
การสร้างแบบจำลองหัวข้อด้วย Word2Vec
เผยแพร่แล้ว: 2022-05-02คำถูกกำหนดโดยบริษัทที่มันเก็บไว้ นั่นคือหลักฐานเบื้องหลัง Word2Vec ซึ่งเป็นวิธีการแปลงคำเป็นตัวเลขและแสดงคำเหล่านั้นในพื้นที่หลายมิติ คำที่พบบ่อยใกล้กันในชุดเอกสาร (คลังข้อมูล) จะปรากฏใกล้กันในพื้นที่นี้ มีการกล่าวกันว่ามีความเกี่ยวข้องตามบริบท
Word2Vec เป็นวิธีการเรียนรู้ของเครื่องที่ต้องใช้คลังข้อมูลและการฝึกอบรมที่เหมาะสม คุณภาพของทั้งคู่ส่งผลต่อความสามารถในการสร้างแบบจำลองหัวข้อได้อย่างแม่นยำ ข้อบกพร่องใด ๆ จะปรากฏชัดทันทีเมื่อตรวจสอบผลลัพธ์สำหรับหัวข้อที่เฉพาะเจาะจงและซับซ้อนมาก เนื่องจากสิ่งเหล่านี้เป็นแบบจำลองที่ยากที่สุดอย่างแม่นยำ สามารถใช้ Word2Vec ได้ด้วยตัวเอง แม้ว่ามักจะใช้ร่วมกับเทคนิคการสร้างแบบจำลองอื่นๆ เพื่อแก้ไขข้อจำกัด
ส่วนที่เหลือของบทความนี้ให้ข้อมูลพื้นฐานเพิ่มเติมเกี่ยวกับ Word2Vec วิธีการทำงาน วิธีการใช้ในการสร้างแบบจำลองหัวข้อ และความท้าทายบางประการที่นำเสนอ
Word2Vec คืออะไร?
ในเดือนกันยายน 2013 นักวิจัยของ Google, Tomas Mikolov, Kai Chen, Greg Corrado และ Jeffrey Dean ได้ตีพิมพ์บทความเรื่อง 'Efficient Estimation of Word Representations in Vector Space' (pdf) นี่คือสิ่งที่เราเรียกว่า Word2Vec เป้าหมายของบทความนี้คือการ “แนะนำเทคนิคที่สามารถใช้สำหรับการเรียนรู้เวกเตอร์คำคุณภาพสูงจากชุดข้อมูลขนาดใหญ่ที่มีคำศัพท์นับพันล้านคำ และคำศัพท์หลายล้านคำในคำศัพท์”
ก่อนหน้านี้ เทคนิคการประมวลผลภาษาธรรมชาติใด ๆ ถือว่าคำเป็นหน่วยเอกพจน์ พวกเขาไม่ได้คำนึงถึงความคล้ายคลึงกันระหว่างคำ แม้ว่าจะมีเหตุผลที่ถูกต้องสำหรับแนวทางนี้ แต่ก็มีข้อจำกัด มีบางสถานการณ์ที่การปรับขนาดเทคนิคพื้นฐานเหล่านี้ไม่สามารถให้การปรับปรุงที่สำคัญได้ จึงต้องพัฒนาเทคโนโลยีขั้นสูง
บทความนี้แสดงให้เห็นว่าแบบจำลองอย่างง่ายซึ่งมีความต้องการในการคำนวณต่ำกว่า สามารถฝึกเวกเตอร์คำคุณภาพสูงได้ เมื่อบทความนี้สรุป "เป็นไปได้ที่จะคำนวณเวกเตอร์คำที่มีมิติสูงที่แม่นยำมากจากชุดข้อมูลที่มีขนาดใหญ่กว่ามาก" พวกเขากำลังพูดถึงการรวบรวมเอกสาร (corpora) ด้วยคำศัพท์หนึ่งล้านล้านคำที่ให้คำศัพท์ขนาดไม่จำกัด
Word2Vec เป็นวิธีการแปลงคำเป็นตัวเลข ในกรณีนี้คือเวกเตอร์ เพื่อให้สามารถค้นพบความคล้ายคลึงกันทางคณิตศาสตร์ แนวคิดก็คือเวกเตอร์ของคำที่คล้ายคลึงกันจะถูกจัดกลุ่มภายในปริภูมิเวกเตอร์
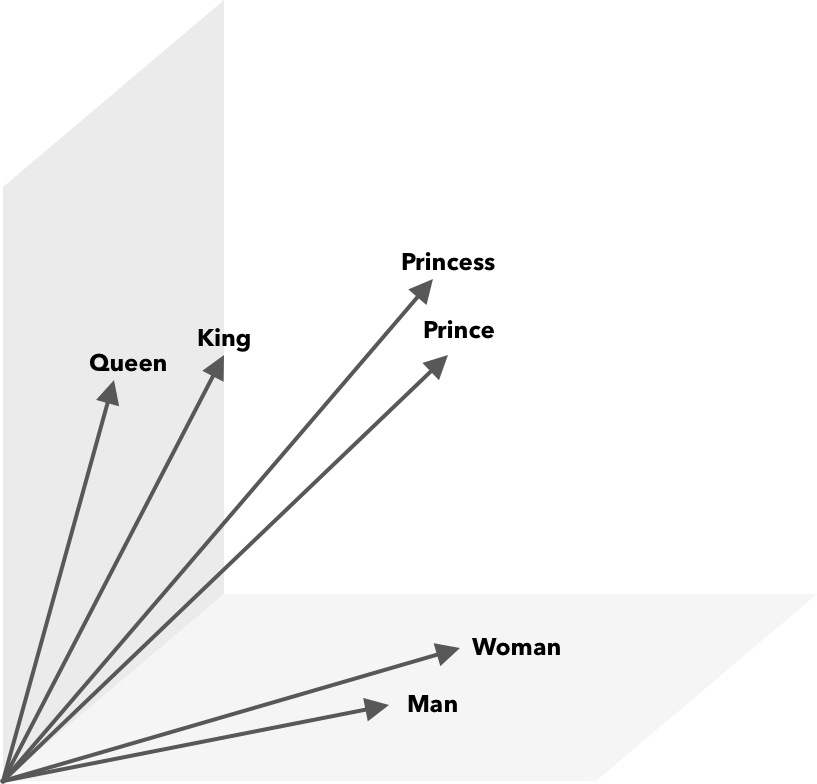
นึกถึงพิกัดละติจูดและลองจิจูดบนแผนที่ เมื่อใช้เวกเตอร์สองมิตินี้ คุณจะระบุได้อย่างรวดเร็วว่าสถานที่สองแห่งอยู่ใกล้กันหรือไม่ สำหรับคำที่จะนำเสนออย่างเหมาะสมในพื้นที่เวกเตอร์ สองมิติไม่เพียงพอ ดังนั้นเวกเตอร์จำเป็นต้องรวมหลายมิติเข้าด้วยกัน
Word2Vec ทำงานอย่างไร
Word2Vec ใช้คลังข้อความขนาดใหญ่เป็นอินพุตและสร้างเวกเตอร์โดยใช้โครงข่ายประสาทตื้น ผลลัพธ์คือรายการคำศัพท์ (คำศัพท์) แต่ละคำมีเวกเตอร์ที่สอดคล้องกัน คำที่มีความหมายคล้ายคลึงกันจะเกิดขึ้นในระยะใกล้ ในทางคณิตศาสตร์ นี่วัดจากความคล้ายคลึงของโคไซน์ โดยที่ความคล้ายคลึงทั้งหมดจะแสดงเป็นมุม 0 องศาในขณะที่ไม่มีความคล้ายคลึงกันจะแสดงเป็นมุม 90 องศา
สามารถเข้ารหัสคำเป็นเวกเตอร์ได้โดยใช้แบบจำลองประเภทต่างๆ ในกระดาษของพวกเขา Mikolov et al. ดูสองโมเดลที่มีอยู่ ได้แก่ feedforward neural net language model (NNLM) และ recurrent neural net language model (RNNLM) นอกจากนี้ พวกเขาเสนอโมเดล log-linear ใหม่ 2 แบบ ได้แก่ ถุงคำแบบต่อเนื่อง (CBOW) และแบบข้ามกรัมแบบต่อเนื่อง
ในการเปรียบเทียบ CBOW และ Skip-gram ทำงานได้ดีกว่า ดังนั้นเรามาตรวจสอบสองรุ่นนี้กัน
CBOW คล้ายกับ NNLM และอาศัยบริบทเพื่อกำหนดคำเป้าหมาย จะกำหนดคำเป้าหมายตามคำที่อยู่ข้างหน้าและข้างหลัง Mikolov พบว่าการแสดงที่ดีที่สุดเกิดขึ้นกับอนาคตสี่คำและคำศัพท์ประวัติศาสตร์สี่คำ เรียกว่า 'ถุงคำ' เพราะลำดับของคำในประวัติศาสตร์ไม่มีผลต่อผลลัพธ์ 'ต่อเนื่อง' ในคำว่า CBOW หมายถึงการใช้ "การแสดงบริบทแบบกระจายอย่างต่อเนื่อง"
ข้ามกรัมเป็นสิ่งที่ตรงกันข้ามของ CBOW ให้คำหนึ่งคำ มันจะทำนายคำรอบข้างภายในช่วงที่กำหนด ช่วงที่กว้างกว่าจะทำให้เวกเตอร์คำมีคุณภาพดีขึ้น แต่เพิ่มความซับซ้อนในการคำนวณ ให้น้ำหนักน้อยกว่าสำหรับคำที่อยู่ห่างไกลเนื่องจากมักมีความเกี่ยวข้องน้อยกว่ากับคำปัจจุบัน
ในการเปรียบเทียบ CBOW กับ Skip-gram พบว่าแบบหลังให้ผลลัพธ์ที่มีคุณภาพดีกว่าในชุดข้อมูลขนาดใหญ่ แม้ว่า CBOW จะเร็วกว่า แต่ Skip-gram จะจัดการกับคำที่ใช้ไม่บ่อยได้ดีกว่า
ระหว่างการฝึก เวกเตอร์ถูกกำหนดให้กับแต่ละคำ องค์ประกอบของเวกเตอร์นั้นได้รับการปรับเพื่อให้คำที่คล้ายกัน (ตามบริบทของคำเหล่านั้น) อยู่ใกล้กันมากขึ้น คิดว่านี่เป็นการชักเย่อ ซึ่งคำต่างๆ ถูกผลักและดึงไปมาในเวกเตอร์หลายมิตินี้ทุกครั้งที่มีการเพิ่มคำศัพท์อื่นลงในช่องว่าง
การดำเนินการทางคณิตศาสตร์นอกเหนือจากความคล้ายคลึงของโคไซน์สามารถดำเนินการกับเวกเตอร์คำได้ ตัวอย่างเช่น vector(”King”) – vector(”Man”) + vector(”Woman”) ส่งผลให้เวกเตอร์ที่ใกล้เคียงที่สุดกับคำที่แสดงถึงคำว่า Queen
Word2Vec สำหรับการสร้างแบบจำลองหัวข้อ
คำศัพท์ที่สร้างโดย Word2Vec สามารถสอบถามโดยตรงเพื่อตรวจหาความสัมพันธ์ระหว่างคำหรือป้อนลงในโครงข่ายประสาทเทียมที่มีการเรียนรู้อย่างลึกซึ้ง ปัญหาหนึ่งของอัลกอริธึม Word2Vec เช่น CBOW และ Skip-gram คือให้น้ำหนักแต่ละคำเท่ากัน ปัญหาที่เกิดขึ้นเมื่อทำงานกับเอกสารคือคำต่างๆ ไม่ได้แสดงถึงความหมายของประโยคอย่างเท่าเทียมกัน

คำบางคำมีความสำคัญมากกว่าคำอื่นๆ ดังนั้น กลยุทธ์การถ่วงน้ำหนักที่แตกต่างกัน เช่น TF-IDF จึงมักถูกนำมาใช้เพื่อจัดการกับสถานการณ์ นอกจากนี้ยังช่วยแก้ไขปัญหาความฮับที่กล่าวถึงในหัวข้อถัดไป Searchmetrics ContentExperience ใช้การผสมผสานระหว่าง TF-IDF และ Word2Vec ซึ่งคุณสามารถอ่านได้ที่นี่ในการเปรียบเทียบกับ MarketMuse
ในขณะที่การฝังคำ เช่น Word2Vec จะเก็บข้อมูลทางสัณฐานวิทยา ความหมาย และวากยสัมพันธ์ การสร้างแบบจำลองหัวข้อมุ่งหวังที่จะค้นพบโครงสร้างความหมายแฝงหรือหัวข้อในคลังข้อมูล
ตาม Budhkar และ Rudzicz (PDF) การรวม Dirichlet allocation (LDA) ที่แฝงไว้กับ Word2Vec สามารถสร้างคุณลักษณะที่เลือกปฏิบัติเพื่อ "จัดการกับปัญหาที่เกิดจากการไม่มีข้อมูลเชิงบริบทที่ฝังอยู่ในโมเดลเหล่านี้" อ่าน LDA2vec ได้ง่ายขึ้นในบทช่วยสอน DataCamp นี้
ความท้าทายของ Word2Vec
มีปัญหาหลายประการเกี่ยวกับการฝังคำโดยทั่วไป รวมถึง Word2Vec เราจะพูดถึงสิ่งเหล่านี้บางส่วน เพื่อการวิเคราะห์ที่ละเอียดยิ่งขึ้น โปรดดู 'การสำรวจวิธีการประเมินการฝังคำ' (pdf) โดย Amir Bakarov คลังข้อมูลและขนาดของคลังข้อมูล ตลอดจนการฝึกอบรมจะส่งผลต่อคุณภาพผลงานอย่างมาก
คุณประเมินผลลัพธ์อย่างไร
ตามที่ Bakarov อธิบายไว้ในบทความของเขา วิศวกร NLP จะประเมินประสิทธิภาพของการฝังที่แตกต่างจากนักภาษาศาสตร์เชิงคอมพิวเตอร์ หรือนักการตลาดเนื้อหาสำหรับเรื่องนั้น ต่อไปนี้คือประเด็นเพิ่มเติมที่อ้างถึงในบทความ
- ความหมายเป็นแนวคิดที่คลุมเครือ การฝังคำที่ "ดี" สะท้อนถึงแนวคิดเรื่องความหมายของเรา อย่างไรก็ตาม เราอาจไม่ทราบว่าความเข้าใจของเราถูกต้องหรือไม่ นอกจากนี้ คำยังมีความสัมพันธ์ประเภทต่างๆ เช่น ความเกี่ยวข้องทางความหมายและความคล้ายคลึงกันของความหมาย คำว่า embedding ควรสะท้อนถึงความสัมพันธ์แบบใด?
- ขาดข้อมูลการฝึกอบรมที่เหมาะสม เมื่อฝึกการฝังคำ นักวิจัยมักจะเพิ่มคุณภาพด้วยการปรับให้เข้ากับข้อมูล นี่คือสิ่งที่เราเรียกว่าการปรับให้เข้าโค้ง แทนที่จะทำให้ผลลัพธ์เหมาะสมกับข้อมูล นักวิจัยควรพยายามจับความสัมพันธ์ระหว่างคำต่างๆ
- การไม่มีความสัมพันธ์กันระหว่างวิธีการภายในและภายนอกหมายความว่ายังไม่ชัดเจนว่าต้องการใช้วิธีใด การประเมินภายนอกจะกำหนดคุณภาพผลลัพธ์สำหรับการใช้งานดาวน์สตรีมเพิ่มเติมในงานประมวลผลภาษาธรรมชาติอื่นๆ การประเมินที่แท้จริงอาศัยการตัดสินของมนุษย์เกี่ยวกับความสัมพันธ์ของคำ
- ปัญหาความผัว. ฮับ ซึ่งเป็นเวกเตอร์คำที่เป็นตัวแทนของคำทั่วไป อยู่ใกล้กับเวกเตอร์คำอื่นๆ จำนวนมากเกินไป เสียงรบกวนนี้อาจทำให้การประเมินมีอคติ
นอกจากนี้ยังมีความท้าทายที่สำคัญสองประการกับ Word2Vec โดยเฉพาะ
- ไม่สามารถจัดการกับความคลุมเครือได้เป็นอย่างดี เป็นผลให้เวกเตอร์ของคำที่มีความหมายหลายอย่างสะท้อนถึงค่าเฉลี่ยซึ่งอยู่ไกลจากอุดมคติ
- Word2Vec ไม่สามารถจัดการคำที่ไม่อยู่ในคำศัพท์ (OOV) และคำที่คล้ายกันทางสัณฐานวิทยาได้ เมื่อแบบจำลองพบแนวคิดใหม่ แบบจำลองจะใช้เวกเตอร์แบบสุ่มซึ่งไม่ใช่การแสดงที่ถูกต้อง
สรุป
การใช้ Word2Vec หรือการฝังคำอื่นๆ ไม่รับประกันความสำเร็จ ผลลัพธ์ที่มีคุณภาพได้รับการระบุในการฝึกอบรมที่เหมาะสมโดยใช้คลังข้อมูลที่เหมาะสมและมีขนาดใหญ่เพียงพอ
แม้ว่าการประเมินคุณภาพของผลลัพธ์จะค่อนข้างยุ่งยาก แต่นี่เป็นวิธีแก้ปัญหาง่ายๆ สำหรับนักการตลาดเนื้อหา ครั้งต่อไปที่คุณประเมินเครื่องมือเพิ่มประสิทธิภาพเนื้อหา ลองใช้หัวข้อที่เฉพาะเจาะจงมาก โมเดลหัวข้อคุณภาพต่ำล้มเหลวเมื่อต้องการทดสอบในลักษณะนี้ ใช้ได้สำหรับข้อกำหนดทั่วไป แต่จะแยกย่อยเมื่อคำขอมีความเฉพาะเจาะจงเกินไป
ดังนั้น หากคุณใช้หัวข้อ 'วิธีปลูกอะโวคาโด' ให้ตรวจสอบให้แน่ใจว่าคำแนะนำนั้นเกี่ยวข้องกับการปลูกพืช ไม่ใช่อะโวคาโดโดยทั่วไป
การสร้างภาษาธรรมชาติของ MarketMuse NLG Technology ช่วยสร้างบทความนี้
สิ่งที่ควรทำตอนนี้
เมื่อคุณพร้อม... นี่คือ 3 วิธีที่เราสามารถช่วยคุณเผยแพร่เนื้อหาที่ดีขึ้น เร็วขึ้น:
- จองเวลากับ MarketMuse กำหนดเวลาการสาธิตสดกับหนึ่งในนักวางกลยุทธ์ของเรา เพื่อดูว่า MarketMuse สามารถช่วยให้ทีมของคุณบรรลุเป้าหมายด้านเนื้อหาได้อย่างไร
- หากคุณต้องการเรียนรู้วิธีสร้างเนื้อหาที่ดีขึ้นเร็วขึ้น โปรดไปที่บล็อกของเรา เต็มไปด้วยทรัพยากรที่จะช่วยปรับขนาดเนื้อหา
- หากคุณรู้จักนักการตลาดรายอื่นที่ชื่นชอบการอ่านหน้านี้ ให้แบ่งปันกับพวกเขาผ่านอีเมล, LinkedIn, Twitter หรือ Facebook