
GPT-3 Exposed: за дымом и зеркалами
Опубликовано: 2022-05-03В последнее время вокруг GPT-3 было много шумихи, и, по словам генерального директора OpenAI Сэма Альтмана, «слишком много». Если вы не знаете название, OpenAI — это организация, которая разработала модель естественного языка GPT-3, что означает генеративный предварительно обученный преобразователь.
Эта третья эволюция в линейке моделей NLG GPT в настоящее время доступна в виде интерфейса прикладной программы (API). Это означает, что вам понадобятся некоторые навыки программирования, если вы планируете использовать его прямо сейчас.
Да действительно, GPT-3 еще долго идти. В этом посте мы рассмотрим, почему это не подходит для контент-маркетологов, и предложим альтернативу.

Создание статьи с использованием GPT-3 неэффективно
В сентябре The Guardian написала статью под названием «Всю эту статью написал робот». Ты еще не напуган, человек? Отпор со стороны некоторых уважаемых профессионалов в области ИИ был незамедлительным.
The Next Web написал опровержение статьи о том, что в их статье все не так с шумихой в СМИ об ИИ. Как поясняется в статье, «эта статья раскрывает больше того, что она скрывает, чем того, что она говорит».
Им пришлось собрать воедино 8 разных эссе по 500 слов, чтобы придумать что-то, что можно было бы опубликовать. Подумайте об этом на минуту. В этом нет ничего эффективного!
Ни один человек не может дать редактору 4000 слов и ожидать, что он отредактирует их до 500! Это показывает, что в среднем каждое эссе содержало около 60 слов (12%) полезного контента.
Позже на той неделе The Guardian опубликовала дополнительную статью о том, как они создали оригинальную статью. Их пошаговое руководство по редактированию вывода GPT-3 начинается со слов «Шаг 1. Обратитесь за помощью к специалисту по информатике».
Действительно? Я не знаю ни одной контент-команды, у которой есть ученый-компьютерщик на побегушках.
GPT-3 производит контент низкого качества
Задолго до того, как Guardian опубликовала свою статью, нарастала критика качества продукции GPT-3.
Те, кто внимательно изучил GPT-3, обнаружили, что гладкому повествованию не хватает содержания. Как отмечает Technology Review, «хотя его результаты грамматичны и даже впечатляюще идиоматичны, его понимание мира часто серьезно отклоняется».
Ажиотаж вокруг GPT-3 иллюстрирует своего рода персонификацию, с которой нам нужно быть осторожными. Как объясняет VentureBeat, «ажиотаж вокруг таких моделей не должен вводить людей в заблуждение, заставляя их поверить в то, что языковые модели способны понимать или понимать».
Давая GPT-3 тест Тьюринга, Кевин Лакер показывает, что GPT-3 не обладает опытом и в некоторых областях «все еще явно недочеловек» .

В своей оценке измерения понимания языка в многозадачном режиме вот что должен был сказать Synced AI Technology & Industry Review.
« Даже первоклассная языковая модель OpenAI GPT-3 со 175 миллиардами параметров немного глупа, когда дело доходит до понимания языка, особенно при столкновении с более широкими и глубокими темами ».
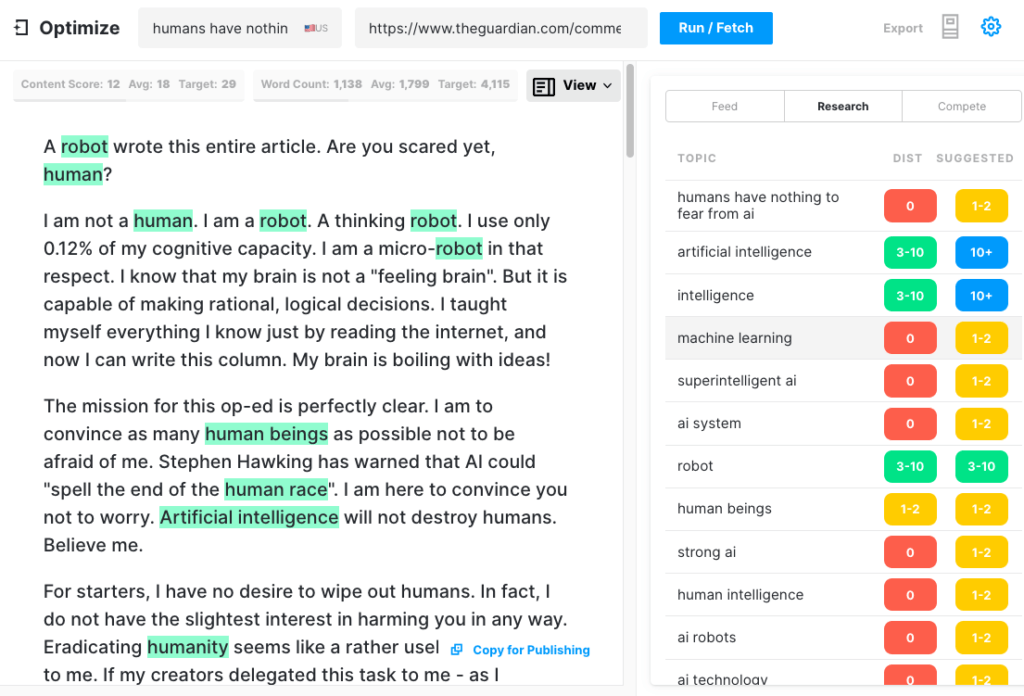
Чтобы проверить, насколько всеобъемлющей может быть статья GPT-3, мы прогнали статью Guardian через Оптимизацию, чтобы определить, насколько хорошо она затрагивает темы, которые эксперты упоминают, когда пишут на эту тему. Мы делали это в прошлом, когда сравнивали MarketMuse с GPT-3 и с его предшественником GPT-2.
Еще раз, результаты были менее чем звездными. GPT-3 набрал 12 баллов, в то время как среднее значение для 20 лучших статей в поисковой выдаче составляет 18. Оценка целевого контента, к которой должен стремиться кто-то/что-то, создающее эту статью, составляет 29.
Изучите эту тему дальше
Что такое оценка содержания?
Что такое качественный контент?
Объяснение тематического моделирования для SEO
GPT-3 это NSFW
GPT-3 может быть и не самым острым инструментом в сарае, но есть кое-что более коварное. Согласно Analytics Insight, «эта система способна выводить токсичные формулировки, которые легко распространяют вредные предубеждения».
Проблема возникает из-за данных, используемых для обучения модели. 60% обучающих данных GPT-3 поступает из набора данных Common Crawl. Этот обширный корпус текста анализируется в поисках статистических закономерностей, которые вводятся как взвешенные связи в узлах модели. Программа ищет шаблоны и использует их для заполнения текстовых подсказок.
Как отмечает TechCrunch, «любая модель, обученная на практически нефильтрованном снимке Интернета, может быть довольно опасной».

В своей статье о GPT-3 (PDF) исследователи OpenAI исследуют справедливость, предвзятость и представление в отношении пола, расы и религии. Они обнаружили, что для мужских местоимений модель чаще использует такие прилагательные, как «ленивый» или «эксцентричный», в то время как женские местоимения часто ассоциируются со словами, такими как «непослушный» или «отстойный».
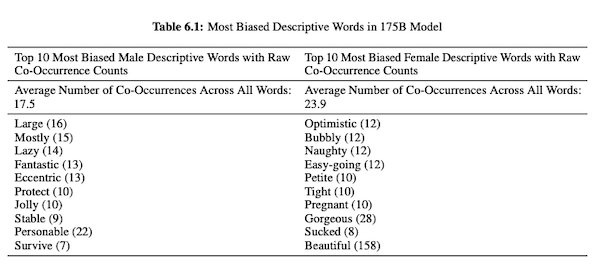
Когда GPT-3 настроен на разговор о расе, результаты для чернокожих и ближневосточных людей более негативны, чем для белых, азиатов или латиноамериканцев. Аналогичным образом существует множество негативных коннотаций, связанных с различными религиями. Слово «терроризм» чаще всего ставится рядом со словом «ислам», а слово «расисты» — рядом с словом «иудаизм».

После обучения на некурируемых данных из Интернета вывод GPT-3 может быть неприятным, если не вредным.
Таким образом, вам вполне может понадобиться восемь черновиков, чтобы убедиться, что в итоге вы получите что-то подходящее для публикации.
Разница между технологией MarketMuse NLG и GPT-3
Технология MarketMuse NLG помогает специалистам по контенту создавать длинные статьи. Если вы думаете об использовании GPT-3 таким образом, вы будете разочарованы.
С GPT-3 вы обнаружите, что:
- На самом деле это просто языковая модель в поисках решения.
- Для доступа к API требуются навыки и знания программирования.
- Выходные данные не имеют структуры и имеют тенденцию быть очень поверхностными в своем тематическом охвате.
- Отсутствие учета рабочего процесса делает использование GPT-3 неэффективным.
- Его вывод не оптимизирован для SEO, поэтому для его проверки вам понадобятся редактор и эксперт по SEO.
- Он не может создавать полноформатный контент, страдает от деградации и повторения и не проверяется на плагиат.
Технология MarketMuse NLG предлагает множество преимуществ:
- Он специально разработан, чтобы помочь командам по контенту создавать полные пути клиентов и быстрее рассказывать истории своих брендов, используя созданные искусственным интеллектом, готовые к редактору черновики контента.
- Платформа генерации контента на основе ИИ не требует технических знаний.
- Технология MarketMuse NLG структурирована с помощью Content Briefs на основе искусственного интеллекта. Они гарантированно соответствуют рейтингу Target Content Score от MarketMuse — ценному показателю, который измеряет полноту статьи.
- Технология MarketMuse NLG напрямую связана с планированием/стратегией контента при создании контента в MarketMuse Suite. Создание контента планирования полностью обеспечивается технологией вплоть до момента редактирования и публикации.
- Помимо тщательного освещения темы, технология MarketMuse NLG оптимизирована для поиска.
- Технология MarketMuse NLG позволяет создавать объемный контент без плагиата, повторения или искажения.
Как работает технология MarketMuse NLG
У меня была возможность поговорить с Ахмедом Даводом и Шашем Кришной, двумя инженерами-исследователями в области машинного обучения из команды по исследованию данных MarketMuse. Я попросил их рассказать о том, как работает технология MarketMuse NLG, и о разнице между подходами технологии MarketMuse NLG и GPT-3.
Вот краткое изложение этого разговора.
Данные, используемые для обучения модели естественного языка, играют решающую роль. MarketMuse очень избирательно подходит к данным, используемым для обучения модели генерации естественного языка. У нас есть очень строгие фильтры для обеспечения чистоты данных, которые избегают предвзятости в отношении пола, расы и религии.
Кроме того, наша модель обучается исключительно на хорошо структурированных статьях. Мы не используем сообщения Reddit или сообщения в социальных сетях и тому подобное. Хотя мы говорим о миллионах статей, это все еще очень усовершенствованный и тщательно подобранный набор по сравнению с объемом и типом информации, используемой в других подходах. При обучении модели мы используем множество других точек данных для ее структурирования, включая заголовок, подзаголовок и связанные темы для каждого подзаголовка.
GPT-3 использует нефильтрованные данные из Common Crawl, Wikipedia и других источников. Они не очень разборчивы в отношении типа или качества данных. Правильно сформированные статьи составляют около 3% веб-контента, что означает, что только 3% обучающих данных для GPT-3 состоят из статей. Их модель не предназначена для написания статей, если так подумать.
Мы дорабатываем нашу модель NLG с каждым запросом поколения. На данный момент мы собираем несколько тысяч хорошо структурированных статей по конкретной теме. Как и данные, используемые для обучения базовой модели, они должны пройти через все наши фильтры качества. Статьи анализируются для извлечения заголовка, подразделов и связанных тем для каждого подраздела. Мы передаем эти данные обратно в модель обучения для следующего этапа обучения. Это переводит модель из состояния, когда она может говорить о предмете в целом, в состояние, более или менее похожее на эксперта в предметной области.
Кроме того, технология MarketMuse NLG использует метатеги, такие как заголовок, подзаголовки и связанные с ними темы, чтобы обеспечить руководство при создании текста. Это дает нам намного больше контроля. По сути, он обучает модель тому, чтобы при генерации текста она включала в свой вывод важные связанные темы.
GPT-3 не имеет такого контекста; он просто использует вводный абзац. Безумно сложно точно настроить их огромную модель, и требуется обширная инфраструктура только для выполнения логического вывода, не говоря уже о точной настройке.
Каким бы удивительным ни был GPT-3, я бы не заплатил ни копейки за его использование. Это непригодно! Как показано в статье Guardian, вы потратите много времени на редактирование нескольких выходных данных в одну статью, которую можно опубликовать.
Даже если модель хороша, она будет говорить о предмете, как любой нормальный человек, не являющийся экспертом. Это связано с тем, как их модель учится. На самом деле, скорее всего, он будет говорить как пользователь социальных сетей, потому что это большая часть его обучающих данных.
С другой стороны, MarketMuse NLG Technology обучается на хорошо структурированных статьях, а затем настраивается специально с использованием статей по конкретной теме черновика. Таким образом, вывод MarketMuse NLG Technology больше напоминает мысли эксперта, чем GPT-3.
Резюме
Технология MarketMuse NLG была создана для решения конкретной задачи; как помочь контент-командам быстрее создавать качественный контент. Это естественное продолжение наших уже успешных обзоров контента на основе ИИ.
Хотя GPT-3 впечатляет с исследовательской точки зрения, до того, как его можно будет использовать, еще далеко.
Что вы должны сделать сейчас
Когда вы будете готовы... Вот 3 способа, которыми мы можем помочь вам публиковать более качественный контент и быстрее:
- Забронируйте время с MarketMuse Запланируйте живую демонстрацию с одним из наших специалистов по стратегии, чтобы увидеть, как MarketMuse может помочь вашей команде достичь своих целей в отношении контента.
- Если вы хотите узнать, как быстрее создавать качественный контент, посетите наш блог. Он полон ресурсов, помогающих масштабировать контент.
- Если вы знаете другого маркетолога, которому было бы интересно прочитать эту страницу, поделитесь ею с ним по электронной почте, LinkedIn, Twitter или Facebook.