
Noindex Nofollow и Disallow: директивы поискового робота
Опубликовано: 2022-12-01Есть три директивы (команды), которые вы можете использовать, чтобы указать, как поисковые системы обнаруживают, сохраняют и предоставляют информацию с вашего сайта в качестве результатов поиска:
- NoIndex: Не добавлять мою страницу в результаты поиска.
- NoFollow: не смотрите ссылки на этой странице.
- Запретить: вообще не смотреть на эту страницу.
Эти директивы позволяют вам контролировать, какие страницы вашего сайта могут сканироваться поисковыми системами и отображаться в результатах поиска.
Что означает отсутствие индекса?
Директива noindex указывает поисковым роботам, таким как googlebot, не включать веб-страницу в результаты поиска.

Как пометить страницу как NoIndex?
Есть два способа ввести директиву noindex :
- Добавьте метатег noindex в HTML-код страницы.
- Вернуть заголовок noindex в HTTP-запросе
Используя метатег «без индекса» для страницы или заголовок ответа HTTP, вы, по сути, скрываете страницу от поиска.
Директиву noindex также можно использовать для блокировки только определенных поисковых систем. Например, вы можете запретить Google индексировать страницу, но разрешить Bing:
Пример: блокировка большинства поисковых систем*
<meta name="robots" content="noindex">
Пример: блокировка только Google
<meta name="googlebot" content="noindex">
Обратите внимание: с сентября 2019 года Google больше не соблюдает директивы noindex в файле robots.txt . Noindex теперь ДОЛЖЕН быть выдан через метатег HTML или заголовок ответа HTTP. Для более продвинутых пользователей функция disallow все еще работает, хотя и не во всех случаях.
В чем разница между noindex и nofollow?
Это разница между хранением контента и обнаружением контента:
noindex применяется на уровне страницы и указывает сканеру поисковой системы не индексировать и не отображать страницу в результатах поиска.
nofollow применяется на уровне страницы или ссылки и сообщает сканеру поисковой системы не переходить (обнаруживать) ссылки.
По сути, тег noindex удаляет страницу из поискового индекса, а атрибут nofollow удаляет ссылку из графа ссылок поисковой системы.
NoFollow как атрибут страницы
Использование nofollow на уровне страницы означает, что сканеры не будут переходить ни по одной из ссылок на этой странице, чтобы обнаружить дополнительный контент, и сканеры не будут использовать ссылки в качестве сигналов ранжирования для целевых сайтов.
<meta name="robots" content="nofollow">
NoFollow как атрибут ссылки
Использование nofollow на уровне ссылки не позволяет поисковым роботам исследовать ссылку на конкретную рекламу и не позволяет использовать эту ссылку в качестве сигнала ранжирования.
Директива nofollow применяется на уровне ссылки с использованием атрибута rel внутри тега href:
<a href="https://domain.com" rel="nofollow">
В частности, для Google использование атрибута ссылки nofollow предотвратит передачу вашего сайта PageRank на целевые URL-адреса.
Почему вы должны пометить страницу как NoFollow?
В большинстве случаев не следует помечать как nofollow всю страницу — достаточно пометить отдельные ссылки как nofollow.
Вы должны пометить всю страницу как nofollow , если не хотите, чтобы Google просматривал ссылки на странице, или если вы считаете, что ссылки на странице могут повредить вашему сайту.
В большинстве случаев общие директивы nofollow на уровне страницы используются, когда вы не контролируете контент, публикуемый на странице Некоторые высококлассные издатели также полностью применяли директиву nofollow к своим страницам, чтобы отговорить своих авторов от размещения рекламных ссылок в своем контенте.
Как использовать страницы без индекса?
Помечайте как неиндексируемые страницы, которые вряд ли будут представлять ценность для пользователей и не должны отображаться в результатах поиска. Например, маловероятно, что страницы, которые существуют для разбиения на страницы, со временем будут отображать одно и то же содержимое.
Domain.com/category/resultspage=2 вряд ли покажет пользователю лучшие результаты, чем domain.com/category/resultspage=1 , и эти две страницы будут конкурировать друг с другом только в поиске. Лучше не индексировать страницы, единственной целью которых является нумерация страниц.
Вот типы страниц, которые вы не должны индексировать:
- Страницы, используемые для пагинации
- Страницы внутреннего поиска
- Целевые страницы, оптимизированные для рекламы
- Пример. Отображает только поле и форму регистрации, без основной навигации.
- Пример: повторяющиеся варианты одного и того же контента, используемые только для рекламы.
- Архивные авторские страницы
- Страницы в потоках оформления заказа
- Страницы подтверждения
- Пример: страницы благодарности
- Пример: Заказать полные страницы
- Например: Успех! Страницы
- Некоторые страницы, созданные плагином, которые не имеют отношения к вашему сайту (например, если вы используете коммерческий плагин, но не используете их обычные страницы продуктов)
- Страницы администратора и страницы входа администратора
Пометка страницы Noindex и Nofollow
Страница, помеченная как noindex, так и nofollow, заблокирует индексацию этой страницы поисковым роботом и блокирует просмотр ссылок на странице.
По сути, изображение ниже демонстрирует, что поисковая система увидит на веб-странице в зависимости от того, как вы использовали директивы noindex и nofollow:

Пометка уже проиндексированной страницы как NoIndex
Если поисковая система уже проиндексировала страницу, а вы пометили ее как noindex , то при следующем сканировании страница будет удалена из результатов поиска Чтобы этот метод удаления страницы из индекса работал, вы не должны блокировать (запрещать) поисковый робот своим файлом robots.txt.
Если вы говорите сканеру не читать страницу, он никогда не увидит маркер noindex , и страница останется проиндексированной, хотя ее содержимое не будет обновляться.
Как запретить поисковым системам индексировать мой сайт?
Если вы хотите удалить страницу из поискового индекса, после того как она уже была проиндексирована, вы можете выполнить следующие действия:
- Примените директиву noindex . Добавьте атрибут noindex в метатег или заголовок ответа HTTP.
- Запросите поисковую систему просканировать страницу. Для Google вы можете сделать это в консоли поиска, запросив переиндексацию страницы Google. Это приведет к тому, что робот Googlebot просканирует страницу, где робот Googlebot обнаружит директиву noindex. Вам нужно будет сделать это для каждой поисковой системы, для которой вы хотите удалить страницу.
- Подтвердите, что страница была удалена из поиска После того, как вы запросили сканер повторно посетить вашу веб-страницу, подождите некоторое время, а затем подтвердите, что ваша страница была удалена из результатов поиска. Вы можете сделать это, зайдя в любую поисковую систему и введя целевой URL-адрес сайта, как на изображении ниже.
Если ваш поиск не дал результатов, ваша страница была удалена из этого поискового индекса. - Если страница не была удалена Убедитесь, что в вашем файле robots.txt нет директивы «запретить». Google и другие поисковые системы не могут прочитать директиву noindex, если им не разрешено сканировать страницу. Если вы это сделаете, удалите директиву disallow для целевой страницы, а затем снова запросите сканирование.
- Установите директиву disallow для целевой страницы в файле robots.txt Disallow: /page$
Вам нужно будет поставить знак доллара в конце URL-адреса в файле robots.txt, иначе вы можете случайно запретить любые страницы под этой страницей, а также любые страницы, начинающиеся с той же строки. Пример: Disallow: /sweater также запретит /sweater-weather и /sweater/green, но Disallow: /sweater$ запретит только конкретную страницу /sweater.
Как удалить страницу из поиска Google
Если страница, которую вы хотите удалить из поиска, находится на сайте, которым вы владеете или управляете, на большинстве сайтов можно использовать инструмент для удаления URL для веб-мастеров.
Инструмент удаления URL-адресов для веб-мастеров удаляет контент из поиска примерно на 90 дней. Если вам нужно более постоянное решение, вам нужно будет использовать директиву noindex, запретить сканирование из вашего файла robots.txt или удалить страницу с вашего сайта. Google предоставляет дополнительные инструкции по постоянному удалению URL здесь.

Если вы пытаетесь удалить страницу из поиска сайта, которым вы не владеете, вы можете запросить Google удалить страницу из поиска, если она соответствует следующим критериям:
- Отображает личную информацию, такую как ваша кредитная карта или номер социального страхования
- Страница является частью вредоносного ПО или фишинговой схемы
- Страница нарушает закон
- Страница нарушает авторские права
Если страница не соответствует ни одному из вышеперечисленных критериев, вы можете обратиться в SEO-фирму или PR-компанию за помощью в управлении онлайн-репутацией.
Следует ли не индексировать страницы категорий?
Обычно не рекомендуется не индексировать страницы категорий, если только вы не являетесь организацией корпоративного уровня, раскручивающей страницы категорий программно на основе пользовательского поиска или тегов, и дублированный контент становится громоздким.
По большей части, если вы разумно помечаете свой контент, чтобы помочь пользователям лучше ориентироваться на вашем сайте и находить то, что им нужно, тогда все будет в порядке.
На самом деле, страницы категорий могут быть золотыми жилами для SEO, поскольку они обычно показывают глубину контента в темах категорий.
Взгляните на этот анализ, который мы провели в декабре 2018 года, чтобы количественно оценить ценность страниц категорий для нескольких онлайн-публикаций.
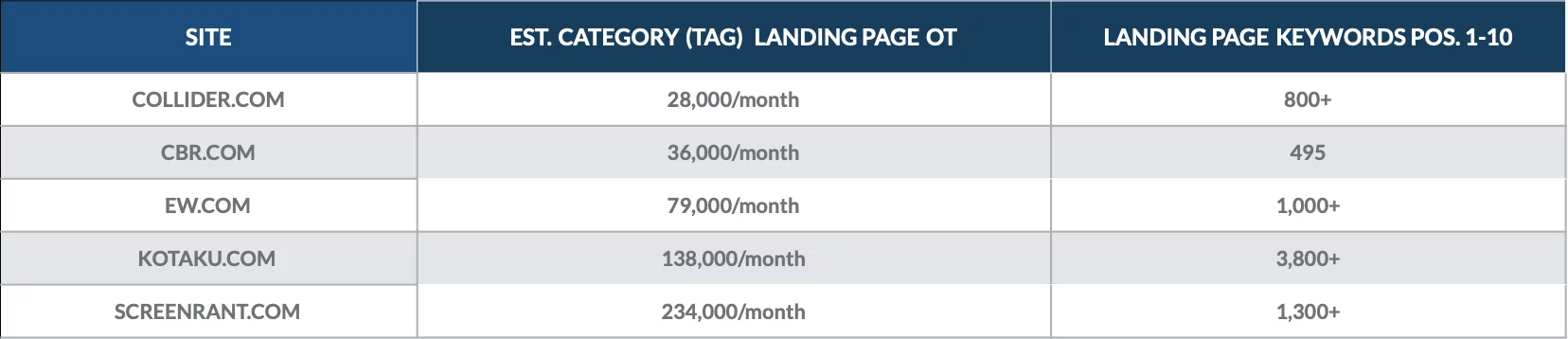
Мы обнаружили, что целевые страницы категории ранжируются по сотням ключевых слов страницы 1 и ежемесячно привлекают тысячи органических посетителей.
Страницы наиболее ценных категорий для каждого сайта часто приносили тысячи органических посетителей каждая.
Взгляните на EW.com ниже, мы измерили трафик каждой страницы (представленный размером круга) и значение трафика на каждой странице (представленный цветом круга).
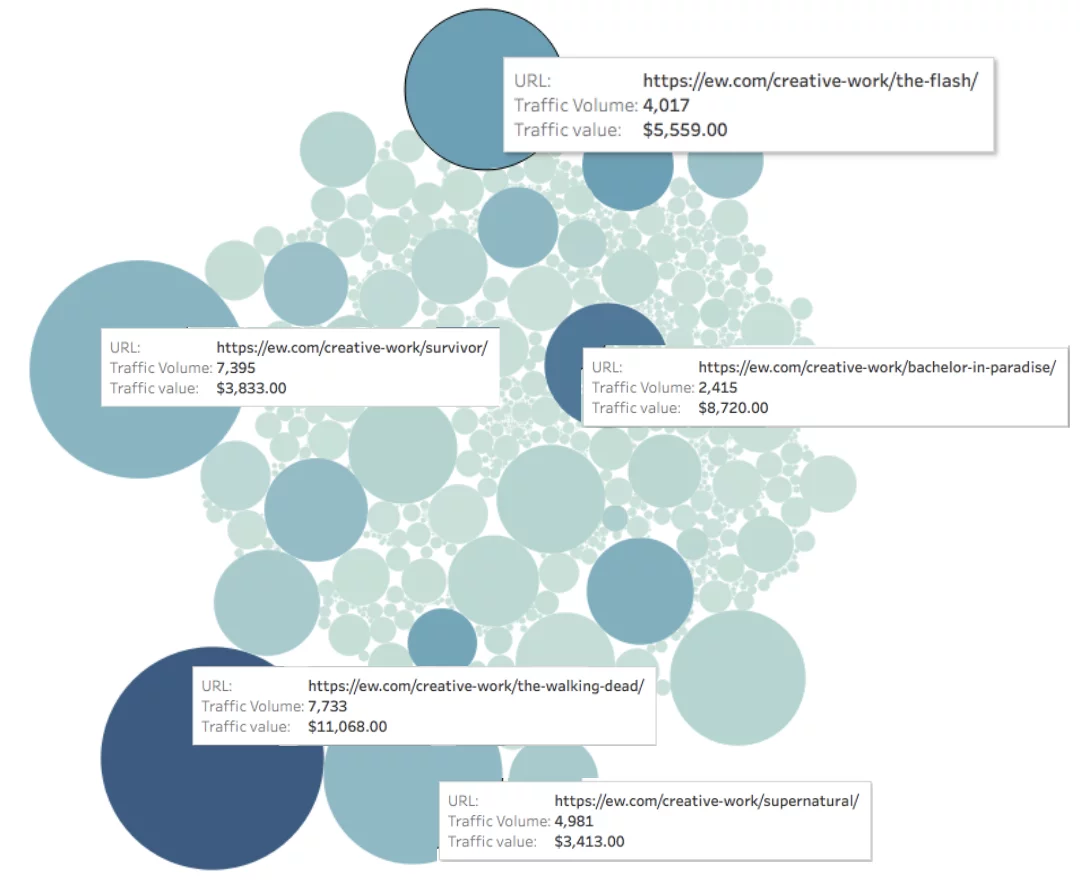
Ежемесячная органическая ценность страницы = глубина цвета
Теперь представьте те же диаграммы, но для продуктовых сайтов, где посетители, скорее всего, совершат активные покупки.
При этом, если ваши категории достаточно похожи, чтобы сбивать пользователей с толку или конкурировать друг с другом в поиске, вам может потребоваться внести изменения:
- Если вы устанавливаете категории самостоятельно, мы рекомендуем перенести контент из одной категории в другую и уменьшить общее количество категорий, которые у вас есть.
- Если вы разрешаете пользователям раскручивать категории, вы можете не индексировать созданные пользователями страницы категорий, по крайней мере, до тех пор, пока новые категории не пройдут процесс проверки.
Как запретить Google индексировать поддомены?
Есть несколько способов запретить Google индексировать субдомены:
- Вы можете добавить пароль, используя файл .htpasswd
- Вы можете запретить поисковые роботы с помощью файла robots.txt.
- Вы можете добавить директиву noindex на каждую страницу субдомена.
- Вы можете 404 все страницы поддоменов
Добавление пароля для блокировки индексации
Если ваши поддомены предназначены для целей разработки, то идеальным вариантом будет добавление файла .htpasswd в корневой каталог вашего поддомена. Стена входа не позволит поисковым роботам индексировать контент в поддомене, а также предотвратит несанкционированный доступ пользователей.
Примеры использования:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
Использование robots.txt для блокировки индексации
Если ваши субдомены служат другим целям, вы можете добавить файл robots.txt в корневой каталог вашего субдомена. Затем он должен быть доступен следующим образом:
https://subdomain.domain.com/robots.txt
Вам нужно будет добавить файл robots.txt к каждому поддомену, который вы пытаетесь заблокировать от поиска. Пример:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
В каждом случае файл robots.txt должен запрещать поисковые роботы. Чтобы заблокировать большинство поисковых роботов с помощью одной команды, используйте следующий код:
Пользовательский агент: *
Запретить: /
Звездочка * после user-agent: называется подстановочным знаком, она будет соответствовать любой последовательности символов. Использование подстановочного знака отправит следующую директиву disallow всем пользовательским агентам, независимо от их имени, от googlebot до yandex.
Обратная косая черта сообщает сканеру, что все страницы вне субдомена включены в директиву disallow.
Как выборочно заблокировать индексацию страниц поддоменов
Если вы хотите, чтобы некоторые страницы субдомена отображались в поиске, но не отображались другие, у вас есть два варианта:
- Используйте директивы noindex на уровне страницы
- Используйте директивы запрета на уровне папки или каталога
Директивы noindex на уровне страницы будут более громоздкими для реализации, поскольку директиву необходимо добавлять в HTML или заголовок каждой страницы. Однако директивы noindex не позволят Google индексировать поддомен независимо от того, был ли он уже проиндексирован или нет.
Директивы запрета на уровне каталога проще реализовать, но они будут работать только в том случае, если страницы поддоменов еще не включены в поисковый индекс. Просто обновите файл robots.txt поддомена, чтобы запретить сканирование соответствующих каталогов или подпапок.
Как узнать, не проиндексированы ли мои страницы?
Случайное добавление страниц без индекса на ваш сайт может иметь серьезные последствия для вашего поискового рейтинга и видимости в поиске.
Если вы обнаружите, что страница не получает органического трафика, несмотря на хороший контент и обратные ссылки, сначала проверьте, не запретили ли вы случайно поисковые роботы в файле robots.txt. Если это не решит вашу проблему, вам нужно будет проверить отдельные страницы на наличие директив noindex.
Проверка NoIndex на страницах WordPress
WordPress упрощает добавление или удаление этого тега на ваших страницах. Первым шагом в проверке наличия nofollow на ваших страницах является простое переключение параметра « Видимость в поисковых системах » на вкладке «Чтение» в меню «Настройки».
Это, вероятно, решит проблему, однако этот параметр работает как «предложение», а не как правило, и часть вашего контента все равно может быть проиндексирована.
Чтобы обеспечить абсолютную конфиденциальность ваших файлов и контента, вам нужно будет сделать последний шаг: либо защитить свой сайт паролем с помощью инструментов управления cPanel, если они доступны, либо с помощью простого плагина.
Точно так же удалить этот тег из вашего контента можно, сняв защиту паролем и сняв флажок в настройках видимости.
Проверка NoIndex на Squarespace
Страницы Squarespace также легко неиндексируются с помощью платформы Code Injection. Как и WordPress, Squarespace можно легко заблокировать от рутинных поисков с помощью защиты паролем, однако платформа также рекомендует не делать этого шага, чтобы защитить целостность вашего контента.
Добавляя строку кода NoIndex на каждую страницу, которую вы хотите скрыть от поисковых систем в Интернете, и на каждую подстраницу под ней, вы можете обеспечить безопасность защищенного контента, доступ к которому должен быть закрыт. Как и на других платформах, удаление этого тега также довольно просто: просто используйте функцию «Внедрение кода», чтобы вернуть код, — это все, что вам нужно сделать.
Squarespace уникален тем, что его конкуренты предлагают эту опцию в первую очередь как часть набора настроек в инструментах управления страницами. Squarespace уходит отсюда, позволяя лично манипулировать кодом. Это интересно, потому что вы можете видеть изменения, которые вы вносите в содержание своей страницы, в отличие от других в этом пространстве.
Проверка NoIndex на Wix
Wix также позволяет просто и быстро исправить проблемы с отсутствием индексации. В настройках «Меню и страницы» вы можете просто деактивировать опцию «показывать эту страницу в результатах поиска», если вы хотите не индексировать одну страницу на вашем сайте.
Как и его конкуренты, Wix также предлагает пароль для защиты ваших страниц или всего сайта для дополнительной конфиденциальности. Однако Wix отличается от других тем, что служба поддержки не предписывает параллельные действия на обоих фронтах, чтобы обезопасить контент от сканера. Wix особо отмечает разницу между скрытием страницы в вашем меню и ее скрытием в критериях поиска.
Это особенно полезный совет для менее опытных создателей веб-сайтов, которые могут изначально не понимать разницы, учитывая, что удаление из меню вашего сайта делает страницу недоступной с сайта, но не из благоразумного поискового запроса Google.