
Эффективное обучение: ближайшее будущее ИИ
Опубликовано: 2017-11-09Эти эффективные методы обучения не являются новыми методами глубокого обучения/машинного обучения, а дополняют существующие методы в виде хаков
Нет никаких сомнений в том, что конечное будущее ИИ должно достичь и превзойти человеческий интеллект. Но это надуманный подвиг. Даже самые оптимистичные из нас делают ставку на то, что искусственный интеллект человеческого уровня (AGI или ASI) появится через 10-15 лет, а скептики даже готовы поспорить, что на это уйдут столетия, если это вообще возможно. Ну пост не об этом.
Здесь мы поговорим о более осязаемом, ближайшем будущем и обсудим новые и эффективные алгоритмы и методы ИИ, которые, по нашему мнению, будут определять ближайшее будущее ИИ.
ИИ начал улучшать людей в нескольких избранных и конкретных задачах. Например, победа над врачами при диагностике рака кожи и победа над игроками в го на чемпионате мира. Но те же системы и модели не справятся с задачами, отличными от тех, для решения которых они были обучены. Вот почему в долгосрочной перспективе в целом интеллектуальная система, которая эффективно выполняет набор задач без необходимости переоценки, считается будущим ИИ.
Но в ближайшем будущем ИИ, задолго до того, как появится ОИИ, как ученые смогут заставить алгоритм на основе ИИ преодолеть проблемы, с которыми они сталкиваются сегодня, выйти из лабораторий и стать объектами повседневного использования?
Если вы посмотрите вокруг, ИИ выигрывает замок за замком (читайте наши статьи о том, как ИИ опережает людей, часть первая и часть вторая). Что может пойти не так в такой беспроигрышной игре? Со временем люди производят все больше и больше данных (это корм, который потребляет ИИ), и наши аппаратные возможности также улучшаются. В конце концов, именно благодаря данным и более совершенным вычислениям в 2012 году началась революция глубокого обучения, верно? Правда в том, что быстрее, чем рост данных и вычислений, растут человеческие ожидания. Специалистам по данным придется думать о решениях, выходящих за рамки того, что существует сейчас, для решения реальных проблем. Например, классификация изображений, как думает большинство людей, является научно решаемой проблемой (если мы сопротивляемся желанию сказать 100% точность или GTFO).
Мы можем классифицировать изображения (скажем, на изображения кошек или изображений собак) в соответствии с человеческими способностями, используя ИИ. Но можно ли уже использовать это для реальных случаев использования? Может ли ИИ решить более практические проблемы, с которыми сталкиваются люди? В некоторых случаях да, но во многих случаях мы еще не достигли этого.
Мы познакомим вас с проблемами, которые являются основными препятствиями на пути разработки реального решения с использованием ИИ. Допустим, вы хотите классифицировать изображения кошек и собак. Мы будем использовать этот пример на протяжении всего поста.

Алгоритм нашего примера: Классификация изображений кошек и собак
На приведенном ниже рисунке обобщены проблемы:

Проблемы, связанные с разработкой реального ИИ
Давайте подробно обсудим эти проблемы:
Обучение с меньшим объемом данных
- Обучающие данные, которые потребляют наиболее успешные алгоритмы глубокого обучения, требуют, чтобы они были помечены в соответствии с содержащимся в них контентом/функцией. Этот процесс называется аннотацией.
- Алгоритмы не могут использовать естественно найденные данные вокруг вас. Аннотировать несколько сотен (или нескольких тысяч точек данных) легко, но нашему алгоритму классификации изображений на человеческом уровне потребовался миллион аннотированных изображений, чтобы хорошо изучить его.
- Итак, вопрос в том, возможно ли аннотирование миллиона изображений? Если нет, то как ИИ может масштабироваться с меньшим количеством аннотированных данных?
Решение разнообразных реальных проблем
- Хотя наборы данных фиксированы, реальное использование более разнообразно (например, алгоритм, обученный на цветных изображениях, может плохо работать с изображениями в оттенках серого, в отличие от людей).
- В то время как мы улучшили алгоритмы компьютерного зрения для обнаружения объектов, чтобы они соответствовали людям. Но, как упоминалось ранее, эти алгоритмы решают очень специфическую проблему по сравнению с человеческим интеллектом, который во многих смыслах гораздо более общий.
- Наш пример алгоритма искусственного интеллекта, который классифицирует кошек и собак, не сможет идентифицировать редкий вид собак, если не будет загружен изображениями этого вида.
Настройка инкрементных данных
- Еще одна серьезная проблема — дополнительные данные. В нашем примере, если мы пытаемся распознавать кошек и собак, мы можем обучить наш ИИ нескольким изображениям кошек и собак разных видов при первом развертывании. Но при открытии вообще нового вида нам нужно обучить алгоритм распознавать «Котпи» вместе с предыдущими видами.
- Хотя новый вид может быть более похож на других, чем мы думаем, и его можно легко обучить адаптации алгоритма, есть моменты, когда это сложнее и требует полного повторного обучения и повторной оценки.
- Вопрос в том, можем ли мы сделать ИИ хотя бы адаптируемым к этим небольшим изменениям?
Чтобы сделать ИИ пригодным для немедленного использования, идея состоит в том, чтобы решить вышеупомянутые проблемы с помощью набора подходов, называемых «Эффективное обучение» (обратите внимание, что это не официальный термин, я просто придумываю его, чтобы не писать «Мета-обучение», «Перенос обучения», «Немного обучения»). Выстреловое обучение, состязательное обучение и многозадачное обучение каждый раз). Мы в ParallelDots сейчас используем эти подходы для решения узких задач с помощью ИИ, побеждая в небольших битвах и готовясь к более комплексному ИИ для победы в больших войнах. Давайте познакомим вас с этими методами по одному.
Примечательно, что большинство из этих методов эффективного обучения не являются чем-то новым. Просто сейчас они наблюдают возрождение. Исследователи SVM (Support Vector Machines) уже давно используют эти методы. Состязательное обучение, с другой стороны, появилось в результате недавней работы Гудфеллоу в GAN, а нейронное мышление — это новый набор методов, для которых совсем недавно стали доступны наборы данных. Давайте углубимся в то, как эти методы помогут в формировании будущего ИИ.
Трансферное обучение
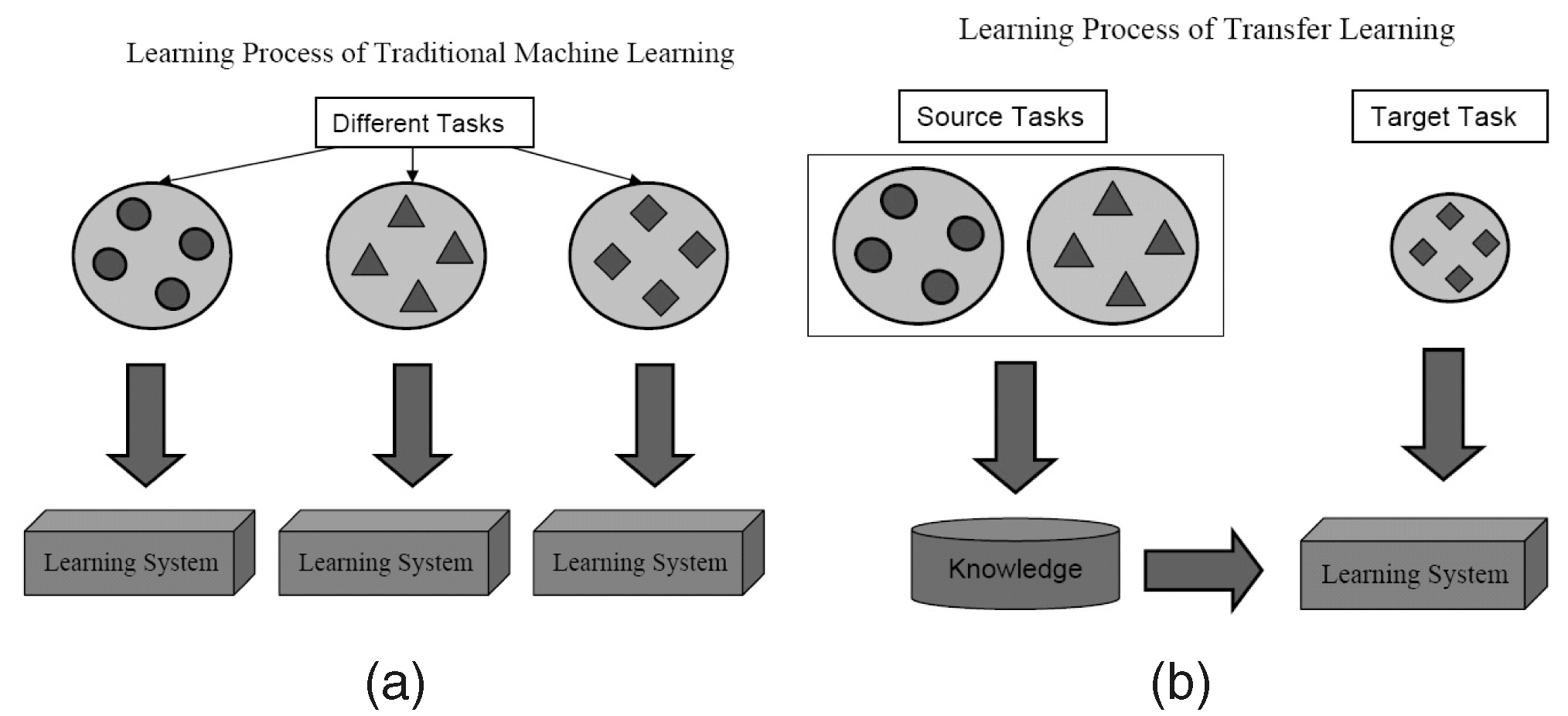
Что это?
Как следует из названия, обучение переносится с одной задачи на другую в рамках одного и того же алгоритма в Transfer Learning. Алгоритмы, обученные одной задаче (исходной задаче) с большим набором данных, могут быть перенесены с модификацией или без нее как часть алгоритма, пытающегося изучить другую задачу (целевую задачу) на (относительно) меньшем наборе данных.
Некоторые примеры
Использование параметров алгоритма классификации изображений в качестве экстрактора признаков в различных задачах, таких как обнаружение объектов, является простым применением трансферного обучения. Напротив, его также можно использовать для выполнения сложных задач. Алгоритм, разработанный Google для классификации диабетической ретинопатии лучше, чем врачи, недавно был создан с использованием трансферного обучения. Удивительно, но детектор диабетической ретинопатии на самом деле был классификатором изображений реального мира (классификатором изображений собак / кошек) Transfer Learning для классификации сканов глаз.
Расскажи мне больше!
В литературе по глубокому обучению вы найдете специалистов по данным, которые называют такие перенесенные части нейронных сетей из источника в целевую задачу предварительно обученными сетями. Точная настройка - это когда ошибки целевой задачи мягко распространяются обратно в предварительно обученную сеть вместо использования предварительно обученной сети без изменений. Хорошее техническое введение в Transfer Learning in Computer Vision можно увидеть здесь. Эта простая концепция трансферного обучения очень важна в нашем наборе методологий эффективного обучения.
Рекомендуется для вас:

Как Metaverse изменит индийскую автомобильную промышленность

Что означает положение о борьбе со спекуляцией для индийских стартапов?

Как стартапы Edtech помогают повысить квалификацию рабочей силы Индии и стать готовыми к будущему ...

Технологические акции нового века на этой неделе: проблемы Zomato продолжаются, EaseMyTrip публикует...

Индийские стартапы срезают путь в погоне за финансированием

Цифровая маркетинговая платформа Logicserve Bags Финансирование 80 CR INR, ребрендинг как LS Dig...
Многозадачное обучение
Что это?
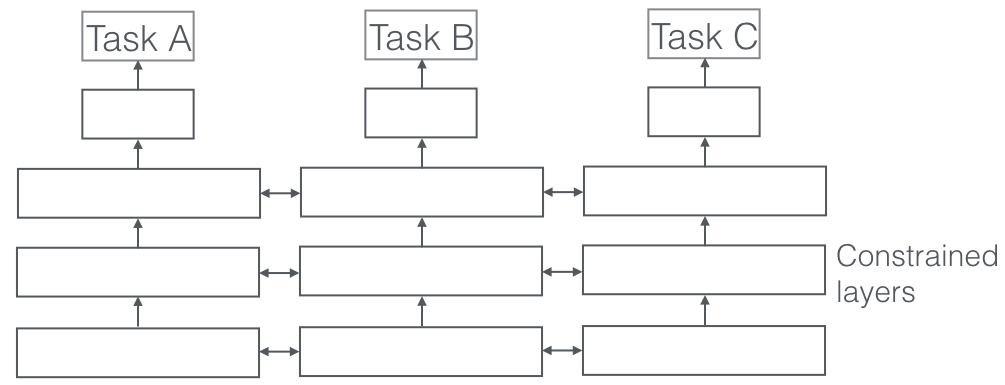

В многозадачном обучении несколько учебных задач решаются одновременно, используя общие черты и различия между задачами. Удивительно, но иногда совместное изучение двух или более задач (также называемых основной задачей и вспомогательными задачами) может улучшить результаты выполнения задач. Обратите внимание, что не каждую пару, тройку или четверку заданий можно считать вспомогательными. Но когда это работает, это бесплатное увеличение точности.
Некоторые примеры
Например, в ParallelDots наши классификаторы настроений, намерений и обнаружения эмоций были обучены как многозадачное обучение, что повысило их точность по сравнению с тем, если бы мы обучали их по отдельности. Лучшая система маркировки семантических ролей и тегов POS в НЛП, которую мы знаем, — это система многозадачного обучения, поэтому она является одной из лучших систем для семантической сегментации и сегментации экземпляров в Computer Vision. Google разработал мультимодальные многозадачные обучающиеся (одна модель, чтобы управлять ими всеми), которые могут учиться как на зрительных, так и на текстовых наборах данных в одном кадре.
Расскажи мне больше!
Очень важный аспект многозадачного обучения, который наблюдается в реальных приложениях, заключается в том, что обучение любой задачи становится пуленепробиваемым, мы должны учитывать данные многих доменов, из которых поступают (также называемые адаптацией домена). Примером в наших случаях использования кошек и собак будет алгоритм, который может распознавать изображения из разных источников (скажем, камеры VGA и HD-камеры или даже инфракрасные камеры). В таких случаях к любой задаче может быть добавлена дополнительная потеря классификации домена (откуда пришли изображения), а затем машина учится так, что алгоритм продолжает улучшаться в основной задаче (классификация изображений в изображения кошек или собак), но намеренно ухудшается во вспомогательной задаче (это делается путем обратного распространения обратного градиента ошибки из задачи классификации предметной области). Идея состоит в том, что алгоритм изучает отличительные признаки для основной задачи, но забывает признаки, которые различают домены, и это сделало бы его лучше. Многозадачное обучение и его родственники, адаптация предметной области, являются одними из самых успешных известных нам методов эффективного обучения и играют большую роль в формировании будущего ИИ.
Состязательное обучение
Что это?
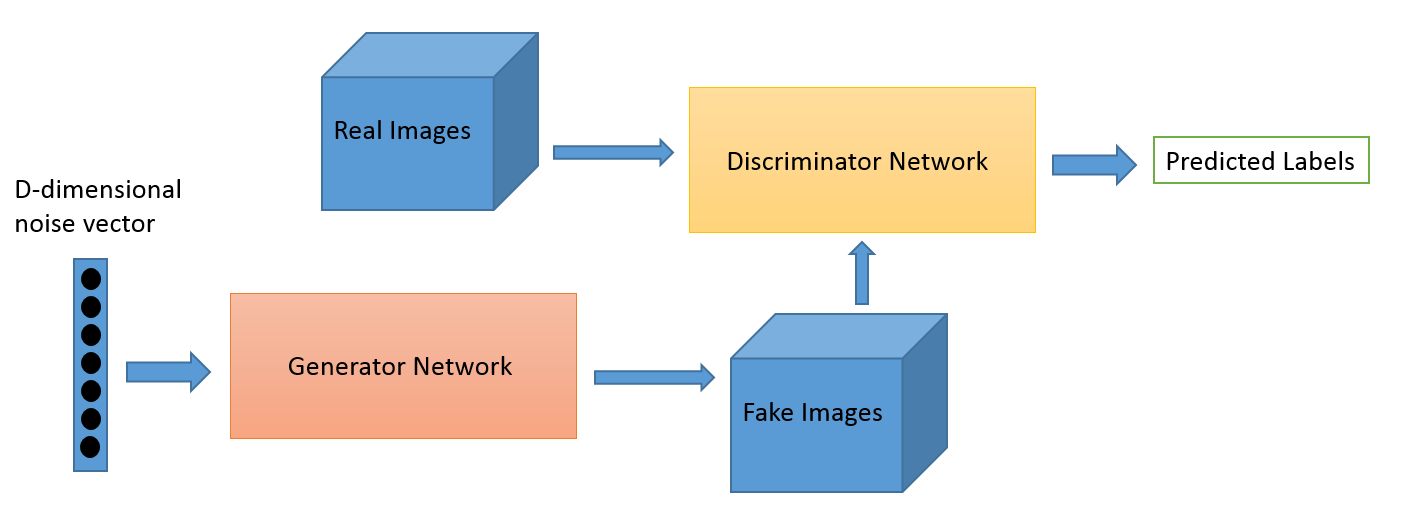
Состязательное обучение как область развилась из исследовательской работы Яна Гудфеллоу. Хотя наиболее популярными приложениями состязательного обучения, без сомнения, являются генеративно-состязательные сети (GAN), которые можно использовать для создания потрясающих изображений, существует множество других способов использования этого набора методов. Обычно эта техника, вдохновленная теорией игр, имеет два алгоритма: генератор и дискриминатор, целью которых является обманывать друг друга во время обучения. Генератор можно использовать для создания новых новых изображений, как мы обсуждали, но он также может генерировать представления любых других данных, чтобы скрыть детали от дискриминатора. Именно поэтому эта концепция представляет для нас такой большой интерес.
Некоторые примеры
Это новая область, и способность генерировать изображения, вероятно, является тем, на чем сосредоточено большинство заинтересованных людей, таких как астрономы. Но мы считаем, что это также приведет к развитию новых вариантов использования, о чем мы расскажем позже.
Расскажи мне больше!
Игра с адаптацией домена может быть улучшена с помощью потери GAN. Вспомогательная потеря здесь — это система GAN вместо чистой классификации доменов, где дискриминатор пытается классифицировать, из какого домена пришли данные, а компонент генератора пытается обмануть его, представляя случайный шум как данные. По нашему опыту, это работает лучше, чем простая адаптация домена (которая также более неустойчива к коду).
Небольшое обучение
Что это?
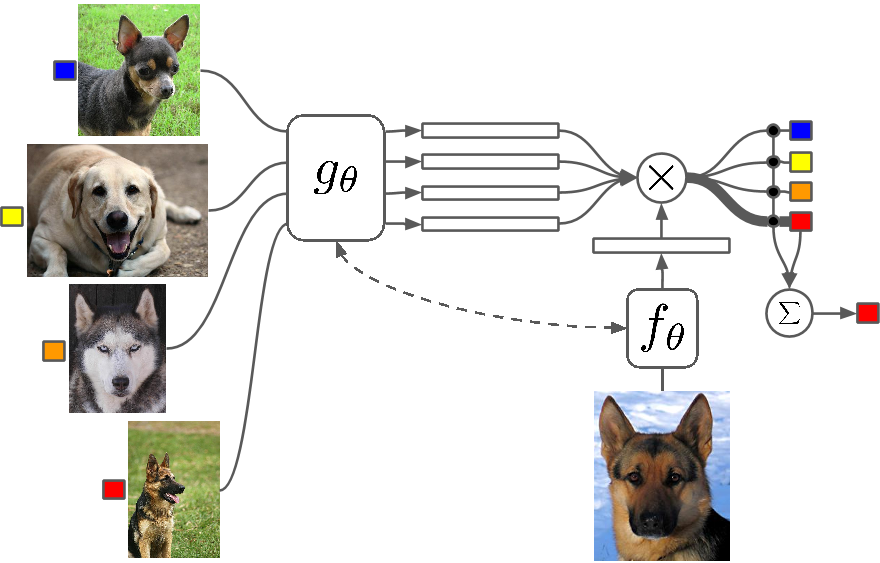
Few Shot Learning — это изучение методов, которые заставляют алгоритмы глубокого обучения (или любого алгоритма машинного обучения) обучаться с меньшим количеством примеров по сравнению с тем, что делает традиционный алгоритм. One Shot Learning — это, по сути, обучение с одним примером категории, индуктивное обучение k-shot означает обучение с k примерами каждой категории.
Некоторые примеры
В области Few Shot Learning появляется множество статей на всех крупных конференциях по глубокому обучению, и теперь есть специальные наборы данных для сравнения результатов, точно так же, как MNIST и CIFAR для обычного машинного обучения. One-shot Learning видит ряд приложений в определенных задачах классификации изображений, таких как обнаружение и представление функций.
Расскажи мне больше!
Существует несколько методов, которые используются для обучения Few Shot, включая трансферное обучение, многозадачное обучение, а также метаобучение как весь алгоритм или его часть. Есть и другие способы, такие как умная функция потерь, использование динамических архитектур или оптимизация. Zero Shot Learning, класс алгоритмов, которые утверждают, что предсказывают ответы для категорий, которые алгоритм даже не видел, — это, по сути, алгоритмы, которые могут масштабироваться с новым типом данных.
Метаобучение
Что это?

Мета-обучение — это именно то, на что это похоже: алгоритм, который обучается таким образом, что, увидев набор данных, он дает новый предиктор машинного обучения для этого конкретного набора данных. Определение очень футуристично, если вы посмотрите на него с первого взгляда. Вы чувствуете: «Вау! это то, что делает Data Scientist», и это автоматизация «самой привлекательной работы 21-го века», и в некотором смысле Meta-Learners начали делать это.
Некоторые примеры
В последнее время мета-обучение стало горячей темой в области глубокого обучения, и появилось множество исследовательских работ, в которых чаще всего используется метод оптимизации гиперпараметров и нейронных сетей, поиск хороших сетевых архитектур, распознавание изображений с несколькими выстрелами и быстрое обучение с подкреплением.
Расскажи мне больше!
Некоторые люди называют эту полную автоматизацию определения как параметров, так и гиперпараметров, таких как сетевая архитектура, autoML, и вы можете найти людей, ссылающихся на Meta Learning и AutoML как на разные области. Несмотря на всю шумиху вокруг них, правда в том, что Meta Learners по-прежнему являются алгоритмами и путями масштабирования машинного обучения с ростом сложности и разнообразия данных.
Большинство статей по мета-обучению представляют собой умные хаки, которые, согласно Википедии, обладают следующими свойствами:
- Система должна включать в себя обучающую подсистему, которая адаптируется с опытом.
- Опыт приобретается за счет использования метазнаний, извлеченных либо в предыдущем эпизоде обучения на одном наборе данных, либо из разных областей или проблем.
- Предвзятость обучения должна выбираться динамически.
Подсистема в основном представляет собой настройку, которая адаптируется, когда в нее вводятся метаданные домена (или совершенно нового домена). Эти метаданные могут рассказать об увеличении количества классов, сложности, изменении цветов и текстур и объектов (в изображениях), стилях, языковых шаблонах (естественный язык) и других подобных функциях. Ознакомьтесь с некоторыми супер классными статьями здесь: Метаобучение с общими иерархиями и Метаобучение с использованием временных сверток. Вы также можете создавать алгоритмы Few Shot или Zero Shot, используя архитектуру метаобучения. Мета-обучение — одна из самых многообещающих технологий, которая поможет сформировать будущее ИИ.
Нейронное мышление
Что это?

Нейронное мышление — следующая большая вещь в задачах классификации изображений. Нейронное мышление — это шаг вперед по сравнению с распознаванием образов, когда алгоритмы выходят за рамки простой идентификации и классификации текста или изображений. Нейронное мышление решает более общие вопросы текстовой или визуальной аналитики. Например, на изображении ниже представлен набор вопросов, на которые нейронное мышление может ответить с помощью изображения.
Расскажи мне больше!
Этот новый набор методов появится после выпуска набора данных Facebook bAbi или недавнего набора данных CLEVR. Методы, предназначенные для расшифровки отношений, а не только паттернов, обладают огромным потенциалом для решения не только нейронных рассуждений, но и многих других сложных проблем, включая проблемы с обучением.
Возвращаться
Теперь, когда мы знаем, что такое методы, давайте вернемся назад и посмотрим, как они решают основные проблемы, с которых мы начали. В таблице ниже представлены возможности методов эффективного обучения для решения проблем:
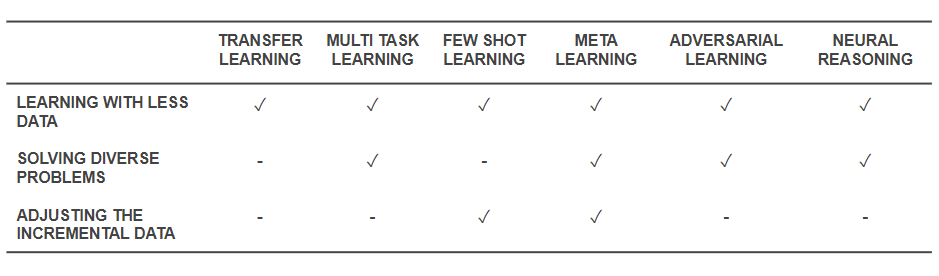
Возможности эффективных методов обучения
- Все упомянутые выше методы так или иначе помогают решить задачу обучения с меньшим объемом данных. В то время как метаобучение дает архитектуры, которые будут просто формироваться с данными, трансферное обучение делает знания из какой-то другой области полезными, чтобы компенсировать меньшее количество данных. Few Shot Learning посвящен проблеме как научной дисциплине. Состязательное обучение может помочь улучшить наборы данных.
- Адаптация предметной области (разновидность многозадачного обучения), состязательное обучение и (иногда) архитектуры метаобучения помогают решать проблемы, возникающие из-за разнообразия данных.
- Meta-Learning и Few Shot Learning помогают решить проблемы с добавочными данными.
- Алгоритмы нейронного мышления обладают огромным потенциалом для решения реальных проблем, если они используются в качестве мета-обучающихся или обучающихся с ограниченным доступом.
Обратите внимание, что эти методы эффективного обучения не являются новыми методами глубокого обучения/машинного обучения, а дополняют существующие методы в виде хаков , делая их более эффективными. Следовательно, вы по-прежнему увидите наши обычные инструменты, такие как сверточные нейронные сети и LSTM, в действии, но с добавлением специй. Эти методы эффективного обучения, которые работают с меньшим количеством данных и выполняют множество задач одновременно, могут упростить производство и коммерциализацию продуктов и услуг на основе ИИ. В ParallelDots мы признаем силу эффективного обучения и используем его в качестве одной из основных черт нашей исследовательской философии.
Этот пост Парта Шриваставы впервые появился в блоге ParallelDots и воспроизводится с его разрешения.