
Достижение отказоустойчивости с помощью очередей: создание системы, которая никогда не пропускает ни одного удара из миллиарда
Опубликовано: 2018-12-21Braze обрабатывает миллиарды и миллиарды событий в день от имени своих клиентов, в результате чего конечным пользователям отправляются миллиарды сверхцеленаправленных персонализированных сообщений. Неспособность отправить одно из этих сообщений имеет последствия, будь то пропущенная квитанция или, что еще хуже, пропущенное уведомление, информирующее пользователя о том, что его еда готова. Чтобы эти ключевые сообщения всегда были правильными и своевременными, Braze применяет стратегический подход к тому, как мы используем очереди заданий.
Что такое очередь заданий?
Типичная очередь заданий — это архитектурный шаблон, в котором процессы отправляют вычислительные задания в очередь, а другие процессы фактически выполняют эти задания. Обычно это хорошо — при правильном использовании это дает вам такие степени параллелизма, масштабируемости и избыточности, которые вы не можете получить с традиционной парадигмой «запрос-ответ». Многие работники могут одновременно выполнять разные задания в нескольких процессах, на нескольких машинах или даже в нескольких центрах обработки данных для обеспечения максимального параллелизма. Вы можете назначать определенные рабочие узлы для работы с определенными очередями и отправлять определенные задания в определенные очереди, что позволяет масштабировать ресурсы по мере необходимости. В случае сбоя рабочего процесса или отключения центра обработки данных оставшиеся задания могут выполнять другие рабочие процессы.
Хотя вы, безусловно, можете применить эти принципы и легко запустить систему очередей заданий в небольшом масштабе, швы начинают проявляться (и даже разрываться), когда вы обрабатываете миллиарды и миллиарды заданий. Давайте рассмотрим несколько проблем, с которыми столкнулся Braze, когда мы выросли от обработки тысяч до миллионов, а теперь и миллиардов рабочих мест в день.
Отсутствие последовательности — это слабость
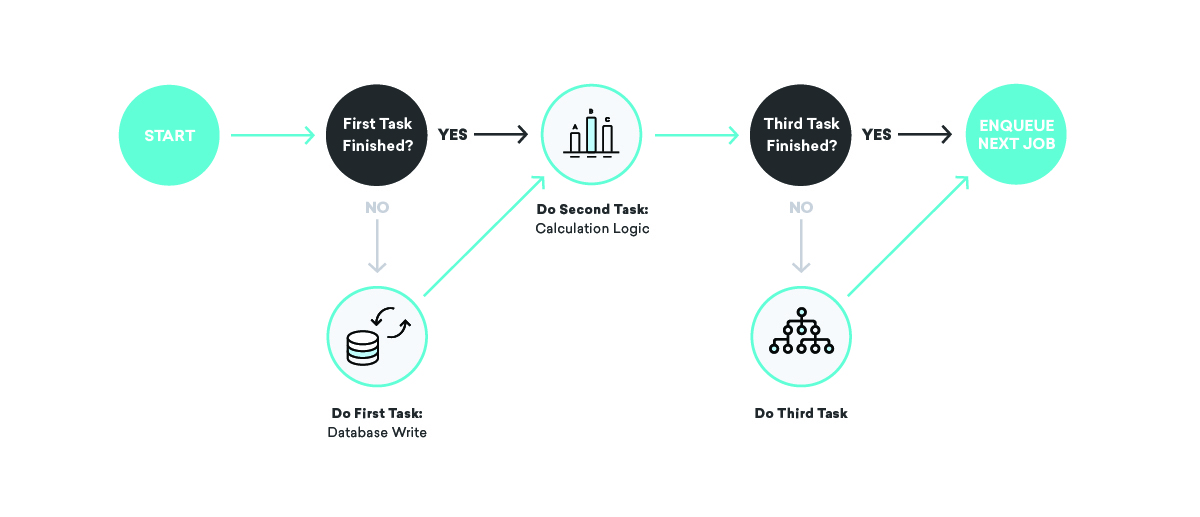
Что произойдет, если мы отправим сообщение, но произойдет сбой до того, как будет записан тот факт, что мы только что отправили это сообщение?
Здесь возможны несколько разных плохих исходов. Во-первых, вы можете перепланировать невыполненное задание и снова отправить сообщение. Это… не идеально: никто не хочет получать одно и то же дважды. Вместо этого подумайте о том, чтобы вообще не перепланировать его. В этом случае наш внутренний учет будет неправильным, поэтому атрибуции, конверсии и все остальные вещи не будут правильными в будущем.
Как это исправить? Когда мы пишем определения наших заданий, мы очень много думаем об идемпотентности и поведении повторных попыток.
Когда вы говорите об очередях, идемпотентность означает, что одно задание может быть остановлено в произвольной точке, повторно поставленное в очередь задание полностью перезапущено, и конечный результат будет таким же, как если бы мы успешно выполнили задание ровно один раз. время. Это тесно связано с нашим предпочтительным поведением при повторных попытках — доставка по крайней мере один раз. Помня о том, что все наши задания будут выполняться по крайней мере один раз, а может и несколько раз, мы можем написать идемпотентные определения заданий, обеспечивающие согласованность даже при случайных сбоях.
Возвращаясь к нашему примеру с отправкой сообщений, как мы можем использовать эти концепции для обеспечения согласованности? В этом случае мы можем разбить задание на две части: первая отправляет сообщение и ставит вторую в очередь, а вторая записывает в базу данных. В этом сценарии мы можем повторять любое задание столько раз, сколько захотим — если провайдер отправки сообщений не работает или внутренняя база данных учета не работает, мы будем соответствующим образом повторять попытки, пока не добьемся успеха!
Хорошие заборы — хорошие соседи
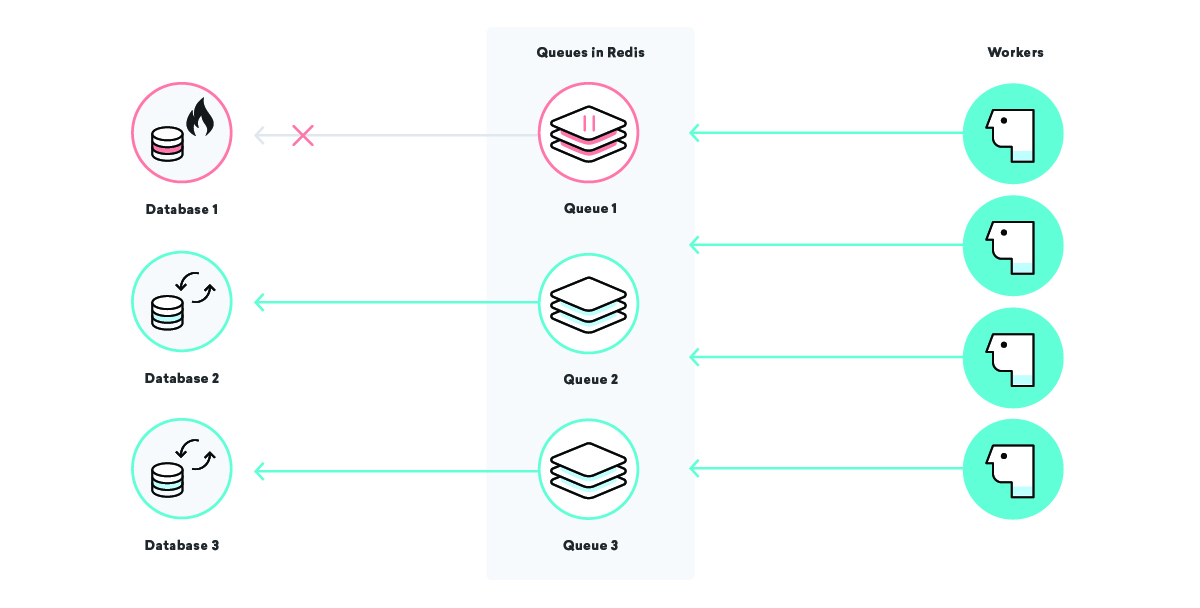
Что происходит с обработкой данных нашей компании Consolidated Widgets, когда база данных для Global Gizmos не работает?
В этом сценарии, если действует наша стратегия доставки хотя бы один раз, мы ожидаем, что все задания по обработке данных для Global Gizmos будут повторяться снова и снова, пока они не увенчаются успехом. Это здорово — мы не потеряем никаких данных, даже если их база данных не работает. Однако для Consolidated Widgets это может быть не так уж хорошо: если рабочие постоянно повторяют попытки и терпят неудачу, они могут быть слишком заняты, чтобы своевременно обрабатывать работу Consolidated Widgets.
Мы можем исправить это, используя хорошо подобранные имена очередей и приостанавливая определенные очереди по мере необходимости. Имея это в нашем наборе инструментов, мы можем хирургическим путем снизить нагрузку на элементы инфраструктуры. В приведенном выше сценарии, как только мы узнаем, что база данных Global Gizmos не работает, мы можем приостановить их очередь обработки данных до тех пор, пока не узнаем, что она восстановлена, гарантируя, что один конкретный сбой не повлияет на других клиентов!

Ожидание болезненно
Что, если Consolidated Widgets и Global Gizmos рассылают рассылки по электронной почте 50 миллионам пользователей каждая с интервалом в 5 минут? Кто идет первым?
Простые системы очередей заданий имеют простую «рабочую» очередь, из которой работники извлекают задания. После того, как у вас будет достаточное количество различных заданий и типов заданий, вы, вероятно, перейдете к созданию нескольких типов очередей, каждый из которых имеет разные приоритеты или типы работников, извлекающих из этих очередей. В этом ключе у нас есть множество простых очередей для обработки данных, обмена сообщениями и различных задач обслуживания.
Перенесемся к тому моменту, когда вы отправляете миллиарды персонализированных сообщений в день, одной очереди «обмена сообщениями» не хватит — что произойдет, когда эта очередь станет очень большой, как в нашем примере выше? Отдаем ли мы предпочтение вакансиям, которые появились первыми?
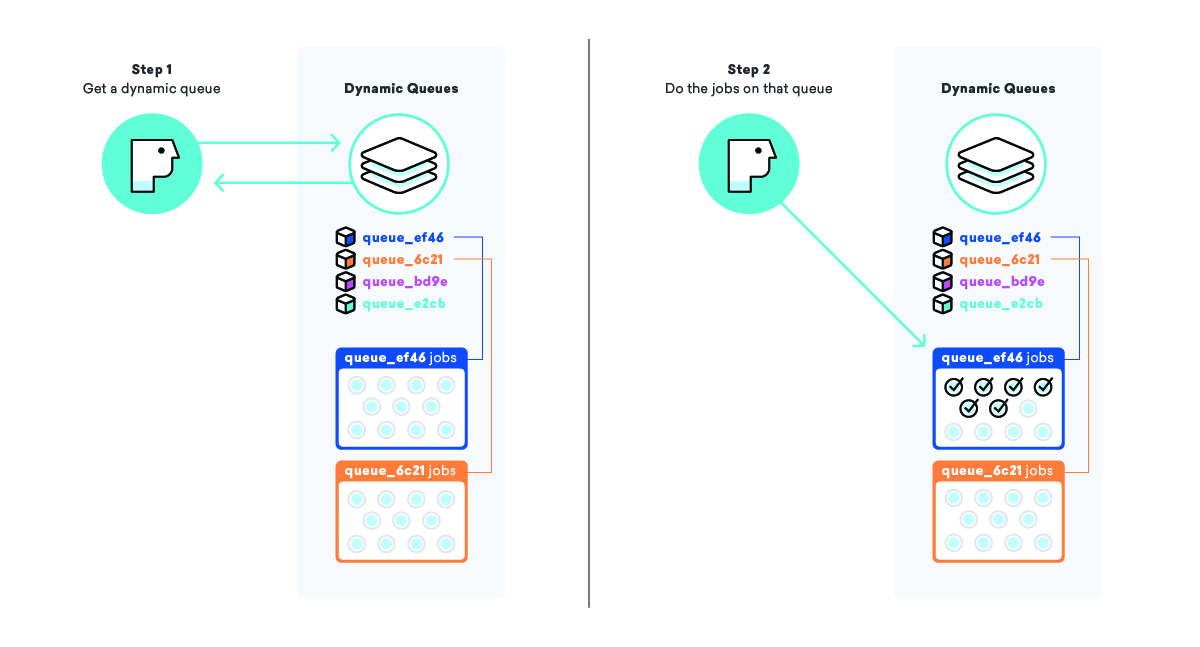
Наша динамическая система очередей направлена на устранение явления, называемого голоданием заданий, когда задание, готовое к выполнению, ожидает долгое время перед выполнением, обычно из-за какого-то приоритета. В простой очереди «обмена сообщениями» приоритет — это просто время поступления задания в очередь, а это означает, что задания, добавленные в конец большой очереди, могут ждать очень долго.
Когда мы ставим в очередь кампанию и все ее сообщения, вместо того, чтобы добавлять задания в большую очередь «обмена сообщениями», мы создаем совершенно новую очередь только для этой кампании со специальным именем, чтобы мы знали, что это такое и как его найти. После добавления заданий в очередь мы берем наш список «динамических очередей» и добавляем это новое имя очереди в конец.
Используя эту стратегию, мы можем поручить рабочим выбрать имя динамической очереди из списка «динамических очередей», а затем обработать все задания в этой конкретной очереди. Это позволяет нам гарантировать, что сообщения отправляются как можно быстрее И что все наши клиенты обрабатываются с одинаковым приоритетом.
Следовательно, это имеет и другие преимущества, такие как более высокая частота попаданий в кэш и меньшее количество подключений к базе данных из-за увеличения локальности работы для конкретных работников. Все выигрывают!
Всегда имейте запасной план
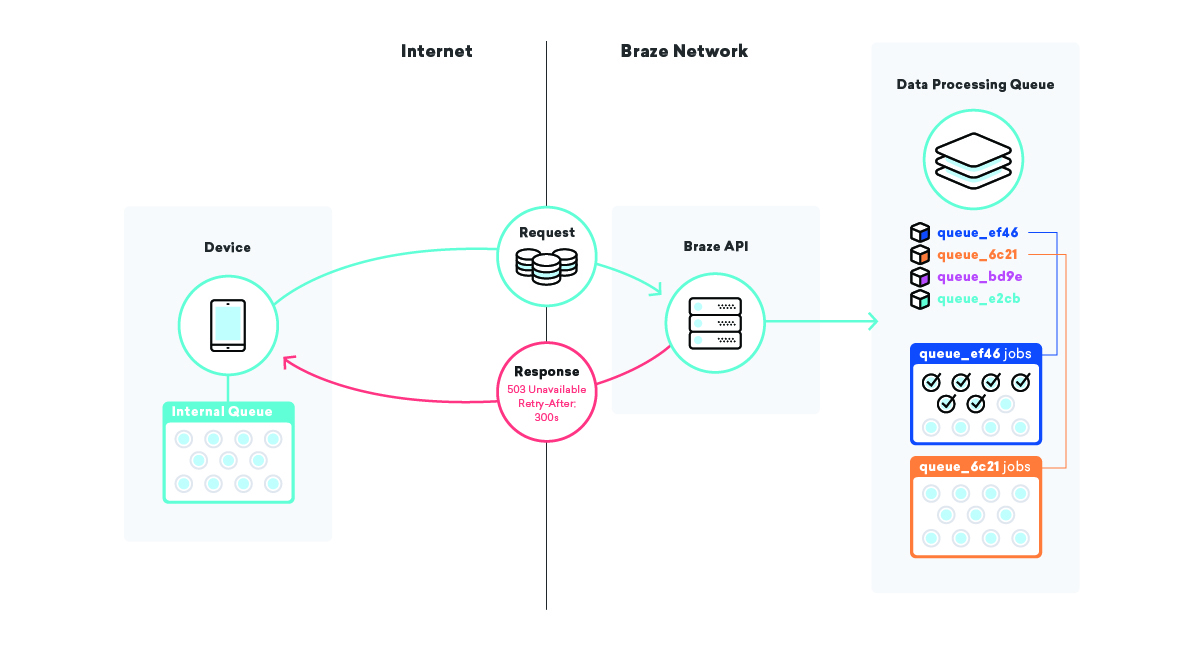
Что происходит, когда база данных не работает, некоторые очереди приостановлены, а очереди заданий начинают заполняться?
Иногда важные элементы инфраструктуры просто умирают. У нас есть вторичные и резервные копии, но время, необходимое для продвижения инфраструктуры резервного копирования, почти никогда не равно нулю. Наличие нескольких уровней очередей во всей инфраструктуре приложений может быть очень полезным для смягчения последствий таких событий.
Одна из таких стратегий, которую мы используем, — создание очереди на самих устройствах. Миллионы и миллионы устройств имеют различные приложения, использующие Braze SDK, и в этих приложениях мы используем очередь для отправки данных в наши API.
Когда наш SDK отправляется на отправку этих данных и по какой-либо причине терпит неудачу, SDK ставит в очередь повторную попытку, используя экспоненциальный алгоритм отсрочки, пока не добьется успеха. Эта стратегия сводит к минимуму влияние сбоев инфраструктуры или кода, поскольку устройства просто ставят в очередь свои собственные данные и отправляют их в Braze, когда все возвращается в онлайн.
Двигаться быстро и ничего не ломать
В конце концов, наша цель — отправлять сверхцеленаправленные, персонализированные сообщения лучше, чем кто-либо другой, а для этого нужно действовать быстро, быть гибкими и делать все правильно. Очереди заданий лежат в основе инфраструктуры Braze, поэтому мы всегда следим за своей производительностью, применяем передовой опыт и экспериментируем с новыми стратегиями и передовыми методами, чтобы быть лучшими в игре.
Если этот тип высокопроизводительной системной инженерии с малой задержкой в области автоматизации маркетинга вас волнует, то вам обязательно следует посетить нашу доску объявлений!