
Что такое краулинговый бюджет и как его разумно оптимизировать?
Опубликовано: 2021-08-19Оглавление
Анализ краулингового бюджета входит в обязанности любого SEO-специалиста (особенно если он работает с крупными сайтами). Важная задача, достойно освещенная в материалах, предоставленных Google. Тем не менее, как вы можете видеть в Твиттере, даже сотрудники Google преуменьшают роль краулингового бюджета в получении лучшего трафика и рейтинга:
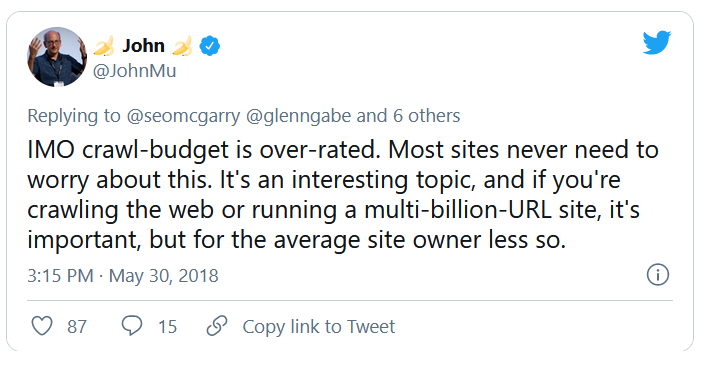

Правы ли они насчет этого?
Как Google работает и собирает данные?
Продолжая тему, давайте вспомним, как поисковая система собирает, индексирует и систематизирует информацию. Важно помнить об этих трех шагах во время дальнейшей работы над веб-сайтом:
Шаг 1: Сканирование . Просмотр онлайн-ресурсов с целью обнаружения и навигации по всем существующим ссылкам, файлам и данным. Как правило, Google начинает с самых популярных мест в Интернете, а затем переходит к сканированию других, менее популярных ресурсов.
Шаг 2: Индексация . Google пытается определить, о чем страница и является ли анализируемый контент/документ уникальным или повторяющимся материалом. На этом этапе Google группирует контент и устанавливает порядок важности (путем чтения предложений в тегах rel="canonical" или rel="alternate" или иным образом).
Шаг 3: Сервировка . После сегментации и индексации данные отображаются в ответ на запросы пользователей. Это также когда Google сортирует данные соответствующим образом, учитывая такие факторы, как местоположение пользователя.
Важно: многие доступные материалы упускают из виду Шаг 4: рендеринг контента . По умолчанию робот Googlebot индексирует текстовый контент. Однако по мере того, как веб-технологии продолжают развиваться, Google пришлось разрабатывать новые решения, чтобы перестать просто «читать» и начать «видеть». Вот что такое рендеринг. Он служит Google для существенного улучшения охвата недавно запущенных веб-сайтов и расширения индекса.
Примечание . Проблемы с рендерингом контента могут быть причиной сбоя краулингового бюджета.
Каков краулинговый бюджет?
Бюджет сканирования — это не что иное, как частота, с которой сканеры и боты поисковых систем могут индексировать ваш веб-сайт, а также общее количество URL-адресов, к которым они могут получить доступ за одно сканирование. Представьте свой краулинговый бюджет в виде кредитов, которые вы можете потратить на сервис или приложение. Если вы не забудете «зарядить» свой краулинговый бюджет, робот замедлится и нанесет вам меньше посещений.
В SEO «зарядка» относится к работе, направленной на получение обратных ссылок или повышение общей популярности веб-сайта. Следовательно, краулинговый бюджет является неотъемлемой частью всей экосистемы Интернета. Когда вы хорошо работаете с контентом и обратными ссылками, вы увеличиваете лимит доступного краулингового бюджета.
В своих ресурсах Google не делает попыток явно определить краулинговый бюджет. Вместо этого он указывает на два основных компонента сканирования, которые влияют на тщательность робота Googlebot и частоту его посещений:
- ограничение скорости сканирования;
- спрос на сканирование.
Что такое ограничение скорости сканирования и как его проверить?
Проще говоря, предел скорости сканирования — это количество одновременных подключений, которые робот Googlebot может установить при сканировании вашего сайта. Поскольку Google не хочет мешать работе пользователей, он ограничивает количество соединений, чтобы обеспечить бесперебойную работу вашего веб-сайта/сервера. Короче говоря, чем медленнее ваш сайт, тем меньше ограничение скорости сканирования.
Важно: Предел сканирования также зависит от общего состояния SEO вашего веб-сайта — если ваш сайт вызывает много переадресаций, ошибок 404/410 или если сервер часто возвращает код состояния 500, количество подключений также уменьшится.
Вы можете анализировать данные об ограничении скорости сканирования с помощью информации, доступной в Google Search Console, в отчете «Статистика сканирования» .
Спрос на сканирование или популярность веб-сайта
В то время как ограничение скорости сканирования требует от вас доработки технических деталей вашего веб-сайта, спрос на сканирование вознаграждает вас за популярность вашего веб-сайта. Грубо говоря, чем больше шума вокруг вашего сайта (и на нем), тем выше спрос на его сканирование.
В этом случае Google анализирует две проблемы:
- Общая популярность — Google чаще запускает частые обходы URL-адресов, которые обычно популярны в Интернете (не обязательно те, на которые есть обратные ссылки с наибольшего количества URL-адресов).
- Свежесть данных индекса — Google стремится предоставлять только самую свежую информацию. Важно: Создание все большего количества нового контента не означает, что ваш общий предел краулингового бюджета увеличивается.
Факторы, влияющие на краулинговый бюджет
В предыдущем разделе мы определили краулинговый бюджет как комбинацию ограничения скорости сканирования и потребности в сканировании. Имейте в виду, что вам нужно позаботиться об обоих одновременно, чтобы обеспечить правильное сканирование (и, следовательно, индексацию) вашего веб-сайта.
Ниже вы найдете простой список моментов, которые следует учитывать при оптимизации краулингового бюджета.
- Сервер — главный вопрос — производительность. Чем ниже ваша скорость, тем выше риск того, что Google выделит меньше ресурсов для индексации вашего нового контента.
- Коды ответа сервера — чем больше на вашем сайте 301 редиректов и ошибок 404/410, тем хуже результаты индексации. Важно: следите за петлями перенаправления — каждый «прыжок» снижает ограничение скорости сканирования вашего сайта для следующего посещения бота.
- Блоки в robots.txt — если вы основываете свои директивы robots.txt на интуиции, вы можете в конечном итоге создать узкие места при индексации. В результате вы очистите индекс, но за счет эффективности индексации новых страниц (когда заблокированные URL-адреса были прочно встроены в структуру всего веб-сайта).
- Фасетная навигация / идентификаторы сеансов / любые параметры в URL-адресах — самое главное, следите за ситуациями, когда адрес с одним параметром может быть параметризован дальше без каких-либо ограничений. Если это произойдет, Google охватит бесконечное количество адресов, потратив все доступные ресурсы на менее важные части нашего веб-сайта.
- Дублированный контент — скопированный контент (помимо каннибализации) значительно снижает эффективность индексации нового контента.
- Тонкий контент — это происходит, когда на странице очень низкое соотношение текста и HTML. В результате Google может идентифицировать страницу как так называемую Soft 404 и ограничить индексацию ее содержания (даже если содержание имеет смысл, что может иметь место, например, на странице производителя, представляющей один продукт, а не уникальное текстовое содержание).
- Плохая внутренняя перелинковка или ее отсутствие .
Полезные инструменты для анализа краулингового бюджета
Поскольку эталона для краулингового бюджета не существует (что означает, что трудно сравнивать лимиты между веб-сайтами), подготовьтесь с помощью набора инструментов, предназначенных для облегчения сбора и анализа данных.
Консоль поиска Google
GSC хорошо выросла за эти годы. Во время анализа краулингового бюджета есть два основных отчета, на которые мы должны обратить внимание: индексирование и статистика сканирования.
Покрытие индекса в GSC
Отчет представляет собой массивный источник данных. Проверим информацию об исключенных из индексации URL. Это отличный способ понять масштаб проблемы, с которой вы столкнулись.
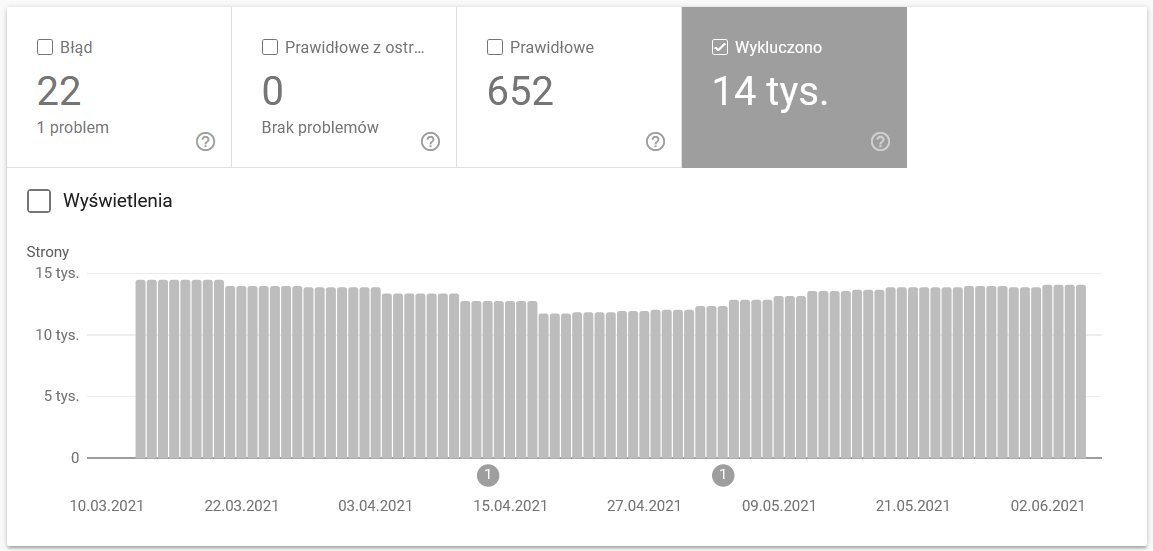
Все отчеты требуют отдельной статьи, поэтому пока давайте сосредоточимся на следующей информации:
- Исключено тегом 'noindex'. Как правило, чем больше страниц без индекса, тем меньше трафика. Напрашивается вопрос – какой смысл держать их на сайте? Как ограничить доступ к этим страницам?
- Просканировано — в настоящее время не проиндексировано — если вы видите это, проверьте, правильно ли контент отображается в глазах робота Googlebot. Помните, что каждый URL с таким статусом тратит впустую ваш краулинговый бюджет, потому что не генерирует органический трафик.
- Обнаружена — в настоящее время не проиндексирована — одна из наиболее тревожных проблем, которую стоит поставить на первое место в списке приоритетов.
- Дублируйте без выбранной пользователем канонической — все дублированные страницы чрезвычайно опасны, поскольку они не только снижают ваш краулинговый бюджет, но и увеличивают риск каннибализации.
- Дубликат, Google выбрал не канонический, а пользовательский — теоретически беспокоиться не о чем. В конце концов, Google должен быть достаточно умен, чтобы принять правильное решение вместо нас. Что ж, на самом деле Google выбирает свои канонические символы довольно случайным образом — часто отсекая ценные страницы с каноническими , указывающими на домашнюю страницу.
- Soft 404 — все «мягкие» ошибки очень опасны, так как могут привести к удалению критических страниц из индекса.
- Дублированный отправленный URL-адрес, не выбранный как канонический — аналогично отчету о состоянии об отсутствии выбранных пользователем канонических.
Статистика сканирования
Отчет не идеален, и что касается рекомендаций, я настоятельно рекомендую также поиграть со старыми добрыми журналами сервера, которые дают более глубокое понимание данных (и больше возможностей моделирования).
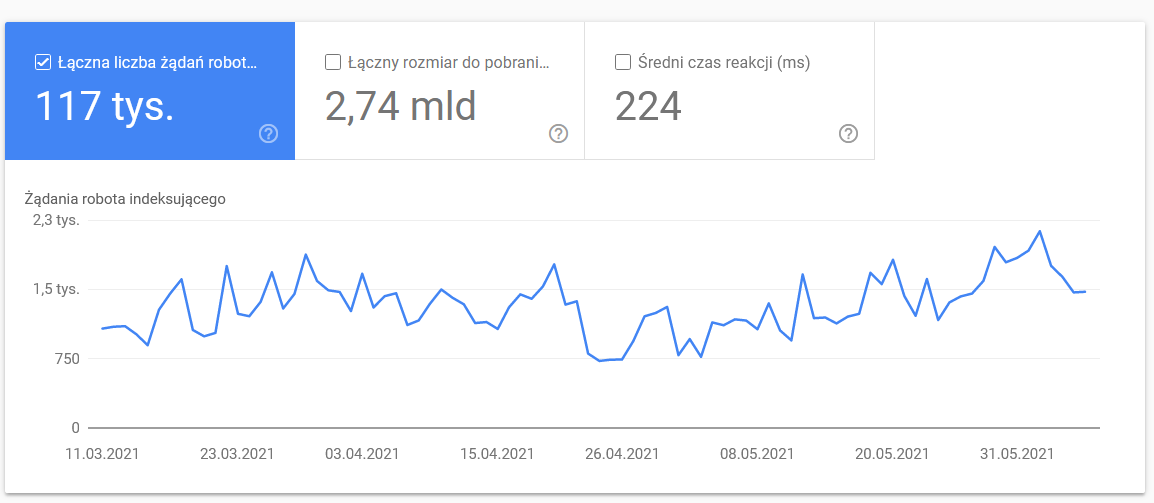
Как я уже сказал, вам будет трудно найти ориентиры для приведенных выше цифр. Тем не менее, это хороший призыв поближе взглянуть на:
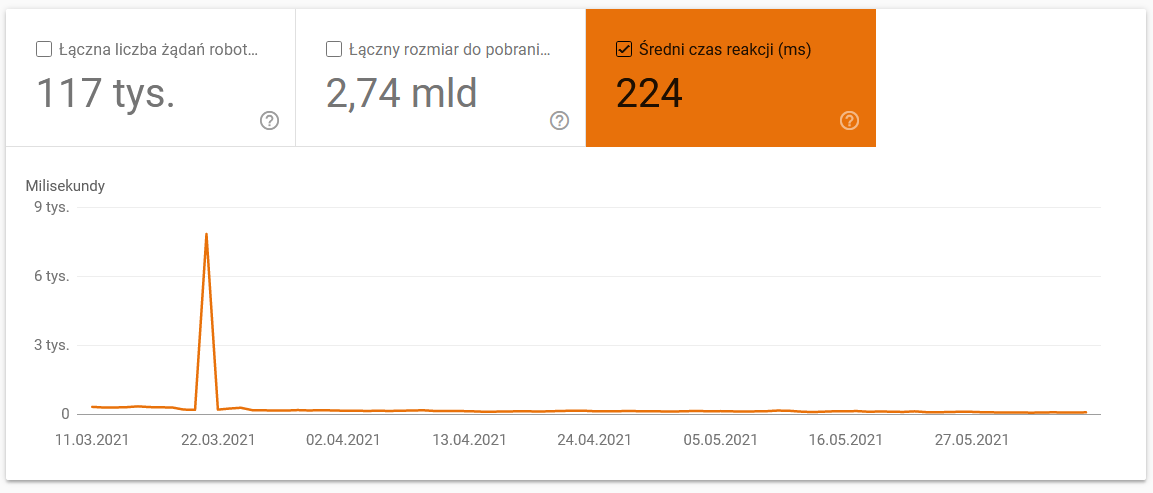
- Среднее время загрузки. На приведенном ниже снимке экрана видно, что среднее время отклика резко сократилось из-за проблем, связанных с сервером:
- Сканировать ответы. Посмотрите на отчет, чтобы увидеть, есть ли у вас проблемы с вашим сайтом или нет. Обратите особое внимание на нетипичные коды состояния сервера, такие как 304 ниже. Эти URL-адреса не служат никакой функциональной цели, но Google тратит свои ресурсы на сканирование их содержимого.

- Цель сканирования. В целом эти данные во многом зависят от объема нового контента на сайте. Различия между информацией, собранной Google и пользователем, могут быть весьма увлекательными:
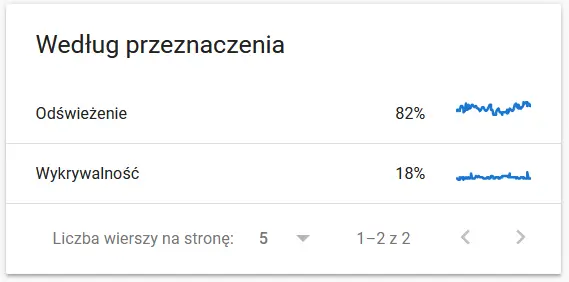
Содержимое повторно просканированного URL в глазах Google:
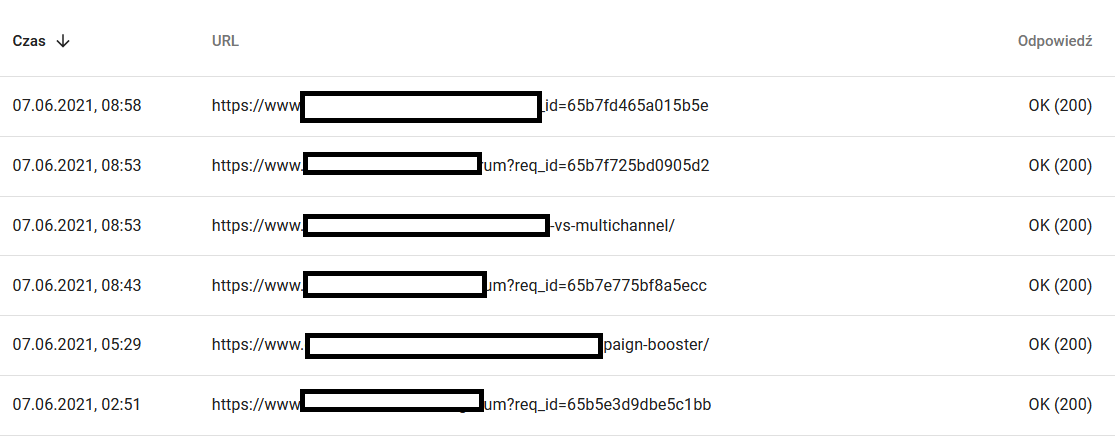
Между тем, вот что пользователь видит в браузере:
Определенно повод для размышлений и анализа :)
- Тип гуглбота . Здесь у вас есть боты, посещающие ваш сайт на блюдечке с голубой каемочкой, вместе с их мотивами для анализа вашего контента. На скриншоте ниже видно, что 22% запросов относятся к загрузке ресурсов страницы.
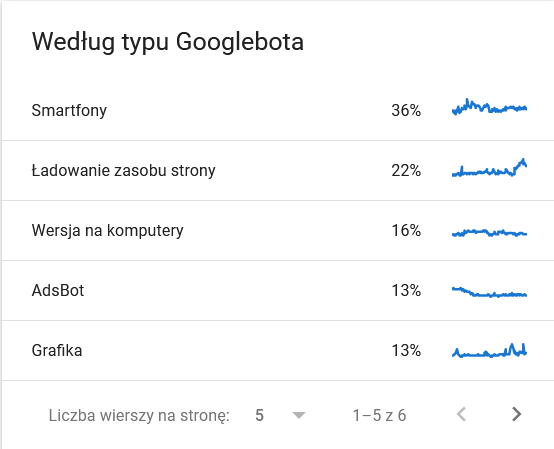
Итого раздулось в последние дни периода:
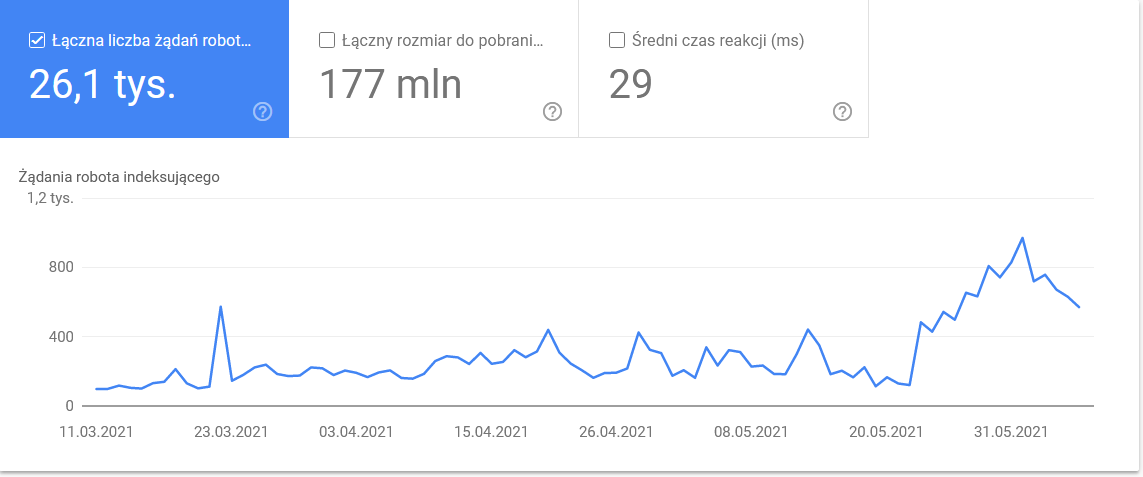
Взгляд на детали показывает URL-адреса, которые требуют более пристального внимания:
Внешние сканеры (с примерами из Screaming Frog SEO Spider)
Сканеры — один из самых важных инструментов для анализа краулингового бюджета вашего веб-сайта. Их основная цель — имитировать движения сканирующих ботов на веб-сайте. Моделирование сразу показывает, все ли идет гладко.
Если вы визуальный ученик, вы должны знать, что большинство решений, доступных на рынке, предлагают визуализацию данных.
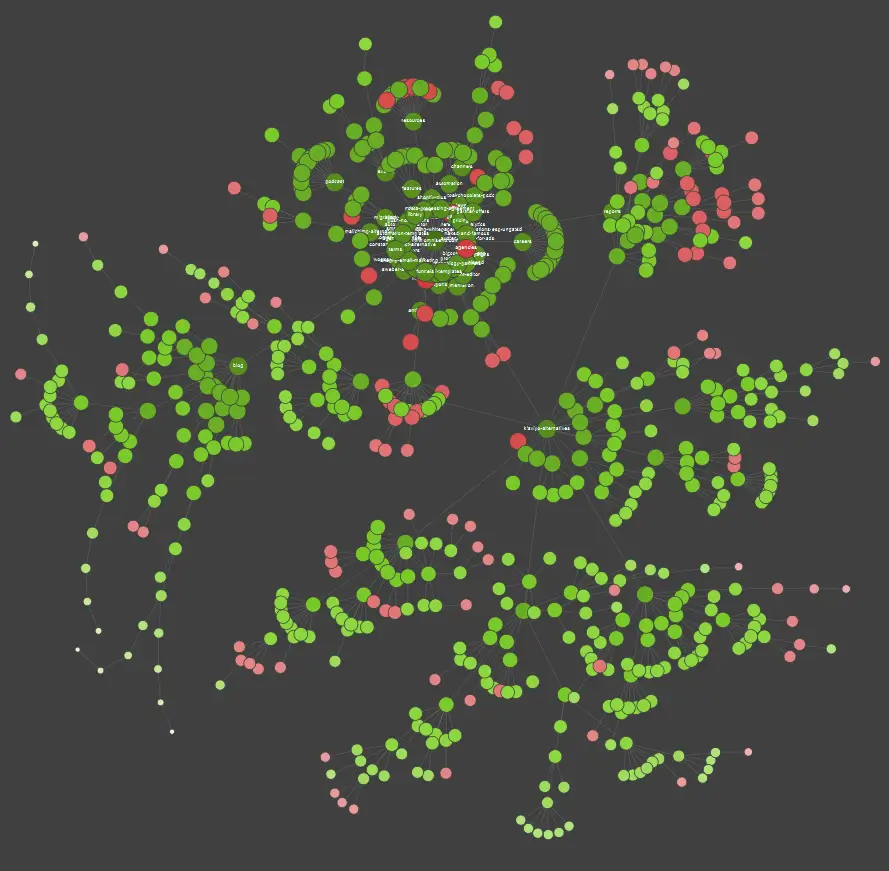
В приведенном выше примере красные точки обозначают непроиндексированные страницы. Подумайте об их полезности и влиянии на работу сайта. Если журналы сервера показывают, что эти страницы тратят впустую много времени Google, не принося никакой пользы, пришло время серьезно пересмотреть вопрос о том, чтобы оставить их на веб-сайте.
Важно . Если мы хотим максимально точно воссоздать поведение робота Google, необходимы правильные настройки. Здесь вы можете увидеть примеры настроек с моего компьютера:
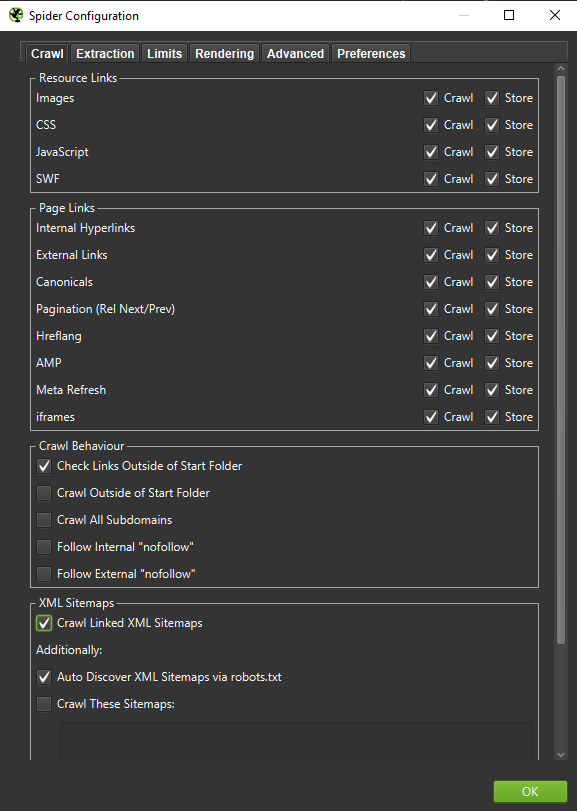
При проведении углубленного анализа рекомендуется протестировать два режима — «Только текст» и «JavaScript» — чтобы сравнить различия (если они есть).

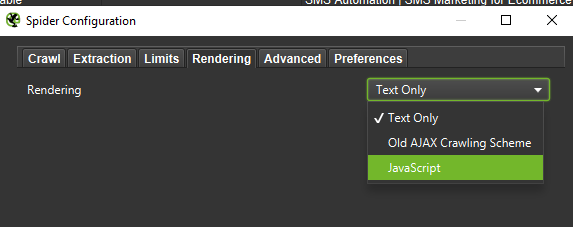
Наконец, никогда не помешает протестировать представленную выше настройку на двух разных пользовательских агентах:
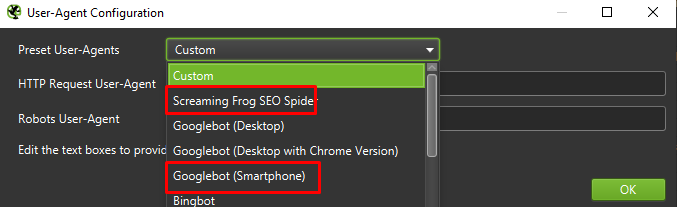
В большинстве случаев вам нужно будет сосредоточиться только на результатах, просканированных/отображенных мобильным агентом.
Важно: я также предлагаю использовать возможность, предоставляемую Screaming Frog, и снабжать вашего поискового робота данными из GA и Google Search Console. Интеграция — это быстрый способ выявить трату краулингового бюджета, например значительное количество потенциально избыточных URL-адресов, которые не получают трафика.
Инструменты для анализа логов (Screaming Frog Logfile и другие)
Выбор анализатора журнала сервера зависит от личных предпочтений. Мой любимый инструмент — анализатор лог-файлов Screaming Frog. Возможно, это не самое эффективное решение (загрузка огромного пакета логов = зависание приложения), но интерфейс мне нравится. Важная часть — приказать системе отображать только проверенных роботов Google.
Инструменты для отслеживания видимости
Полезная помощь, поскольку они позволяют вам определить ваши главные страницы. Если страница имеет высокий рейтинг по многим ключевым словам в Google (= получает много трафика), у нее потенциально может быть больший спрос на сканирование (проверьте это в журналах — действительно ли Google генерирует больше обращений для этой конкретной страницы?).
Для наших целей нам потребуются общие отчеты в Senuto — Пути и URL-адреса — для дальнейшего просмотра в будущем. Оба отчета доступны в Анализе видимости, вкладка Разделы. Взглянуть:
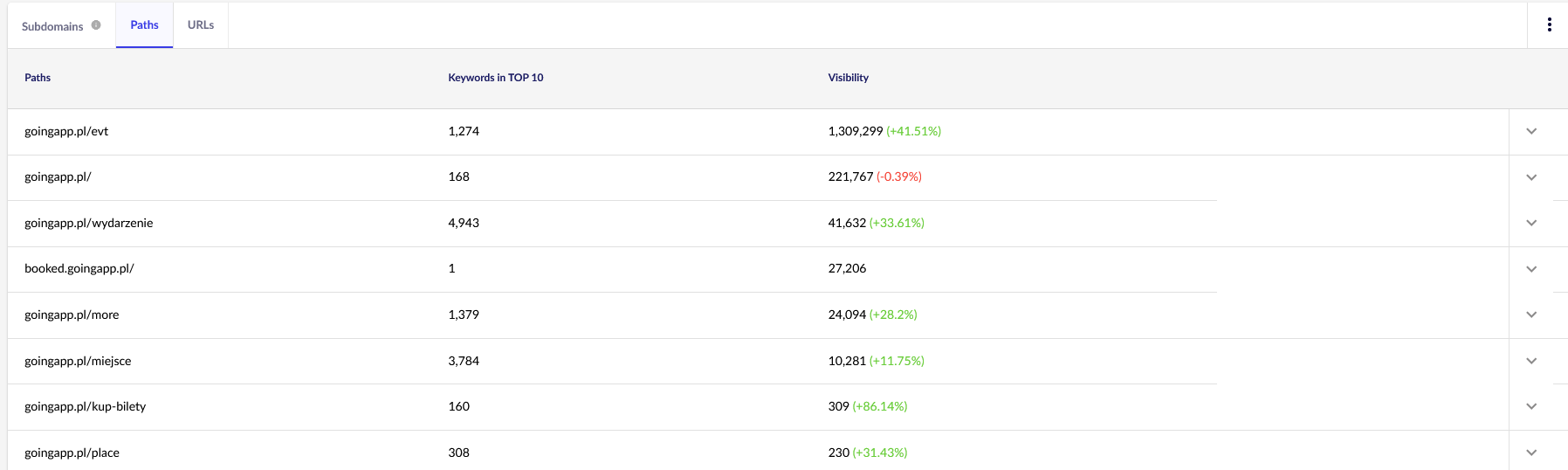
Нас больше всего интересует второй отчет. Давайте отсортируем его, чтобы посмотреть на видимость наших ключевых слов (список и общее количество ключевых слов, по которым наш сайт входит в ТОП-10). Результаты помогут нам определить основную ось для стимулирования (и эффективного распределения) нашего краулингового бюджета.
Инструменты для анализа обратных ссылок (Ahrefs, Majestic)
Если на одной из ваших страниц много внешних ссылок, используйте ее в качестве основы стратегии оптимизации краулингового бюджета. Популярные страницы могут взять на себя роль хабов, передающих сок дальше. Кроме того, популярная страница с приличным пулом ценных ссылок имеет больше шансов привлечь частое сканирование.
В Ahrefs нам нужен отчет Страницы, а точнее его часть под названием: «Лучшее по ссылкам»:
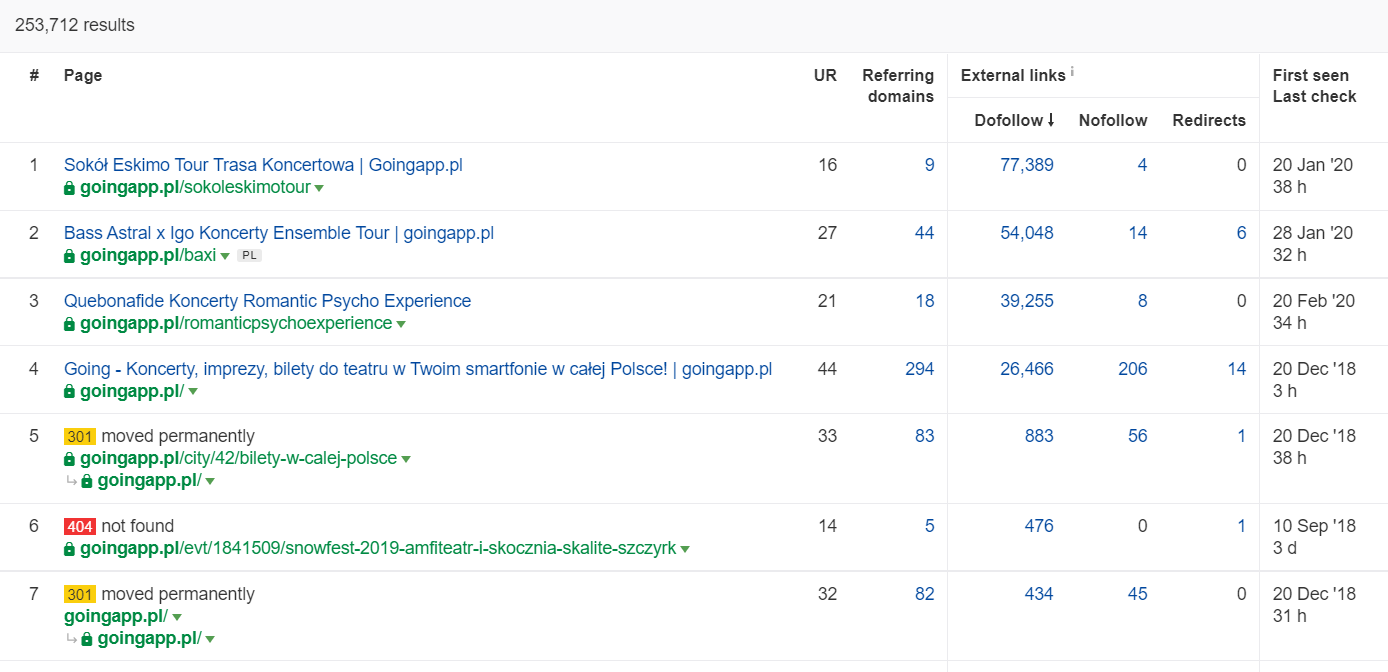
Приведенный выше пример показывает, что некоторые LP, связанные с концертами, продолжали генерировать надежную статистику по обратным ссылкам. Даже несмотря на то, что все концерты были отменены из-за пандемии, использование исторически влиятельных страниц по-прежнему окупается, чтобы возбудить любопытство ползающих ботов и распространить сок в более глубокие уголки вашего веб-сайта.
Каковы явные признаки проблемы с краулинговым бюджетом?
Осознание того, что вы имеете дело с проблематичным (чрезмерно низким) краулинговым бюджетом, не приходит легко. Почему? В первую очередь потому, что SEO — чрезвычайно сложное предприятие. Низкий рейтинг или проблемы с индексацией могут быть следствием посредственного ссылочного профиля или отсутствия нужного контента на веб-сайте.
Как правило, диагностика краулингового бюджета включает проверку:
- Сколько времени проходит от публикации до индексации новых страниц (сообщений в блоге/продуктов), если вы не запрашиваете индексацию через Google Search Console?
- Как долго Google хранит недействительные URL-адреса в своем индексе? Важно: адреса перенаправления являются исключением — Google хранит их намеренно.
- Есть ли у вас страницы, которые попадают в индекс только для того, чтобы потом исчезнуть?
- Сколько времени Google тратит на страницы, которые не приносят ценности (трафика)? Перейдите к анализу журнала, чтобы узнать.
Как анализировать и оптимизировать краулинговый бюджет?
Решение погрузиться в оптимизацию краулингового бюджета в основном продиктовано размером вашего сайта. Google предполагает, что в целом веб-сайты, содержащие менее 1000 страниц, не должны мучиться, пытаясь максимально использовать доступные ограничения сканирования. В моей книге вы должны начать бороться за более эффективное и действенное сканирование, если ваш веб-сайт включает более 300 страниц и ваш контент динамически меняется (например, вы продолжаете добавлять новые страницы / сообщения в блоге).
Почему? Это вопрос гигиены SEO. Внедрите хорошие привычки оптимизации и разумное управление краулинговым бюджетом в первые дни, и в будущем вам придется меньше исправлять и переделывать дизайн.
Оптимизация краулингового бюджета. Стандартная процедура
В целом работа по анализу и оптимизации кроу-бюджета состоит из трех этапов:
- Сбор данных — процесс сбора всего, что мы знаем о веб-сайте — как от веб-мастеров, так и от внешних инструментов.
- Анализ видимости и идентификация низко висящих плодов. Что работает как часы? Что может быть лучше? Какие направления имеют наибольший потенциал для роста?
- Рекомендации по краулинговому бюджету.
Сбор данных для аудита краулингового бюджета
1. Полное сканирование веб-сайта, выполненное с помощью одного из имеющихся в продаже инструментов. Цель состоит в том, чтобы выполнить как минимум два обхода: первый имитирует Googlebot, а второй извлекает веб-сайт в качестве пользовательского агента по умолчанию (подойдет пользовательский агент браузера). На данном этапе вас интересует только загрузка 100% контента . Если вы заметили, что краулер зациклился (когда после дня сканирования у нас остается только 10% сайта на жестком диске) — сообщите, что возникла проблема и вы можете остановить сканирование. Разумное количество URL-адресов для анализа, в случае крупных веб-сайтов, составляет около 250–300 тысяч страниц.
а) В основном мы ищем внутренние перенаправления 301, ошибки 404, а также ситуации, когда ваши тексты могут быть отнесены к категории некачественного контента. В Screaming Frog есть возможность обнаруживать почти дублированный контент:
2. Журналы сервера . Идеальные временные рамки должны охватывать последний месяц, однако в случае крупных веб-сайтов двух последних недель может оказаться достаточно. В лучшем случае у нас должен быть доступ к историческим журналам серверов, чтобы сравнить перемещения робота Googlebot в то время, когда все шло гладко.
3. Экспорт данных из Google Search Console . В сочетании с пунктами 1 и 2 выше, данные индексного покрытия и статистики сканирования должны дать вам достаточно полный отчет обо всех событиях на вашем веб-сайте.
4. Данные об органическом трафике . Самые популярные страницы по данным Google Search Console, Google Analytics, а также Senuto и Ahrefs. Мы хотим определить все страницы, которые выделяются среди толпы своей высокой статистикой видимости, объемом трафика или количеством обратных ссылок. Эти страницы должны стать основой вашей работы над краулинговым бюджетом. Мы будем использовать их для улучшения сканирования наиболее важных страниц.
5. Просмотр индекса вручную . В некоторых случаях лучший друг SEO-специалиста — простое решение. В данном случае: обзор данных, взятых прямо из индекса! Это хороший способ проверить свой веб-сайт с комбинацией inurl: + сайт: операторы.Наконец, нам нужно объединить все собранные данные. Как правило, мы будем использовать внешний сканер с функциями, позволяющими импортировать внешние данные (данные GSC, журналы сервера и данные органического трафика).
Анализ видимости и низко висящие плоды
Процесс заслуживает отдельной статьи, но наша цель сегодня — получить общее представление о наших целях для веб-сайта и достигнутом прогрессе. Нас интересует все необычное: внезапные падения трафика (которые нельзя объяснить сезонными тенденциями) и одновременные сдвиги в органической видимости. Мы проверяем, какие группы страниц являются самыми сильными, поскольку они станут нашими ХАБами для более глубокого проникновения робота Googlebot на наш веб-сайт.
В идеале такая проверка должна охватывать всю историю нашего сайта с момента его запуска. Однако, поскольку объем данных продолжает расти с каждым месяцем, давайте сосредоточимся на анализе видимости и органического трафика за последние 12 месяцев.
Краулинговый бюджет – наши рекомендации
Действия, перечисленные выше, будут различаться в зависимости от размера оптимизированного веб-сайта. Тем не менее, это самые важные элементы, которые я всегда учитываю при анализе краулингового бюджета. Первостепенной целью является устранение узких мест на вашем сайте. Другими словами, чтобы гарантировать максимальную возможность сканирования для роботов Google (или других агентов индексации).
1. Начнем с азов — устранение всевозможных ошибок 404/410, анализ внутренних редиректов и их удаление из внутренней перелинковки . Мы должны завершить нашу работу последним сканированием. На этот раз все ссылки должны возвращать код ответа 200 без внутренних перенаправлений или ошибок 404.
- На этом этапе рекомендуется исправить все цепочки редиректов, обнаруженные в отчете по обратным ссылкам.
2. После сканирования убедитесь, что в структуре нашего сайта нет явных дубликатов .
- Также проверьте на предмет потенциальной каннибализации — помимо проблем, возникающих при таргетинге на одно и то же ключевое слово на нескольких страницах (вкратце, вы перестаете контролировать, какая страница будет отображаться в Google), каннибализация негативно влияет на весь ваш краулинговый бюджет.
- Объедините обнаруженные дубликаты в один URL-адрес (обычно тот, который имеет более высокий рейтинг).
3. Проверьте, сколько URL имеют тег noindex . Как мы знаем, Google по-прежнему может перемещаться по этим страницам. Они просто не отображаются в результатах поиска. Мы пытаемся минимизировать долю тегов noindex в структуре нашего сайта.
- Показательный пример — блог организует свою структуру с помощью тегов; авторы утверждают, что решение продиктовано удобством пользователя. Каждый пост помечен 3–5 тегами, присвоенными непоследовательно и не индексируемыми. Анализ журнала показывает, что это третья по посещаемости структура на веб-сайте.
4. Просмотрите файл robots.txt . Помните, что внедрение robots.txt не означает, что Google не будет отображать адрес в индексе.
- Проверьте, какие из заблокированных адресных структур все еще сканируются. Может быть, их отключение вызывает узкое место?
- Удалите устаревшие/ненужные директивы.
5. Проанализируйте количество неканонических URL-адресов на вашем сайте. Google перестал рассматривать rel="canonical" как жесткую директиву. Во многих случаях атрибут просто игнорируется поисковой системой (сортировка параметров в индексе — тот еще кошмар).
6. Проанализируйте фильтры и лежащий в их основе механизм . Фильтрация списков — самая большая головная боль оптимизации краулингового бюджета. Владельцы бизнеса электронной коммерции настаивают на внедрении фильтров, применимых в любой комбинации (например, фильтрация по цвету + материалу + размеру + доступности… в сотый раз). Решение не является оптимальным и должно быть сведено к минимуму.
7. Информационная архитектура на веб-сайте — такая, которая учитывает бизнес-цели, потенциал трафика и текущий ссылочный профиль. Давайте исходить из предположения, что ссылка на контент, критически важный для наших бизнес-целей, должна быть видна на всем сайте (на всех страницах) или на главной странице. Здесь мы, конечно, упрощаем, но главная страница и верхнее меню/ссылки по всему сайту являются наиболее мощными индикаторами повышения ценности внутренних ссылок. В то же время мы пытаемся добиться оптимального распространения домена: наша цель - ситуация, когда мы можем начать сканирование с любой страницы и при этом достичь того же количества страниц (каждый URL должен иметь одну входящую ссылку МИНИМУМ). .
- Работа над надежной информационной архитектурой — один из ключевых элементов оптимизации краулингового бюджета. Это позволяет нам освободить часть ресурсов бота из одного места и перенаправить их в другое. Это также одна из самых больших проблем, поскольку она требует сотрудничества заинтересованных сторон бизнеса, что часто приводит к огромным битвам и критике, подрывающей рекомендации SEO.
8. Рендеринг контента. Критически важно в случае веб-сайтов, стремящихся основывать свои внутренние ссылки на рекомендательных системах, фиксирующих поведение пользователей. Прежде всего, большинство этих инструментов полагаются на файлы cookie. Google не хранит файлы cookie, поэтому не получает персонализированные результаты. В результате Google всегда видит один и тот же контент или не видит его вообще.
- Распространенной ошибкой является предотвращение доступа робота Googlebot к важному содержимому JS/CSS. Этот шаг может привести к проблемам с индексацией страниц (и пустой трате времени Google на отображение недоступного контента).
9. Производительность веб-сайта — Core Web Vitals . Хотя я скептически отношусь к влиянию CWV на ранжирование сайта (по многим причинам, в том числе из-за разнообразия имеющихся в продаже устройств и разной скорости интернет-соединения), это один из параметров, который стоит обсудить с программистом.
10. Sitemap.xml — проверьте, работает ли он и содержит ли все ключевые элементы (ничего, кроме канонических URL-адресов, возвращающих код состояния 200).
- Моя первая рекомендация по оптимизации sitemap.xml — разделить ваши страницы по типам или, если возможно, по категориям. Это подразделение даст вам полный контроль над перемещениями Google и индексацией контента.