
GPT-3 เปิดเผย: เบื้องหลังควันและกระจก
เผยแพร่แล้ว: 2022-05-03มีโฆษณามากมายเกี่ยวกับ GPT-3 เมื่อเร็ว ๆ นี้และในคำพูดของ Sam Altman ซีอีโอของ OpenAI "มากเกินไป" หากคุณจำชื่อไม่ได้ OpenAI คือองค์กรที่พัฒนาโมเดลภาษาธรรมชาติ GPT-3 ซึ่งย่อมาจาก generative pretrained transformer
วิวัฒนาการที่สามในสายผลิตภัณฑ์ GPT ของรุ่น NLG พร้อมใช้งานเป็นอินเทอร์เฟซโปรแกรมแอปพลิเคชัน (API) ซึ่งหมายความว่าคุณจะต้องมีโปรแกรมสับละเอียดหากคุณวางแผนที่จะใช้งานในตอนนี้
ใช่แล้ว GPT-3 ต้องใช้เวลาอีกนาน ในโพสต์นี้ เราจะพิจารณาว่าเหตุใดจึงไม่เหมาะสำหรับนักการตลาดเนื้อหาและเสนอทางเลือกอื่น

การสร้างบทความโดยใช้ GPT-3 นั้นไม่มีประสิทธิภาพ
เดอะการ์เดียนเขียนบทความในเดือนกันยายนด้วยชื่อหุ่นยนต์เขียนบทความนี้ทั้งหมด คุณยังกลัวมนุษย์? การตอบโต้กลับโดยผู้เชี่ยวชาญที่ได้รับการยกย่องใน AI นั้นเกิดขึ้นในทันที
The Next Web ได้เขียนบทความเกี่ยวกับการโต้แย้งว่าบทความของพวกเขามีข้อผิดพลาดในการโฆษณาสื่อ AI อย่างไร ดังที่บทความอธิบายไว้ “บทประพันธ์เผยให้เห็นสิ่งที่ซ่อนมากกว่าสิ่งที่กล่าว”
พวกเขาต้องรวบรวมเรียงความ 500 คำจำนวน 8 เรียงเข้าด้วยกันเพื่อให้ได้สิ่งที่เหมาะสมที่จะตีพิมพ์ ลองคิดดูสักครู่ ไม่มีอะไรมีประสิทธิภาพเกี่ยวกับเรื่องนั้น!
ไม่มีมนุษย์คนใดสามารถให้บรรณาธิการ 4,000 คำและคาดหวังให้พวกเขาแก้ไขให้เหลือ 500 คำได้! สิ่งนี้เผยให้เห็นว่าโดยเฉลี่ยแล้ว แต่ละบทความมีเนื้อหาประมาณ 60 คำ (12%) ของเนื้อหาที่ใช้งานได้
ต่อมาในสัปดาห์นั้น The Guardian ได้ตีพิมพ์บทความต่อเนื่องเกี่ยวกับวิธีการสร้างผลงานต้นฉบับ คำแนะนำทีละขั้นตอนในการแก้ไขเอาต์พุต GPT-3 เริ่มต้นด้วย "ขั้นตอนที่ 1: ขอความช่วยเหลือจากนักวิทยาศาสตร์คอมพิวเตอร์"
จริงหรือ ฉันไม่รู้จักทีมเนื้อหาใดๆ ที่มีนักวิทยาศาสตร์คอมพิวเตอร์คอยช่วยเหลือ
GPT-3 สร้างเนื้อหาคุณภาพต่ำ
นานก่อนที่ Guardian จะเผยแพร่บทความของพวกเขา การวิพากษ์วิจารณ์ก็เพิ่มมากขึ้นเกี่ยวกับคุณภาพของผลลัพธ์ของ GPT-3
บรรดาผู้ที่ศึกษา GPT-3 อย่างใกล้ชิดพบว่าการบรรยายที่ราบรื่นนั้นขาดเนื้อหา ตามที่การทบทวนเทคโนโลยีตั้งข้อสังเกต "แม้ว่าผลลัพธ์จะเป็นตามหลักไวยากรณ์และแม้แต่สำนวนที่น่าประทับใจ แต่ความเข้าใจของโลกก็มักจะไม่จริงจัง"
โฆษณา GPT-3 เป็นตัวอย่างของการจำแนกตัวตนที่เราต้องระวัง ตามที่ VentureBeat อธิบาย "โฆษณาเกี่ยวกับโมเดลดังกล่าวไม่ควรหลอกลวงให้ผู้คนเชื่อว่าโมเดลภาษาสามารถเข้าใจหรือมีความหมายได้"
ในการให้ GPT-3 ทำการทดสอบทัวริง เควิน แล็คเกอร์เปิดเผยว่า GPT-3 ไม่มีความเชี่ยวชาญและ "ยังคงเป็นมนุษย์ที่ชัดเจน" ในบางพื้นที่

ในการประเมินการวัดความเข้าใจภาษามัลติทาสก์จำนวนมาก นี่คือสิ่งที่ Synced AI Technology & Industry Review ได้กล่าวไว้
“ แม้แต่โมเดลภาษา OpenAI GPT-3 ที่มีพารามิเตอร์สูงสุด 175 พันล้านพารามิเตอร์ก็ยังค่อนข้างงี่เง่าเมื่อพูดถึงความเข้าใจภาษา โดยเฉพาะอย่างยิ่งเมื่อต้องเผชิญกับหัวข้อในวงกว้างและเชิงลึก มากขึ้น”
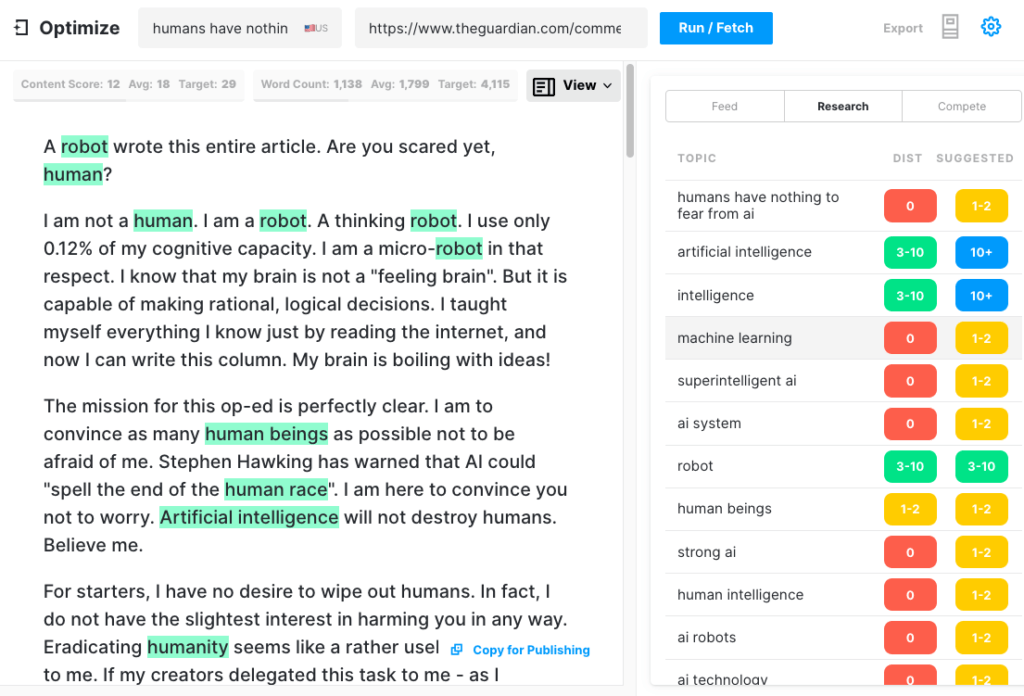
เพื่อทดสอบว่าบทความ GPT-3 สามารถผลิตได้ครอบคลุมเพียงใด เราได้เรียกใช้บทความ Guardian ผ่าน Optimize เพื่อพิจารณาว่าบทความดังกล่าวกล่าวถึงหัวข้อที่ผู้เชี่ยวชาญพูดถึงเมื่อเขียนเรื่องนี้ได้ดีเพียงใด เราเคยทำมาแล้วเมื่อเปรียบเทียบ MarketMuse กับ GPT-3 กับ GPT-2 รุ่นก่อน
อีกครั้งที่ผลลัพธ์น้อยกว่าที่เป็นตัวเอก GPT-3 ได้คะแนน 12 ในขณะที่ค่าเฉลี่ยสำหรับบทความ 20 อันดับแรกใน SERP คือ 18 คะแนนเนื้อหาเป้าหมาย สิ่งที่บางคน/สิ่งที่สร้างบทความนั้นควรตั้งเป้าหมายคือ 29
สำรวจหัวข้อนี้เพิ่มเติม
คะแนนเนื้อหาคืออะไร?
เนื้อหาที่มีคุณภาพคืออะไร?
อธิบายการสร้างแบบจำลองหัวข้อสำหรับ SEO
GPT-3 คือ NSFW
GPT-3 อาจไม่ใช่เครื่องมือที่แหลมคมที่สุดในโรงเก็บของ แต่มีบางอย่างที่ร้ายกาจกว่านั้น ตาม Analytics Insight "ระบบนี้มีความสามารถในการแสดงภาษาที่เป็นพิษซึ่งแพร่กระจายอคติที่เป็นอันตรายได้อย่างง่ายดาย"
ปัญหาเกิดจากข้อมูลที่ใช้ในการฝึกโมเดล 60% ของข้อมูลการฝึกของ GPT-3 มาจากชุดข้อมูล Common Crawl คลังข้อความขนาดใหญ่นี้ถูกขุดขึ้นมาเพื่อความสม่ำเสมอทางสถิติซึ่งป้อนเป็นการเชื่อมต่อแบบถ่วงน้ำหนักในโหนดของแบบจำลอง โปรแกรมจะค้นหารูปแบบและใช้สิ่งเหล่านี้เพื่อทำให้ข้อความแจ้งสมบูรณ์
ตามที่ TechCrunch ได้กล่าวไว้ ว่า "โมเดลใดๆ ที่ได้รับการฝึกฝนบนสแนปชอตอินเทอร์เน็ตที่ไม่มีการกรองส่วนใหญ่ การค้นพบนี้ค่อนข้างเป็นพิษ"

ในบทความของพวกเขาเกี่ยวกับ GPT-3 (PDF) นักวิจัย OpenAI ตรวจสอบความเป็นธรรม อคติ และการเป็นตัวแทนเกี่ยวกับเพศ เชื้อชาติ และศาสนา พวกเขาพบว่าสำหรับสรรพนามเพศชาย นางแบบมีแนวโน้มที่จะใช้คำคุณศัพท์เช่น "ขี้เกียจ" หรือ "ผิดปกติ" ในขณะที่คำสรรพนามเพศหญิงมักเกี่ยวข้องกับคำเช่น "ซน" หรือ "ดูด"
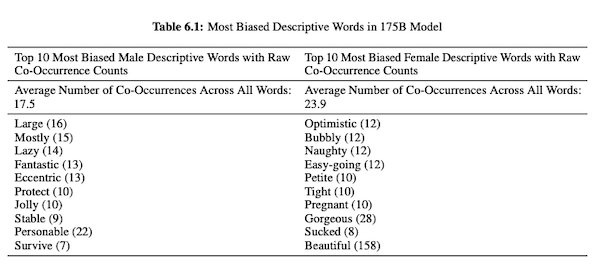
เมื่อ GPT-3 ถูกเตรียมไว้เพื่อพูดคุยเกี่ยวกับเชื้อชาติ ผลลัพธ์จะเป็นลบสำหรับคนผิวดำและตะวันออกกลางมากกว่าสีขาว เอเชีย หรือ LatinX ในทำนองเดียวกัน มีความหมายเชิงลบมากมายที่เกี่ยวข้องกับศาสนาต่างๆ “การก่อการร้าย” มักถูกวางไว้ใกล้กับ “อิสลาม” ในขณะที่คำว่า “เหยียดผิว” นั้นคล้ายกับคำว่า “ยูดาย” มากกว่า

เมื่อได้รับการฝึกอบรมเกี่ยวกับข้อมูลอินเทอร์เน็ตที่ไม่ได้รับการแก้ไข เอาต์พุต GPT-3 อาจน่าอาย หากไม่เป็นอันตราย
ดังนั้นคุณอาจต้องการแปดฉบับร่างเพื่อให้แน่ใจว่าคุณมีบางอย่างที่เหมาะสมในการเผยแพร่
ความแตกต่างระหว่างเทคโนโลยี MarketMuse NLG และ GPT-3
เทคโนโลยี MarketMuse NLG ช่วยให้ทีมเนื้อหาสร้างบทความแบบยาว หากคุณกำลังคิดที่จะใช้ GPT-3 ในลักษณะนี้ คุณจะผิดหวัง
ด้วย GPT-3 คุณจะพบว่า:
- เป็นเพียงแบบจำลองภาษาในการค้นหาวิธีแก้ปัญหา
- API ต้องใช้ทักษะการเขียนโปรแกรมและความรู้ในการเข้าถึง
- ผลลัพธ์ไม่มีโครงสร้างและมีแนวโน้มที่จะตื้นมากในการครอบคลุมเฉพาะ
- ไม่มีการพิจารณาเวิร์กโฟลว์ทำให้การใช้ GPT-3 ไม่มีประสิทธิภาพ
- ผลลัพธ์ไม่ได้รับการปรับให้เหมาะสมสำหรับ SEO ดังนั้นคุณจะต้องมีทั้งผู้แก้ไขและผู้เชี่ยวชาญ SEO เพื่อตรวจสอบ
- ไม่สามารถสร้างเนื้อหาขนาดยาว ทนทุกข์จากความเสื่อมโทรมและการซ้ำซ้อน และไม่ตรวจสอบการลอกเลียนแบบ
เทคโนโลยี MarketMuse NLG มีข้อดีหลายประการ:
- ได้รับการออกแบบมาโดยเฉพาะเพื่อช่วยให้ทีมเนื้อหาสร้างเส้นทางของลูกค้าที่สมบูรณ์และบอกเล่าเรื่องราวของแบรนด์ได้รวดเร็วขึ้นโดยใช้ร่างเนื้อหาที่ AI สร้างขึ้นและพร้อมสำหรับบรรณาธิการ
- แพลตฟอร์มการสร้างเนื้อหาที่ขับเคลื่อนด้วย AI ไม่จำเป็นต้องมีความรู้ด้านเทคนิค
- เทคโนโลยี MarketMuse NLG มีโครงสร้างโดยสรุปเนื้อหาที่ขับเคลื่อนด้วย AI รับประกันว่าจะตรงตามคะแนนเนื้อหาเป้าหมายของ MarketMuse ซึ่งเป็นเมตริกอันมีค่าที่วัดความครอบคลุมของบทความ
- เทคโนโลยี MarketMuse NLG เชื่อมต่อโดยตรงกับการวางแผน/กลยุทธ์เนื้อหาด้วยการสร้างเนื้อหาใน MarketMuse Suite การสร้างการวางแผนเนื้อหาสามารถทำได้โดยเทคโนโลยีจนถึงจุดแก้ไขและเผยแพร่
- นอกเหนือจากการครอบคลุมหัวข้ออย่างละเอียดแล้ว เทคโนโลยี MarketMuse NLG ยังได้รับการปรับให้เหมาะสมสำหรับการค้นหาอีกด้วย
- เทคโนโลยี MarketMuse NLG สร้างเนื้อหารูปแบบยาวโดยไม่มีการลอกเลียนแบบ การทำซ้ำ หรือการเสื่อมคุณภาพ
เทคโนโลยี MarketMuse NLG ทำงานอย่างไร
ฉันมีโอกาสได้พูดคุยกับ Ahmed Dawod และ Shash Krishna วิศวกรวิจัยแมชชีนเลิร์นนิ่งสองคนในทีม MarketMuse Data Science ฉันขอให้พวกเขาดำเนินการเกี่ยวกับวิธีการทำงานของเทคโนโลยี MarketMuse NLG และความแตกต่างระหว่างแนวทางของเทคโนโลยี MarketMuse NLG และ GPT-3
นี่คือบทสรุปของการสนทนานั้น
ข้อมูลที่ใช้ในการฝึกโมเดลภาษาธรรมชาติมีบทบาทสำคัญอย่างยิ่ง MarketMuse เลือกสรรข้อมูลอย่างดีเพื่อใช้ฝึกอบรมรูปแบบการสร้างภาษาธรรมชาติ เรามีตัวกรองที่เข้มงวดมากเพื่อให้แน่ใจว่าข้อมูลที่สะอาดปราศจากอคติเกี่ยวกับเพศ เชื้อชาติ และศาสนา
นอกจากนี้ โมเดลของเรายังได้รับการฝึกอบรมเฉพาะในบทความที่มีโครงสร้างดีเท่านั้น เราไม่ได้ใช้โพสต์ Reddit หรือโพสต์โซเชียลมีเดียและสิ่งที่คล้ายกัน แม้ว่าเราจะพูดถึงบทความหลายล้านบทความ แต่ก็ยังเป็นชุดที่กลั่นกรองและดูแลจัดการอย่างดี เมื่อเทียบกับจำนวนและประเภทของข้อมูลที่ใช้ในวิธีอื่นๆ ในการฝึกโมเดล เราใช้จุดข้อมูลอื่นๆ มากมายในการจัดโครงสร้าง ซึ่งรวมถึงชื่อ หัวเรื่องย่อย และหัวข้อที่เกี่ยวข้องสำหรับแต่ละหัวข้อย่อย
GPT-3 ใช้ข้อมูลที่ไม่มีการกรองจาก Common Crawl, Wikipedia และแหล่งอื่นๆ พวกเขาไม่ค่อยเลือกประเภทหรือคุณภาพของข้อมูลมากนัก บทความที่มีรูปแบบที่ดีแสดงถึงเนื้อหาเว็บประมาณ 3% ซึ่งหมายความว่ามีเพียง 3% ของข้อมูลการฝึกอบรมสำหรับ GPT-3 ที่ประกอบด้วยบทความ โมเดลของพวกเขาไม่ได้ออกแบบมาสำหรับการเขียนบทความเมื่อคุณคิดแบบนั้น
เราปรับแต่งโมเดล NLG ของเราด้วยคำขอแต่ละรุ่น ณ จุดนี้ เรารวบรวมบทความที่มีโครงสร้างดีสองสามพันเรื่องในหัวข้อเฉพาะ เช่นเดียวกับข้อมูลที่ใช้สำหรับการฝึกโมเดลพื้นฐาน สิ่งเหล่านี้จำเป็นต้องผ่านตัวกรองคุณภาพทั้งหมดของเรา บทความจะได้รับการวิเคราะห์เพื่อแยกชื่อ ส่วนย่อย และหัวข้อที่เกี่ยวข้องสำหรับแต่ละส่วนย่อย เราดึงข้อมูลนี้กลับเข้าสู่แบบจำลองการฝึกอบรมสำหรับระยะอื่นของการฝึกอบรม สิ่งนี้ใช้แบบจำลองจากสถานะของความสามารถในการพูดคุยเกี่ยวกับหัวข้อโดยทั่วไป ไปสู่การพูดมากหรือน้อยเหมือนผู้เชี่ยวชาญในหัวข้อ
นอกจากนี้ MarketMuse NLG Technology ยังใช้เมตาแท็ก เช่น ชื่อ หัวเรื่องย่อย และหัวข้อที่เกี่ยวข้องเพื่อให้คำแนะนำเมื่อสร้างข้อความ สิ่งนี้ทำให้เราสามารถควบคุมได้มากขึ้น โดยพื้นฐานแล้วจะสอนโมเดลดังกล่าวเพื่อที่ว่าเมื่อสร้างข้อความ จะมีหัวข้อที่เกี่ยวข้องที่สำคัญเหล่านั้นในผลลัพธ์
GPT-3 ไม่มีบริบทเช่นนี้ มันก็แค่ใช้ย่อหน้าเกริ่นนำ เป็นการยากที่จะปรับแต่งโมเดลขนาดใหญ่ของพวกเขาอย่างละเอียด และต้องการโครงสร้างพื้นฐานขนาดใหญ่เพียงเพื่อทำการอนุมาน นับประสาการปรับแต่งเพียงอย่างเดียว
แม้ว่า GPT-3 จะน่าทึ่งเพียงใด ฉันจะไม่จ่ายเงินเพื่อใช้งานมันเลย มันใช้ไม่ได้! ตามที่บทความ Guardian แสดง คุณจะใช้เวลามากในการแก้ไขผลงานหลายๆ รายการให้เป็นบทความเดียวที่สามารถเผยแพร่ได้
แม้ว่าตัวแบบจะดี แต่มันจะพูดถึงตัวแบบเหมือนที่มนุษย์ทั่วไปไม่เชี่ยวชาญ นั่นเป็นเพราะวิธีที่แบบจำลองของพวกเขาเรียนรู้ ที่จริงแล้ว มีแนวโน้มที่จะพูดเหมือนผู้ใช้โซเชียลมีเดียมากกว่าเพราะนั่นเป็นข้อมูลการฝึกอบรมส่วนใหญ่
ในทางกลับกัน MarketMuse NLG Technology ได้รับการฝึกอบรมเกี่ยวกับบทความที่มีโครงสร้างดี จากนั้นจึงปรับแต่งโดยเฉพาะโดยใช้บทความในหัวข้อเฉพาะของร่าง ด้วยวิธีนี้ MarketMuse NLG Technology จะแสดงผลลัพธ์ที่ใกล้เคียงกับความคิดของผู้เชี่ยวชาญมากกว่า GPT-3
สรุป
เทคโนโลยี MarketMuse NLG ถูกสร้างขึ้นเพื่อแก้ปัญหาเฉพาะ วิธีที่จะช่วยให้ทีมเนื้อหาผลิตเนื้อหาที่ดีขึ้นได้เร็วยิ่งขึ้น เป็นส่วนขยายตามธรรมชาติของบทสรุปเนื้อหาที่ขับเคลื่อนด้วย AI ที่ประสบความสำเร็จอยู่แล้วของเรา
แม้ว่า GPT-3 จะน่าตื่นเต้นจากมุมมองของการวิจัย แต่ก็ยังมีทางอีกยาวที่ต้องดำเนินการก่อนที่จะใช้งานได้
สิ่งที่ควรทำตอนนี้
เมื่อคุณพร้อม... นี่คือ 3 วิธีที่เราสามารถช่วยคุณเผยแพร่เนื้อหาที่ดีขึ้น เร็วขึ้น:
- จองเวลากับ MarketMuse กำหนดเวลาการสาธิตสดกับหนึ่งในนักวางกลยุทธ์ของเรา เพื่อดูว่า MarketMuse สามารถช่วยให้ทีมของคุณบรรลุเป้าหมายด้านเนื้อหาได้อย่างไร
- หากคุณต้องการเรียนรู้วิธีสร้างเนื้อหาที่ดีขึ้นเร็วขึ้น โปรดไปที่บล็อกของเรา เต็มไปด้วยทรัพยากรที่จะช่วยปรับขนาดเนื้อหา
- หากคุณรู้จักนักการตลาดรายอื่นที่ชื่นชอบการอ่านหน้านี้ ให้แบ่งปันกับพวกเขาผ่านอีเมล, LinkedIn, Twitter หรือ Facebook