
Генерация естественного языка против вращения статьи
Опубликовано: 2022-05-02Генерация естественного языка использует глубокое обучение для создания читаемого человеком текста; уникальная статья, основанная на модели предсказания языка. Инструменты счетчика статей берут оригинальную статью и создают одну или несколько вариаций, заменяя определенные слова, фразы или предложения альтернативными версиями.
Если вы проводили какое-либо исследование приложений для генерации естественного языка для контент-маркетинга, возможно, вы сталкивались с программным обеспечением для раскрутки статей. Также известный как переписывание статей, это одна из тех старых тактик SEO, как автоматическое создание обратных ссылок, используемая в менее чем законных (черных) целях.
В этом посте мы рассмотрим, как работает вращающееся программное обеспечение, варианты его использования и чем оно отличается от генерации естественного языка (NLG). Есть много причин, по которым я не одобряю использование счетчиков статей, поэтому думайте об этой статье как о публичном объявлении.

Как используются счетчики статей
Лучший способ понять счетчики статей — посмотреть на язык, используемый для продажи этих продуктов. Вот несколько цитат с сайтов, пытающихся продавать программное обеспечение для спиннеров:
- «Мгновенно раскручивайте уникальные версии любых статей».
- «Создавайте сотни новых статей за считанные минуты».
- «Производить горы контента».
- «Создание огромного количества контента, чтобы помочь лучше ранжировать ваши сайты».
Некоторые даже пытаются извлечь выгоду из тенденции искусственного интеллекта, утверждая, что их программное обеспечение управляется ИИ. Они описывают свой продукт, используя термины ИИ, а иногда даже прибегают к выдумыванию терминов.
«Эмуляция естественного языка» — мой любимый фальшивый термин. Я не шучу. Кто-то это придумал, но это был не я! Звучит сложно, но ничего не значит.
Основываясь на используемом языке, вы, вероятно, можете догадаться, в какой ситуации развернуты счетчики статей. Как правило, они используются на низкокачественных сайтах, созданных исключительно для целей SEO, при этом затраты на написание статей должны быть как можно ниже.
Создание читаемого текста занимает последнее место в списке приоритетов для таких типов блогов. Вместо этого их цель — создать сеть ссылок для повышения рейтинга основного «денежного» сайта.
Публикация качественного контента не является целью этой работы. «Уникальный контент» — это все, что достаточно хорошо, чтобы пройти автоматическую проверку поисковых систем на плагиат.
Если вам интересно, действительно ли всемирной паутине нужно больше этого контента, ответ — нет!
Как работает счетчик статей?
По сравнению с NLG счетчики контента примитивны. Они берут часть контента и создают вариацию, пытаясь создать впечатление, что это уникальная статья. Это достигается заменой слов, фраз, предложений, а иногда и абзацев вариантами.
Ранние попытки вращения статей привели к тому, что статьи было невозможно читать. Проблема в том, что они не могли распознать контекст или часть речи.
Таким образом, замены были в лучшем случае странными, а часто и неправильными. Содержание, конечно, не было оригинальным.
Вот точный вывод счетчика статей на примере предыдущего абзаца .

Повторяющийся контент выделяется желтым цветом. Плохие замены окрашены в красный цвет. Допустимые замены окрашены в зеленый цвет.
Таким образом, 67,5% опубликованных статей — это дублированный контент, который не изменился по сравнению с оригиналом. Шесть из семи замен были некачественными, и только одна была приемлемой.
Нужно ли мне сказать больше!
Некачественный производный контент является отличительной чертой накрутки статей.
Хотя некоторые новые авторы статей заявляют об использовании искусственного интеллекта, на самом деле это несколько преувеличено. В лучшем случае они могут использовать Google Natural Language API для извлечения токенов и предложений, а также для маркировки частей речи (PoS). Это часть обработки естественного языка (NLP), но, как мы увидим, для генерации естественного языка требуется гораздо больше.
Как ни посмотри, создание статей по-прежнему остается процессом создания производных произведений из оригинала.
Инструменты перефразирования Не перефразируйте
Учитывая негативный оттенок вращения статей, некоторые инструменты для спиннинга статей зарекомендовали себя как инструмент перефразирования. Не дайте себя обмануть. Инструменты перефразирования, которые я видел, работают точно так же, как счетчики статей.
Посмотреть на себя.

Вывод выше взят из бесплатного инструмента перефразирования, где я использовал тот же оригинальный текст из предыдущего раздела. Выделенный текст указывает на слова, которые были заменены.
Я прогнал и оригинальную, и перефразированную версию через Grammarly; вы можете увидеть результат ниже.
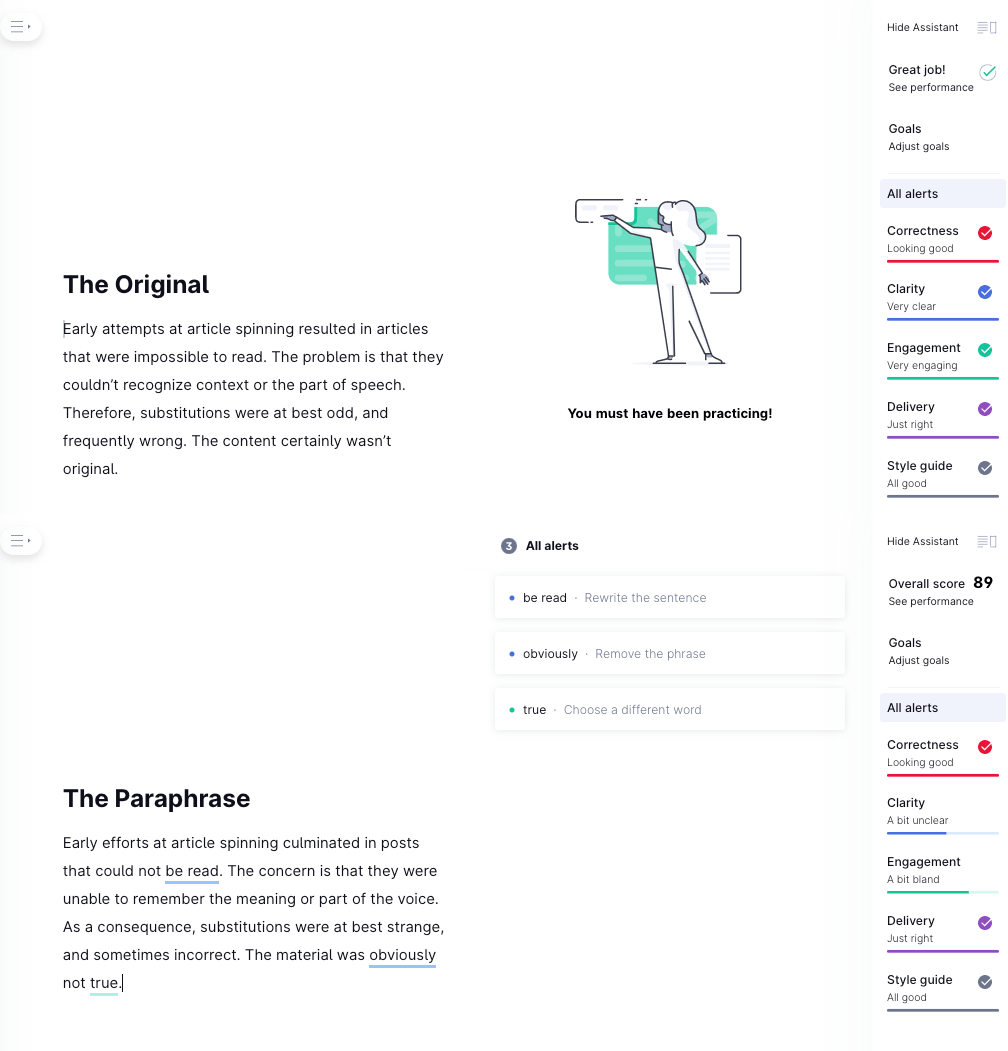
Использование этого инструмента «перефразирования» приводит к потере ясности и вовлеченности. Это прямо противоположно тому, чего должно достичь перефразирование.
Как работает генерация естественного языка?
В отличие от переписывания статей, генерация на естественном языке не требует оригинального контента. Он создает совершенно новый контент вместо того, чтобы переписывать существующие статьи.

NLG использует либо подход, основанный на правилах, либо опирается на статистическое языковое моделирование. Любой метод может использовать технологии NLP и понимания естественного языка (NLU) для улучшения качества сгенерированного текста.
NLP анализирует текст с помощью тегов (PoS) и распознавания сущностей, в то время как NLU использует NLP и глубокое обучение для создания семантических моделей, которые получают смысл.
Разница между NLG и программным обеспечением для спиннинга статей
Какими бы продвинутыми не претендовали на себя спиннеры статей, они не могут генерировать текст, а только изменяют его. Для этого типа инструмента требуется существующая запись в блоге, из которой он может создавать только производные.
Они не создают, они просто модифицируют. Таким образом, он не подходит для контент-маркетологов, стремящихся масштабировать производство контента и поддерживать качество без масштабирования затрат и сложности.
Лучшие из этой жалкой партии могут использовать некоторую ограниченную обработку естественного языка, чтобы сделать лучший выбор при замене слов. Но назвать это искусственным интеллектом — с большой натяжкой.
Как работает технология MarketMuse NLG?
MarketMuse NLG Technology — это платформа для создания контента с использованием искусственного интеллекта, выходные данные которой структурируются в соответствии с нашими информационными бюллетенями на основе искусственного интеллекта.
Технология MarketMuse NLG позволяет создавать объемный всеобъемлющий контент без:
Плагиат
Репетиция
Ухудшение качества
Каждый черновик уникален, оригинален и не просто извлекает или модифицирует текстовые фрагменты других документов. Технологию MarketMuse NLG можно настроить в соответствии со стилем ваших авторов. Он также может подражать стилю автора или публикации.
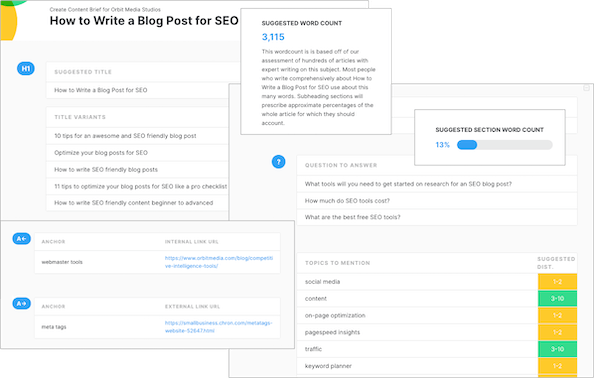
Эти сводки содержания, которые обеспечивают структуру и содержание Продукция MarketMuse NLG Technology включает:
- Полная структура, включая подзаголовки
- Связанные темы, которые необходимо включить
- Список вопросов, которые необходимо решить
Это тот же краткий обзор содержания, который обычно дается писателю-человеку для работы. Вместо этого мы передаем его технологии MarketMuse NLG.
Подумайте об этом так.
Если бы вы назначили писателю незнакомую тему, он бы сначала прочитал эту тему. Технология MarketMuse NLG ничем не отличается. Но вместо того, чтобы исследовать несколько документов, он выходит в Интернет для анализа огромных объемов данных.
Вот выдержка из технологии MarketMuse NLG по теме «Глюкагон как неинвазивное лечение диабета».

Подзаголовок, тема этого раздела, — «Роль инсулина и глюкагона». Вопросы и соответствующие темы, связанные с этим подзаголовком, показаны справа. Вместе они помогают обеспечить релевантность и тщательность результатов.
Используйте технологию MarketMuse NLG, чтобы:
- Масштабируйте контент без затрат на масштабирование
- Авторитетно пишите на любую тему
- Избегайте распространенных ошибок с текстом, сгенерированным ИИ
- Подражайте любому стилю письма, который вы желаете
Обеспечьте предсказуемость затрат на контент и неизменное качество, позволив ИИ сделать работу по созданию качественного первоначального проекта.
Что вы должны сделать сейчас
Когда вы будете готовы... Вот 3 способа, которыми мы можем помочь вам публиковать более качественный контент и быстрее:
- Забронируйте время с MarketMuse Запланируйте живую демонстрацию с одним из наших специалистов по стратегии, чтобы увидеть, как MarketMuse может помочь вашей команде достичь своих целей в отношении контента.
- Если вы хотите узнать, как быстрее создавать качественный контент, посетите наш блог. Он полон ресурсов, помогающих масштабировать контент.
- Если вы знаете другого маркетолога, которому было бы интересно прочитать эту страницу, поделитесь ею с ним по электронной почте, LinkedIn, Twitter или Facebook.