
Бенчмаркинг движка NLU: подход на основе данных для лидеров рынка ИИ
Опубликовано: 2022-09-09Механизмы распознавания естественного языка (NLU) являются мощным драйвером настроений клиентов. ИИ и NLU настолько развились, что сотрудник Google привлек внимание всего мира, заявив, что чат-бот компании LaMDA был человеком, обладающим самосознанием.
Но не волнуйтесь. Мы здесь не для того, чтобы напугать вас историями о роботах с искусственным интеллектом, захвативших мир, или об обслуживании клиентов.
Около 71% американских потребителей по-прежнему предпочитают человеческое общение при общении с клиентами, и именно здесь на сцену выходят эталонные механизмы NLU.
NLU может помочь агентам лучше понимать и обслуживать клиентов, добавляя уровни знаний, контекста и настроений во взаимодействие с клиентами. Разговорный ИИ, основанный на эталонных механизмах NLU, позволяет брендам быть более интеллектуальными и чуткими и выявлять скрытые подсказки клиентов, чтобы сделать обслуживание клиентов более персонализированным и менее машинным.
Но как вы тестируете двигатели NLU, чтобы оценить их возможности ИИ? Чтобы добраться туда, давайте сначала разберемся с ключевыми техническими терминами.
Глоссарий по бенчмаркингу двигателей NLU
Разговорный ИИ
Разговорный ИИ — это функция на базе NLU, которая позволяет компьютерам и цифровым приложениям проявлять эмпатию к клиентам, распознавая эмоции, срочность и контекст, лежащие в основе человеческих разговоров.Набор данных
Набор данных — это набор связанных наборов информации, которые компьютеры могут обрабатывать как единый набор информации.высказывание
Высказывание — это фраза или предложение речи пользователя, полученное посредством текста, аудио или видео. Механизмы NLU используют высказывания для обучения, тестирования и интерпретации намерений пользователя.Намерение
Намерение указывает на цель пользователя, стоящую за действиями, событиями или утверждениями. Например, действие пользователя может быть классифицировано как запрос продукта, жалоба, запрос на возврат средств и т. д.Точность
Точность — это процент тестовых предложений, соответствующих правильному намерению механизма NLU.F1 макрос
Гармоническое среднее макросредних значений точности и отзыва для каждого намерения называется макросом F1.
Точность = количество истинно положительных результатов в отношении намерения/все положительные результаты в отношении намерения.
Отзыв = количество истинно положительных результатов в отношении намерения/количество результатов, определенных как положительные в отношении намерения.
Бенчмаркинг движка NLU: понимание процесса
Сравнение двигателей NLU может быть утомительным процессом. На составление списка решений с поддержкой NLU и проверку общих намерений, наблюдаемых у ваших клиентов, может уйти много времени. Вот где структурированный подход, подкрепленный исследованиями, пригодится для оценки двигателей NLU и их интуитивных возможностей ИИ с беспристрастным подходом.
Сравнительный анализ сервисов понимания естественного языка для создания диалоговых агентов
Этот метод сравнительного анализа NLU сравнивает механизмы NLU в наборе данных для бота домашней автоматизации, разбитого на малые и большие наборы данных, чтобы оценить точность машинного обучения при различных размерах данных обучения и тестирования.
Методология, используемая в методе сравнительного анализа NLU
Небольшой набор данных
64 разных намерения выбираются случайным образом
10 примеров предложений используются для каждого намерения обучить движок NLU.
Тестируется 1076 примеров предложений (не входящих в обучающий набор).
Большой набор данных
Те же самые 64 намерения, упомянутые выше, выбраны для большого набора данных.
Для каждого намерения обучить движок NLU используется около 30 примеров предложений.
Тестируется 5 518 примеров предложений (не входящих в обучающий набор).
Отчет о тесте двигателя NLU: результат
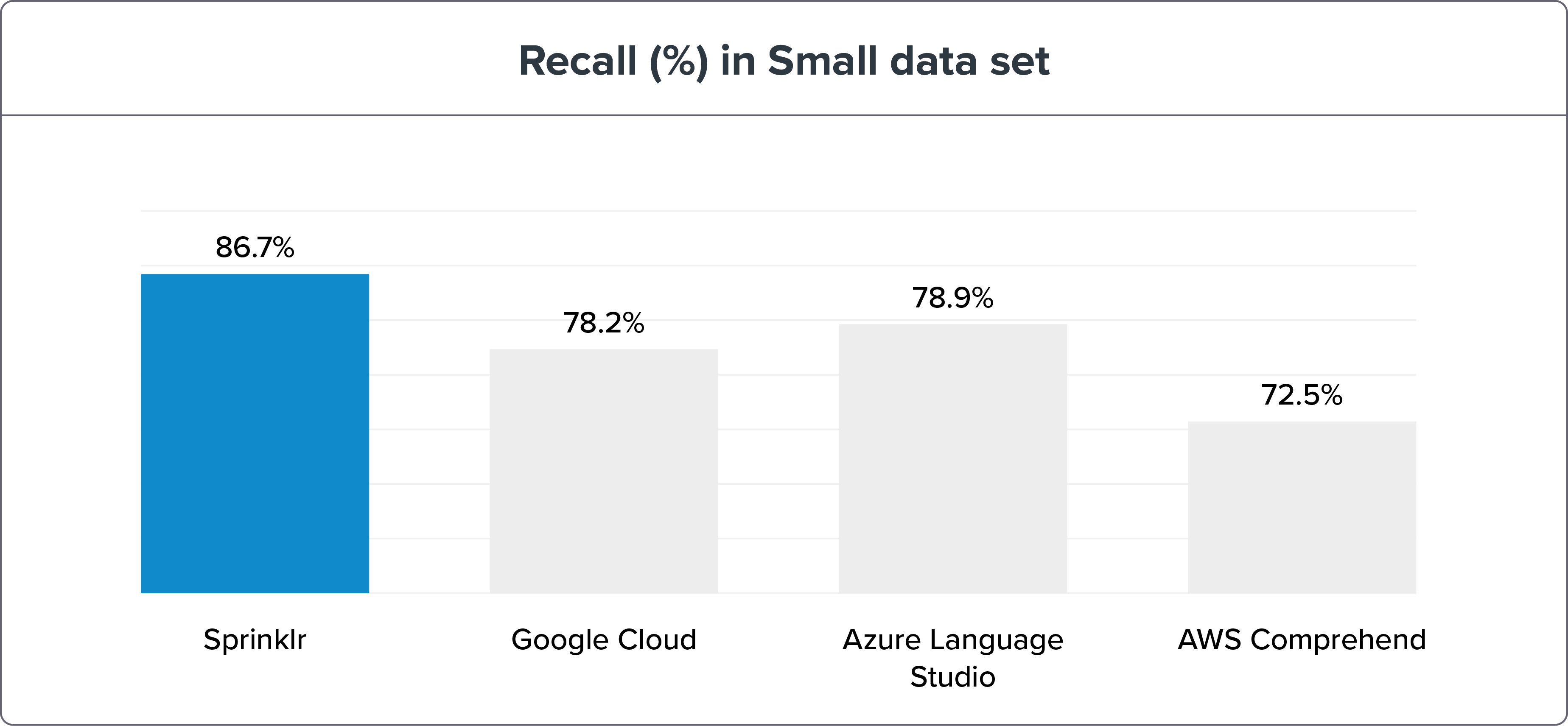
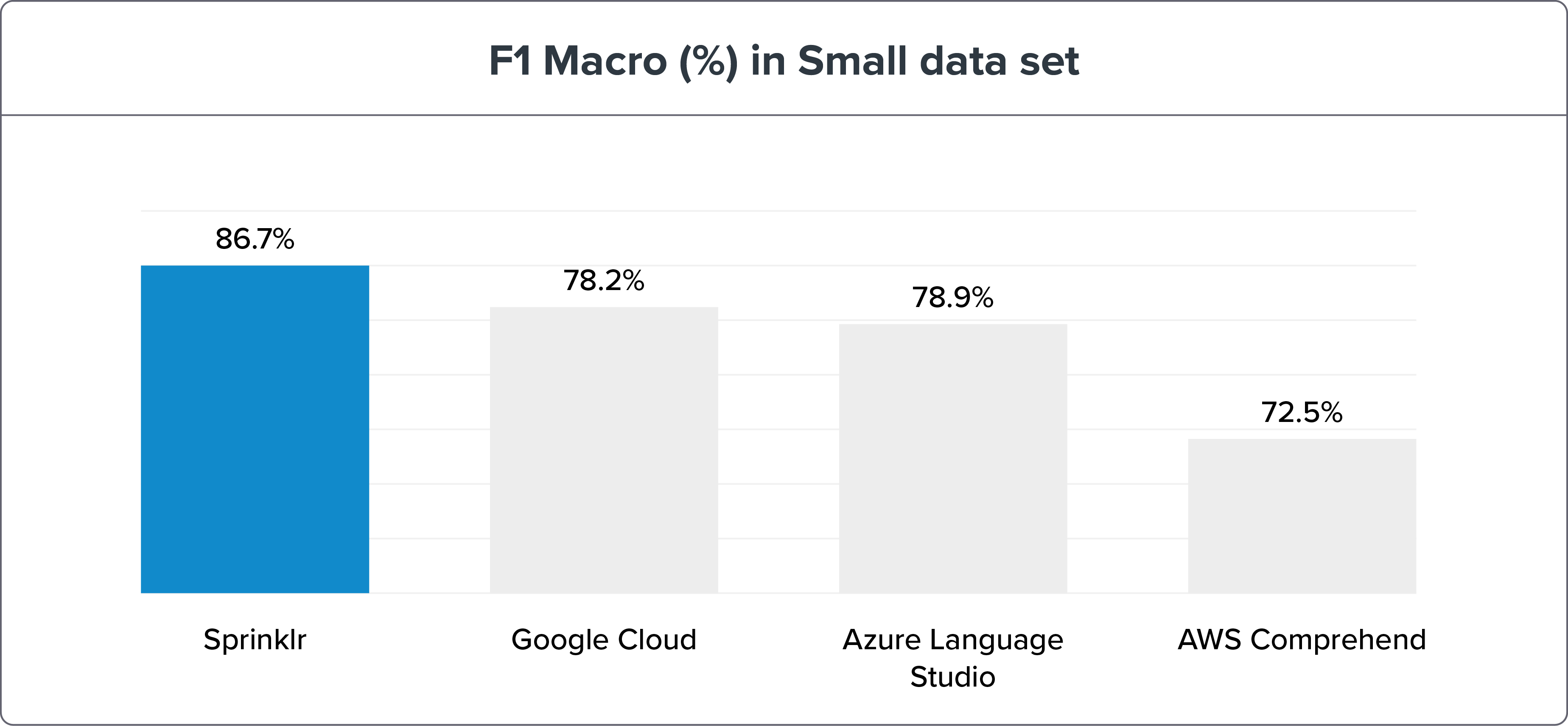
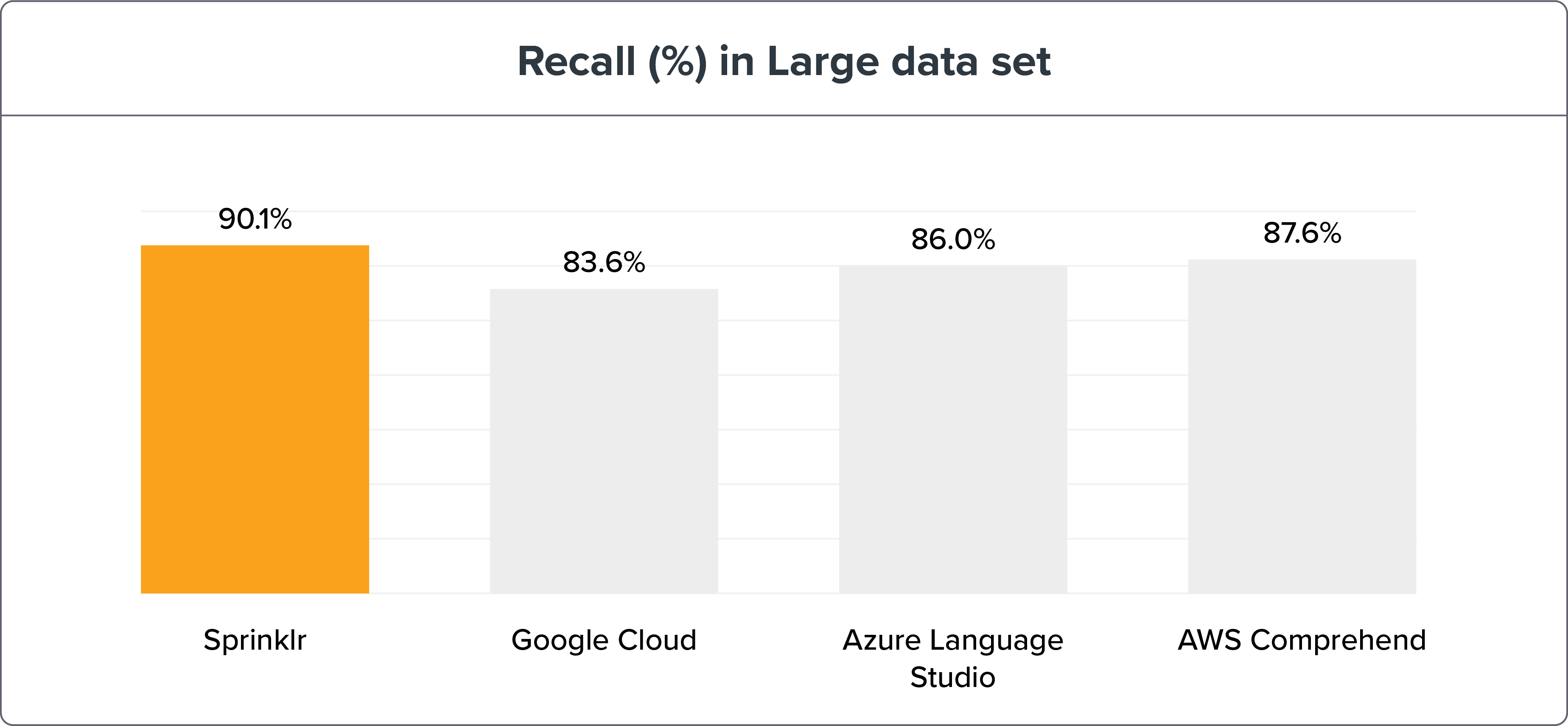
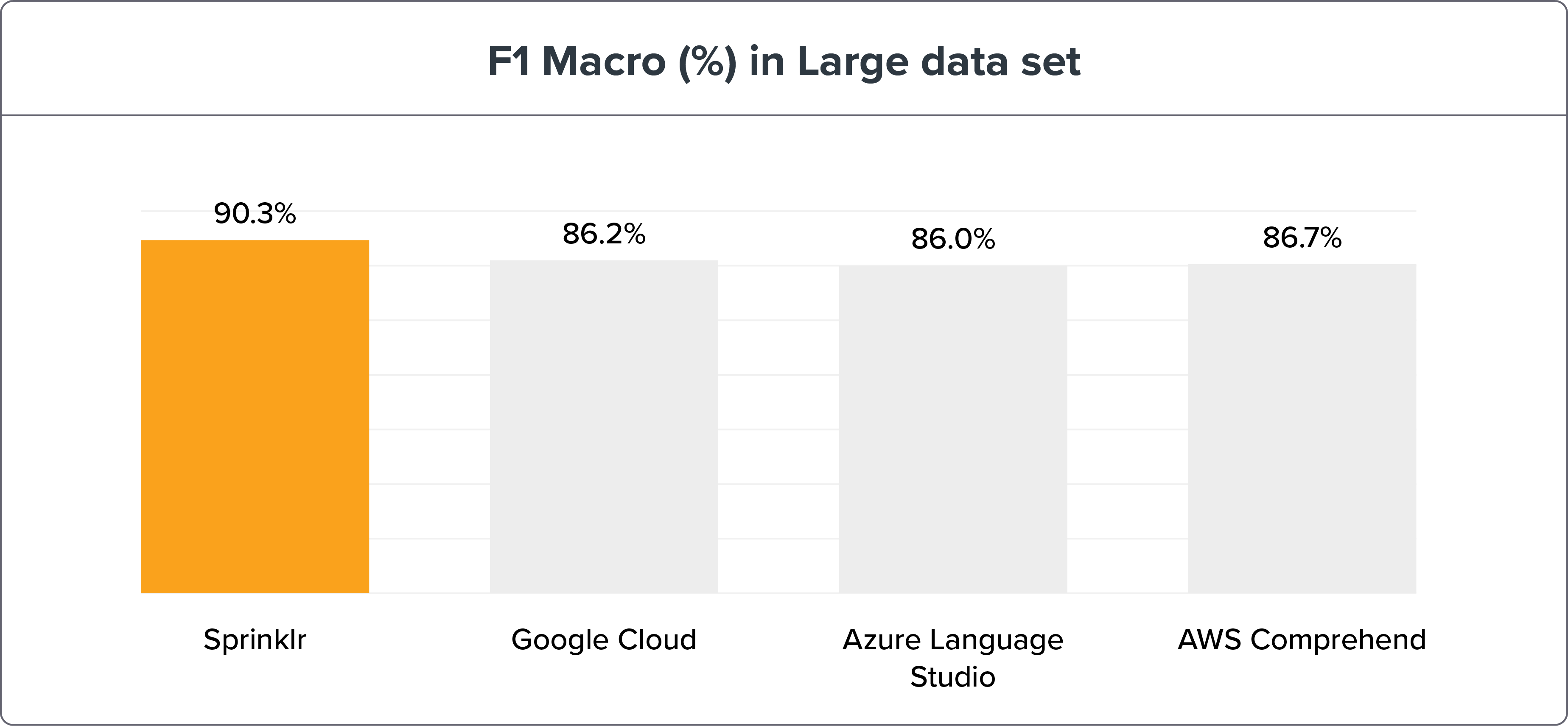
Метод сравнительного анализа NLU показывает, что точность NLP Sprinklr благодаря отзыву и макросам F1 намного выше, чем у его современников — Google Cloud, Azure Language Studio и AWS Comprehend. С данными и результатами бенчмаркинга можно ознакомиться здесь .
Если мы разобьем бенчмаркинг движка NLU на малые и большие наборы данных, движок Sprinklr NLU по-прежнему будет явным победителем.
Примечание . Большие наборы данных — лучший способ проверить и обучить намерения для повышения точности. Но разница в точности с двигателем NLU Sprinklr составляет всего ≤ 3%.
Небольшой набор данных
Параметры:
640 обучающих предложений = 10 предложений на намерение
1076 тестовых предложений
Большой набор данных
Параметры:
1908 обучающих предложений ≈ 30 предложений на намерение
5518 тестовых предложений
Sprinklr становится явным победителем в тестировании движка NLU
Механизм NLU Sprinklr остается последовательным и точным в определении целей запросов, с лучшим сопоставлением между тестовыми входными данными и обучающими входными данными.
Пример 1: небольшой набор данных
Запрос: есть ли что-нибудь, о чем мне нужно знать
Основная истина: calendar_query

Пример 2: Большой набор данных
Запрос: сколько стран входит в Евросоюз
Основная правда: qa_factoid

Ограничения бенчмаркинга движка NLU
Размер набора данных : поскольку использовалось большое количество хорошо изученных наборов данных, механизмы NLU могли учиться на тестовых высказываниях быстрее, чем в случае с обычно находимыми необработанными структурированными данными.
Используемые языки: для тестирования различных экземпляров и намерений использовался только английский язык.
Характер тестовых данных : высказывания пользователей могут не звучать как типичные клиенты, которые могут делать больше грамматических ошибок и иметь пробелы в разговоре.
Наиболее распространенные проблемы интерпретации движка NLU
Типичные механизмы NLU имеют определенные ограничения, особенно при интерпретации взаимодействия с клиентами. Вот наиболее распространенные ошибки интерпретации движка NLU и способы их избежать:
Сарказм
Механизмы NLU могут с трудом обнаруживать сарказм или пассивно-агрессивные комментарии клиентов.
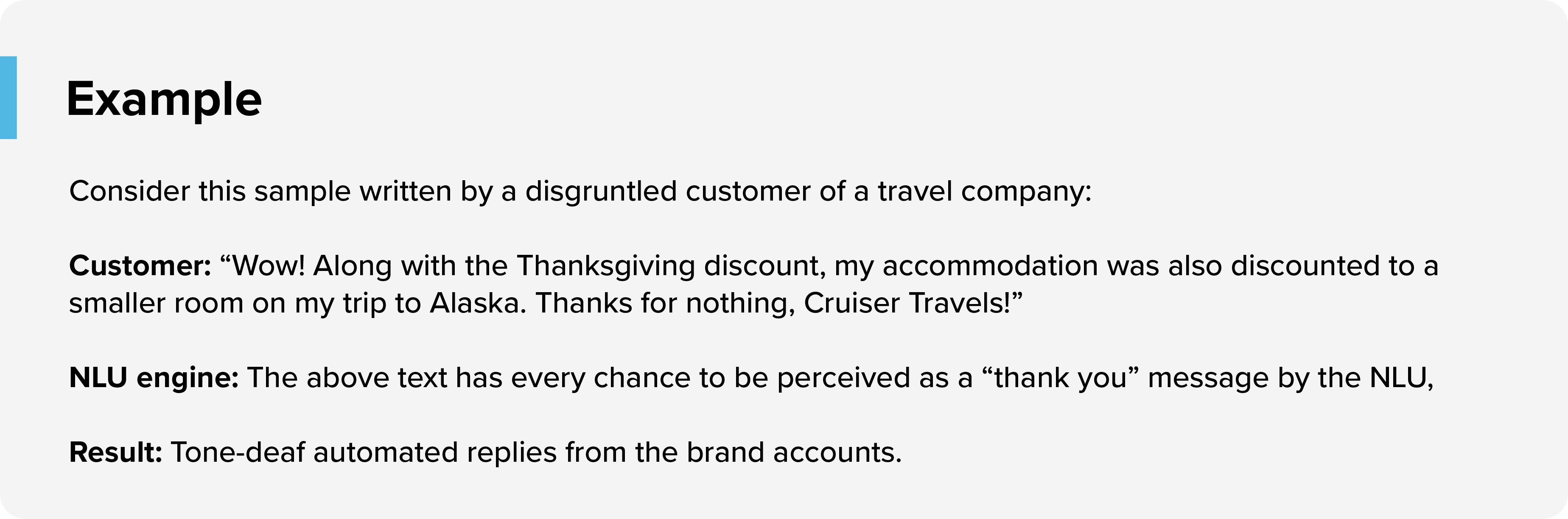
Как это исправить: один из способов решить эту проблему — добавить ключевые слова, такие как «спасибо, вау, что угодно», которые будут запускаться агентами перед утверждением автоматического ответа механизма NLU.

двусмысленность
Иногда люди изо всех сил пытаются различить, используется ли слово в предложении как существительное, глагол или прилагательное. Фразовые глаголы, такие как «повесить» или «потушить», также могут повлиять на распознавание механизма NLU.
Как это исправить: лучший способ уменьшить двусмысленность — продолжать обучать движок NLU неоднозначным предложениям и фразам. Со временем движок начинает учиться на тестовых входных данных, сравнивая их с реальным взаимодействием пользователя.
Другие способы уменьшить неоднозначность в механизмах NLU и чат-ботах AI:
Используйте модели машинного обучения для лучшего обучения NLU : используйте контекстно-зависимые модели машинного обучения, такие как представления двунаправленного кодировщика из преобразователей (BERT) и встраивания из языковой модели (ELMo), для обучения вашего механизма NLU. Эти модели ИИ учитывают все различные представления слов и предложений и используют дополнительный текст для заполнения неоднозначных пользовательских записей.
Создавайте соответствующие подсказки для перепроверки языковых неопределенностей . Включите механизм NLU для предоставления ответов «устранения неоднозначности», которые предлагают пользователям выбрать правильную версию своего текста из более чем одной возможности. Это очень похоже на подсказку «Вы имели в виду…» от Google, которая содержит возможные варианты вашего поискового запроса.
Тренируйтесь и тренируйтесь еще больше : тщательно тренируйте свои двигатели NLU, чтобы отделять сигналы от шума. Нет более быстрого пути к лучшему обнаружению намерений, чем обучение вашего механизма NLU разнообразными и уникальными наборами данных. Запросы пользователей могут содержать слова и предложения, которые влияют на возможности маркировки намерений механизма NLU.

Языковые ошибки
Орфографические ошибки и неправильное построение предложений могут помешать механизму NLU точно определить намерения пользователя. В то время как проверки грамматики могут исправить основные ошибки, сленг и разговорный язык трудно интерпретировать, особенно при преобразовании текста в речь и анализе речи.
Как это исправить: еще раз, ключом к преодолению этой проблемы является загрузка механизма NLU огромным набором неточных фиктивных высказываний, загруженных ошибками и неправильным языком.
Варианты домена
Доменная речь — это еще одна область, которая отличается от одной отрасли к другой. «Документация» в здравоохранении может отличаться от рабочего процесса «документации» в технологиях.
Как это исправить: четкое определение иерархии намерений может помочь вашему механизму NLU определить отрасль или область, с которой связан ответ или высказывание клиента.
Качества, которые характеризуют лучшие двигатели NLU
Когнитивные способности двигателей NLU — это лишь один из факторов, которые следует учитывать при их оценке для вашей компании. Это помогает преодолеть утомительную ручную работу, которая мешает понять намерения пользователя в масштабе.
Кроме того, вот еще несколько важных качеств, на которые следует обращать внимание в движке NLU:
1. Скорость
Механизм NLU должен быстро выдавать результаты, поскольку диалоговый ИИ помогает понять намерение клиента ответить быстро и точно. Скорость обработки взаимодействия с клиентом не должна снижать точность обнаружения намерений механизма NLU.
2. Вертикализация
Двигатели NLU имеют множество вариантов использования, охватывающих такие отрасли, как технологии, розничная торговля, электронная коммерция, логистика и гостиничный бизнес. Функциональность диалогового ИИ должна уметь различать эти отрасли и адаптироваться к каждой области решения с уникальным подходом.
3. Простота использования
Обратите внимание на механизмы NLU, которые включают профили нетехнических сотрудников. Понимание того, как тестировать и обучать наборы данных, не должно ограничиваться инженерами по обеспечению качества и разработчиками. Это то, что владельцы бизнеса без технического образования могут сделать сами. Диалоговый искусственный интеллект, основанный на механизмах NLU без кода, — это способ улучшить внедрение и удобство использования.
4. Масштабируемость
По мере того, как механизм NLU собирает все больше и больше входных данных, ему приходится тренироваться в различной региональной семантике, лингвистических вариациях и различных объектах пользовательского выражения. Создайте среду NLU, которая может обрабатывать несколько языков, и подготовьте своих диалоговых чат-ботов с искусственным интеллектом к будущему .
Что делает движок Sprinklr NLU лидером на рынке диалогового ИИ?
Механизм искусственного интеллекта Sprinklr специально создан для понимания и контекстуализации всего спектра управления качеством обслуживания клиентов. Вот семь отличий, которые отличают ИИ Sprinklr от обычных диалоговых платформ ИИ:
1. Точная классификация сообщений
Автоматически читайте, расшифровывайте и анализируйте сообщения клиентов, классифицируйте их как намерения и определяйте внутренние команды для точного распределения дел.
2. Тщательное обнаружение кризисов
Запускайте оповещения, когда взаимодействие с клиентом выходит из-под контроля, используя заранее определенные параметры, такие как негативные упоминания бренда и ключевые слова, или выявленные ИИ признаки дистресса, такие как обнаружение настроений.
3. Контекстно-зависимая виртуальная помощь
Создавайте автоматические ответы клиентам или предоставляйте агентам помощь ИИ на основе доступных данных о клиентах, базы знаний и истории взаимодействий по каналам.
4. Прогнозный анализ, готовый к будущему
Предвидьте не только обслуживание клиентов, но и рыночные тенденции, такие как популярные темы, макроэкономика, настроения потребителей, PR-кризисы и изменение отраслевых ориентиров, чтобы скорректировать свои продукты и маркетинговые планы. ИИ Sprinklr может распознавать закономерности в цифровых каналах, демографические данные клиентов и многое другое с разбивкой по контексту данных.

5. Умные визуальные интерпретации
Обрабатывайте визуальные данные, связанные с взаимодействием бренда и клиентов, для точного определения изображений и видео без участия человека.
6. Сквозная студия искусственного интеллекта
Обучайте, тестируйте и развертывайте модели ИИ в Sprinklr для лучшего прослушивания социальных сетей, классификации сообщений, диалогового ИИ и чат-ботов, автоматизации ответов и сообществ самообслуживания .
7. Модерация взаимодействия с брендом
Отслеживайте каждое взаимодействие агента с клиентом, чтобы обеспечить соблюдение внутренних правил бренда, и создавайте отчеты, чтобы определить области улучшения для повышения удовлетворенности клиентов (CSAT) и сокращения основных факторов, побуждающих к контакту.
Вы хотите масштабировать свою поддержку клиентов с автоматической персонализацией и операционной эффективностью? Механизм NLU Sprinklr может стать мостом, в котором вы нуждаетесь — он поставляется с миллионами прогнозов ИИ, точек данных и сотнями мгновенно развертываемых моделей ИИ.
Начните бесплатную пробную версию Modern Care Lite
Узнайте, как Sprinklr помогает компаниям предоставлять первоклассные услуги на более чем 13 каналах, используя базовый ИИ, чтобы вы могли слушать, направлять, разрешать и измерять — во всем клиентском опыте.