
การเรียนรู้อย่างมีประสิทธิภาพ: อนาคตอันใกล้ของ AI
เผยแพร่แล้ว: 2017-11-09เทคนิคการเรียนรู้ที่มีประสิทธิภาพเหล่านี้ไม่ใช่เทคนิคการเรียนรู้เชิงลึก/แมชชีนเลิร์นนิงใหม่ แต่เสริมเทคนิคที่มีอยู่ให้กลายเป็นการแฮ็ก
ไม่ต้องสงสัยเลยว่าอนาคตสูงสุดของ AI คือการเข้าถึงและก้าวข้ามความฉลาดของมนุษย์ แต่นี่เป็นความสำเร็จที่ยากจะบรรลุได้ แม้แต่คนที่มองโลกในแง่ดีที่สุดในหมู่พวกเราก็พนันได้เลยว่า AI ระดับมนุษย์ (AGI หรือ ASI) จะอยู่ได้ไกลถึง 10-15 ปีนับจากนี้ ด้วยความคลางแคลงใจแม้จะเต็มใจที่จะเดิมพันว่าจะใช้เวลาหลายศตวรรษถ้าเป็นไปได้ นี่ไม่ใช่สิ่งที่โพสต์เกี่ยวกับ
ในที่นี้เราจะพูดถึงอนาคตที่ใกล้ตัวและจับต้องได้มากกว่านี้ และหารือเกี่ยวกับอัลกอริธึมและเทคนิค AI ที่เกิดขึ้นใหม่และมีศักยภาพ ซึ่งในความเห็นของเราจะกำหนดอนาคตอันใกล้ของ AI
AI ได้เริ่มพัฒนามนุษย์ให้ดีขึ้นในงานเฉพาะบางงานที่ได้รับการคัดเลือก ตัวอย่างเช่น การเอาชนะแพทย์ในการวินิจฉัยโรคมะเร็งผิวหนังและการเอาชนะผู้เล่น Go ในการแข่งขันชิงแชมป์โลก แต่ระบบและรุ่นเดียวกันจะล้มเหลวในการปฏิบัติงานที่แตกต่างจากที่ได้รับการฝึกให้แก้ปัญหา ด้วยเหตุนี้ ในระยะยาว ระบบอัจฉริยะโดยทั่วไปซึ่งทำงานชุดหนึ่งอย่างมีประสิทธิภาพโดยไม่จำเป็นต้องประเมินใหม่จึงถูกขนานนามว่าเป็นอนาคตของ AI
แต่ในอนาคตอันใกล้ของ AI ก่อนที่ AGI จะเกิดขึ้น นักวิทยาศาสตร์จะทำให้อัลกอริธึมที่ขับเคลื่อนด้วย AI เอาชนะปัญหาที่พวกเขาเผชิญอยู่ในปัจจุบันเพื่อออกจากห้องปฏิบัติการและกลายเป็นวัตถุที่ใช้ในชีวิตประจำวันได้อย่างไร
เมื่อคุณมองไปรอบๆ AI จะชนะปราสาททีละแห่ง (อ่านโพสต์ของเราเกี่ยวกับวิธีที่ AI แซงหน้ามนุษย์ ส่วนที่หนึ่งและส่วนที่สอง) อะไรที่อาจผิดพลาดได้ในเกมที่ชนะแบบนี้? มนุษย์กำลังผลิตข้อมูลมากขึ้นเรื่อยๆ (ซึ่งเป็นอาหารสัตว์ที่ AI ใช้) เมื่อเวลาผ่านไปและความสามารถของฮาร์ดแวร์ของเราก็ดีขึ้นเช่นกัน ท้ายที่สุดแล้ว ข้อมูลและการคำนวณที่ดีขึ้นเป็นสาเหตุที่ทำให้การปฏิวัติการเรียนรู้เชิงลึกเริ่มต้นในปี 2555 ใช่ไหม ความจริงก็คือ เร็วกว่าการเติบโตของข้อมูลและการคำนวณคือการเติบโตของความคาดหวังของมนุษย์ Data Scientists จะต้องคิดถึงวิธีแก้ไขที่มากกว่าที่มีอยู่ในขณะนี้เพื่อแก้ปัญหาในโลกแห่งความเป็นจริง ตัวอย่างเช่น การจัดประเภทรูปภาพตามที่คนส่วนใหญ่คิดว่าเป็นปัญหาในเชิงวิทยาศาสตร์ (หากเราต่อต้านการกระตุ้นให้พูดว่าแม่นยำ 100% หรือ GTFO)
เราสามารถจำแนกรูปภาพ (สมมติว่าเป็นรูปแมวหรือรูปสุนัข) ที่ตรงกับความสามารถของมนุษย์โดยใช้ AI แต่สิ่งนี้สามารถใช้กับกรณีการใช้งานจริงได้หรือไม่? AI สามารถนำเสนอวิธีแก้ปัญหาสำหรับปัญหาเชิงปฏิบัติที่มนุษย์กำลังเผชิญอยู่ได้หรือไม่? ในบางกรณีใช่ แต่ในหลายกรณีเรายังไม่ถึงจุดนั้น
เราจะแนะนำคุณผ่านความท้าทายซึ่งเป็นอุปสรรคสำคัญในการพัฒนาโซลูชันในโลกแห่งความเป็นจริงโดยใช้ AI สมมติว่าคุณต้องการจำแนกภาพแมวและสุนัข เราจะใช้ตัวอย่างนี้ตลอดทั้งโพสต์

ตัวอย่างอัลกอริทึมของเรา: การจำแนกภาพแมวและสุนัข
กราฟิกด้านล่างสรุปความท้าทาย:

ความท้าทายที่เกี่ยวข้องกับการพัฒนา AI . ในโลกแห่งความเป็นจริง
ให้เราพูดถึงความท้าทายเหล่านี้โดยละเอียด:
การเรียนรู้ด้วยข้อมูลน้อย
- ข้อมูลการฝึกอบรมอัลกอริธึม Deep Learning ที่ประสบความสำเร็จมากที่สุดต้องใช้ข้อมูลนั้นต้องติดป้ายกำกับตามเนื้อหา/คุณลักษณะที่มีอยู่ กระบวนการนี้เรียกว่าคำอธิบายประกอบ
- อัลกอริทึมไม่สามารถใช้ข้อมูลที่พบตามธรรมชาติรอบตัวคุณได้ คำอธิบายประกอบของข้อมูลสองสามร้อย (หรือสองสามพันจุดข้อมูล) นั้นง่าย แต่อัลกอริธึมการจำแนกรูปภาพระดับมนุษย์ของเราใช้รูปภาพที่มีคำอธิบายประกอบนับล้านภาพเพื่อเรียนรู้ได้ดี
- คำถามคือ การทำคำอธิบายประกอบเป็นล้านภาพเป็นไปได้หรือไม่? ถ้าไม่เช่นนั้น AI จะปรับขนาดด้วยปริมาณข้อมูลที่มีคำอธิบายประกอบน้อยลงได้อย่างไร
การแก้ปัญหาในโลกแห่งความเป็นจริงที่หลากหลาย
- แม้ว่าชุดข้อมูลจะได้รับการแก้ไข แต่การใช้งานจริงนั้นมีความหลากหลายมากกว่า (เช่น อัลกอริธึมที่ฝึกเกี่ยวกับภาพสีอาจล้มเหลวอย่างมากในรูปภาพระดับสีเทาที่ไม่เหมือนมนุษย์)
- ในขณะที่เราได้ปรับปรุงอัลกอริธึม Computer Vision เพื่อตรวจจับวัตถุให้เข้ากับมนุษย์ แต่ดังที่กล่าวไว้ก่อนหน้านี้ อัลกอริธึมเหล่านี้แก้ปัญหาเฉพาะเจาะจงมาก เมื่อเทียบกับความฉลาดของมนุษย์ ซึ่งโดยทั่วไปกว่ามากในหลายแง่มุม
- ตัวอย่างอัลกอริธึม AI ของเรา ซึ่งจัดประเภทแมวและสุนัข จะไม่สามารถระบุสายพันธุ์สุนัขหายากได้หากไม่ได้รับอาหารด้วยภาพของสายพันธุ์นั้น
การปรับข้อมูลที่เพิ่มขึ้น
- ความท้าทายที่สำคัญอีกประการหนึ่งคือข้อมูลที่เพิ่มขึ้น ในตัวอย่างของเรา หากเราพยายามจำแมวและสุนัข เราอาจฝึก AI ของเราสำหรับภาพแมวและสุนัขจำนวนหนึ่งจากสายพันธุ์ต่างๆ ในขณะที่เราปรับใช้ครั้งแรก แต่ในการค้นพบสายพันธุ์ใหม่ทั้งหมด เราต้องฝึกอัลกอริทึมให้รู้จัก “Kotpies” ร่วมกับสายพันธุ์ก่อนหน้า
- แม้ว่าสปีชีส์ใหม่อาจคล้ายกับสายพันธุ์อื่นๆ มากกว่าที่เราคิด และสามารถฝึกฝนได้ง่ายเพื่อปรับใช้อัลกอริทึม แต่ก็มีบางจุดที่ยากกว่าและต้องมีการฝึกอบรมและการประเมินใหม่อย่างสมบูรณ์
- คำถามคือเราจะทำให้ AI สามารถปรับให้เข้ากับการเปลี่ยนแปลงเล็กๆ น้อยๆ เหล่านี้ได้หรือไม่?
เพื่อให้ AI ใช้งานได้ทันที แนวคิดคือการแก้ปัญหาความท้าทายดังกล่าวด้วยชุดแนวทางที่เรียกว่าการเรียนรู้ที่มีประสิทธิภาพ (โปรดทราบว่านี่ไม่ใช่คำศัพท์ที่เป็นทางการ ฉันแค่สร้างขึ้นเพื่อหลีกเลี่ยงการเขียน Meta-Learning, Transfer Learning, Few Shot Learning, Adversarial Learning และ Multi-Task Learning ทุกครั้ง) พวกเราที่ ParallelDots กำลังใช้แนวทางเหล่านี้ในการแก้ปัญหาที่แคบด้วย AI ชนะการต่อสู้เล็กๆ น้อยๆ ในขณะที่เตรียมพร้อมสำหรับ AI ที่ครอบคลุมมากขึ้นเพื่อพิชิตสงครามที่ใหญ่กว่า ให้เราแนะนำคุณเกี่ยวกับเทคนิคเหล่านี้ทีละครั้ง
เห็นได้ชัดว่าเทคนิคส่วนใหญ่ของการเรียนรู้อย่างมีประสิทธิภาพเหล่านี้ไม่ใช่สิ่งใหม่ พวกเขาเพิ่งเห็นการฟื้นคืนชีพในขณะนี้ นักวิจัย SVM (Support Vector Machines) ใช้เทคนิคเหล่านี้มาเป็นเวลานาน ในทางกลับกัน Adversarial Learning เป็นสิ่งที่ออกมาจากงานล่าสุดของ Goodfellow ใน GAN และ Neural Reasoning เป็นเทคนิคชุดใหม่ที่มีชุดข้อมูลพร้อมใช้งานเมื่อเร็วๆ นี้ มาเจาะลึกกันว่าเทคนิคเหล่านี้จะช่วยกำหนดอนาคตของ AI ได้อย่างไร
ถ่ายทอดการเรียนรู้
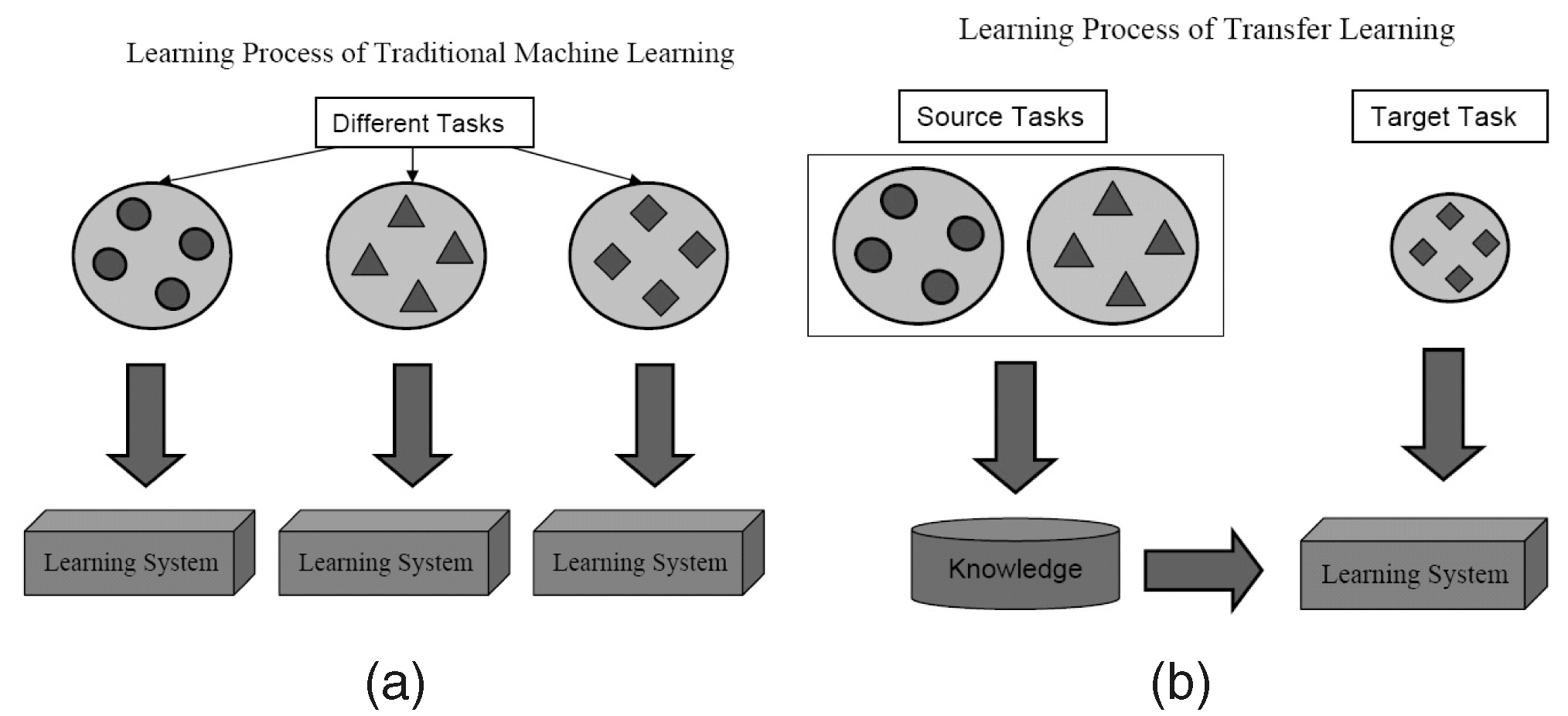
มันคืออะไร?
ตามชื่อที่แนะนำ การเรียนรู้จะถูกถ่ายโอนจากงานหนึ่งไปยังอีกงานหนึ่งภายในอัลกอริธึมเดียวกันใน Transfer Learning อัลกอริธึมที่ฝึกฝนในงานเดียว (งานต้นทาง) ที่มีชุดข้อมูลขนาดใหญ่สามารถถ่ายโอนโดยมีหรือไม่มีการแก้ไขโดยเป็นส่วนหนึ่งของอัลกอริทึมที่พยายามเรียนรู้งานอื่น (งานเป้าหมาย) ในชุดข้อมูล (ค่อนข้าง) ที่เล็กกว่า
ตัวอย่างบางส่วน
การใช้พารามิเตอร์ของอัลกอริธึมการจำแนกรูปภาพเป็นตัวแยกคุณลักษณะในงานต่างๆ เช่น การตรวจจับวัตถุ เป็นแอปพลิเคชันง่ายๆ ของ Transfer Learning ในทางตรงกันข้าม สามารถใช้กับงานที่ซับซ้อนได้ อัลกอริธึมที่ Google พัฒนาขึ้นเพื่อจำแนกภาวะเบาหวานขึ้นจอตาได้ดีกว่าแพทย์ในสมัยก่อน ถูกสร้างขึ้นโดยใช้ Transfer Learning น่าแปลกที่เครื่องตรวจจับเบาหวานจอตาเป็นเครื่องจำแนกภาพในโลกแห่งความเป็นจริง (ตัวแยกประเภทภาพสุนัข/แมว) โอนการเรียนรู้เพื่อจำแนกการสแกนตา
บอกรายละเอียดฉันเพิ่มเตืม!
คุณจะพบว่า Data Scientists เรียกส่วนที่ถ่ายโอนดังกล่าวของโครงข่ายประสาทเทียมจากต้นทางไปยังงานเป้าหมายเป็นเครือข่ายที่ได้รับการฝึกฝนล่วงหน้าในเอกสารการเรียนรู้เชิงลึก การปรับละเอียดคือเมื่อข้อผิดพลาดของงานเป้าหมายถูก backpropagated เล็กน้อยในเน็ตที่ฝึกไว้ล่วงหน้า แทนที่จะใช้เครือข่ายที่ฝึกไว้ล่วงหน้าที่ไม่ได้รับการแก้ไข ข้อมูลแนะนำทางเทคนิคที่ดีเกี่ยวกับ Transfer Learning in Computer Vision สามารถดูได้ที่นี่ แนวคิดง่ายๆ ของ Transfer Learning นี้มีความสำคัญมากในชุดวิธีการเรียนรู้ที่มีประสิทธิภาพของเรา
แนะนำสำหรับคุณ:

Metaverse จะพลิกโฉมอุตสาหกรรมยานยนต์อินเดียได้อย่างไร

บทบัญญัติต่อต้านการแสวงหากำไรสำหรับสตาร์ทอัพในอินเดียมีความหมายอย่างไร?

Edtech Startups ช่วยให้แรงงานอินเดียเพิ่มพูนทักษะและเตรียมพร้อมสู่อนาคตได้อย่างไร...

หุ้นเทคโนโลยียุคใหม่ในสัปดาห์นี้: ปัญหาของ Zomato ยังคงดำเนินต่อไป, EaseMyTrip Posts Stro...

สตาร์ทอัพอินเดียใช้ทางลัดในการไล่ล่าหาทุน

แพลตฟอร์มการตลาดดิจิทัล Logicserve ระดมทุน INR 80 Cr รีแบรนด์เป็น LS Dig...
การเรียนรู้แบบมัลติทาสก์
มันคืออะไร?
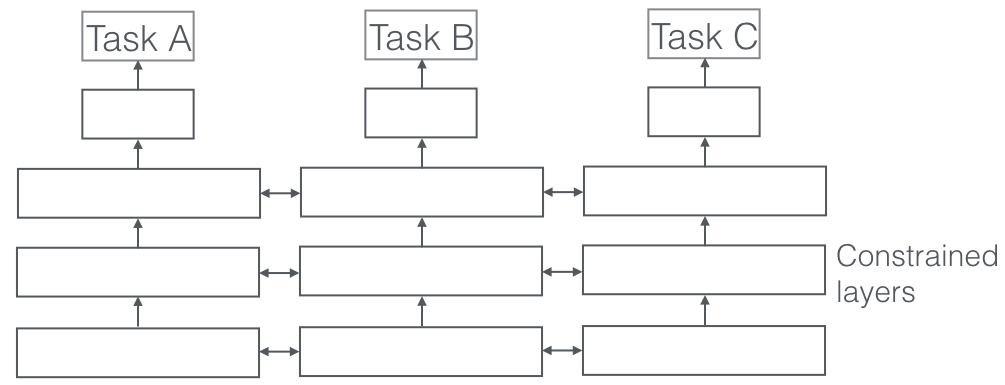

ใน Multi-Task Learning งานการเรียนรู้หลายงานจะได้รับการแก้ไขพร้อมๆ กัน ในขณะที่ใช้ประโยชน์จากความธรรมดาและความแตกต่างจากงานต่างๆ เป็นเรื่องน่าประหลาดใจ แต่บางครั้งการเรียนรู้งานสองอย่างหรือมากกว่าร่วมกัน (หรือที่เรียกว่างานหลักและงานเสริม) สามารถทำให้ผลงานดีขึ้นได้ โปรดทราบว่างานทุกคู่หรือแฝดสามหรือสี่ชิ้นไม่สามารถถือเป็นงานเสริมได้ แต่เมื่อใช้งานได้ ความแม่นยำจะเพิ่มขึ้นอย่างอิสระ
ตัวอย่างบางส่วน
ตัวอย่างเช่น ที่ ParallelDots ตัวแยกประเภท Sentiment, Intent และ Emotion Detection ของเราได้รับการฝึกฝนเป็น Multi-Task Learning ซึ่งเพิ่มความแม่นยำเมื่อเทียบกับหากเราฝึกแยกกัน ระบบการติดแท็ก Semantic Role ที่ดีที่สุดและระบบการติดแท็ก POS ใน NLP ที่เรารู้จักคือระบบการเรียนรู้แบบหลายงาน ดังนั้นจึงเป็นหนึ่งในระบบที่ดีที่สุดสำหรับการแบ่งส่วนความหมายและอินสแตนซ์ใน Computer Vision Google ได้คิดค้น Multi-Task Learners หลายรูปแบบ (โมเดลเดียวที่จะควบคุมพวกเขาทั้งหมด) ที่สามารถเรียนรู้จากทั้งชุดข้อมูลการมองเห็นและข้อความในช็อตเดียวกัน
บอกรายละเอียดฉันเพิ่มเตืม!
แง่มุมที่สำคัญมากของการเรียนรู้แบบมัลติทาสก์ที่เห็นในแอปพลิเคชันในโลกแห่งความเป็นจริงคือการฝึกอบรมงานใดๆ ให้กลายเป็นระบบกันกระสุน เราต้องคำนึงถึงข้อมูลที่มาจากโดเมนจำนวนมาก (เรียกอีกอย่างว่าการปรับโดเมน) ตัวอย่างในกรณีการใช้งานของแมวและสุนัขของเราจะเป็นอัลกอริธึมที่สามารถจดจำรูปภาพจากแหล่งต่างๆ (เช่น กล้อง VGA และกล้อง HD หรือแม้แต่กล้องอินฟราเรด) ในกรณีเช่นนี้ สามารถเพิ่มการสูญเสียการจำแนกโดเมน (โดยที่รูปภาพมาจาก) ในงานใดก็ได้ จากนั้นเครื่องจะเรียนรู้ว่าอัลกอริธึมทำงานได้ดีขึ้นในงานหลัก (จำแนกรูปภาพเป็นภาพแมวหรือสุนัข) แต่ ตั้งใจทำให้งานเสริมแย่ลง (ทำได้โดย backpropagating การไล่ระดับข้อผิดพลาดย้อนกลับจากงานการจำแนกโดเมน) แนวคิดคืออัลกอริธึมเรียนรู้คุณสมบัติการเลือกปฏิบัติสำหรับงานหลัก แต่ลืมคุณลักษณะที่สร้างความแตกต่างของโดเมนและสิ่งนี้จะทำให้ดีขึ้น Multi-Task Learning และลูกพี่ลูกน้องในการปรับโดเมนเป็นหนึ่งในเทคนิคการเรียนรู้ที่มีประสิทธิภาพที่ประสบความสำเร็จมากที่สุดที่เรารู้จักและมีบทบาทสำคัญในการกำหนดอนาคตของ AI
การเรียนรู้จากฝ่ายตรงข้าม
มันคืออะไร?
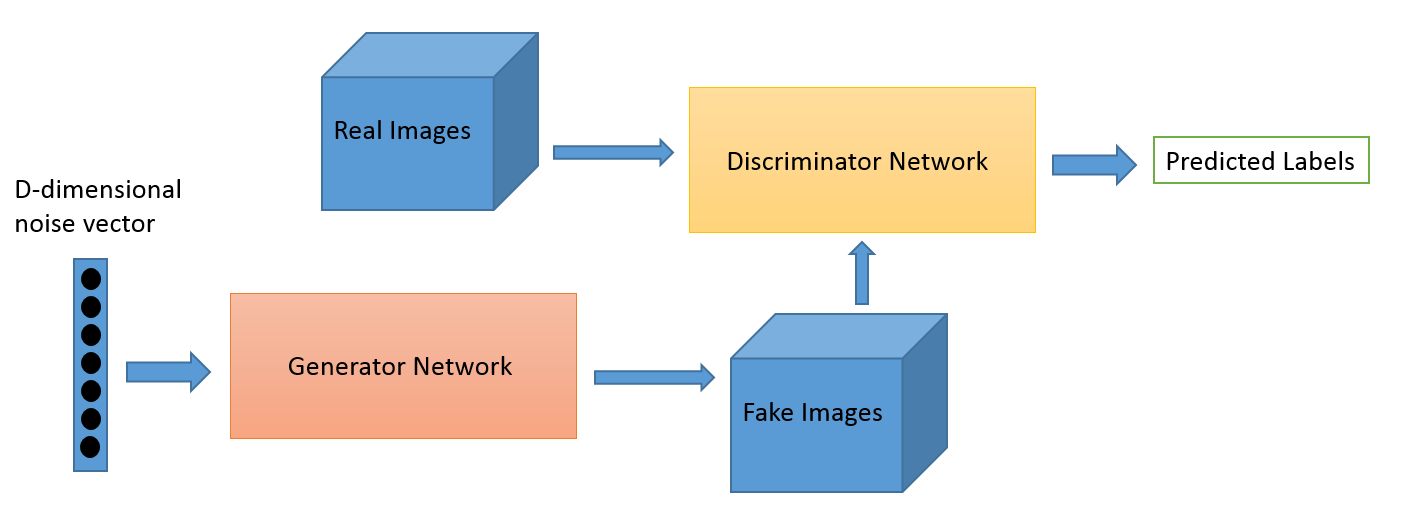
Adversarial Learning เป็นสาขาวิชาที่วิวัฒนาการมาจากงานวิจัยของ Ian Goodfellow แม้ว่าแอปพลิเคชันยอดนิยมของ Adversarial Learning จะไม่ต้องสงสัยเลยว่า Generative Adversarial Networks (GAN) ที่สามารถใช้สร้างภาพที่น่าทึ่งได้ แต่ก็มีเทคนิคอื่นๆ อีกหลายวิธีในชุดเทคนิคนี้ โดยทั่วไปแล้ว เทคนิคที่ได้รับแรงบันดาลใจจากทฤษฎีเกมนี้จะมีอัลกอริธึมสองตัวคือเครื่องกำเนิดและตัวแบ่งแยก ซึ่งมีจุดมุ่งหมายเพื่อหลอกกันและกันในขณะที่พวกเขากำลังฝึก เครื่องกำเนิดสามารถใช้เพื่อสร้างภาพใหม่ ๆ ตามที่เราพูดคุยกัน แต่ยังสามารถสร้างการแสดงข้อมูลอื่น ๆ เพื่อซ่อนรายละเอียดจากผู้เลือกปฏิบัติ อย่างหลังคือเหตุผลที่แนวคิดนี้น่าสนใจสำหรับเรามาก
ตัวอย่างบางส่วน
นี่เป็นสาขาใหม่และความสามารถในการสร้างภาพอาจเป็นสิ่งที่ผู้สนใจส่วนใหญ่เช่นนักดาราศาสตร์ให้ความสำคัญ แต่เราเชื่อว่าสิ่งนี้จะพัฒนากรณีการใช้งานใหม่ ๆ ตามที่เราบอกในภายหลัง
บอกรายละเอียดฉันเพิ่มเตืม!
เกมการปรับโดเมนสามารถปรับปรุงได้โดยใช้การสูญเสีย GAN การสูญเสียเสริมที่นี่คือระบบ GAN แทนการจำแนกโดเมนบริสุทธิ์ โดยที่ผู้เลือกปฏิบัติพยายามจัดประเภทข้อมูลที่มาจากโดเมน และส่วนประกอบเครื่องกำเนิดไฟฟ้าพยายามหลอกมันด้วยการนำเสนอสัญญาณรบกวนแบบสุ่มเป็นข้อมูล จากประสบการณ์ของเรา วิธีนี้ใช้ได้ผลดีกว่าการปรับโดเมนแบบธรรมดา
การเรียนรู้ไม่กี่ช็อต
มันคืออะไร?
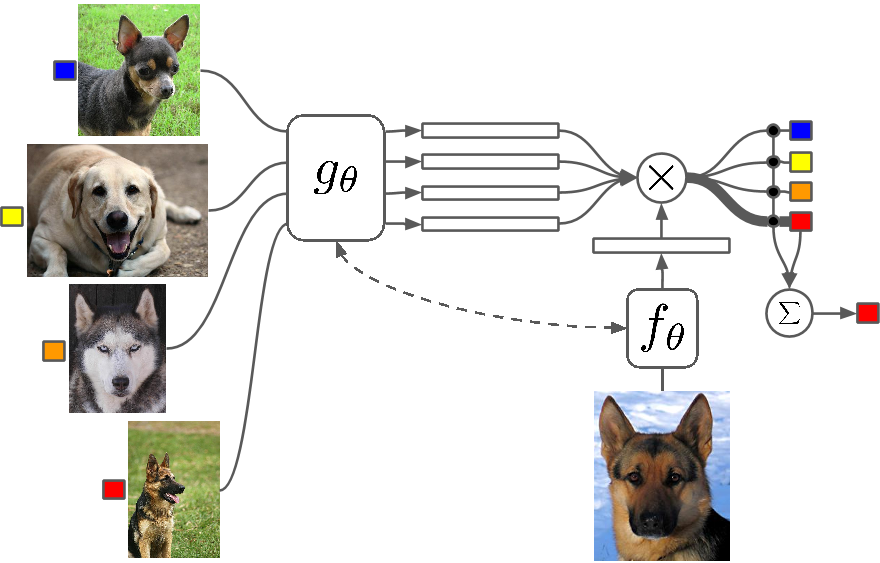
Few Shot Learning เป็นการศึกษาเทคนิคที่ทำให้อัลกอริทึม Deep Learning (หรืออัลกอริธึมการเรียนรู้ของเครื่อง) เรียนรู้โดยใช้ตัวอย่างน้อยลงเมื่อเทียบกับสิ่งที่อัลกอริธึมแบบเดิมทำ One Shot Learning คือการเรียนรู้ด้วยตัวอย่างหนึ่งของหมวดหมู่ การเรียนรู้ k-shot แบบอุปนัยหมายถึงการเรียนรู้ด้วยตัวอย่าง k ของแต่ละหมวดหมู่
ตัวอย่างบางส่วน
การเรียนรู้แบบไม่กี่ช็อตในขณะที่ภาคสนามกำลังเห็นการไหลเข้าของเอกสารในการประชุมเชิงลึกที่สำคัญทั้งหมด และขณะนี้มีชุดข้อมูลเฉพาะสำหรับผลการเปรียบเทียบ เช่นเดียวกับ MNIST และ CIFAR สำหรับการเรียนรู้ของเครื่องตามปกติ One-shot Learning เห็นแอปพลิเคชั่นจำนวนมากในงานจำแนกรูปภาพบางประเภท เช่น การตรวจจับคุณสมบัติและการแสดง
บอกรายละเอียดฉันเพิ่มเตืม!
มีหลายวิธีที่ใช้สำหรับการเรียนรู้แบบไม่กี่ช็อต รวมถึง Transfer Learning, Multi-Task Learning และ Meta-Learning ที่เป็นอัลกอริธึมทั้งหมดหรือบางส่วน มีวิธีอื่นๆ เช่น มีฟังก์ชันการสูญเสียที่ชาญฉลาด การใช้สถาปัตยกรรมแบบไดนามิก หรือการใช้แฮ็กการเพิ่มประสิทธิภาพ Zero Shot Learning ซึ่งเป็นคลาสของอัลกอริธึมที่อ้างว่าทำนายคำตอบสำหรับหมวดหมู่ที่อัลกอริธึมยังไม่ได้เห็น โดยพื้นฐานแล้วคืออัลกอริธึมที่สามารถปรับขนาดด้วยข้อมูลประเภทใหม่
Meta-Learning
มันคืออะไร?

Meta-Learning เป็นสิ่งที่ดูเหมือน เป็นอัลกอริธึมที่ฝึกเมื่อเห็นชุดข้อมูล จะให้ผลลัพธ์เป็นเครื่องทำนายการเรียนรู้ของเครื่องใหม่สำหรับชุดข้อมูลนั้น ๆ คำจำกัดความนั้นล้ำสมัยมากหากคุณมองแวบแรก คุณรู้สึกว่า "ว้าว! นั่นคือสิ่งที่ Data Scientist ทำ” และทำให้ “งานที่เซ็กซี่ที่สุดในศตวรรษที่ 21” เป็นไปโดยอัตโนมัติ และในแง่หนึ่ง Meta-Learners ก็เริ่มทำเช่นนั้น
ตัวอย่างบางส่วน
Meta-Learning ได้กลายเป็นประเด็นร้อนใน Deep Learning เมื่อเร็ว ๆ นี้ โดยมีงานวิจัยจำนวนมากออกมา ส่วนใหญ่มักใช้เทคนิคสำหรับการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์และโครงข่ายประสาทเทียม การค้นหาสถาปัตยกรรมเครือข่ายที่ดี การจดจำภาพไม่กี่ช็อต และการเรียนรู้การเสริมกำลังอย่างรวดเร็ว
บอกรายละเอียดฉันเพิ่มเตืม!
บางคนอ้างถึงการทำงานอัตโนมัติเต็มรูปแบบในการตัดสินใจเลือกทั้งพารามิเตอร์และไฮเปอร์พารามิเตอร์ เช่น สถาปัตยกรรมเครือข่าย เป็น autoML และคุณอาจพบว่าผู้คนอ้างถึง Meta Learning และ AutoML เป็นฟิลด์ต่างๆ แม้จะมีโฆษณามากมายรอบตัวพวกเขา แต่ความจริงก็คือ Meta Learners ยังคงเป็นอัลกอริธึมและเส้นทางในการปรับขนาดแมชชีนเลิร์นนิงด้วยความซับซ้อนและความหลากหลายของข้อมูลที่เพิ่มขึ้น
เอกสาร Meta-Learning ส่วนใหญ่เป็นการแฮ็กที่ชาญฉลาด ซึ่งตาม Wikipedia มีคุณสมบัติดังต่อไปนี้:
- ระบบต้องมีระบบย่อยการเรียนรู้ที่ปรับให้เข้ากับประสบการณ์
- ประสบการณ์ได้รับจากการใช้ประโยชน์จากความรู้เมตาที่ดึงมาจากตอนการเรียนรู้ก่อนหน้าในชุดข้อมูลเดียวหรือจากโดเมนหรือปัญหาที่แตกต่างกัน
- ต้องเลือกอคติการเรียนรู้แบบไดนามิก
โดยทั่วไประบบย่อยคือการตั้งค่าที่ปรับเมื่อมีการแนะนำ meta-data ของโดเมน (หรือโดเมนใหม่ทั้งหมด) ข้อมูลเมตานี้สามารถบอกเกี่ยวกับจำนวนคลาสที่เพิ่มขึ้น ความซับซ้อน การเปลี่ยนสีและพื้นผิวและวัตถุ (ในภาพ) สไตล์ รูปแบบภาษา (ภาษาธรรมชาติ) และคุณลักษณะอื่นๆ ที่คล้ายคลึงกัน ตรวจสอบเอกสารสุดเจ๋งที่นี่: Meta-Learning Shared Hierarchies และ Meta-Learning โดยใช้ Temporal Convolutions คุณยังสามารถสร้างอัลกอริธึม Few Shot หรือ Zero Shot ได้โดยใช้สถาปัตยกรรม Meta-Learning Meta-Learning เป็นหนึ่งในเทคนิคที่มีแนวโน้มมากที่สุดซึ่งจะช่วยในการกำหนดอนาคตของ AI
การใช้เหตุผลทางประสาท
มันคืออะไร?

การใช้เหตุผลทางประสาทเป็นเรื่องใหญ่ต่อไปในปัญหาการจำแนกรูปภาพ การใช้เหตุผลทางประสาทเป็นขั้นตอนที่อยู่เหนือการรู้จำรูปแบบซึ่งอัลกอริธึมกำลังก้าวไปไกลกว่าแนวคิดในการระบุและจำแนกข้อความหรือรูปภาพ การใช้เหตุผลทางประสาทกำลังแก้ปัญหาทั่วไปในการวิเคราะห์ข้อความหรือการวิเคราะห์ด้วยภาพ ตัวอย่างเช่น รูปภาพด้านล่างแสดงชุดคำถาม การใช้เหตุผลเชิงเหตุผลสามารถตอบได้จากรูปภาพ
บอกรายละเอียดฉันเพิ่มเตืม!
เทคนิคชุดใหม่นี้กำลังจะเกิดขึ้นหลังจากการเปิดตัวชุดข้อมูล bAbi ของ Facebook หรือชุดข้อมูล CLEVR ล่าสุด เทคนิคต่างๆ ที่จะมาถึงในการถอดรหัสความสัมพันธ์และไม่ใช่แค่รูปแบบเท่านั้นที่มีศักยภาพมหาศาลในการแก้ปัญหา ไม่ใช่แค่การให้เหตุผลทางประสาทเท่านั้น แต่ยังรวมถึงปัญหายากๆ อีกหลายอย่าง รวมถึงปัญหาการเรียนรู้ไม่กี่ช็อต
จะกลับไป
ตอนนี้เรารู้แล้วว่าเทคนิคคืออะไร ให้เราย้อนกลับไปดูว่าพวกเขาแก้ปัญหาพื้นฐานที่เราเริ่มต้นได้อย่างไร ตารางด้านล่างแสดงภาพรวมความสามารถของเทคนิคการเรียนรู้ที่มีประสิทธิภาพเพื่อรับมือกับความท้าทาย:
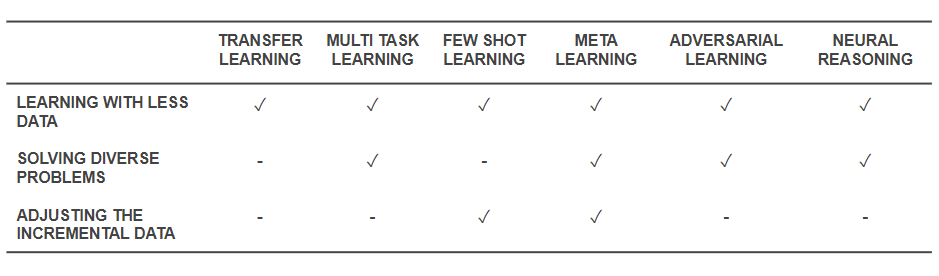
ความสามารถของเทคนิคการเรียนรู้ที่มีประสิทธิภาพ
- เทคนิคทั้งหมดที่กล่าวมาข้างต้นช่วยแก้ปัญหาการฝึกอบรมที่มีข้อมูลน้อยกว่าไม่ทางใดก็ทางหนึ่ง แม้ว่า Meta-Learning จะให้สถาปัตยกรรมที่หล่อหลอมด้วยข้อมูล แต่ Transfer Learning จะทำให้ความรู้จากโดเมนอื่นมีประโยชน์ในการชดเชยข้อมูลน้อยลง การเรียนรู้ไม่กี่ช็อตทุ่มเทให้กับปัญหาในฐานะวินัยทางวิทยาศาสตร์ การเรียนรู้จากฝ่ายตรงข้ามสามารถช่วยปรับปรุงชุดข้อมูลได้
- การปรับโดเมน (ประเภทของการเรียนรู้แบบหลายงาน) การเรียนรู้จากฝ่ายตรงข้าม และ (บางครั้ง) สถาปัตยกรรมการเรียนรู้เมตาช่วยแก้ปัญหาที่เกิดจากความหลากหลายของข้อมูล
- Meta-Learning และ Less Shot Learning ช่วยแก้ปัญหาข้อมูลที่เพิ่มขึ้น
- อัลกอริธึมการให้เหตุผลทางประสาทมีศักยภาพมหาศาลในการแก้ปัญหาในโลกแห่งความเป็นจริงเมื่อรวมเป็น Meta-Learners หรือ Few Shot Learners
โปรดทราบว่า เทคนิคการเรียนรู้อย่างมีประสิทธิภาพเหล่านี้ไม่ใช่เทคนิค Deep Learning/Machine Learning ใหม่ แต่เสริมเทคนิคที่มีอยู่ให้เป็นแฮ็กที่ ทำให้พวกเขาเสียเงินมากขึ้น ดังนั้น คุณจะยังคงเห็นเครื่องมือทั่วไปของเรา เช่น Convolutional Neural Networks และ LSTM ที่ใช้งานได้จริง แต่มีเครื่องเทศที่เพิ่มเข้ามา เทคนิคการเรียนรู้อย่างมีประสิทธิภาพเหล่านี้ซึ่งทำงานกับข้อมูลน้อยลงและทำงานหลายอย่างพร้อมกันสามารถช่วยในการผลิตและการค้าผลิตภัณฑ์และบริการที่ขับเคลื่อนด้วย AI ได้ง่ายขึ้น ที่ ParallelDots เราตระหนักถึงพลังของการเรียนรู้อย่างมีประสิทธิภาพและรวมเอามันเป็นหนึ่งในคุณสมบัติหลักของปรัชญาการวิจัยของเรา
โพสต์นี้โดย Parth Shrivastava ปรากฏตัวครั้งแรกบนบล็อก ParallelDots และทำซ้ำโดยได้รับอนุญาต