
Понимание алгоритмов Google NLP для лучшего SEO контента
Опубликовано: 2022-06-04
Обработка естественного языка, или НЛП, является одним из самых сложных и инновационных достижений в области искусственного интеллекта (ИИ) и алгоритмов поисковых систем. И неудивительно, что Google стал лидером в области НЛП. С добавлением в 2021 году алгоритма SMITH и предыдущего алгоритма естественного языка BERT компания Google разработала искусственный интеллект, который хорошо понимает человеческий язык. И эта технология может быть использована для создания контента с помощью ИИ.
Алгоритмы НЛП от Google с исключительной точностью изменили игру ИИ. Итак, что это означает для SEO? В этой статье мы подробно расскажем о технологиях NLP Google и о том, как их можно использовать для повышения рейтинга в результатах поиска.
Что такое обработка естественного языка?

Обработка естественного языка (NLP) — это область информатики и искусственного интеллекта, изучающая, как заставить компьютеры понимать человеческий язык. В отличие от предыдущих форм ИИ, НЛП использует глубокое обучение.
НЛП считается важным компонентом искусственного интеллекта, поскольку оно позволяет компьютерам взаимодействовать с людьми так, как это кажется естественным.
Хотя может показаться, что НЛП предназначено для улучшения результатов поиска Google и избавления писателей от бизнеса, эта технология используется в самых разных целях, помимо SEO.
Вот наиболее распространенные:
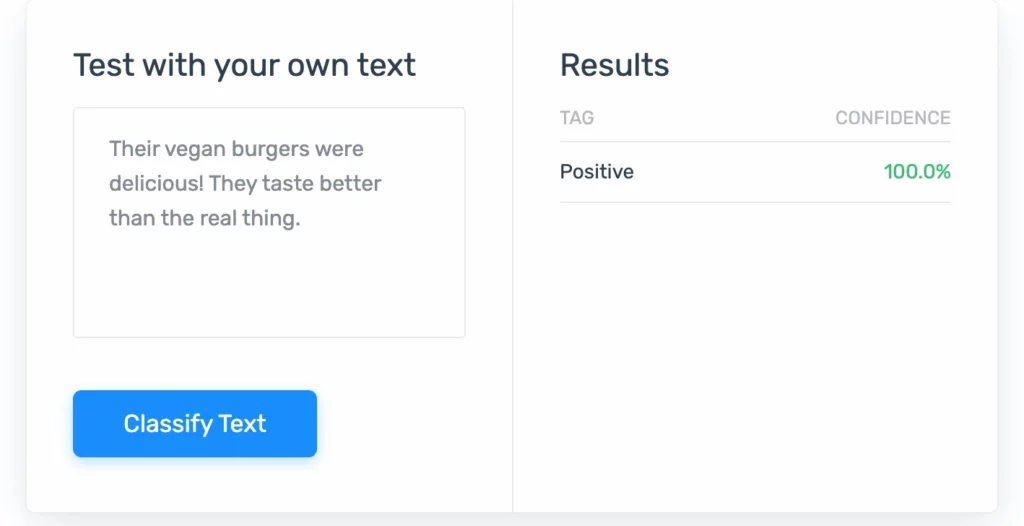
1. Анализ настроений: НЛП, которое измеряет эмоциональный уровень людей, чтобы определить такие вещи, как удовлетворенность клиентов.
2. Чат-боты: это экраны чата, которые появляются на страницах справки или на общих веб-сайтах. У них есть умение снижать нагрузку на центры поддержки клиентов.

4. Распознавание речи. НЛП берет звук и переводит его в команды и многое другое.

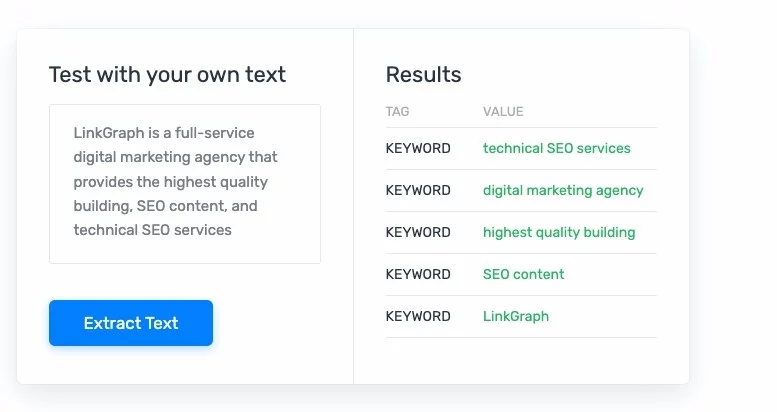
Классификация текста, извлечение и обобщение: эти формы НЛП могут анализировать текст, а затем переформатировать его, чтобы людям было легче использовать, анализировать и понимать. Извлечение текста может быть весьма полезным, когда речь идет о таких задачах, как медицинское кодирование и выявление ошибок при выставлении счетов.
Что такое глубокое обучение?

Глубокое обучение — это категория машинного обучения, которая моделируется нейронными сетями в человеческом мозгу. Эта форма машинного обучения часто считается более сложной, чем типичные модели обучения ИИ.
Поскольку они отражают человеческий мозг, они также могут отражать человеческое поведение — и многому учатся! Часто алгоритмы глубокого обучения используют систему из двух частей. Одна система делает прогнозы, а другая уточняет результаты.
Глубокое обучение уже некоторое время используется в бытовых устройствах, общественных местах и на рабочем месте. К наиболее распространенным приложениям относятся:
- Беспилотные автомобили
- Голосовые пульты
- Обнаружение мошенничества с кредитными картами
- Медицинское оборудование
- Спутниковая национальная оборона
Как НЛП влияет на SEO?

Несколько обновлений Google PageRank нарушили стандарты SEO, такие как боты, обрабатывающие естественный язык. С запуском SMITH от Google мы увидели, как специалисты по поисковой оптимизации изо всех сил пытались понять, как работает алгоритм, а также как создавать контент, соответствующий стандартам алгоритма. Однако, как и в большинстве обновлений алгоритмов, время часто показывает, как соответствовать стандартам контента и превосходить их, чтобы гарантировать, что ваш контент имеет наилучшие шансы попасть в поисковую выдачу.
По сути, НЛП помогает Google предоставлять пользователям более качественные результаты поиска в зависимости от их намерений и более четкого понимания содержания сайта. Это означает, что только те сайты, которые предоставляют лучший контент, занимают свои позиции в поисковой выдаче. Кроме того, различный контент, который не соответствует намерениям искателя, будет скрыт в более глубокой поисковой выдаче или вообще не будет отображаться.
Что такое Google BERT?

Алгоритм BERT (представления двунаправленного кодировщика от трансформеров) был развернут в 2019 году и произвел фурор как самое большое изменение со времен PageRank. Этот алгоритм представляет собой НЛП, который работает для понимания текста, чтобы обеспечить превосходные результаты поиска.
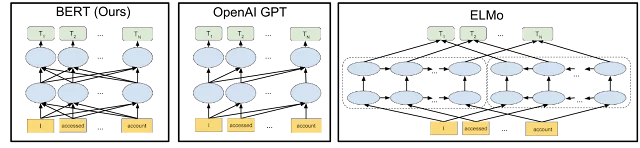
В частности, BERT — это нейронная сеть, предназначенная для лучшего понимания контекста слов в предложении. Алгоритм может изучать отношения между словами в предложении с помощью метода, называемого предварительным обучением.
Целью алгоритма BERT является повышение точности задач обработки естественного языка, таких как машинный перевод и ответы на вопросы.
Как работает алгоритм Google BERT?
Алгоритм BERT может достичь своей цели, используя технику, называемую трансферным обучением. Трансферное обучение — это метод, который используется для повышения точности нейронной сети с использованием предварительно обученной сети, которая уже обучена на большом наборе данных.
В отличие от многих обновлений Google, внутренняя работа BERT открыта. Алгоритм BERT основан на документе, опубликованном Google в 2018 году. Это объяснение с открытым исходным кодом включает в себя то, что BERT использует двунаправленную контекстную модель для лучшего понимания значения отдельных слов или фраз. Результатом является точно настроенная классификация контента.
Например:
Если вы ищете бар для счастливого часа, а не бар для вашего оборудования для жима лежа, Google покажет вам правильный тип бара в зависимости от того, как это слово используется в контексте на странице.
Что еще отличает BERT?
BERT использовал облачные тензорные процессоры (TPU) , которые ускорили способность NLP учиться на существующих образцах текста в качестве системы предварительного обучения. Предварительное обучение — это метод, который используется для обучения нейронной сети на большом наборе данных, прежде чем она будет использоваться для обработки данных. Затем предварительно обученная сеть используется для обработки данных, аналогичных тем, которые использовались для обучения сети. Используя облачные TPU, BERT смог обрабатывать данные быстро, очень быстро. И Google Cloud также удалось протестировать.
После миллионов тренировок алгоритм BERT способен достичь более высокой точности, чем предыдущие алгоритмы обработки естественного языка, поскольку он способен лучше понимать контекст слов в предложении.
Сколько образцов текста потребовалось BERT? BERT использовал миллионы, даже миллиарды образцов, чтобы полностью понять естественный язык (не только английский).
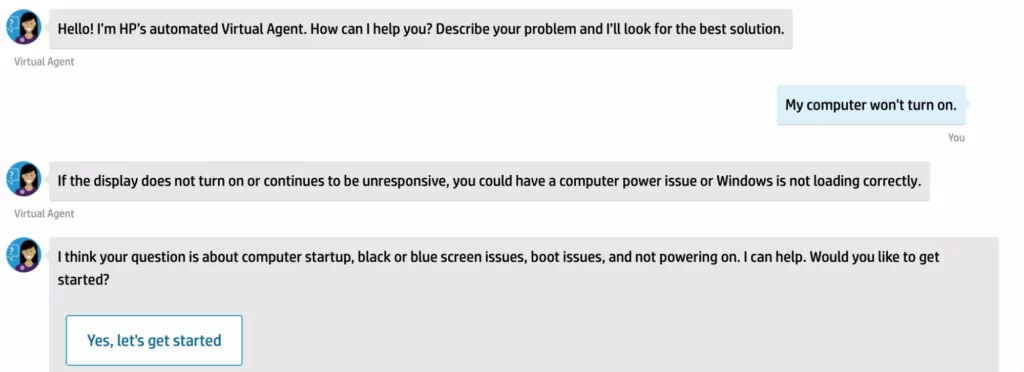
Как обновление Берта от Google повлияло на веб-сайты?
Влияние обновления BERT на веб-сайты было двояким. Во-первых, обновление повысило точность результатов поиска Google. Это означало, что веб-сайты, занимавшие более высокие позиции в результатах поиска Google, имели более высокий рейтинг кликов (CTR).

Во-вторых, обновление BERT повысило важность контента веб-сайта. Это означает, что веб-сайты с высококачественным релевантным контентом с большей вероятностью будут занимать более высокие позиции в результатах поиска Google.
Каковы ограничения Google Bert?

BERT — мощный инструмент, но его возможности имеют некоторые ограничения. Хотя легко увлечься точностью этой модели НЛП, важно помнить, что модель BERT не способна учитывать все когнитивные процессы человека. И это могут быть ограничения в его возможностях понимания контента.
BERT — это текстовый алгоритм
Во-первых, BERT эффективен только для задач обработки естественного языка, которые включают текст. Его нельзя использовать для задач, связанных с изображениями или другими формами данных. Однако имейте в виду, что BERT может читать ваш замещающий текст , что может помочь вам появиться в результатах поиска изображений Google.
BERT не понимает «всей картины»
Во-вторых, BERT неэффективен для задач, требующих очень высокой степени понимания. По сути, BERT отлично разбирается в словах внутри предложений, но не способен понимать целые статьи.
Например, BERT может понять, что «летучая мышь» в следующем предложении относится к млекопитающему, а не к деревянной бейсбольной бите: Летучая мышь съела комара. Но он не эффективен для задач, требующих понимания сложных предложений или абзацев.
Что такое алгоритм Google SMITH?

Алгоритм Google SMITH (или Siamese Multi-depth Transformer-based Hierarchical) — это алгоритм ранжирования, разработанный инженерами Google. Алгоритм анализирует естественный язык, изучает модели значений фраз в зависимости от их расстояния друг от друга и создает иерархию информации, которая позволяет более точно индексировать страницы.
Это позволяет SMITH более эффективно выполнять классификацию контента.
Еще одна интересная особенность SMITH заключается в том, что он может работать как предсказатель текста. Есть и другие компании, которые наделали много шума с помощью НЛП (вспомните печально известную бета-версию Open AI GPT-3 в прошлом году). Некоторые из этих технологий могли бы помочь другим в создании собственных поисковых систем .
Как обновление SMITH от Google повлияло на веб-сайты?
Обновление SMITH от Google оказало значительное влияние на веб-сайты. Обновление было разработано для повышения точности результатов поиска, и оно сделало это путем наказания веб-сайтов, которые использовали методы манипулирования, чтобы повлиять на их рейтинг. Разработанный для борьбы с широким спектром манипулятивных методов, включая спам-ссылки, черную поисковую оптимизацию и искусственный интеллект, SMITH поднял планку качества контента и создания органических ссылок.
Некоторые из наиболее распространенных манипулятивных техник, на которые ориентировался СМИТ, включали:
- наполнение ключевыми словами
- покупка ссылок
- чрезмерное использование анкорного текста.
Веб-сайты, которые, как было обнаружено, использовали эти методы, были оштрафованы Google, что привело к снижению их поискового рейтинга.
В чем разница между обновлением Google SMITH и Google BERT?

Как модель BERT, так и модель SMITH предоставляют поисковым роботам Google лучшее понимание языка и индексацию страниц. Мы знаем, что Google уже любит длинный контент, но когда SMITH работает, Google понимает более длинный контент еще эффективнее. SMITH улучшит области рекомендаций по новостям, рекомендаций по связанным статьям и кластеризации документов.
Как настроить свою SEO-стратегию для алгоритмов Google NLP
Хотя Google утверждает, что вы не можете оптимизировать для BERT или SMITH, понимание того, как оптимизировать NLP, может повлиять на производительность вашего сайта в поисковой выдаче. Однако знание того, что BERT фокусируется на обеспечении намерения пользователя, означает, что вы должны понимать намерение любого поискового запроса, для которого хотите оптимизировать.
Google часто немного уклончив в отношении того, когда они внедряют свои алгоритмы, и они продолжают скрывать, когда SMITH будет полностью развернут. Но всегда лучше предположить, что они начали оптимизировать изменения.
SMITH, вероятно, является лишь одной из многих итераций долгосрочной цели Google по сохранению своего доминирования в области НЛП и технологий машинного обучения. По мере того, как Google совершенствует свое понимание полных документов, хорошая информационная архитектура будет иметь еще большее значение .
Как вы можете оптимизировать свой контент для алгоритмов НЛП Google?

- Убедитесь, что ваш контент хорошо отформатирован и легко читается. Поддерживайте лучшие практики заголовков и другие лучшие практики читабельности. Это включает:
- Старайтесь, чтобы ваши предложения не превышали 20 слов.
- Используйте маркированные списки для перечисленных элементов больше 2
- Используйте правильную иерархию заголовков
- Избегайте предоставления читателям непроницаемого блока текста.
- Используйте четкий, лаконичный язык, который легко понять. Не слишком усложняйте структуру предложений. Ограничив длину предложения, вы, вероятно, также упорядочите свои мысли.
- Избегайте использования сложных или трудных слов, которые могут запутать алгоритмы Google. Откажитесь от тезауруса и пишите предложения прямо. Имейте в виду, что кратчайший путь к чему-то часто оказывается лучшим.
- Используйте ключевые слова и основные термины, которые имеют отношение к вашей теме . Семантически связанные термины Focus могут помочь обработчикам естественного языка Google лучше понять всю вашу страницу.
- Убедитесь, что ваш контент свежий и актуальный. Помните, что мотивацией этих алгоритмов НЛП является улучшение результатов поиска при отсеивании спама и устаревшего контента.
- Пишите интересный и увлекательный контент, который люди захотят прочитать. Вы никогда не ошибетесь, предоставив поисковикам лучший контент для их нужд . Помните о целях поиска и тематической глубине.
- Отзывы ваших клиентов имеют значение. НЛП Google, вероятно, может выполнять анализ настроений сущностей, поэтому не игнорируйте плохие отзывы. Если вы получаете негативные отзывы (будь то на английском языке или на марсианском языке), вы можете поспорить, что анализ настроений сущностей Google опустит вас вниз в поисковой выдаче.
- Дайте четкие ответы на вопросы поисковиков. Если вы хотите попасть в избранный фрагмент, НЛП Google доставят вас туда только в том случае, если вы выполните извлечение текста с использованием анализа сущностей. Это означает, что у Google есть возможность оттачивать конкретную информацию для отображения пользователям, выполняющим поиск.
Будущее Google NLP
Google Natural Language API и облачный TPU теперь доступны для всех . Таким образом, если вы можете использовать платформу машинного обучения для выполнения задач NLP, вы можете использовать API естественного языка Google. Вы даже можете принять участие в обучении Google Cloud NLP , если хотите!
Оптимизируйте для Google Natural Language API и получите результаты
Ясно одно: API на естественном языке никуда не денутся. Как видно из эволюции модели BERT и модели SMITH, алгоритмы поиска Google будут продолжать понимать ваш контент все лучше и лучше.
Пусть ваша мантра останется прежней: сосредоточьтесь на содержании, сосредоточьтесь на качестве. В то время как SEO-специалисты будут продолжать учиться и экспериментировать, чтобы выяснить, что лучше всего работает для алгоритмов Google NLP, всегда придерживайтесь лучших практик для SEO. Имейте в виду, что то, что вы пишете, повлияет на ваш рейтинг, но то, что пишут ваши клиенты и посетители, также повлияет благодаря анализу настроений. Узнайте больше об алгоритме BERT.
Инструмент SearchAtlas для генерации контента AI создан на основе Google Natural Language API, поэтому вы можете создавать контент самого высокого качества с меньшими усилиями.