
Тематическое моделирование с Word2Vec
Опубликовано: 2022-05-02Слово определяется компанией, которую оно держит. Это предпосылка Word2Vec, метода преобразования слов в числа и представления их в многомерном пространстве. Слова, которые часто встречаются близко друг к другу в коллекции документов (корпусе), также будут отображаться близко друг к другу в этом пространстве. Говорят, что они связаны контекстуально.
Word2Vec — это метод машинного обучения, требующий корпуса и надлежащего обучения. Качество обоих влияет на его способность точно моделировать тему. Любые недостатки становятся очевидными при изучении выходных данных для очень специфических и сложных тем, поскольку их труднее всего точно смоделировать. Word2Vec можно использовать сам по себе, хотя его часто комбинируют с другими методами моделирования, чтобы устранить его ограничения.
В оставшейся части этой статьи представлены дополнительные сведения о Word2Vec, о том, как он работает, как он используется в тематическом моделировании, а также о некоторых проблемах, с которыми он сталкивается.
Что такое Word2Vec?
В сентябре 2013 года исследователи Google Томас Миколов, Кай Чен, Грег Коррадо и Джеффри Дин опубликовали статью «Эффективная оценка представлений слов в векторном пространстве» (pdf). Это то, что мы теперь называем Word2Vec. Цель статьи заключалась в том, чтобы «представить методы, которые можно использовать для изучения высококачественных векторов слов из огромных наборов данных с миллиардами слов и миллионами слов в словаре».
До этого момента любые методы обработки естественного языка рассматривали слова как единичные единицы. Они не принимали во внимание какое-либо сходство между словами. Хотя для такого подхода были веские причины, у него были свои ограничения. Были ситуации, в которых масштабирование этих основных методов не могло дать значительных улучшений. Отсюда необходимость развития передовых технологий.
В документе показано, что простые модели с их более низкими вычислительными требованиями могут обучать высококачественные векторы слов. Как делается вывод в документе, «можно вычислить очень точные многомерные векторы слов из гораздо большего набора данных». Речь идет о коллекциях документов (корпусах) с одним триллионом слов, обеспечивающих практически неограниченный словарный запас.
Word2Vec — это способ преобразования слов в числа, в данном случае в векторы, чтобы сходство можно было обнаружить математически. Идея состоит в том, что векторы похожих слов группируются в векторном пространстве.
Подумайте о широтных и долготных координатах на карте. Используя этот двумерный вектор, вы можете быстро определить, находятся ли два местоположения относительно близко друг к другу. Для правильного представления слов в векторном пространстве двух измерений недостаточно. Таким образом, векторы должны включать в себя множество измерений.
Как работает Word2Vec?
Word2Vec принимает на вход большой текстовый корпус и векторизует его с помощью неглубокой нейронной сети. На выходе получается список слов (словарь), каждому соответствует свой вектор. Слова с похожим значением пространственно встречаются в непосредственной близости. Математически это измеряется косинусным сходством, где полное сходство выражается как угол 0 градусов, а отсутствие сходства выражается как угол 90 градусов.
Слова могут быть закодированы как векторы с использованием различных типов моделей. В своей статье Миколов и соавт. рассмотрел две существующие модели: языковую модель нейронной сети с прямой связью (NNLM) и языковую модель рекуррентной нейронной сети (RNNLM). Кроме того, они предлагают две новые логарифмически-линейные модели, непрерывный пакет слов (CBOW) и непрерывный Skip-gram.
В своих сравнениях CBOW и Skip-gram показали лучшие результаты, поэтому давайте рассмотрим эти две модели.
CBOW похож на NNLM и полагается на контекст для определения целевого слова. Он определяет целевое слово на основе слов, которые стоят до и после него. Миколов обнаружил, что наилучшее исполнение произошло с четырьмя будущими и четырьмя историческими словами. Это называется «мешок слов», потому что порядок слов в истории не влияет на вывод. «Непрерывный» в термине CBOW относится к использованию «непрерывного распределенного представления контекста».
Skip-gram — это обратная сторона CBOW. Учитывая слово, он предсказывает окружающие слова в пределах определенного диапазона. Больший диапазон обеспечивает лучшее качество векторов слов, но увеличивает вычислительную сложность. Меньший вес придается отдаленным терминам, потому что они обычно меньше связаны с текущим словом.
При сравнении CBOW с Skip-gram было обнаружено, что последний дает более качественные результаты на больших наборах данных. Хотя CBOW быстрее, Skip-gram лучше обрабатывает редко используемые слова.
При обучении каждому слову присваивается вектор. Компоненты этого вектора настраиваются таким образом, чтобы похожие слова (в зависимости от их контекста) располагались ближе друг к другу. Думайте об этом как о перетягивании каната, где слова толкаются и тянутся в этом многомерном векторе каждый раз, когда в пространство добавляется новый термин.
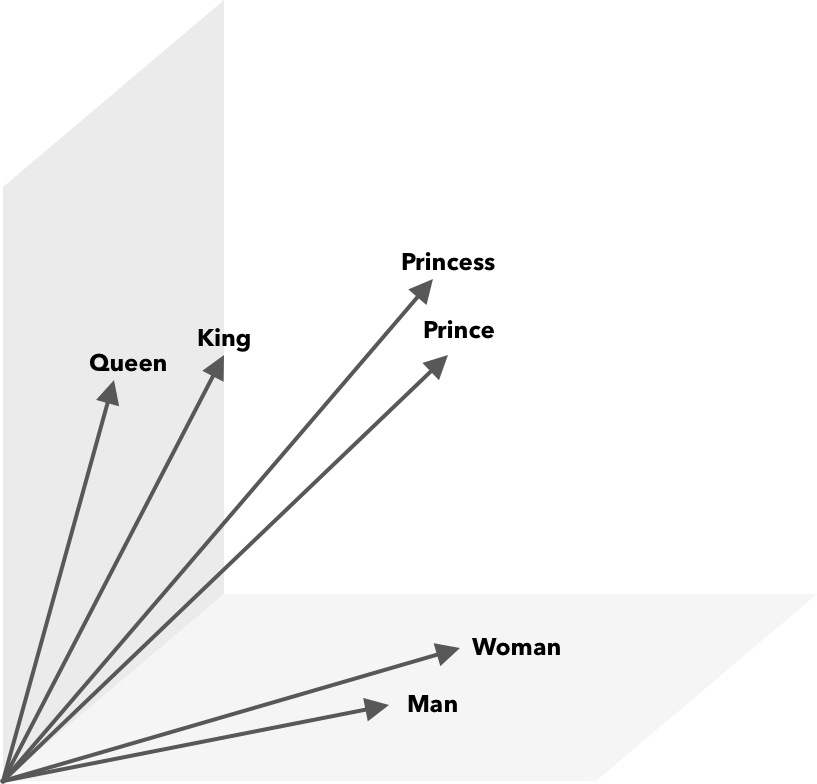
Математические операции, помимо косинусного сходства, могут выполняться над векторами слов. Например, вектор («Король») – вектор («Мужчина») + вектор («Женщина») дает вектор, ближайший к вектору, представляющему слово «Королева».

Word2Vec для тематического моделирования
Словарь, созданный Word2Vec, можно запрашивать напрямую для выявления взаимосвязей между словами или вводить в нейронную сеть с глубоким обучением. Одна проблема с алгоритмами Word2Vec, такими как CBOW и Skip-gram, заключается в том, что они одинаково взвешивают каждое слово. Проблема, возникающая при работе с документами, заключается в том, что слова не в равной степени отражают смысл предложения.
Некоторые слова важнее других. Таким образом, для разрешения ситуации часто используются различные стратегии взвешивания, такие как TF-IDF. Это также помогает решить проблему ступицы, упомянутую в следующем разделе. Searchmetrics ContentExperience использует комбинацию TF-IDF и Word2Vec, о которой вы можете прочитать здесь в нашем сравнении с MarketMuse.
В то время как вложения слов, такие как Word2Vec, захватывают морфологическую, семантическую и синтаксическую информацию, моделирование тем направлено на обнаружение скрытых семантических структур или тем в корпусе.
По словам Будхкара и Рудзича (PDF), сочетание скрытого распределения Дирихле (LDA) с Word2Vec может создавать дискриминационные функции для «решения проблемы, вызванной отсутствием контекстной информации, встроенной в эти модели». Более легкое чтение по LDA2vec можно найти в этом руководстве по DataCamp.
Проблемы Word2Vec
Есть несколько проблем с встраиванием слов в целом, включая Word2Vec. Мы коснемся некоторых из них, для более подробного анализа обратитесь к «Обзору методов оценки встраивания слов» (pdf) Амира Бакарова. Корпус и его размер, а также само обучение существенно повлияют на качество вывода.
Как вы оцениваете результат?
Как объясняет Бакаров в своей статье, инженер NLP обычно оценивает производительность встраивания иначе, чем компьютерный лингвист или контент-маркетолог, если уж на то пошло. Вот некоторые дополнительные вопросы, упомянутые в документе.
- Семантика — расплывчатая идея. «Хорошее» встраивание слов отражает наше представление о семантике. Однако мы можем не осознавать, правильно ли наше понимание. Кроме того, слова имеют разные типы отношений, такие как семантическая родственность и семантическое сходство. Какие отношения должно отражать встраивание слова?
- Отсутствие надлежащих обучающих данных. При обучении встраивания слов исследователи часто повышают их качество, адаптируя их к данным. Это то, что мы называем подгонкой кривой. Вместо того, чтобы приводить результат в соответствие с данными, исследователи должны попытаться уловить взаимосвязь между словами.
- Отсутствие корреляции между внутренними и внешними методами означает, что неясно, какой класс методов предпочтительнее. Внешняя оценка определяет качество вывода для дальнейшего использования в других задачах обработки естественного языка. Внутренняя оценка опирается на человеческое суждение о словесных отношениях.
- Проблема ступицы. Хабы, векторы слов, представляющие общие слова, близки к чрезмерному количеству других векторов слов. Этот шум может исказить оценку.
Кроме того, в частности, с Word2Vec есть две серьезные проблемы.
- Он не может хорошо справляться с двусмысленностью. В результате вектор многозначности слова отражает среднее, что далеко от идеала.
- Word2Vec не может обрабатывать слова вне словаря (OOV) и морфологически похожие слова. Когда модель сталкивается с новой концепцией, она прибегает к использованию случайного вектора, который не является точным представлением.
Резюме
Использование Word2Vec или любого другого встраивания слов не является гарантией успеха. Качественный результат зависит от надлежащего обучения с использованием соответствующего и достаточно большого корпуса.
Хотя оценка качества вывода может быть обременительной, вот простое решение для контент-маркетологов. В следующий раз, когда вы будете оценивать оптимизатор контента, попробуйте использовать очень конкретную тему. Тематические модели низкого качества терпят неудачу, когда дело доходит до тестирования таким образом. Они хороши для общих терминов, но ломаются, когда запрос становится слишком конкретным.
Итак, если вы используете тему «как вырастить авокадо», убедитесь, что предложения имеют какое-то отношение к выращиванию растения, а не к авокадо в целом.
В создании этой статьи помогла технология генерации естественного языка MarketMuse NLG.
Что вы должны сделать сейчас
Когда вы будете готовы... Вот 3 способа, которыми мы можем помочь вам публиковать более качественный контент и быстрее:
- Забронируйте время с MarketMuse Запланируйте живую демонстрацию с одним из наших специалистов по стратегии, чтобы увидеть, как MarketMuse может помочь вашей команде достичь своих целей в отношении контента.
- Если вы хотите узнать, как быстрее создавать качественный контент, посетите наш блог. Он полон ресурсов, помогающих масштабировать контент.
- Если вы знаете другого маркетолога, которому было бы интересно прочитать эту страницу, поделитесь ею с ним по электронной почте, LinkedIn, Twitter или Facebook.