
Noindex Nofollow และ Disallow: ค้นหาคำสั่งของโปรแกรมรวบรวมข้อมูล
เผยแพร่แล้ว: 2022-12-01มีสามคำสั่ง (คำสั่ง) ที่คุณสามารถใช้เพื่อกำหนดวิธีที่เครื่องมือค้นหาค้นพบ จัดเก็บ และให้บริการข้อมูลจากไซต์ของคุณเป็นผลการค้นหา:
- NoIndex: อย่าเพิ่มเพจของฉันในผลการค้นหา
- NoFollow: อย่าดูลิงก์ในหน้านี้
- Disallow: อย่าดูหน้านี้เลย
คำสั่งเหล่านี้ช่วยให้คุณควบคุมได้ว่าหน้าใดในไซต์ของคุณที่เครื่องมือค้นหาจะรวบรวมข้อมูลและปรากฏในการค้นหา
ไม่มีดัชนีหมายความว่าอย่างไร
คำสั่ง noindex บอกโปรแกรมรวบรวมข้อมูลการค้นหา เช่น googlebot ไม่ให้รวมหน้าเว็บในผลการค้นหา

คุณทำเครื่องหมายหน้า NoIndex อย่างไร
มีสองวิธีในการออกคำสั่ง noindex :
- เพิ่มเมตาแท็ก noindex ให้กับโค้ด HTML ของหน้า
- ส่งคืนส่วนหัว noindex ในคำขอ HTTP
การใช้เมตาแท็ก "ไม่มีดัชนี" สำหรับหน้าหรือเป็นส่วนหัวการตอบสนอง HTTP เท่ากับคุณกำลังซ่อนหน้าจากการค้นหา
นอกจากนี้ยังสามารถใช้คำสั่ง noindex เพื่อบล็อกเฉพาะเครื่องมือค้นหาที่ระบุเท่านั้น ตัวอย่างเช่น คุณสามารถบล็อก Google ไม่ให้จัดทำดัชนีหน้า แต่ยังคงอนุญาต Bing:
ตัวอย่าง: การปิดกั้นเครื่องมือค้นหาส่วนใหญ่*
<ชื่อเมตา=”หุ่นยนต์” เนื้อหา=”noindex”>
ตัวอย่าง: การบล็อกเฉพาะ Google
<ชื่อเมตา=”googlebot” เนื้อหา=”noindex”>
โปรดทราบ: ตั้งแต่เดือนกันยายน 2019 Google ไม่ปฏิบัติตามคำสั่ง noindex ในไฟล์ robots.txt อีกต่อไป ขณะนี้ Noindex ต้องออกผ่านเมตาแท็ก HTML หรือส่วนหัวการตอบสนอง HTTP สำหรับผู้ใช้ขั้นสูง การ ไม่อนุญาต ยังคงใช้งานได้ในขณะนี้ แม้ว่าจะไม่ใช่กับทุกกรณีการใช้งาน
noindex กับ nofollow ต่างกันอย่างไร?
ความแตกต่างระหว่างการจัดเก็บเนื้อหาและการค้นหาเนื้อหา:
noindex จะถูกนำไปใช้ที่ระดับหน้าและบอกโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาว่าไม่ต้องจัดทำดัชนีและแสดงหน้าในผลการค้นหา
ใช้ nofollow ที่ระดับเพจหรือลิงก์ และบอกโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาว่าอย่าติดตาม (ค้นพบ) ลิงก์
โดยพื้นฐานแล้ว แท็ก noindex จะลบหน้าออกจากดัชนีการค้นหา และแอตทริบิวต์ nofollow จะลบลิงก์ออกจากกราฟลิงก์ของเครื่องมือค้นหา
ไม่ติดตามเป็นแอตทริบิวต์ของเพจ
การใช้ nofollow ที่ระดับเพจหมายความว่าโปรแกรมรวบรวมข้อมูลจะไม่ติดตามลิงก์ใดๆ ในหน้านั้นเพื่อค้นหาเนื้อหาเพิ่มเติม และโปรแกรมรวบรวมข้อมูลจะไม่ใช้ลิงก์เป็นสัญญาณการจัดอันดับสำหรับไซต์เป้าหมาย
<ชื่อเมตา=”หุ่นยนต์” เนื้อหา=”nofollow”>
NoFollow เป็นแอตทริบิวต์ลิงก์
การใช้ nofollow ที่ระดับลิงก์จะป้องกันไม่ให้โปรแกรมรวบรวมข้อมูลสำรวจลิงก์เฉพาะของโฆษณา และป้องกันไม่ให้ใช้ลิงก์นั้นเป็นสัญญาณการจัดอันดับ
คำสั่ง nofollow ถูกนำไปใช้ที่ระดับลิงก์โดยใช้แอตทริบิวต์ rel ภายในแท็ก href:
<a href=”https://domain.com” rel=”nofollow”>
สำหรับ Google โดยเฉพาะ การใช้แอตทริบิวต์ลิงก์ nofollow จะป้องกันไม่ให้ไซต์ของคุณส่ง PageRank ไปยัง URL ปลายทาง
ทำไมคุณควรทำเครื่องหมายเพจเป็น NoFollow?
ในกรณีการใช้งานส่วนใหญ่ คุณ ไม่ ควรทำเครื่องหมายทั้งหน้าเป็น nofollow การทำเครื่องหมายแต่ละลิงก์เป็น nofollow ก็เพียงพอแล้ว
คุณจะทำเครื่องหมายทั้งหน้าเป็น nofollow หากคุณไม่ต้องการให้ Google ดูลิงก์ในหน้านั้น หรือหากคุณคิดว่าลิงก์ในหน้านั้นอาจทำให้ไซต์ของคุณเสียหายได้
ในกรณีส่วนใหญ่ คำสั่ง nofollow ระดับเพจแบบครอบคลุมจะใช้เมื่อคุณไม่มีอำนาจควบคุมเนื้อหาที่โพสต์บนเพจ ผู้เผยแพร่โฆษณาระดับไฮเอนด์บางรายยังใช้คำสั่ง nofollow กับเพจของตนอย่างครอบคลุมเพื่อห้ามไม่ให้ผู้เขียนวางลิงก์ผู้สนับสนุนไว้ในเนื้อหาของตน
ฉันจะใช้ NoIndex Pages ได้อย่างไร
ทำเครื่องหมายหน้าเว็บเป็น noindex ซึ่งไม่น่าจะให้คุณค่าแก่ผู้ใช้ และไม่ควรแสดงเป็นผลการค้นหา ตัวอย่างเช่น หน้าเว็บที่มีอยู่สำหรับการแบ่งหน้าไม่น่าจะมีเนื้อหาเดียวกันปรากฏเมื่อเวลาผ่านไป
Domain.com/category/resultspage=2 ไม่น่าจะแสดงผลลัพธ์ที่ดีกว่าแก่ผู้ใช้มากกว่า domain.com/category/resultspage=1 และทั้งสองหน้าจะแข่งขันกันในการค้นหาเท่านั้น เป็นการดีที่สุดที่จะ noindex หน้าที่มีจุดประสงค์เพียงอย่างเดียวคือการแบ่งหน้า
ต่อไปนี้คือประเภทของหน้าเว็บที่คุณควรพิจารณาไม่จัดทำดัชนี:
- หน้าที่ใช้ในการแบ่งหน้า
- หน้าค้นหาภายใน
- หน้า Landing Page ที่เพิ่มประสิทธิภาพโฆษณา
- ตัวอย่าง: แสดงเฉพาะการเสนอขายและแบบฟอร์มลงทะเบียน ไม่มีการนำทางหลัก
- ตัวอย่าง: รูปแบบที่ซ้ำกันของเนื้อหาเดียวกัน ใช้สำหรับโฆษณาเท่านั้น
- หน้าผู้เขียนที่เก็บถาวร
- หน้าในขั้นตอนการชำระเงิน
- หน้ายืนยัน
- เช่นหน้าขอบคุณ
- ตัวอย่าง: สั่งซื้อหน้าที่สมบูรณ์
- ตัวอย่าง: สำเร็จ! หน้า
- หน้าที่สร้างด้วยปลั๊กอินบางหน้าที่ไม่เกี่ยวข้องกับไซต์ของคุณ (เช่น หากคุณใช้ปลั๊กอินการค้าแต่ไม่ได้ใช้หน้าผลิตภัณฑ์ปกติ)
- หน้าผู้ดูแลระบบและหน้าเข้าสู่ระบบของผู้ดูแลระบบ
ทำเครื่องหมายหน้า Noindex และ Nofollow
หน้าที่ทำเครื่องหมายทั้ง noindex และ nofollow จะบล็อกโปรแกรมรวบรวมข้อมูลไม่ให้จัดทำดัชนีหน้านั้น และบล็อกโปรแกรมรวบรวมข้อมูลไม่ให้สำรวจลิงก์ในหน้านั้น
โดยพื้นฐานแล้ว รูปภาพด้านล่างแสดงให้เห็นว่าเครื่องมือค้นหาจะเห็นอะไรบนหน้าเว็บ ขึ้นอยู่กับว่าคุณใช้คำสั่ง noindex และ nofollow อย่างไร:

การทำเครื่องหมายหน้าที่จัดทำดัชนีแล้วเป็น NoIndex
หากเครื่องมือค้นหาจัดทำดัชนีหน้าเว็บแล้ว และคุณทำเครื่องหมายว่าเป็น noindex ครั้งต่อไปที่มีการรวบรวมข้อมูลหน้าเว็บนั้นจะถูกลบออกจากผล เพื่อให้วิธีการลบหน้าออกจากดัชนีนี้ใช้งานได้ คุณต้องไม่บล็อก (ไม่อนุญาต) โปรแกรมรวบรวมข้อมูลด้วยไฟล์ robots.txt ของคุณ
หากคุณบอกโปรแกรมรวบรวมข้อมูลไม่ให้อ่านหน้าเว็บ โปรแกรมรวบรวมข้อมูลจะไม่เห็นเครื่องหมาย noindex และหน้าเว็บจะยังคงจัดทำดัชนีแม้ว่าเนื้อหาจะไม่ได้รับการรีเฟรช
ฉันจะหยุดเครื่องมือค้นหาไม่ให้จัดทำดัชนีไซต์ของฉันได้อย่างไร
หากคุณต้องการลบเพจออกจากดัชนีการค้นหา หลังจากจัดทำดัชนีแล้ว คุณสามารถทำตามขั้นตอนต่อไปนี้:
- ใช้คำสั่ง noindex เพิ่มแอตทริบิวต์ noindex ให้กับเมตาแท็กหรือส่วนหัวการตอบสนอง HTTP
- ขอให้เครื่องมือค้นหารวบรวมข้อมูลหน้า สำหรับ Google คุณสามารถทำได้ในคอนโซลการค้นหา ขอให้ Google จัดทำดัชนีหน้าใหม่ การดำเนินการนี้จะเรียกให้ Googlebot รวบรวมข้อมูลหน้าเว็บ โดยที่ Googlebot จะค้นพบคำสั่ง noindex คุณจะต้องดำเนินการนี้กับเครื่องมือค้นหาแต่ละรายการที่คุณต้องการนำหน้าเว็บออก
- ยืนยันว่าหน้านี้ถูกลบออกจากการค้นหา แล้ว เมื่อคุณขอให้โปรแกรมรวบรวมข้อมูลกลับมาที่หน้าเว็บของคุณอีกครั้ง ให้เวลาสักครู่ จากนั้นจึงยืนยันว่าหน้าของคุณถูกลบออกจากผลการค้นหาแล้ว คุณสามารถทำได้โดยไปที่เครื่องมือค้นหาใดๆ และป้อน URL เป้าหมายของโคลอนของไซต์ เช่นในภาพด้านล่าง
หากการค้นหาของคุณไม่มีผลลัพธ์ แสดงว่าหน้าของคุณถูกลบออกจากดัชนีการค้นหานั้นแล้ว - หากยังไม่ได้นำหน้าออก ตรวจสอบว่าคุณไม่มีคำสั่ง "ไม่อนุญาต" ในไฟล์ robots.txt ของคุณ Google และเครื่องมือค้นหาอื่นๆ ไม่สามารถอ่านคำสั่ง noindex ได้หากไม่ได้รับอนุญาตให้รวบรวมข้อมูลหน้า หากคุณทำเช่นนั้น ให้ลบคำสั่งไม่อนุญาตสำหรับหน้าเป้าหมาย แล้วร้องขอการรวบรวมข้อมูลอีกครั้ง
- ตั้งค่าคำสั่งไม่อนุญาตสำหรับหน้าเป้าหมายในไฟล์ robots.txt Disallow: /page$
คุณจะต้องใส่เครื่องหมายดอลลาร์ที่ส่วนท้ายของ URL ในไฟล์ robots.txt ของคุณ มิฉะนั้นคุณอาจไม่อนุญาตหน้าใดๆ ในหน้านั้น รวมทั้งหน้าใดๆ ที่ขึ้นต้นด้วยสตริงเดียวกันโดยไม่ตั้งใจ ตัวอย่าง: Disallow: /sweater จะไม่อนุญาต /sweater-weather และ /sweater/green ด้วย แต่ Disallow: /sweater$ จะไม่อนุญาตเฉพาะหน้า /sweater เท่านั้น
ยังไง เพื่อลบเพจออกจาก Google Search
หากหน้าที่คุณต้องการนำออกจากการค้นหาอยู่ในไซต์ที่คุณเป็นเจ้าของหรือจัดการ ไซต์ส่วนใหญ่สามารถใช้เครื่องมือลบ URL ของผู้ดูแลเว็บได้
เครื่องมือลบ URL ของผู้ดูแลเว็บจะลบเนื้อหาออกจากการค้นหาเป็นเวลาประมาณ 90 วันเท่านั้น หากคุณต้องการโซลูชันที่ถาวรกว่านี้ คุณจะต้องใช้คำสั่ง noindex ไม่อนุญาตให้รวบรวมข้อมูลจาก robots.txt หรือลบหน้าเว็บออกจากไซต์ของคุณ Google มีคำแนะนำเพิ่มเติมสำหรับการลบ URL อย่างถาวรที่นี่

หากคุณกำลังพยายามลบหน้าออกจากการค้นหาสำหรับไซต์ที่คุณไม่ได้เป็นเจ้าของ คุณสามารถขอให้ Google ลบหน้านั้นออกจากการค้นหาได้หากเป็นไปตามเกณฑ์ต่อไปนี้:
- แสดงข้อมูลส่วนบุคคล เช่น บัตรเครดิตหรือหมายเลขประกันสังคมของคุณ
- หน้านี้เป็นส่วนหนึ่งของโครงการมัลแวร์หรือฟิชชิ่ง
- เพจละเมิดกฎหมาย
- เพจนี้ละเมิดลิขสิทธิ์
หากเพจไม่ตรงตามเกณฑ์ข้อใดข้อหนึ่งข้างต้น คุณสามารถติดต่อบริษัท SEO หรือบริษัทประชาสัมพันธ์เพื่อขอความช่วยเหลือเกี่ยวกับการจัดการชื่อเสียงทางออนไลน์
คุณควร noindex หน้าหมวดหมู่หรือไม่?
โดยปกติแล้ว ไม่แนะนำให้ทำดัชนีหน้าหมวดหมู่ เว้นแต่คุณจะเป็นองค์กรระดับองค์กรที่ปั่นหน้าหมวดหมู่โดยทางโปรแกรมโดยอิงจากการค้นหาหรือแท็กที่ผู้ใช้สร้างขึ้น และเนื้อหาที่ซ้ำกันเริ่มเทอะทะ
ส่วนใหญ่หากคุณแท็กเนื้อหาของคุณอย่างชาญฉลาด ในลักษณะที่ช่วยให้ผู้ใช้สำรวจไซต์ของคุณได้ดีขึ้นและค้นหาสิ่งที่ต้องการ คุณก็ไม่เป็นไร
อันที่จริง หน้าหมวดหมู่สามารถเป็นขุมทองสำหรับ SEO ได้ เนื่องจากโดยทั่วไปแล้วจะแสดงเนื้อหาเชิงลึกภายใต้หัวข้อหมวดหมู่
ดูการวิเคราะห์นี้ที่เราทำในเดือนธันวาคม 2018 เพื่อหามูลค่าของหน้าหมวดหมู่สำหรับสิ่งพิมพ์ออนไลน์จำนวนหนึ่ง
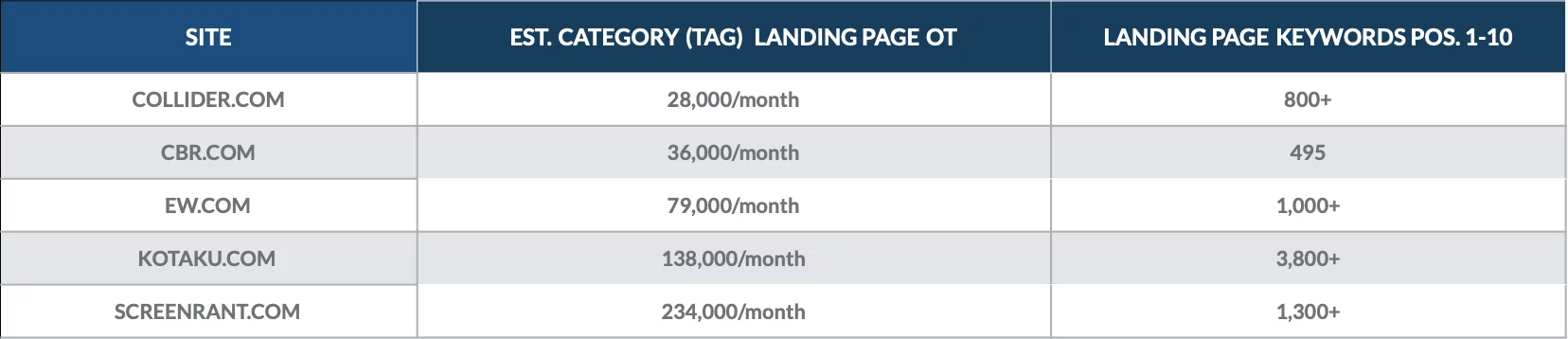
เราพบว่าหน้า Landing Page ของหมวดหมู่นั้นได้รับการจัดอันดับสำหรับคำหลักหลายร้อยหน้า 1 และนำผู้เยี่ยมชมทั่วไปหลายพันคนเข้ามาในแต่ละเดือน
หน้าหมวดหมู่ที่มีค่าที่สุดสำหรับแต่ละไซต์มักจะดึงดูดผู้เข้าชมทั่วไปหลายพันคนในแต่ละหน้า
ลองดูที่ EW.com ด้านล่าง เราวัดปริมาณการเข้าชมแต่ละหน้า (แสดงด้วยขนาดของวงกลม) และมูลค่าของการเข้าชมแต่ละหน้า (แสดงด้วยสีของวงกลม)
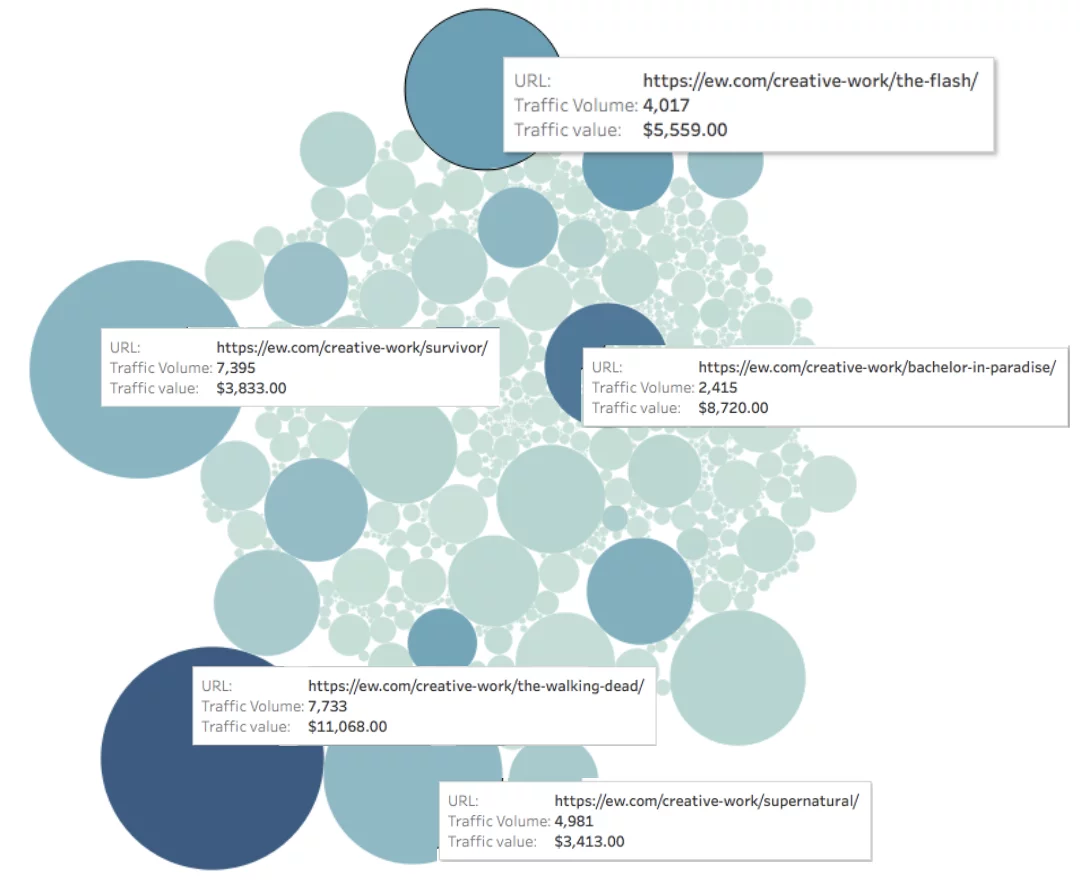
ค่าอินทรีย์รายเดือนของหน้า = ความลึกของสี
ตอนนี้ลองนึกภาพแผนภูมิเดียวกัน แต่สำหรับไซต์ตามผลิตภัณฑ์ที่ผู้เยี่ยมชมมีแนวโน้มที่จะทำการซื้อ
อย่างไรก็ตาม หากหมวดหมู่ของคุณคล้ายกันมากพอที่จะทำให้ผู้ใช้สับสนหรือแข่งขันกันในการค้นหา คุณอาจต้องทำการเปลี่ยนแปลง:
- หากคุณตั้งค่าหมวดหมู่ด้วยตนเอง เราขอแนะนำให้ย้ายเนื้อหาจากหมวดหมู่หนึ่งไปยังอีกหมวดหมู่หนึ่ง และลดจำนวนหมวดหมู่ทั้งหมดที่คุณมีอยู่โดยรวม
- หากคุณอนุญาตให้ผู้ใช้แยกหมวดหมู่ คุณอาจต้องการไม่จัดทำดัชนีหน้าหมวดหมู่ที่ผู้ใช้สร้างขึ้น อย่างน้อยก็จนกว่าหมวดหมู่ใหม่จะผ่านกระบวนการตรวจสอบ
ฉันจะหยุด Google จากการจัดทำดัชนีโดเมนย่อยได้อย่างไร
มีตัวเลือกบางอย่างที่จะหยุดไม่ให้ Google จัดทำดัชนีโดเมนย่อย:
- คุณสามารถเพิ่มรหัสผ่านโดยใช้ไฟล์ .htpasswd
- คุณสามารถไม่อนุญาตโปรแกรมรวบรวมข้อมูลด้วยไฟล์ robots.txt
- คุณสามารถเพิ่มคำสั่ง noindex ให้กับทุกหน้าในโดเมนย่อยได้
- คุณสามารถ 404 หน้าโดเมนย่อยทั้งหมด
การเพิ่มรหัสผ่านเพื่อบล็อกการสร้างดัชนี
หากโดเมนย่อยของคุณมีวัตถุประสงค์เพื่อการพัฒนา การเพิ่มไฟล์ .htpasswd ลงในไดเร็กทอรีรากของโดเมนย่อยของคุณถือเป็นตัวเลือกที่สมบูรณ์แบบ ผนังเข้าสู่ระบบจะป้องกันโปรแกรมรวบรวมข้อมูลสำหรับการจัดทำดัชนีเนื้อหาบนโดเมนย่อย และ จะป้องกันการเข้าถึงของผู้ใช้ที่ไม่ได้รับอนุญาต
ตัวอย่างการใช้งาน:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
การใช้ robots.txt เพื่อบล็อกการจัดทำดัชนี
หากโดเมนย่อยของคุณรองรับวัตถุประสงค์อื่น คุณสามารถเพิ่มไฟล์ robots.txt ลงในไดเร็กทอรีรากของโดเมนย่อยของคุณได้ จากนั้นควรสามารถเข้าถึงได้ดังนี้:
https://subdomain.domain.com/robots.txt
คุณจะต้องเพิ่มไฟล์ robots.txt ในแต่ละโดเมนย่อยที่คุณพยายามบล็อกจากการค้นหา ตัวอย่าง:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
ในแต่ละกรณี ไฟล์ robots.txt ควรไม่อนุญาตให้โปรแกรมรวบรวมข้อมูล หากต้องการบล็อกโปรแกรมรวบรวมข้อมูลส่วนใหญ่ด้วยคำสั่งเดียว ให้ใช้รหัสต่อไปนี้:
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /
ดาว * หลัง user-agent: เรียกว่า wildcard ซึ่งจะจับคู่กับลำดับของอักขระใดก็ได้ การใช้สัญลักษณ์แทนจะส่งคำสั่งที่ไม่อนุญาตต่อไปนี้ไปยังตัวแทนผู้ใช้ทั้งหมดโดยไม่คำนึงถึงชื่อของพวกเขา ตั้งแต่ googlebot ถึง yandex
เครื่องหมายแบ็กสแลชบอกโปรแกรมรวบรวมข้อมูลว่าหน้าทั้งหมดนอกโดเมนย่อยรวมอยู่ในคำสั่งไม่อนุญาต
วิธีเลือกบล็อกการจัดทำดัชนีของหน้าโดเมนย่อย
หากคุณต้องการให้บางหน้าจากโดเมนย่อยปรากฏในการค้นหา แต่ไม่ต้องการให้หน้าอื่นๆ ปรากฏขึ้น คุณมีสองตัวเลือก:
- ใช้คำสั่ง noindex ระดับหน้า
- ใช้คำสั่ง disallow ระดับโฟลเดอร์หรือไดเร็กทอรี
คำสั่ง noindex ระดับหน้าจะยุ่งยากกว่าในการปรับใช้ เนื่องจากคำสั่งนั้นจำเป็นต้องเพิ่มใน HTML หรือส่วนหัวของทุกหน้า อย่างไรก็ตาม คำสั่ง noindex จะหยุดไม่ให้ Google จัดทำดัชนีโดเมนย่อย ไม่ว่าโดเมนย่อยนั้นได้รับการจัดทำดัชนีแล้วหรือไม่ก็ตาม
คำสั่ง disallow ระดับไดเร็กทอรีนั้นนำไปใช้ได้ง่ายกว่า แต่จะใช้งานได้ก็ต่อเมื่อหน้าโดเมนย่อยไม่ได้อยู่ในดัชนีการค้นหาแล้วเท่านั้น เพียงอัปเดตไฟล์ robots.txt ของโดเมนย่อยเพื่อไม่อนุญาตให้รวบรวมข้อมูลไดเรกทอรีหรือโฟลเดอร์ย่อยที่เกี่ยวข้อง
ฉันจะรู้ได้อย่างไรว่าเพจของฉันไม่มีการจัดทำดัชนี
การเพิ่มหน้าคำสั่งที่ไม่มีดัชนีบนไซต์ของคุณโดยไม่ตั้งใจอาจส่งผลอย่างมากต่ออันดับการค้นหาและการแสดงผลการค้นหาของคุณ
หากคุณพบว่าหน้าใดไม่เห็นการเข้าชมแบบออร์แกนิกแม้จะมีเนื้อหาและลิงก์ย้อนกลับที่ดี ก่อนอื่นให้ตรวจสอบก่อนว่าคุณไม่ได้ปิดโปรแกรมรวบรวมข้อมูลจากไฟล์ robots.txt ของคุณโดยไม่ตั้งใจ หากยังไม่สามารถแก้ปัญหาได้ คุณจะต้องตรวจสอบแต่ละหน้าเพื่อหาคำสั่ง noindex
ตรวจสอบ NoIndex บนหน้า WordPress
WordPress ทำให้ง่ายต่อการเพิ่มหรือลบแท็กนี้บนหน้าเว็บของคุณ ขั้นตอนแรกในการตรวจสอบ nofollow บนเพจของคุณคือเพียงแค่สลับการตั้งค่า การมองเห็นของเครื่องมือค้นหา ภายในแท็บ "การอ่าน" ของเมนู "การตั้งค่า"
การดำเนินการนี้น่าจะช่วยแก้ปัญหาได้ อย่างไรก็ตาม การตั้งค่านี้ทำงานเป็น 'คำแนะนำ' แทนที่จะเป็นกฎ และเนื้อหาบางส่วนของคุณอาจจบลงด้วยการจัดทำดัชนีอยู่ดี
เพื่อให้แน่ใจว่าไฟล์และเนื้อหาของคุณมีความเป็นส่วนตัวอย่างแท้จริง คุณจะต้องดำเนินการขั้นตอนสุดท้ายหนึ่งขั้นตอน ไม่ว่าจะเป็นรหัสผ่านป้องกันไซต์ของคุณโดยใช้เครื่องมือการจัดการ cPanel หากมี หรือผ่านปลั๊กอินธรรมดา
ในทำนองเดียวกัน การลบแท็กนี้ออกจากเนื้อหาของคุณทำได้โดยการลบการป้องกันด้วยรหัสผ่านและยกเลิกการเลือกการตั้งค่าการเปิดเผย
กำลังตรวจสอบ NoIndex บน Squarespace
หน้า Squarespace สามารถ NoIndexed ได้อย่างง่ายดายโดยใช้ความสามารถในการฉีดโค้ดของแพลตฟอร์ม เช่นเดียวกับ WordPress Squarespace สามารถบล็อกได้อย่างง่ายดายจากการค้นหาตามปกติโดยใช้การป้องกันด้วยรหัสผ่าน อย่างไรก็ตาม แพลตฟอร์มยังแนะนำไม่ให้ทำตามขั้นตอนนี้เพื่อปกป้องความสมบูรณ์ของเนื้อหาของคุณ
การเพิ่มบรรทัดโค้ด NoIndex ในแต่ละหน้าที่คุณต้องการซ่อนจากเครื่องมือค้นหาทางอินเทอร์เน็ตและในแต่ละหน้าย่อยที่อยู่ด้านล่าง คุณสามารถรับประกันความปลอดภัยของเนื้อหาที่ปลอดภัยซึ่งควรถูกกันไม่ให้เข้าถึงโดยสาธารณะ เช่นเดียวกับแพลตฟอร์มอื่นๆ การลบแท็กนี้ก็ค่อนข้างตรงไปตรงมาเช่นกัน เพียงแค่ใช้ฟีเจอร์ Code Injection เพื่อนำโค้ดกลับออกไป สิ่งที่คุณต้องทำก็คือ
Squarespace มีเอกลักษณ์ตรงที่คู่แข่งเสนอตัวเลือกนี้โดยหลักแล้วเป็นส่วนหนึ่งของชุดการตั้งค่าในเครื่องมือการจัดการเพจ Squarespace ออกจากที่นี่ ทำให้สามารถจัดการโค้ดส่วนตัวได้ สิ่งนี้น่าสนใจเพราะคุณสามารถเห็นการเปลี่ยนแปลงที่คุณทำกับเนื้อหาของเพจของคุณ ซึ่งแตกต่างจากสิ่งอื่นๆ ในพื้นที่นี้
ตรวจสอบ NoIndex บน Wix
Wix ยังช่วยให้สามารถแก้ไขปัญหา NoIndexing ได้ง่ายและรวดเร็ว ในการตั้งค่า “เมนูและหน้า” คุณสามารถปิดใช้งานตัวเลือกเพื่อ 'แสดงหน้านี้ในผลการค้นหา' หากคุณต้องการ NoIndex หน้าเดียวภายในไซต์ของคุณ
เช่นเดียวกับคู่แข่ง Wix ยังแนะนำรหัสผ่านสำหรับปกป้องหน้าเว็บหรือทั้งไซต์ของคุณเพื่อความเป็นส่วนตัวเพิ่มเติม อย่างไรก็ตาม Wix แตกต่างจากที่อื่นตรงที่ทีมสนับสนุนไม่ได้กำหนดการดำเนินการคู่ขนานกันทั้งสองด้านเพื่อรักษาความปลอดภัยเนื้อหาจากโปรแกรมรวบรวมข้อมูล Wix ระบุข้อแตกต่างระหว่างการซ่อนหน้าจากเมนูของคุณกับการซ่อนจากเกณฑ์การค้นหา
นี่เป็นคำแนะนำที่เป็นประโยชน์อย่างยิ่งสำหรับผู้สร้างเว็บไซต์ที่มีประสบการณ์น้อย ซึ่งในตอนแรกอาจไม่เข้าใจความแตกต่าง เนื่องจากการนำออกจากเมนูไซต์ของคุณทำให้ไม่สามารถเข้าถึงหน้าเว็บได้จากไซต์ แต่ไม่ใช่จากข้อความค้นหาของ Google ที่รอบคอบ