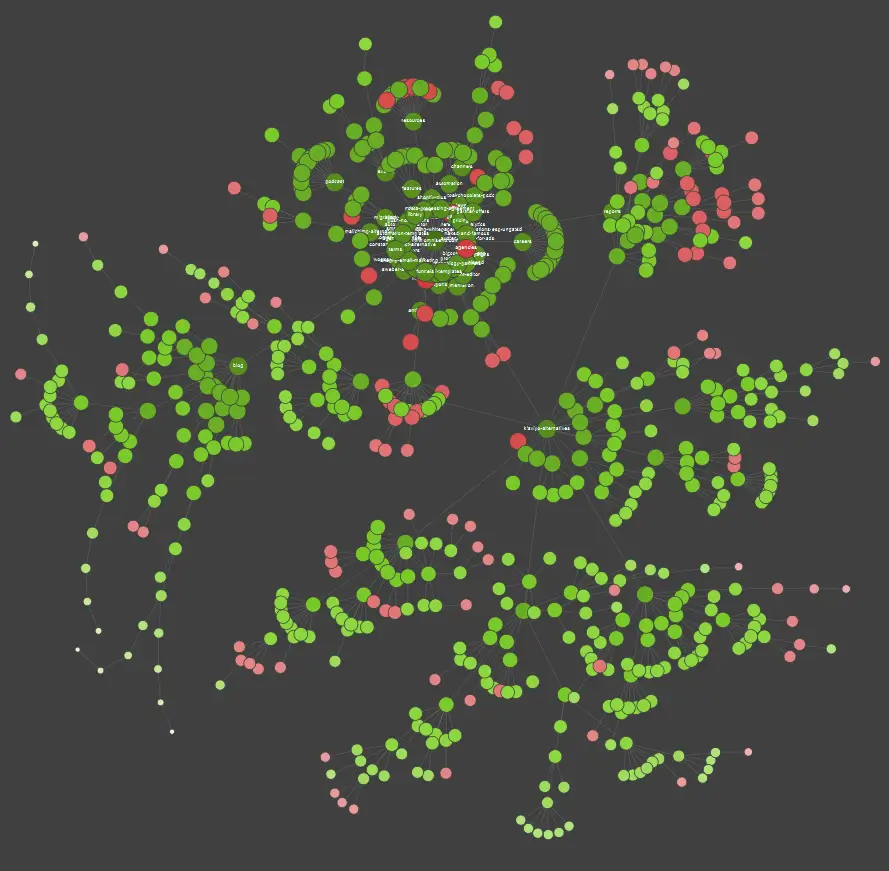
În exemplul de mai sus, punctele roșii reprezintă pagini neindexate. Luați un timp pentru a lua în considerare utilitatea și impactul lor asupra funcționării site-ului. Dacă jurnalele de server dezvăluie că aceste pagini pierd mult timp Google fără să adauge nicio valoare - este timpul să revizuim serios punctul de a le păstra pe site.
Important : dacă dorim să recreăm comportamentul unui Googlebot cât mai precis posibil, setările corecte sunt obligatorii. Aici puteți vedea exemple de setări de pe computerul meu:

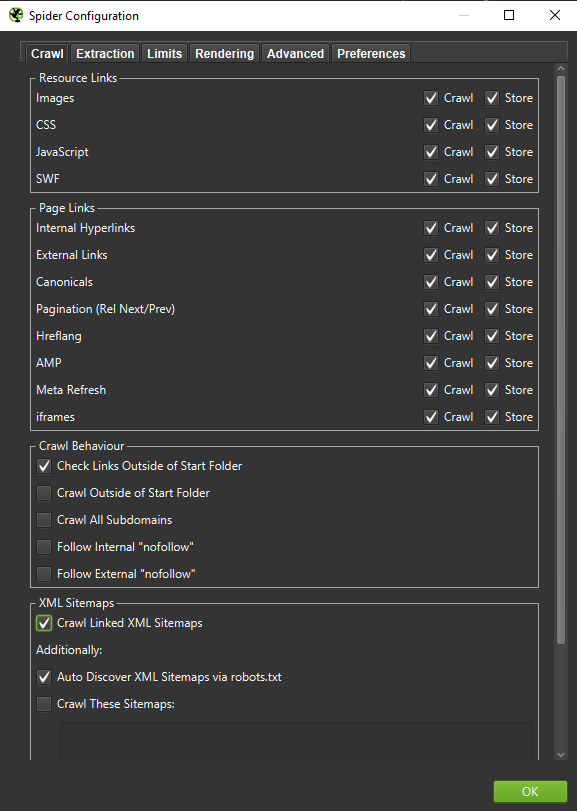
Atunci când efectuați o analiză aprofundată, este o chemare bună să testați două moduri – Numai text, dar și JavaScript – pentru a compara diferențele (dacă există).
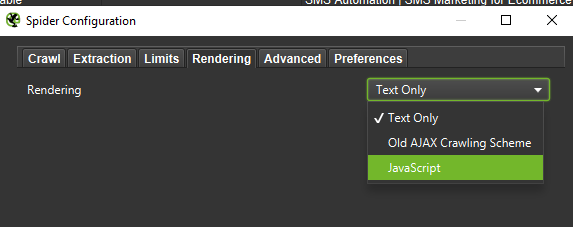
În cele din urmă, nu strică niciodată să testați configurația prezentată mai sus pe doi agenți de utilizator diferiți:
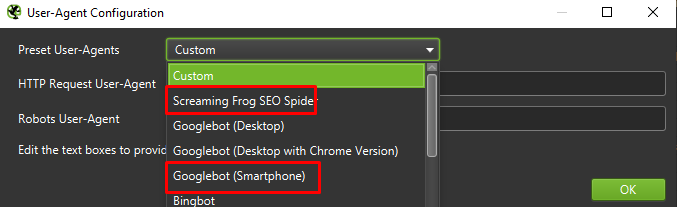
În cele mai multe cazuri, va trebui să vă concentrați doar pe rezultatele accesate cu crawlere/redate de agentul mobil.
Important: vă sugerez, de asemenea, să folosiți oportunitatea oferită de Screaming Frog și să vă alimentați crawler-ul cu date din GA și Google Search Console. Integrarea este o modalitate rapidă de a identifica risipa bugetară de accesare cu crawlere, cum ar fi un corp substanțial de adrese URL potențial redundante care nu primesc trafic.
Instrumente pentru analiza jurnalelor (Screaming Frog Logfile și altele)
Alegerea unui analizor de jurnal de server este o chestiune de preferință personală. Instrumentul meu de bază este Screaming Frog Log File Analyzer. Poate nu este cea mai eficientă soluție (încărcarea unui pachet uriaș de loguri = agățarea aplicației), dar îmi place interfața. Partea importantă este să ordonați sistemului să afișeze numai Googlebot verificați.
Instrumente pentru urmărirea vizibilității
Un ajutor util, deoarece vă permit să vă identificați paginile de top. Dacă o pagină are o poziție ridicată pentru multe cuvinte cheie în Google (= primește mult trafic), poate avea o cerere mai mare de accesare cu crawlere (verificați-o în jurnale – Google într-adevăr generează mai multe accesări pentru această pagină anume?).
În scopurile noastre, vom avea nevoie de rapoarte generale în Senuto – Căi și URL-uri – pentru o examinare continuă în viitor. Ambele rapoarte sunt disponibile în Analiza vizibilității, fila Secțiuni. Uită-te:
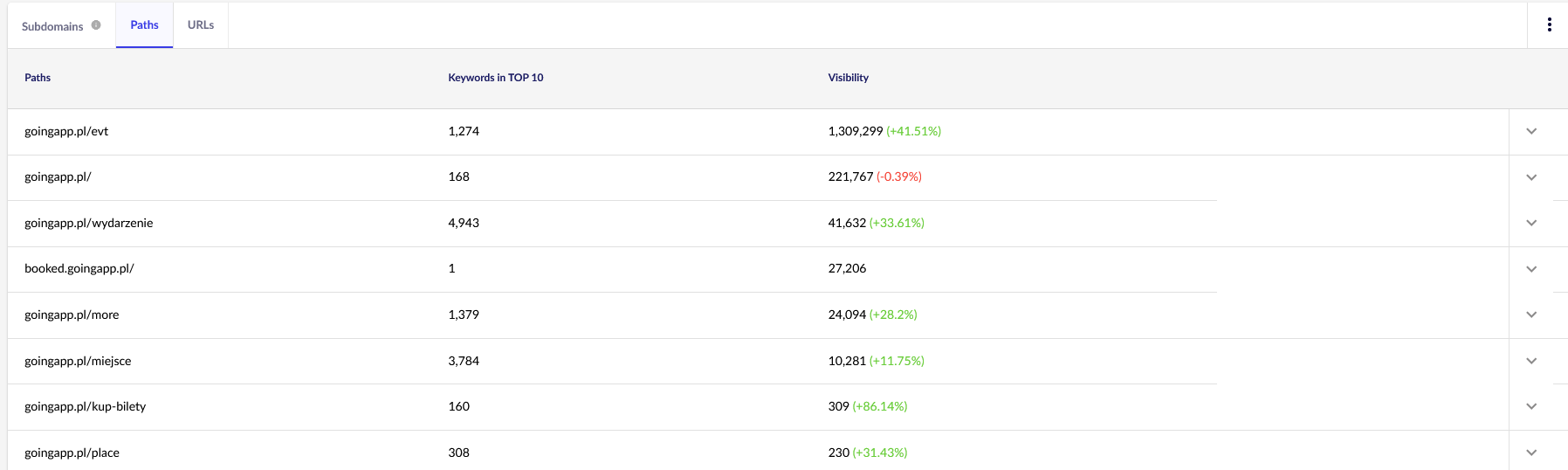
Principalul nostru punct de interes este al doilea raport. Să-l sortăm pentru a analiza vizibilitatea cuvintelor cheie (lista și numărul total de cuvinte cheie pentru care site-ul nostru se clasează în TOP 10). Rezultatele ne vor servi pentru a identifica axa principală pentru stimularea (și alocarea eficientă) a bugetului nostru de crawl.
Instrumente pentru analiza backlink (Ahrefs, Majestic)
Dacă una dintre paginile dvs. are o cantitate mare de link-uri de intrare, utilizați-o ca pilon al strategiei dvs. de optimizare a bugetului de accesare cu crawlere. Paginile populare pot prelua rolul de hub-uri care transferă sucul mai departe. În plus, o pagină populară cu un număr decent de link-uri valoroase are o șansă mai mare de a atrage accesări frecvente.
În Ahrefs, avem nevoie de raportul Pagini și, mai exact, de partea lui intitulată: „Cel mai bine după linkuri”:
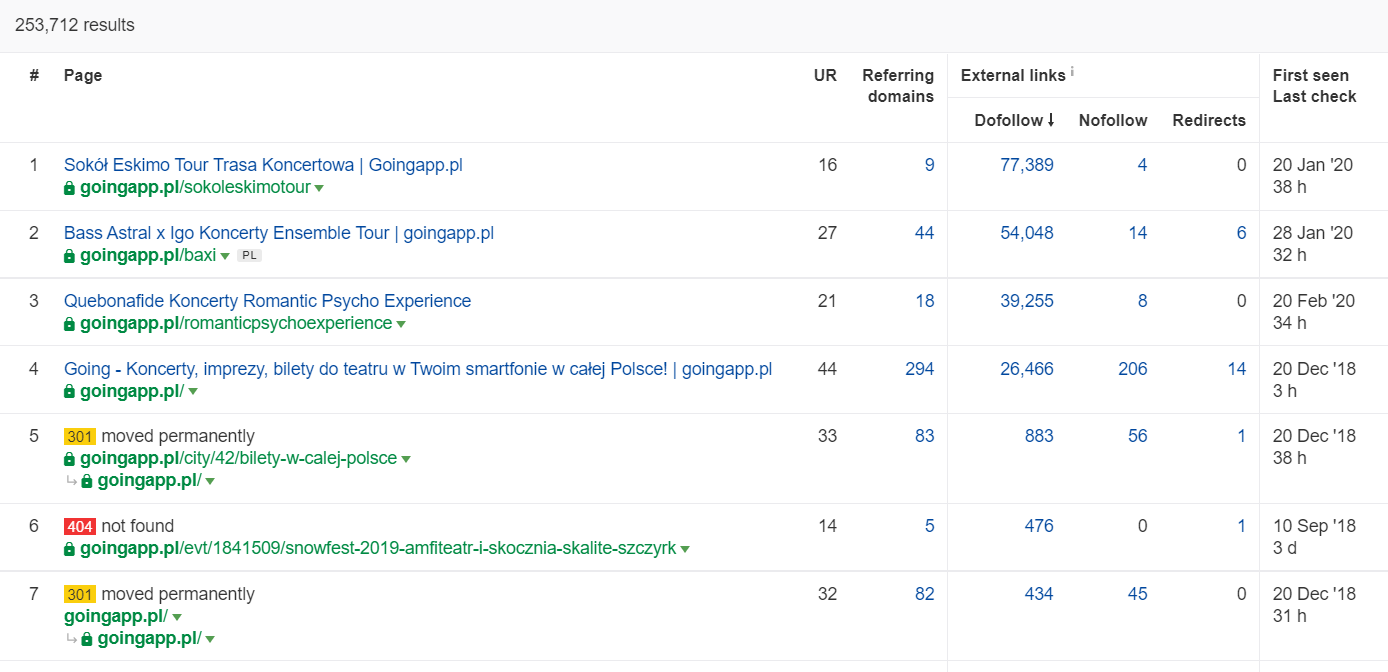
Exemplul de mai sus arată că unele LP-uri legate de concerte au continuat să genereze statistici solide pentru backlink-uri. Chiar și cu toate concertele anulate din cauza pandemiei, încă merită să folosiți pagini istorice puternice pentru a stârni curiozitatea roboților cu crawlere și pentru a răspândi sucul în colțurile mai adânci ale site-ului dvs.
Care sunt semnele revelatoare ale unei probleme cu bugetul de accesare cu crawlere?
Conștientizarea că aveți de-a face cu un buget de accesare cu crawlere problematic (excesiv de mic) nu este ușor. De ce? În principal, pentru că SEO este o întreprindere extrem de complexă. Rangurile scăzute sau problemele de indexare pot fi la fel de bine consecința unui profil de link mediocru sau a lipsei conținutului potrivit pe site.
De obicei, o diagnosticare a bugetului de accesare cu crawlere implică verificarea:
- Cât timp trece de la publicare până la indexarea paginilor noi (postări de blog/produse), presupunând că nu solicitați indexarea prin Google Search Console?
- Cât timp păstrează Google adresele URL nevalide în indexul său? Important: adresele redirecționate sunt o excepție – Google le stochează intenționat.
- Aveți pagini care intră în index doar pentru a se lăsa mai târziu?
- Cât timp petrece Google pe paginile care nu reușesc să genereze valoare (trafic)? Accesați analiza jurnalului pentru a afla.
Cum să analizați și să optimizați bugetul de accesare cu crawlere?
Decizia de a vă introduce în optimizarea bugetului de accesare cu crawlere este dictată în principal de dimensiunea site-ului dvs. Google sugerează că, în general, site-urile web cu mai puțin de 1000 de pagini nu ar trebui să se chinuie să profite la maximum de limitele de accesare cu crawlere disponibile. În cartea mea, ar trebui să începi să lupți pentru o accesare cu crawlere mai eficientă și eficientă dacă site-ul tău web include mai mult de 300 de pagini și conținutul tău se schimbă dinamic (de exemplu, continui să adaugi noi pagini / postări de blog).
De ce? Este o chestiune de igiena SEO. Implementați obiceiuri bune de optimizare și gestionarea corectă a bugetului de accesare cu crawlere în primele zile și veți avea mai puține de rectificat și reproiectat în viitor.
Optimizarea bugetului cu crawlere. O procedură standard
În general, munca de analiză și optimizare a bugetului craw constă în trei etape:
- Colectarea datelor, care este procesul de compilare a tot ceea ce știm despre site - atât de la webmasteri, cât și de la instrumente externe.
- Analiza vizibilității și identificarea fructelor agățate. Ce merge ca un ceas? Ce ar putea fi mai bun? Ce zone au cel mai mare potențial de creștere?
- Recomandări pentru bugetul de crawl.
Colectarea datelor pentru un audit bugetar cu crawlere
1. O accesare completă a site-ului web efectuată cu unul dintre instrumentele disponibile comercial. Scopul este de a finaliza cel puțin două accesări cu crawlere: prima simulează Googlebot, în timp ce cealaltă preia site-ul web ca agent utilizator implicit (agentul utilizator al unui browser va face). În această etapă, sunteți interesat doar să descărcați 100% din conținut . Dacă observați că crawler-ul a intrat într-o buclă (când, după o zi de crawling, mai avem doar 10% din site-ul web pe hard disk) - să știți că există o problemă și puteți opri crawler-ul. Un număr rezonabil de adrese URL pentru analiză, în cazul site-urilor web mari, este de aproximativ 250–300 de mii de pagini.
a) Ceea ce căutăm sunt în principal redirecționări interne 301, erori 404, dar și situații în care textele dvs. pot fi clasificate ca conținut subțire. Screaming Frog are opțiunea de a detecta conținut aproape duplicat:
2. Jurnalele serverului . Perioada de timp ideală ar trebui să acopere ultima lună, însă, în cazul site-urilor web mari, ultimele două săptămâni se pot dovedi suficiente. În cel mai bun scenariu, ar trebui să avem acces la jurnalele istorice ale serverului pentru a compara mișcările Googlebot la momentul în care totul mergea bine.
3. Exporturi de date din Google Search Console . În combinație cu punctele 1 și 2 de mai sus, datele din Acoperirea indexului și Statisticile de accesare cu crawlere ar trebui să vă ofere o relatare destul de cuprinzătoare a tuturor evenimentelor de pe site-ul dvs.
4. Date organice de trafic . Paginile de top după cum sunt determinate de Google Search Console, Google Analytics, precum și Senuto și Ahrefs. Dorim să identificăm toate paginile care ies în evidență în rândul mulțimii prin statisticile lor de mare vizibilitate, volumul de trafic sau numărul de backlink. Aceste pagini ar trebui să devină coloana vertebrală a activității dvs. privind bugetul de accesare cu crawlere. Le vom folosi pentru a îmbunătăți accesarea cu crawlere a celor mai importante pagini.
5. Revizuirea manuală a indexului . În unele cazuri, cel mai bun prieten al unui expert SEO este o soluție simplă. În acest caz: o trecere în revistă a datelor preluate direct din index! Este un apel bun să vă verificați site-ul web cu combinația de operatori inurl: + site:.În cele din urmă, trebuie să unim toate datele colectate. De obicei, vom folosi un crawler extern cu funcții care permit importurile de date externe (date GSC, jurnalele de server și date organice de trafic).
Analiza vizibilității și fructele agățate
Procesul necesită un articol separat, dar scopul nostru de astăzi este să obținem o perspectivă generală asupra obiectivelor noastre pentru site-ul web și a progresului înregistrat. Ne interesează tot ceea ce iese din comun: scăderi bruște de trafic (care nu pot fi explicate prin tendințele sezoniere) și schimbări concomitente ale vizibilității organice. Verificăm care grupuri de pagini sunt cele mai puternice, deoarece acestea vor deveni HUB-urile noastre pentru a împinge Googlebot mai adânc în site-ul nostru.
În lumea perfectă, un astfel de control ar trebui să acopere întreaga istorie a site-ului nostru de la lansare. Cu toate acestea, deoarece volumul de date continuă să crească în fiecare lună, să ne concentrăm pe analiza vizibilității și a traficului organic din ultimele 12 luni.
Bugetul de accesare cu crawlere – recomandările noastre
Activitățile enumerate mai sus vor diferi în funcție de dimensiunea site-ului web optimizat. Cu toate acestea, acestea sunt cele mai importante elemente pe care le iau întotdeauna în considerare atunci când efectuez o analiză a bugetului de accesare cu crawlere. Scopul primordial este de a elimina blocajele de pe site-ul dvs. Cu alte cuvinte, pentru a garanta accesul cu crawlere maxim pentru Googlebots (sau alți agenți de indexare).
1. Să începem de la elementele de bază – eliminarea tot felul de erori 404/410, analiza redirecționărilor interne și eliminarea lor din link-ul intern . Ar trebui să ne încheiem treaba cu un ultim crawl. De data aceasta, toate linkurile ar trebui să returneze un cod de răspuns 200, fără redirecționări interne sau erori 404.
- În această etapă, este o idee bună să rectificați toate lanțurile de redirecționare detectate în raportul de backlink.
2. După accesarea cu crawlere, asigurați-vă că structura site-ului nostru nu conține duplicate flagrante .
- Verificați și împotriva potențialei canibalizări – în afară de problemele care apar din vizarea aceluiași cuvânt cheie cu mai multe pagini (pe scurt, nu mai controlați ce pagină va fi afișată de Google), canibalizarea vă afectează negativ întregul buget de accesare cu crawlere.
- Consolidați duplicatele identificate într-o singură adresă URL (de obicei cea care se clasează mai sus).
3. Verificați câte adrese URL au eticheta noindex . După cum știm, Google încă poate naviga prin acele pagini. Pur și simplu nu apar în rezultatele căutării. Încercăm să minimizăm ponderea etichetelor noindex în structura site-ului nostru.
- Caz concret – un blog își organizează structura cu etichete; autorii susțin că soluția este dictată de confortul utilizatorului. Fiecare postare este etichetată cu 3–5 etichete, atribuite inconsecvent și neindexate. Analiza jurnalelor arată că este a treia structură cea mai accesată cu crawlere de pe site.
4. Examinați robots.txt . Rețineți că implementarea robots.txt nu înseamnă că Google nu va afișa adresa în index.
- Verificați care dintre structurile de adrese blocate sunt încă accesate cu crawlere. Poate că tăierea lor cauzează un blocaj?
- Eliminați directivele învechite/care nu sunt necesare.
5. Analizați volumul de adrese URL non-canonice de pe site-ul dvs. Google a încetat să considere rel="canonical" drept o directivă rigidă. În multe cazuri, atributul este de-a dreptul ignorat de motorul de căutare (parametrii de sortare în index – încă un coșmar).
6. Analizați filtrele și mecanismul lor subiacent . Filtrarea înregistrărilor este cea mai mare durere de cap a optimizării bugetului de accesare cu crawlere. Proprietarii de afaceri de comerț electronic insistă să implementeze filtre aplicabile în orice combinație (de exemplu, filtrarea după culoare + material + dimensiune + disponibilitate... până la a enesesa oară). Soluția nu este optimă și ar trebui limitată la minimum.
7. Arhitectura informațiilor de pe site – una care ia în considerare obiectivele de afaceri, potențialul de trafic și profilul actual de link. Să lucrăm pe ipoteza că un link către conținutul esențial pentru obiectivele noastre de afaceri ar trebui să fie vizibil pe tot site-ul (pe toate paginile) sau pe pagina de pornire. Simplificăm aici, desigur, dar pagina de pornire și meniul de sus / link-urile la nivel de site sunt cei mai puternici indicatori în construirea valorii din linkurile interne. În același timp, încercăm să obținem o răspândire optimă a domeniului: scopul nostru este situația în care putem începe accesarea cu crawlere de pe orice pagină și să ajungem în continuare la același număr de pagini (fiecare URL ar trebui să aibă un link de intrare LA MINIM) .
- Lucrul către o arhitectură informațională robustă este unul dintre elementele cheie ale optimizării bugetului de accesare cu crawlere. Ne permite să eliberăm unele dintre resursele botului dintr-o locație și să le redirecționăm către alta. Este, de asemenea, una dintre cele mai mari provocări, deoarece necesită cooperarea părților interesate de afaceri – ceea ce duce adesea la lupte uriașe și critici care subminează recomandările SEO.
8. Redarea conținutului. Esențial în cazul site-urilor web care urmăresc să își bazeze linkurile interne pe sisteme de recomandare care captează comportamentul utilizatorului. Mai presus de toate, majoritatea acestor instrumente se bazează pe fișiere cookie. Google nu stochează cookie-uri, așa că nu obține rezultate personalizate. Rezultatul: Google vede întotdeauna același conținut sau nu vede deloc conținut.
- Este o greșeală comună să împiedici Googlebot să acceseze conținut critic JS/CSS. Această mișcare poate duce la probleme cu indexarea paginilor (și pierde timpul Google cu redarea conținutului indisponibil).
9. Performanța site-ului – Core Web Vitals . Deși sunt sceptic cu privire la impactul CWV asupra clasamentelor site-urilor (din multe motive, inclusiv diversitatea dispozitivelor disponibile comercial și vitezele diferite ale conexiunii la Internet), este unul dintre parametrii care merită cel mai mult discutați cu un codificator.
10. Sitemap.xml – verificați dacă funcționează și conține toate elementele cheie (nimic decât URL-uri canonice care returnează un cod de stare 200).
- Prima mea recomandare pentru optimizarea sitemap.xml este să vă împărțiți paginile după tip sau – când este posibil – categorie. Divizia vă va oferi control deplin asupra mișcărilor Google și indexării conținutului.