
Выявление субъективных атрибутов сущностей
Опубликовано: 2022-05-13Выявление субъективных атрибутов пользовательского контента сущностей
Этот недавно выданный патент касается идентификации субъективных атрибутов сущностей.
Я не видел патента на субъективные атрибуты сущностей или ответы на эти сущности.
Важным аспектом этого является то, что это пользовательский контент.
Нам говорят, что пользовательский контент (UGC) становится все более распространенным в Интернете из-за растущей популярности социальных сетей, блогов, обзорных сайтов и т. д.
Мы часто видим пользовательский контент в виде комментариев, например:
- Комментарий первого пользователя о контенте, которым поделился второй пользователь в социальной сети.
- Комментарии пользователей в ответ на статью в блоге обозревателя
- Комментарий к видеоклипу, размещенному на контент-хостинге
- Обзоры (например, продуктов, фильмов)
- Действия (такие как Нравится!, Не нравится!, +1, обмен, добавление в закладки, плейлист и т. д.)
- Так далее
В соответствии с этим патентом предоставляется способ идентификации и прогнозирования субъективных атрибутов объектов (таких как медиаклипы, изображения, газетные статьи, записи в блогах, лица, организации, коммерческие предприятия и т. д.).
Это начинается с:
- Идентификация первого набора субъективных атрибутов для первого объекта на основе реакции на первый объект (например, комментарии на веб-сайте, демонстрация одобрения первого объекта (например, «Нравится!» и т. д.)
- Совместное использование первого объекта
- Закладка первого объекта
- Добавление первого объекта в список воспроизведения
- Обучение классификатора (такого как машина опорных векторов, AdaBoost, нейронная сеть, дерево решений на наборе отображений ввода-вывода, где набор отображений ввода-вывода включает отображение ввода-вывода, вход которого Предоставление вектора признаков для первого объекта, чьи выходные данные основаны на первом наборе субъективных атрибутов
- Предоставление вектора признаков для второго объекта обученному классификатору для получения второго набора субъективных атрибутов для второго объекта.
Память и процессор предоставляются для идентификации и прогнозирования субъективных атрибутов сущностей.
Машиночитаемый носитель данных содержит инструкции, которые заставляют компьютерную систему выполнять операции, в том числе:
- Идентификация первого набора субъективных атрибутов для первого объекта на основе реакции на первый объект
- Получение первого вектора признаков для первого объекта
- Обучение классификатора на наборе отображений ввода-вывода, при этом набор отображений ввода-вывода содержит отображение ввода-вывода, входные данные которого основаны на первом векторе признаков, а выходные данные основаны на первом наборе субъективных атрибутов.
- Получение второго вектора признаков для второго объекта
- Предоставление классификатору после обучения второго вектора признаков для получения второго набора субъективных атрибутов для второго объекта.
Этот патент на определение субъективных атрибутов объектов = находится по адресу:
Выявление субъективных атрибутов путем анализа сигналов курирования
Изобретатели: Хришикеш Арадье и Санкет Шетти.
Правопреемник: Google LLC
Патент США: 11 328 218
Выдано: 10 мая 2022 г.
Подано: 6 ноября 2017 г.
Абстрактный:
Раскрываются система и способ идентификации и прогнозирования субъективных атрибутов объектов (таких как медиаклипы, фильмы, телешоу, изображения, газетные статьи, записи в блогах, лица, организации, коммерческие предприятия и т. д.).
В одном аспекте субъективные атрибуты для первого элемента мультимедийных данных идентифицируются на основе реакции на первый элемент мультимедийных данных, и определяются оценки релевантности для личных качеств относительно первого элемента мультимедийных данных.
Классификатор обучается с использованием (i) входных данных для обучения, содержащих набор признаков для первого элемента мультимедиа, и целевых выходных данных для входных данных для обучения, при этом выходные данные содержат соответствующие оценки релевантности для субъективных атрибутов первого элемента мультимедиа.
Выявление и прогнозирование субъективных атрибутов сущностей
Способы идентификации и прогнозирования субъективных атрибутов объектов (таких как медиаклипы, изображения, газетные статьи, записи в блогах, лица, организации, коммерческие предприятия и т. д.).
Субъективные атрибуты (такие как «милый», «забавный», «крутой» и т. д.) определяются, а субъективные атрибуты для конкретного объекта идентифицируются на основе реакции пользователя на объект, например:
- Комментарии на веб-сайте
- Нравиться!
- Совместное использование первого объекта с другими пользователями
- Закладка первого объекта
- Добавление первого объекта в список воспроизведения
- И т.д
Оценки релевантности субъективных атрибутов определяются в отношении объекта
Если субъективный атрибут «милый» появляется в значительной части комментариев к видеоклипу, то «милый» может получить высокий балл релевантности.
Затем объект связывается с идентифицированными субъективными атрибутами и оценками релевантности (например, с помощью тегов, примененных к объекту, с помощью записей в таблице реляционной базы данных и т. д.).
Вышеупомянутая процедура выполняется для каждого объекта в заданном наборе объектов (например, видеоклипы в хранилище видеоклипов и т. д.), а обратное сопоставление субъективных атрибутов с объектами в группе создается на основе личных качеств и оценок релевантности. .
Затем обратное сопоставление можно использовать для идентификации всех сущностей в наборе, которые соответствуют заданному субъективному атрибуту (например, всем сущностям, связанным с субъективным атрибутом «забавный» и т. д.), что позволяет:
- Быстрое извлечение релевантных объектов для обработки поиска по ключевым словам
- Заполнение плейлистов
- Доставка рекламы
- Генерация обучающих наборов для классификатора
- Так далее
Классификатор (такой как машина опорных векторов [SVM], AdaBoost, нейронная сеть, дерево решений и т. д.) обучается, предоставляя набор обучающих примеров, где вход для обучающего примера содержит вектор признаков, полученный из конкретный объект (например, вектор признаков для видеоклипа.
Он может содержать числовые значения о:
- Цвет
- Текстура
- Интенсивность
- Теги метаданных, связанные с видеоклипом
- И т.д
Выходные данные имеют оценки релевантности для каждого субъективного атрибута в словаре для конкретного объекта.
Затем обученный классификатор может прогнозировать субъективные атрибуты объектов, не входящих в обучающий набор (например, недавно загруженный видеоклип, новостная статья, которая еще не получила комментариев и т. д.).
Этот патент может классифицировать объекты в соответствии с субъективными атрибутами, такими как «забавный», «милый» и т. д., на основе реакции пользователя на объекты.
Этот патент может улучшить качество описаний объектов, таких как теги для видеоклипа, повысить качество поиска и таргетинг рекламы.
Архитектура системы для определения субъективных атрибутов
Архитектура системы включает в себя:
- Серверная машина
- Магазин сущностей
- Клиентские машины подключены к сети
Сеть может быть общедоступной (такой как Интернет), частной сетью (такой как локальная сеть (LAN) или обширная сеть (WAN)) или их комбинацией.
Клиентскими машинами могут быть беспроводные терминалы (смартфоны и т. д.), персональные компьютеры (ПК), ноутбуки, планшетные компьютеры или любые другие вычислительные или коммуникационные устройства.
На клиентских машинах может работать операционная система (ОС), которая управляет аппаратным и программным обеспечением клиентских машин.
Браузер (не показан) может работать на клиентских машинах (например, в ОС клиентских машин).
Браузер может быть веб-браузером, который может получать доступ к веб-страницам и контенту, обслуживаемому веб-сервером.
Клиентские машины также могут загружать:
- веб-страница
- Медиа клипы
- Записи в блоге
- ссылки на статьи
- Так далее
Серверная машина включает в себя веб-сервер и диспетчер субъективных атрибутов. Веб-сервер и менеджер эмоциональных атрибутов могут работать на разных устройствах.
Хранилище сущностей — это постоянное хранилище, способное хранить такие объекты, как медиаклипы (например, видеоклипы, аудиоклипы, клипы, содержащие как видео, так и аудио, изображения и т. д.) и другие типы элементов контента (например, веб-страницы, текстовые файлы). на основе документов, обзоров ресторанов, обзоров фильмов и т. д.), а также структуры данных для маркировки, организации и индексации сущностей.
Хранилище сущностей может размещаться на устройствах хранения, таких как оперативная память, магнитные или оптические накопители, ленты или жесткие диски, NAS, SAN и т. д.
Хранилище сущностей может размещаться на сетевом файловом сервере. Напротив, в других реализациях хранилище сущностей может размещаться в каком-либо другом типе постоянного хранилища, таком как серверная машина или другие машины, связанные с серверной машиной через сеть.
Сущности, хранящиеся в хранилище сущностей, могут включать пользовательский контент, загружаемый клиентскими машинами, и могут включать контент, предоставляемый поставщиками услуг, например:
- Новостные организации
- Издатели
- Библиотеки
- Скоро
Сервер может обслуживать веб-страницы и контент из хранилищ сущностей клиентам.
Менеджер субъективных атрибутов:
- Определяет субъективные атрибуты объектов на основе реакции пользователя (такие как комментарии, лайки!, совместное использование, добавление в закладки, плейлисты и т. д.)
- Определяет оценки релевантности для субъективных атрибутов сущностей
- Связывает субъективные атрибуты и оценки релевантности с сущностями
- Извлекает функции, такие как функции изображения, такие как цвет, текстура и интенсивность; характеристики звука, такие как амплитуда, соотношение спектральных коэффициентов; текстовые особенности, такие как частота слов, средняя длина предложения, параметры форматирования; метаданные, связанные с объектом; и т. д.) из сущностей для создания векторов признаков
- Обучает классификатор на основе векторов признаков и оценок релевантности субъективных атрибутов.
- Использует обученный классификатор для прогнозирования субъективных атрибутов новых сущностей на основе векторов признаков новых сущностей.
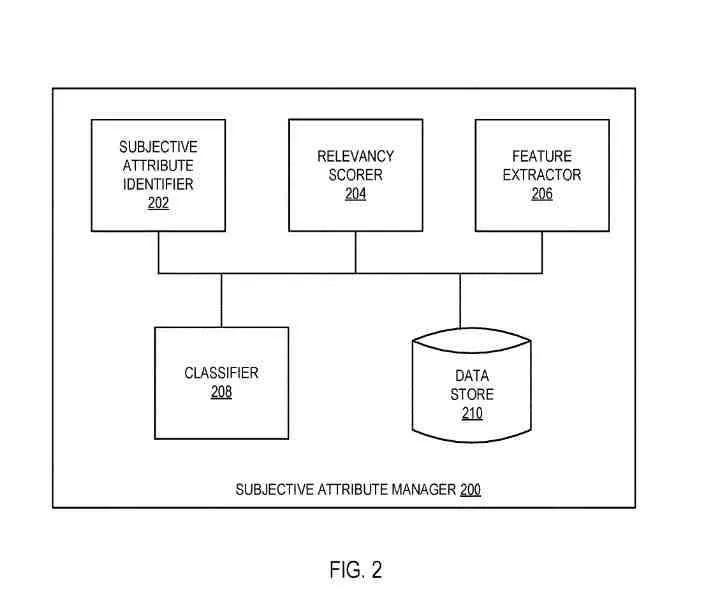
Менеджер субъективных атрибутов
Менеджер субъективных атрибутов может быть таким же, как менеджер субъективных атрибутов, и может включать в себя:
- Идентификатор субъективного атрибута
- Счетчик релевантности
- Экстрактор функций
- Классификатор
- Хранилище данных
.
Компоненты могут быть объединены или разделены на дополнительные детали.
Хранилище данных может быть таким же, как хранилище сущностей, или другим хранилищем данных (например, временным буфером или постоянным хранилищем данных) для хранения личного словаря атрибутов, сущностей, которые должны быть обработаны, векторов признаков, связанных с сущностями, личных атрибутов. и оценки релевантности, связанные с сущностями, или некоторая комбинация этих данных.
Хранилище данных может размещаться на устройствах хранения, таких как оперативная память, магнитные или оптические диски, ленты или жесткие диски и т. д.
Диспетчер субъективных атрибутов уведомляет пользователей о типах информации, хранящейся в хранилище данных и хранилище сущностей, и позволяет пользователям выбрать, чтобы такая информация не собиралась и не передавалась диспетчеру субъективных атрибутов.
Идентификатор субъективного атрибута
Идентификатор личного атрибута идентифицирует субъективные атрибуты объектов на основе реакции пользователя на объекты.
Идентификатор личного атрибута может идентифицировать субъективные атрибуты посредством обработки текста комментариев пользователей к объекту, размещенному пользователем на веб-сайте социальной сети.
Идентификатор субъективного атрибута может идентифицировать субъективные атрибуты объектов на основе других типов реакции пользователя на объекты, например:
- 'Нравиться!' или "Не нравится!"
- Совместное использование сущности
- Добавление объекта в закладки
- Добавление объекта в список воспроизведения
- Так далее
Идентификатор личного атрибута может применять пороги для определения того, какие атрибуты связаны с сущностью (например, субъективный атрибут должен появляться по крайней мере в N комментариях и т. д.).
Средство оценки релевантности определяет оценки релевантности для субъективных атрибутов сущностей.
Например, когда идентификатор субъективного атрибута идентифицировал субъективные атрибуты «милый», «забавный» и «крутой» на основе комментариев к медиаклипу, размещенному на веб-сайте социальной сети, оценщик релевантности может определить баллы релевантности для каждого из этих трех субъективных атрибутов. атрибуты на основе:
- Частота, с которой эти субъективные атрибуты появляются в комментариях
- Конкретные пользователи, предоставившие субъективные атрибуты
- Так далее
Например, если имеется 40 комментариев, а слово «милый» состоит из 20 слов, а «классный» — из 8 комментариев, то «милый» может получить более высокий показатель релевантности, чем «классный».
Оценки релевантности могут быть присвоены на основе доли комментариев, в которых появляется субъективный атрибут (например, оценка 0,5 для «симпатичного» и оценка 0,2 для «потрясающего» и т. д.).
Оценщик релевантности может сохранить только k наиболее релевантных субъективных атрибутов и отбросить другие личные атрибуты.
Например, предположим, что идентификатор личного атрибута идентифицирует семь эмоциональных атрибутов, которые появляются в комментариях пользователя не менее трех раз. В этом случае оценщик релевантности может, например, сохранить только пять субъективных атрибутов с наивысшими оценками релевантности и отбросить два других эмоциональных атрибута (например, установив их оценки релевантности на ноль и т. д.).
Показатель релевантности — это натуральное число от 0,0 до 1,0 включительно.
Средство извлечения признаков получает вектор признаков для объекта, используя такие методы, как:
- Анализ основных компонентов
- Полуопределенные вложения
- Изомапы
- Частичные наименьшие квадраты
- Так далее
Вычисления, связанные с извлечением признаков объекта, выполняются самим экстрактором признаков.

В некоторых других аспектах эти вычисления выполняются другим объектом, например исполняемой библиотекой:
- Подпрограммы обработки изображений, размещенные на сервере [не показаны на рисунках]
- Процедуры обработки звука
- Подпрограммы обработки текста
- И т.д
Результаты передаются экстрактору признаков.
Классификатор — это обучающая машина (такая как машины опорных векторов [SVM], AdaBoost, нейронные сети, деревья решений и т. д.), которая принимает в качестве входных данных вектор признаков, связанный с объектом, и выводит оценки релевантности (например, фактическое число между 0 и 1 включительно и т.д.) для каждого субъективного признака словаря личного признака.
Классификатор состоит из одного классификатора.
Классификатор может включать в себя несколько классификаторов (например, классификатор для каждого субъективного атрибута в словаре личных атрибутов и т. д.).
Набор положительных примеров и отрицательных критериев собран для каждого субъективного признака в словаре личных признаков.
Набор положительных примеров для субъективного атрибута может включать в себя векторы признаков для сущностей, связанных с этим конкретным личным атрибутом.
Набор отрицательных примеров для субъективного атрибута может включать в себя векторы признаков для сущностей, которые не были связаны с этим конкретным личным атрибутом.
Когда набор положительных примеров и набор отрицательных критериев неодинаковы по размеру, можно выбрать более обширный набор, чтобы он соответствовал размеру меньшей группы.
После обучения классификатор может прогнозировать субъективные атрибуты для других объектов, не входящих в обучающий набор, предоставляя векторы признаков для этих объектов в качестве входных данных для классификатора.
Набор субъективных атрибутов может быть получен из выходных данных классификатора путем включения всех эмоциональных атрибутов с ненулевыми показателями релевантности. Группа субъективных баллов может быть получена путем применения наименьшего порога к числовым оценкам (путем рассмотрения всех личных качеств, имеющих оценку не менее, скажем, 0,2, как составляющих набор).
Выявление субъективных атрибутов сущностей
Способ осуществляется путем обработки логики, которая может включать в себя аппаратные средства (схемы, выделенная логика и т. д.), программное обеспечение (например, запускаемое в компьютерной системе общего назначения или выделенной машине) или и то, и другое.
Этот метод выполняется серверной машиной, в то время как некоторые другие реализации могут выполняться другим устройством.
Различные компоненты менеджеров субъективных атрибутов могут работать на отдельных компьютерах (например, идентификатор личного атрибута и счетчик релевантности могут работать на одном устройстве, а экстрактор признаков и классификатор — на другом и т. д.).
Для простоты объяснения метод изображается и описывается как серия действий.
Но действия могут происходить в различном порядке и вместе с другими действиями, не представленными и не описанными здесь.
Кроме того, не все проиллюстрированные действия могут потребоваться для установки способов согласно раскрытому предмету изобретения.
Кроме того, специалисты в данной области поймут и оценят, что способ может быть представлен как ряд взаимосвязанных состояний посредством диаграммы состояний или событий.
Кроме того, следует понимать, что способы, раскрытые в данном описании, можно сохранять на изделии, чтобы упростить транспортировку и перенос таких методологий на вычислительные устройства.
Термин «изделие производства», используемый здесь, предназначен для охвата компьютерной программы, доступной с любого машиночитаемого устройства или носителя.
Генерируется словарь субъективных атрибутов.
В некоторых аспектах может быть определен словарь субъективных атрибутов. Напротив, в некоторых других факторах словарь личных атрибутов может генерироваться автоматически путем сбора терминов и фраз, которые используются в реакциях пользователей на объекты. Напротив, в других аспектах словарный запас может быть создан комбинацией ручных и автоматизированных методов.
Словарь засеян небольшим количеством субъективных атрибутов, которые, как ожидается, будут применяться к сущностям. Словарный запас со временем расширяется по мере того, как все больше терминов или фраз, которые появляются в реакциях пользователей, идентифицируются с помощью автоматической обработки ответов.
Словарь субъективных атрибутов может быть организован иерархически, возможно, на основе «метаатрибутов», связанных с личными атрибутами (например, личный атрибут «забавный» может иметь метаатрибут «положительный», в то время как субъективный признак «отвратительный» может иметь мета-атрибут «негативный» и т. д.).
Набор S сущностей (например, все сущности в хранилище сущностей, подмножество сущностей в хранилище сущностей и т. д.) предварительно обрабатывается.
В соответствии с одним аспектом предварительная обработка объектов включает в себя идентификацию реакции пользователя на объекты, а затем обучение классификатора на основе ответов.
Когда сущность является реальной физической сущностью
Следует отметить, что когда объект является реальным физическим объектом (например, человеком, рестораном и т. д.), предварительная обработка объекта выполняется через «кибер-прокси», связанный с физическим объектом (например, фан-страница актера в социальной сети, обзор ресторана на сайте и т. д.); но считается, что субъективные атрибуты связаны с самой сущностью (например, с актером или рестораном, а не с фан-страницей актера или обзором ресторана).
Подробно описан пример способа выполнения.
Atn получен объект E, которого нет в наборе S (например, недавно загруженный видеоклип, новостная статья, которая еще не получила комментариев, объект в хранилище объектов, который не был включен в обучающий набор и т. д.).
Получаются атрибуты предмета и оценки релевантности для объекта E.
Реализация первого примерного способа подробно описана ниже, а производительность второго примерного способа описана.
Полученные субъективные атрибуты и оценки релевантности связываются с объектом E (например, путем применения соответствующих тегов к объекту, добавления записи в таблицу реляционной базы данных и т. д.).
Выполнение продолжается обратно.
Следует отметить, что классификатор может быть повторно обучен (например, после каждых 100 итераций цикла, каждые N дней и т. д.) с помощью процесса повторного обучения, который может выполняться одновременно.
Предварительная обработка набора сущностей
Способ осуществляется путем обработки логики, которая может включать в себя аппаратные средства (схемы, выделенная логика и т. д.), программное обеспечение (например, запускаемое в компьютерной системе общего назначения или выделенной машине) или и то, и другое.
Метод выполняется, в то время как в некоторых других реализациях может выполняться другой машиной.
Обучающий набор инициализируется пустым набором. Сущность E выбирается и удаляется из набора S сущностей.
Субъективные атрибуты объекта E идентифицируются на основе реакции пользователя на объект E (например, пользовательские комментарии, лайки!, добавление в закладки, совместное использование, добавление в список воспроизведения и т. д.).
Идентификация субъективных атрибутов включает выполнение обработки комментариев пользователей, например:
- Сопоставление слов в комментариях пользователей с субъективными атрибутами в словаре
- Сочетание сопоставления слов и других методов обработки естественного языка, таких как синтаксический и семантический анализ.
- И т.д
Сущности, которые появляются рядом с локациями
Реакции пользователей могут быть объединены для сущностей, которые происходят во многих местах, например:
- Сущности, которые появляются в плейлистах многих пользователей
- Сущности, которыми поделились и которые появляются во многих «лентах новостей» пользователей на веб-сайте социальной сети.
- И т.д
Различные местоположения могут быть взвешены по своему вкладу в оценку релевантности на основе множества факторов, таких как:
Конкретный пользователь, связанный с местоположением (например, конкретный пользователь может быть авторитетом в области классической музыки, и поэтому комментарии об объекте в его ленте новостей могут иметь больший вес, чем комментарии в другой ленте новостей и т. д.), нетекстовые реакции пользователей (например, как «Нравится!», «Не нравится!», «+1» и т. д.).
Кроме того, количество мест, где появляется объект, также может быть использовано для определения субъективных атрибутов и оценок релевантности (например, оценки релевантности для видеоклипа могут быть увеличены, когда видеоклип находится в сотнях пользовательских списков воспроизведения и т. д.).
Блокировка выполняется по идентификатору субъективного атрибута.
Оценки релевантности субъективных атрибутов определяются сущностью E.
Оценка релевантности определяется для конкретного субъективного атрибута на основе частоты, с которой личный атрибут появляется в комментариях пользователей, конкретных пользователей, которые предоставили субъективные подробности в своих словах (например, некоторые пользователи могут быть известны по опыту как более точные в своих словах). свои комментарии, чем другие пользователи и т. д.).
Например, если имеется 40 комментариев, а слово «милый» состоит из 20 слов, а «классный» — из 8 комментариев, то «милый» может получить более высокий показатель релевантности, чем «классный».
Оценки релевантности могут быть присвоены на основе доли комментариев, в которых появляется субъективный атрибут (например, оценка 0,5 для «симпатичного» и оценка 0,2 для «потрясающего» и т. д.).
Согласно одному аспекту, показатели релевантности нормализуются, чтобы попасть в интервалы [0, 1].
В соответствии с некоторыми аспектами выявленные субъективные атрибуты могут быть отброшены на основании их оценок релевантности (например, сохранение k эмоциональных атрибутов с наивысшими оценками релевантности, отбрасывание любого личного атрибута, оценка релевантности которого ниже порогового значения, и т. д.).
Следует отметить, что субъективный атрибут можно отбросить, установив его показатель релевантности равным нулю в некоторых аспектах.
Субъективные атрибуты и показатели релевантности связаны с сущностями
Субъективные атрибуты и оценки релевантности связаны с сущностями (например, с помощью тегов, записей в таблице в реляционной базе данных и т. д.).
Получается вектор признаков для объекта E.
В одном аспекте вектор признаков для видеоклипа или неподвижного изображения может содержать числовые значения цвета, текстуры, интенсивности и т. д., в то время как вектор признаков для аудиоклипа (или видеоклипа со звуком) может включать числовые значения амплитуды. , спектральные коэффициенты и т.д., а вектор признаков для текстового документа может включать:
- Числовые значения частоты слов
- Средняя длина предложения
- Параметры форматирования
- Так далее
Это может быть выполнено экстрактором признаков.
Вектор признаков и полученные оценки релевантности добавляются в обучающую выборку.
Бок проверяет, пусто ли множество сущностей S; если S непусто, выполнение продолжается, в противном случае выполнение продолжается.
Классификатор обучается на всех примерах обучающего набора, так что вектор признаков обучающего примера предоставляется в качестве входных данных для классификатора, а субъективные оценки релевантности атрибутов предоставляются в качестве выходных данных.
Получение субъективных атрибутов и оценок релевантности объекта
Генерируется вектор признаков для объекта E.
Как описано выше, вектор признаков для видеоклипа или неподвижного изображения может содержать числовые значения цвета, текстуры, интенсивности и т. д. Напротив, вектор признаков для аудиоклипа (или видеоклипа со звуком) может включать числовые значения. об амплитуде, спектральных коэффициентах и т. д. Напротив, вектор признаков для текстового документа может включать числовые значения частоты слов, средней длины предложения, параметров форматирования и т. д.
Обученный классификатор предоставляет вектор признаков для получения прогнозируемых субъективных атрибутов и оценок релевантности для объекта E.
Прогнозируемые субъективные атрибуты и оценки релевантности связываются с объектом E (например, с помощью тегов, примененных к объекту E, посредством записей в таблице реляционной базы данных и т. д.).
Второй метод получения субъективных атрибутов и оценок релевантности объекта
Способ реализуется путем обработки логики, которая может включать аппаратное обеспечение (схема, специальная логика и т. д.), программное обеспечение или их комбинацию.
Этот метод выполняется серверной машиной, в то время как некоторые другие могут выполняться другим устройством.
Генерируется вектор признаков для объекта E. Обученный классификатор предоставляет вектор признаков для получения прогнозируемых субъективных атрибутов и оценок релевантности для объекта E.
Полученные предсказанные субъективные атрибуты предлагаются пользователю (например, пользователю, который загрузил объект. Уточненный набор личных атрибутов получается от пользователя, например, через веб-страницу, на которой пользователь выбирает из предложенных атрибутов и, возможно, добавляет новые атрибуты и т. д.).
Оценка релевантности по умолчанию для сущностей
Оценка релевантности по умолчанию назначается всем новым субъективным атрибутам, добавленным пользователем.
Оценка релевантности по умолчанию может быть 1,0 по шкале от 0,0 до 1,0, оценка релевантности по умолчанию может быть основана на конкретном пользователе (например, оценка 1,0, когда известно, что пользователь из прошлой истории очень хорошо предлагает атрибуты, оценка 0,8, когда известно, что пользователь неплохо предлагает атрибуты и т. д.).
Ветви блокировки получаются в зависимости от того, удалил ли пользователь какой-либо из предложенных субъективных атрибутов (например, не выбрав атрибут).
Объект E сохраняется как отрицательный пример удаленного атрибута (ов) для будущего повторного обучения классификатора. Уточненный набор субъективных атрибутов и соответствующие оценки релевантности связываются с сущностью E (например, с помощью тегов, примененных к сущности E, посредством записей в таблице реляционной базы данных и т. д.).