
Как использовать НЛП в контент-маркетинге
Опубликовано: 2022-05-02Крис Пенн, соучредитель Trust Insights, и соучредитель и директор по продуктам MarketMuse Джефф Койл обсуждают экономическое обоснование использования ИИ для маркетинга. После вебинара Пол принял участие в сеансе «спроси меня о чем угодно» в нашем сообществе Slack, The Content Strategy Collective (присоединяйтесь здесь). Вот заметки о вебинаре, за которыми следует стенограмма AMA.

Вебинар
Эта проблема
Со взрывом контента у нас появились новые посредники. Они не журналисты и не влиятельные лица в социальных сетях. Это алгоритмы; модели машинного обучения, которые диктуют все, что стоит между вами и вашей аудиторией.
Не учтите это, и ваш контент будет по-прежнему погрязать в безвестности.
Решение: обработка естественного языка
НЛП — это программирование компьютеров для обработки и анализа больших объемов данных на естественном языке. Это происходит из документов, чат-ботов, сообщений в социальных сетях, страниц вашего веб-сайта и всего остального, что по сути представляет собой набор слов. НЛП на основе правил появилось первым, но его вытеснила статистическая обработка естественного языка.
Как работает НЛП
Три основные задачи обработки естественного языка — это распознавание, понимание и генерация.
Распознавание . Компьютеры не могут обрабатывать текст, как люди. Они могут только читать числа. Итак, первый шаг — преобразование языка в формат, понятный компьютеру.
Понимание . Представление текста в виде чисел позволяет алгоритмам проводить статистический анализ, чтобы определить, какие темы чаще всего упоминаются вместе.
Генерация . После анализа и математического понимания следующим логическим шагом в НЛП является генерация текста. Машины можно использовать для выявления вопросов, на которые писатель должен ответить в своем содержании. На другом уровне искусственный интеллект может управлять сводками контента, которые дают дополнительные сведения о создании контента экспертного уровня.
Эти инструменты коммерчески доступны сегодня через MarketMuse. Помимо этого, есть модели генерации естественного языка, с которыми вы можете играть сегодня, но они не имеют коммерческого использования. Хотя технология MarketMuse NLG появится очень скоро.
Упомянутые дополнительные ресурсы
- Huggingface.co
- питон
- р
- Колаб
- Студия IBM Watson

АМА
Есть ли у вас какие-либо статьи или рекомендации веб-сайтов, чтобы не отставать от тенденций индустрии искусственного интеллекта?
Читайте академические исследования, опубликованные там. Такие сайты отлично справляются с освещением последних и лучших событий.
- KDNuggets.com
- На пути к науке о данных
- Каггл
Это и крупные исследовательские центры публикации в Facebook, Google, IBM, Microsoft и Amazon. Вы увидите множество отличных материалов, размещенных на этих сайтах.
«Я использую средство проверки плотности ключевых слов для всего своего контента. Насколько это далеко от разумной стратегии сегодня для SEO?»
Плотность ключевых слов — это, по сути, подсчет частоты терминов. Он имеет место для понимания очень грубой природы текста, но ему не хватает какого-либо семантического знания. Если у вас нет доступа к инструментам NLP, по крайней мере, посмотрите на такие вещи, как «люди также искали» в выбранном вами инструменте SEO.
Не могли бы вы привести несколько конкретных примеров того, как вы генерируете контент в… веб-страницы? Сообщения? твиты?
Проблема в том, что эти инструменты именно таковы — они инструменты. Это как, как вы приводите в действие шпатель? Это зависит от того, что вы готовите. Вы можете использовать его, чтобы помешивать суп, а также переворачивать блины. Способ начать работу с некоторыми из этих знаний зависит от вашего уровня технических навыков. Например, если вам удобно работать с блокнотами Python и Jupyter, вы можете буквально импортировать библиотеку трансформеров, загрузить текстовый файл обучения и сразу же начать генерацию. Я проделал это с твитами одного политика, и он начал выдавать твиты, которые положат начало Третьей мировой войне. Если вам технически некомфортно, начните искать такие инструменты, как MarketMuse. Я позволю Джеффу Койлу предложить варианты того, как средний маркетолог может начать работу.
Если вы посмотрите не только на инструменты, но и на стратегии, что может быть примером стратегии, которую вы могли бы реализовать, чтобы использовать эти знания?
Пара быстрых ответов предназначена для таких вещей, как метаописания, для классификации страниц или блоков контента в таксономию или для попыток угадать вопросы, на которые нужны ответы, но это действительно точечные решения. Большая стратегическая мудрость приходит, когда вы используете это, чтобы показать свои текущие сильные стороны, свои пробелы и то, где у вас есть импульс. Оттуда принятие решений о том, что создавать, обновлять, расширять, становится преобразующим для бизнеса. Теперь представьте, что вы делаете то же самое против конкурента. Нахождение их пробелов. вспенить, промыть, повторить.
Стратегия всегда основывается на цели. Какую цель вы пытаетесь достичь? Вы привлекаете поисковый трафик? Вы занимаетесь лидогенерацией? Вы занимаетесь пиаром? НЛП — это набор инструментов. Это похоже на то, что стратегия — это меню. Вы подаете завтрак, обед или ужин? Какие инструменты и рецепты вы используете, будет сильно зависеть от меню, которое вы подаете. Суповая кастрюля будет совершенно бесполезна, если вы готовите спанакопиту.
Что является хорошей отправной точкой для тех, кто хочет начать добычу данных для понимания?
Начните с научного метода.
- На какой вопрос вы хотите ответить?
- Какие данные, процессы и инструменты вам нужны, чтобы ответить на этот вопрос?
- Сформулируйте гипотезу, одно условие, доказуемое истинное или ложное утверждение, которое вы можете проверить.
- Контрольная работа.
- Проанализируйте свои тестовые данные.
- Уточните или отклоните гипотезу.
Для самих данных используйте нашу структуру данных 6C, чтобы оценить качество данных.
Каковы, по вашему мнению, основные намерения поисковых пользователей, которые маркетологи должны учитывать?
Этапы пути клиента. Наметьте клиентский опыт от начала до конца — осведомленность, внимание, вовлечение, покупка, владение, лояльность, евангелизация. Затем наметьте, какими могут быть намерения на каждом этапе. Например, при владении цели поиска, скорее всего, будут ориентированы на обслуживание. Например, «Как устранить треск в аэродромах». Задача состоит в том, чтобы собрать данные на каждом из этапов путешествия и использовать их для обучения/настройки.
Тебе не кажется, что это может быть немного изменчиво? Если нам нужно что-то более стабильное для автоматизации процесса, нам нужно обобщить вещи на более высоком уровне.
Как сказал Джефф Безос, сосредоточьтесь на том, что не меняется. Общий путь владения не сильно меняется — кто-то, недовольный своей пачкой жевательной резинки, испытает то же самое, что и тот, кто недоволен новым атомным авианосцем, который он ввел в эксплуатацию. Детали, конечно, меняются, но понимание того, какие типы данных и намерений жизненно важны для понимания того, где кто-то находится, эмоционально, в путешествии — и как они передают это в языке.
В какие подводные камни могут попасть люди, пытаясь классифицировать намерения пользователей?
Безусловно, предвзятость подтверждения. Люди будут проецировать свои собственные предположения на опыт клиентов и интерпретировать данные о клиентах с учетом собственных предубеждений. Я бы также посоветовал, насколько это возможно, использовать данные взаимодействия (открытые электронные письма, шаги в дверь, звонки в колл-центр и т. д.) как можно лучше, чтобы проверить их. Я знаю, что в некоторых местах, особенно в крупных организациях, большие поклонники моделирования структурированными уравнениями для понимания намерений пользователей. Я не был таким большим поклонником, как они, но это дополнительный потенциальный подход.
Какие инструменты или продукты, по вашему мнению, хорошо справляются с определением намерений пользователя в отношении запроса?
Гав. Кроме MarketMuse? Честно говоря, мне приходилось работать со своими собственными вещами, потому что я не нашел хороших результатов, особенно от основных инструментов SEO. FastText для векторизации, а затем неструктурированной кластеризации.
По вашему опыту, как BERT изменил Google Search?
Основным вкладом BERT является контекст, особенно с модификаторами. BERT позволяет Google видеть порядок слов и интерпретировать значение. До этого эти два запроса могли быть функционально эквивалентны в модели стиля «мешок слов»:
- где лучшая кофейня
- где лучше всего покупать кофе
Эти два запроса, хотя и очень похожи, могут иметь совершенно разные результаты. Кофейня может быть не тем местом, где вы хотите покупать бобы. Walmart — это ОПРЕДЕЛЕННО не то место, где вы хотите пить кофе.
Считаете ли вы, что ИИ или ИКТ когда-нибудь разовьют сознание/эмоции/эмпатию, как люди? Как мы будем их программировать? Как мы можем очеловечить ИИ?
Ответ на этот вопрос зависит от того, что происходит с квантовыми вычислениями. Quantum допускает переменные нечеткие состояния и массовые параллельные вычисления, которые имитируют то, что происходит в нашем собственном мозгу. Ваш мозг — это очень медленный массивный параллельный процессор, основанный на химических веществах. Очень хорошо делать кучу дел одновременно, если не быстро. Квант позволит компьютерам делать то же самое, но намного, намного быстрее — и это открывает двери для общего искусственного интеллекта. Вот моя проблема, и это проблема с ИИ уже сегодня, в узком смысле: мы обучаем их на основе нас самих. Человечество не проделало большой работы по хорошему обращению с собой или с планетой, на которой мы живем. Мы не хотим, чтобы наши компьютеры подражали этому.
Я подозреваю, что в той мере, в какой это позволяют системы, компьютерные эмоции будут функционально сильно отличаться от наших собственных и будут самоорганизовываться на основе их данных, точно так же, как наши — на основе наших химических нейронных сетей. Это, в свою очередь, означает, что они могут чувствовать себя совсем иначе, чем мы. Если машины, основанные главным образом на логике и данных, проведут беспристрастную и объективную оценку человечества, они могут, честно говоря, решить, что от нас больше проблем, чем пользы. И они не ошибутся, если честно. Мы, как вид, большую часть времени представляем собой варварский беспорядок.
Как, по вашему мнению, контент-маркетологи интегрируют/внедряют генерацию естественного языка в свой повседневный рабочий процесс/процессы?
Маркетологи уже должны интегрировать его в какой-то форме, даже если это просто ответы на вопросы, как мы продемонстрировали в продукте MarketMuse. Ответы на вопросы, которые, как вы знаете, волнуют аудиторию, — это быстрый и простой способ создать значимый контент. Мой друг Маркус Шеридан написал прекрасную книгу «Они спрашивают, вы отвечаете», которую, по иронии судьбы, вам на самом деле не нужно читать, чтобы понять основную стратегию работы с клиентами: отвечать на вопросы людей. Если у вас еще нет вопросов, отправленных реальными людьми, используйте NLG, чтобы задать их.
Каким вы видите развитие ИИ и НЛП в ближайшие 2 года?
Если бы я знал это, меня бы здесь не было, потому что я был бы в крепости на вершине горы, которую купил на свои заработки. Но, если серьезно, основной поворот, который мы наблюдали за последние 2 года и который не показывает никаких признаков изменений, — это переход от «создания собственных» моделей к «загрузке предварительно обученных и точных настроек». Я думаю, нас ждут захватывающие времена в области видео и аудио, поскольку машины совершенствуются в синтезе. Генерация музыки, в частности, созрела для автоматизации; прямо сейчас машины генерируют совершенно посредственную музыку в лучшем случае, а в худшем - болят уши. Это быстро меняется. Я вижу больше примеров, таких как смешивание трансформаторов и автоэнкодеров вместе, как это сделал BART, как важные следующие шаги в развитии модели и современных результатах.

Как вы видите направление исследований Google в отношении информационного поиска?
Проблема, с которой Google продолжает сталкиваться, и вы видите это во многих своих исследовательских работах, — это масштаб. Им особенно сложно работать с такими вещами, как YouTube; тот факт, что они по-прежнему в значительной степени полагаются на биграммы, не является ударом по их сложности, это признание того, что все, что больше, требует безумных вычислительных затрат. Любые крупные прорывы от них будут происходить не столько на уровне модели, сколько на уровне масштаба, чтобы справиться с потоком нового, богатого контента, который каждый день выливается в Интернет.
С какими наиболее интересными приложениями ИИ вы сталкивались?
Автономность всего — это область, за которой я внимательно слежу. Так же как и глубокие подделки. Это примеры того, насколько опасен путь впереди, если мы не будем осторожны. В частности, в НЛП генерация делает быстрые успехи, и за ней нужно следить.
Где вы видели, чтобы оптимизаторы использовали НЛП способами, которые не работают или не будут работать?
Я сбился со счета. В большинстве случаев люди используют инструмент не по назначению и получают некачественные результаты. Как мы упоминали на вебинаре, существуют оценочные листы для различных современных тестов для моделей, и люди, которые используют инструмент в слабой области, обычно не получают удовольствия от результатов. Тем не менее… большинство специалистов по поисковой оптимизации не используют никаких НЛП, кроме того, что им предоставляют поставщики, а многие поставщики все еще застряли в 2015 году. Это все списки ключевых слов, все время.
Где вы видите видео (YouTube) и поиск изображений в Google? Как вы думаете, технологии, развернутые Google для всех типов поиска, очень похожи или отличаются друг от друга?
Все технологии Google построены на основе их инфраструктуры и используют их технологии. Так много построено на TensorFlow, и не зря — он очень надежный и масштабируемый. В чем разница, так это в том, как Google использует различные инструменты. TensorFlow для распознавания изображений по своей сути имеет очень разные входные данные и слои, чем TensorFlow для попарного сравнения и языковой обработки. Но если вы знаете, как использовать TensorFlow и различные модели, вы можете самостоятельно добиться кое-чего интересного.
Каким образом мы можем адаптироваться/идти в ногу с достижениями в области ИИ и НЛП?
Продолжайте читать, исследовать и тестировать. Ничто не заменит испачкать руки, хотя бы немного. Зарегистрируйте бесплатную учетную запись Google Colab и попробуйте. Изучите немного Python. Скопируйте и вставьте примеры кода из Stack Overflow. Вам не нужно знать каждую внутреннюю работу двигателя внутреннего сгорания, чтобы водить машину, но когда что-то идет не так, немного знаний имеет большое значение. То же самое верно в отношении ИИ и НЛП — даже простое умение вызывать BS у поставщика является ценным навыком. Это одна из причин, по которой мне нравится работать с ребятами из MarketMuse. Они на самом деле знают, что делают, и их работа с искусственным интеллектом не является чушью.
Что бы вы сказали людям, которые обеспокоены тем, что ИИ лишит их работы? Например, писатели, которые видят такие технологии, как NLG, и беспокоятся, что останутся без работы, если ИИ окажется «достаточно хорошим», чтобы редактор просто немного подчистил текст.
«ИИ заменит задачи, а не рабочие места» — Институт Брукингса И это абсолютно верно. Но будут потеряны чистые рабочие места, потому что вот что произойдет. Предположим, ваша работа состоит из 50 задач. ИИ делает 30 из них. Отлично, теперь у вас есть 20 задач. Если вы единственный человек, который делает это, то вы в нирване, потому что у вас есть еще 30 единиц времени, чтобы делать более интересную и веселую работу. Это то, что обещают оптимисты ИИ. Проверка на практике: если 5 человек выполняют эти 50 единиц, а ИИ делает 30 из них, то теперь ИИ выполняет 150/250 единиц работы. Это означает, что людям осталось выполнить 100 единиц работы, а корпорации, как они есть, немедленно сократят 3 должности, потому что 100 единиц работы могут выполнять 2 человека. Стоит ли вам беспокоиться о том, что ИИ займет рабочие места? Это зависит от работы. Если работа, которую вы выполняете, невероятно повторяющаяся, очень беспокойтесь. В моем старом агентстве был бедолага, чья работа заключалась в том, чтобы копировать и вставлять результаты поиска в электронную таблицу для клиентов (я работал в PR-фирме, не самом технологичном месте) по 8 часов в день. Эта работа находится в непосредственной опасности, и, честно говоря, должна была быть в течение многих лет. Повторение = автоматизация = ИИ = потеря задачи. Чем меньше повторяющихся действий вы выполняете, тем в большей безопасности вы находитесь.
Каждое изменение также создавало все большее и большее неравенство в доходах. Сейчас мы находимся в опасной точке, когда машины — которые не тратят, не являются потребителями — выполняют все больше и больше работы людей, которые тратят, но потребляют, и мы видим это в массовом доминировании богатства в технологиях. Это социальная проблема, которую нам придется решить в какой-то момент.
И проблема в том, что прогресс — это сила. Как писал Роберт Ингерсолл (позже его ошибочно приписали Аврааму Линкольну): «Почти все люди могут выдержать невзгоды, но если вы хотите проверить характер человека, дайте ему власть». Мы видим, как люди сегодня обращаются с властью.
Как я могу связать данные Google Analytics с NLP Research?
ГА указывает направление, затем НЛП указывает на создание. Что популярно? Я только что сделал это для клиента некоторое время назад. У них тысячи веб-страниц и сеансов чата. Мы использовали GA, чтобы проанализировать, какие категории росли быстрее всего на их сайте, а затем использовали NLP для обработки этих журналов чата, чтобы показать им, что в тренде и о чем им нужно создавать контент.
Google Analytics отлично подходит для того, чтобы сообщить нам, ЧТО произошло. НЛП может начать немного выяснять ПОЧЕМУ, а затем мы завершаем это исследованием рынка.
Я видел, как ты использовал Talkwalker в качестве источника данных во многих своих исследованиях. Какие другие источники и варианты использования следует рассмотреть для анализа?
Итак, так много. Data.gov. Talkwalker. MarketMuse. Otter.ai за расшифровку вашего аудио. Ядра Kaggle. Поиск данных Google — который, кстати, является ЗОЛОТЫМ, и если вы его не используете, вам обязательно следует им пользоваться. Новости Google и GDELT. Там так много замечательных источников.
Как для вас выглядит идеальное сотрудничество между отделом маркетинга и аналитики данных?
Без шуток; Одна из самых больших ошибок, которые Кэти Робберт и я постоянно видим в работе с клиентами, — это организационная разрозненность. Левая рука понятия не имеет, что делает правая, и везде царит беспорядок. Собирать людей вместе, делиться идеями, делиться списками дел, проводить общие стендапы, обучать друг друга — функционально быть «одной командой, одной мечтой» — это идеальное сотрудничество, до такой степени, что вам больше не нужно использовать слово «сотрудничество». . Люди просто работают вместе и используют все свои навыки.
Можете ли вы просмотреть отчет MVP, который вы часто просматриваете в своих презентациях, и то, как он работает?
Отчет MVP обозначает наиболее ценные страницы. Он работает следующим образом: данные о пути извлекаются из Google Analytics, упорядочиваются, а затем проходят через модель цепи Маркова, чтобы определить, какие страницы с наибольшей вероятностью помогут конверсиям.
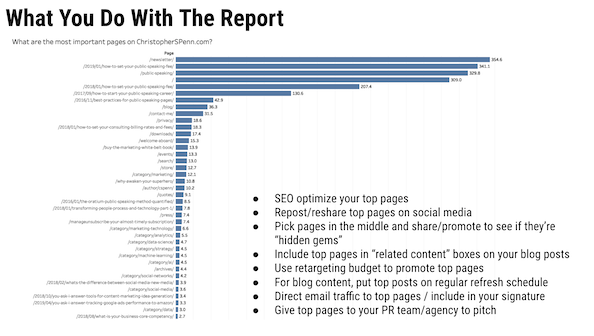
И если вы хотите более подробное объяснение.
Можете ли вы дать больше информации о предвзятости данных? Какие соображения следует учитывать при построении моделей NLP или NLG?
О, да. Здесь так много можно сказать. Во-первых, нам нужно установить, что такое предвзятость, потому что есть два основных вида.
Человеческое предубеждение обычно определяется как «предубеждение в пользу или против чего-либо по сравнению с другим, обычно таким образом, который считается несправедливым».
Кроме того, существует математическое смещение, которое обычно определяется как «Статистика является смещенной, если она рассчитывается таким образом, что она систематически отличается от оцениваемого параметра совокупности».
Они разные, но родственные. Математическая предвзятость не обязательно плоха; например, вы абсолютно хотите быть предвзятым в пользу ваших самых лояльных клиентов, если у вас есть хоть какое-то деловое чутье. Человеческая предвзятость неявно плоха в смысле несправедливости, особенно по отношению ко всему, что считается защищенным классом: возраст, пол, сексуальная ориентация, гендерная идентичность, раса / этническая принадлежность, статус ветерана, инвалидность и т. д. Это классы, которые вы НЕ ДОЛЖНЫ дискриминировать.
Человеческая предвзятость порождает предвзятость данных, как правило, в 6 местах: люди, стратегия, данные, алгоритмы, модели и действия. Мы нанимаем предвзятых людей — просто посмотрите на руководство или совет директоров компании, чтобы определить, какова их предвзятость. На днях я видел, как одно PR-агентство рекламировало свою приверженность разнообразию, и один щелчок мыши указывает на их исполнительную команду, и они представляют собой единую этническую принадлежность, все 15 человек.
Я мог бы продолжать ДОЛГО, но я предлагаю вам пройти курс, который я разработал по этой теме в Институте маркетингового ИИ. Что касается моделей NLG и NLP, нам нужно сделать несколько вещей.
Во-первых, мы должны проверить наши данные. Есть ли в этом предвзятость, и если да, то является ли она дискриминацией защищаемого класса? Во-вторых, если это дискриминация, можно ли смягчить ее или мы должны выбросить данные?
Распространенной тактикой является преобразование метаданных в debias. Если у вас есть, например, набор данных, в котором 60% мужчин и 40% женщин, вы перекодируете 10% мужчин в женщины, чтобы сбалансировать его для обучения модели. Это несовершенно и имеет некоторые проблемы, но это лучше, чем позволить предвзятости.
В идеале мы встроили интерпретируемость в наши модели, которые позволяют нам запускать проверки в процессе, а затем мы также проверяем результаты (объяснимость) постфактум. И то, и другое необходимо, если вы хотите пройти аудит, подтверждающий, что вы не встраиваете предубеждения в свои модели. Горе компании, у которой есть только апостериорные объяснения.
И, наконец, вам абсолютно необходим человеческий надзор за разнообразной и инклюзивной командой для проверки результатов. В идеале вы должны использовать третью сторону, но допустима и доверенная внутренняя сторона. Представляет ли модель и ее результаты искаженный результат, чем вы могли бы получить от самой популяции?
Например, если вы создавали контент для 16–22-летних и ни разу не встретили в сгенерированном тексте такие термины, как тупица, сырой, низкий ключ и т. д., вы не смогли зафиксировать какие-либо данные на входной стороне. это научит модель правильно использовать их язык.
Самая большая основная проблема здесь — справиться со всем этим с помощью неструктурированных данных. Вот почему родословная так важна. Без родословной вы не сможете доказать, что правильно отобрали население. Происхождение — это ваша документация о том, что является источником данных, откуда они взялись, как они были собраны, применимы ли к нему какие-либо нормативные требования или раскрытие информации.
Что вы должны сделать сейчас
Когда вы будете готовы... Вот 3 способа, которыми мы можем помочь вам публиковать более качественный контент и быстрее:
- Забронируйте время с MarketMuse Запланируйте живую демонстрацию с одним из наших специалистов по стратегии, чтобы увидеть, как MarketMuse может помочь вашей команде достичь своих целей в отношении контента.
- Если вы хотите узнать, как быстрее создавать качественный контент, посетите наш блог. Он полон ресурсов, помогающих масштабировать контент.
- Если вы знаете другого маркетолога, которому было бы интересно прочитать эту страницу, поделитесь ею с ним по электронной почте, LinkedIn, Twitter или Facebook.