
งบประมาณการรวบรวมข้อมูลคืออะไรและจะเพิ่มประสิทธิภาพได้อย่างไรอย่างชาญฉลาด
เผยแพร่แล้ว: 2021-08-19สารบัญ
การวิเคราะห์งบประมาณการรวบรวมข้อมูลเป็นหน้าที่หนึ่งของผู้เชี่ยวชาญด้าน SEO (โดยเฉพาะหากพวกเขากำลังติดต่อกับเว็บไซต์ขนาดใหญ่) งานที่สำคัญครอบคลุมอย่างเหมาะสมในเอกสารที่ Google จัดหาให้ อย่างที่คุณเห็นบน Twitter แม้แต่พนักงานของ Google ก็ลดบทบาทการรวบรวมข้อมูลงบประมาณในการรับการเข้าชมและการจัดอันดับที่ดีขึ้น:
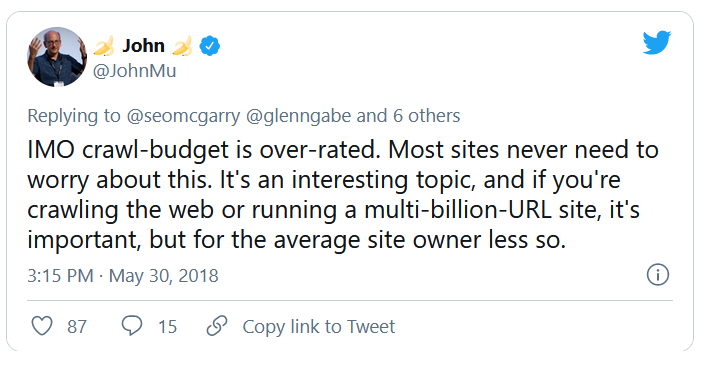

พวกเขาพูดถูกเกี่ยวกับเรื่องนี้หรือไม่?
Google ทำงานและรวบรวมข้อมูลอย่างไร
เมื่อเราขยายความในหัวข้อนี้ ให้ระลึกว่าเครื่องมือค้นหารวบรวม จัดทำดัชนี และจัดระเบียบข้อมูลอย่างไร การรักษาสามขั้นตอนเหล่านี้ไว้ในมุมของจิตใจเป็นสิ่งสำคัญในระหว่างที่คุณทำงานบนเว็บไซต์ในภายหลัง:
ขั้นตอนที่ 1: การรวบรวมข้อมูล การค้นหาแหล่งข้อมูลออนไลน์โดยมีวัตถุประสงค์เพื่อค้นหาและสำรวจลิงก์ ไฟล์ และข้อมูลที่มีอยู่ทั้งหมด โดยทั่วไป Google จะเริ่มต้นด้วยสถานที่ยอดนิยมบนเว็บ จากนั้นจึงดำเนินการค้นหาแหล่งข้อมูลอื่นๆ ที่มีแนวโน้มน้อยกว่า
ขั้นตอนที่ 2: การจัดทำดัชนี Google พยายามกำหนดว่าหน้านั้นเกี่ยวกับอะไร และเนื้อหา / เอกสารที่อยู่ภายใต้การวิเคราะห์นั้นเป็นเนื้อหาที่ไม่ซ้ำหรือซ้ำกันหรือไม่ ในขั้นตอนนี้ Google จะจัดกลุ่มเนื้อหาและจัดลำดับความสำคัญ (โดยอ่านคำแนะนำในแท็ก rel=”canonical” หรือ rel=”alternate” หรืออย่างอื่น)
ขั้นตอนที่ 3: การให้บริการ เมื่อแบ่งกลุ่มและจัดทำดัชนีแล้ว ข้อมูลจะแสดงตามคำค้นหาของผู้ใช้ นอกจากนี้ยังเป็นกรณีที่ Google จัดเรียงข้อมูลตามความเหมาะสม โดยพิจารณาจากปัจจัยต่างๆ เช่น ตำแหน่งของผู้ใช้
สำคัญ: สื่อที่มีจำนวนมากมองข้ามขั้นตอนที่ 4: การแสดงเนื้อหา โดยค่าเริ่มต้น Googlebot จะจัดทำดัชนีเนื้อหาข้อความ อย่างไรก็ตาม ในขณะที่เทคโนโลยีเว็บยังคงพัฒนาต่อไป Google จึงต้องคิดค้นโซลูชันใหม่ๆ เพื่อหยุดเพียงแค่ "อ่าน" และเริ่ม "มองเห็น" เช่นกัน นั่นคือสิ่งที่การแสดงผลเป็นเรื่องเกี่ยวกับ มันให้บริการ Google ในการปรับปรุงการเข้าถึงอย่างมากในหมู่เว็บไซต์ที่เพิ่งเปิดตัวใหม่และขยายดัชนี
หมายเหตุ : ปัญหาเกี่ยวกับการแสดงเนื้อหาอาจเป็นสาเหตุของงบประมาณการรวบรวมข้อมูลที่ล้มเหลว
งบประมาณการรวบรวมข้อมูลคืออะไร?
งบประมาณการรวบรวมข้อมูลเป็นเพียงความถี่ที่โปรแกรมรวบรวมข้อมูลและบอทของเครื่องมือค้นหาสามารถจัดทำดัชนีเว็บไซต์ของคุณได้ เช่นเดียวกับจำนวน URL ทั้งหมดที่สามารถเข้าถึงได้ในการรวบรวมข้อมูลครั้งเดียว ลองนึกภาพงบประมาณการรวบรวมข้อมูลของคุณเป็นเครดิตที่คุณสามารถใช้ในบริการหรือแอป หากคุณไม่ลืมที่จะ "เรียกเก็บ" งบประมาณการรวบรวมข้อมูลของคุณ หุ่นยนต์จะช้าลงและจ่ายการเข้าชมน้อยลง
ใน SEO "การชาร์จ" หมายถึงงานที่ได้รับลิงก์ย้อนกลับหรือปรับปรุงความนิยมโดยรวมของเว็บไซต์ ดังนั้น งบประมาณการรวบรวมข้อมูลจึงเป็นส่วนสำคัญของระบบนิเวศทั้งหมดของเว็บ เมื่อคุณทำงานได้ดีกับเนื้อหาและลิงก์ย้อนกลับ คุณกำลังเพิ่มขีดจำกัดงบประมาณการรวบรวมข้อมูลที่มีอยู่ของคุณ
ในแหล่งข้อมูล Google ไม่มีความเสี่ยงในการกำหนดงบประมาณการรวบรวมข้อมูลอย่างชัดเจน แต่จะชี้ไปที่องค์ประกอบพื้นฐานสองประการของการรวบรวมข้อมูลซึ่งส่งผลต่อความละเอียดถี่ถ้วนของ Googlebot และความถี่ในการเข้าชม:
- ขีด จำกัด อัตราการรวบรวมข้อมูล;
- ความต้องการรวบรวมข้อมูล
ขีดจำกัดอัตราการรวบรวมข้อมูลคืออะไรและจะตรวจสอบได้อย่างไร
กล่าวอย่างง่ายที่สุด ขีดจำกัดอัตราการรวบรวมข้อมูลคือจำนวนการเชื่อมต่อพร้อมกันที่ Googlebot สามารถสร้างได้เมื่อรวบรวมข้อมูลไซต์ของคุณ เนื่องจาก Google ไม่ต้องการทำร้ายประสบการณ์ของผู้ใช้ จึงจำกัดจำนวนการเชื่อมต่อเพื่อให้เว็บไซต์/เซิร์ฟเวอร์ของคุณทำงานได้อย่างราบรื่น โดยสังเขป ยิ่งเว็บไซต์ของคุณช้า ขีดจำกัดอัตราการรวบรวมข้อมูลของคุณก็จะยิ่งน้อยลง
สำคัญ: ขีดจำกัดการรวบรวมข้อมูลยังขึ้นอยู่กับความสมบูรณ์ของ SEO โดยรวมของเว็บไซต์ของคุณด้วย หากเว็บไซต์ของคุณทำให้เกิดการเปลี่ยนเส้นทางหลายครั้ง ข้อผิดพลาด 404/410 หรือหากเซิร์ฟเวอร์ส่งคืนรหัสสถานะ 500 บ่อยครั้ง จำนวนการเชื่อมต่อก็จะลดลงเช่นกัน
คุณสามารถวิเคราะห์ข้อมูลขีดจำกัดอัตราการรวบรวมข้อมูลด้วยข้อมูลที่มีอยู่ใน Google Search Console ใน รายงานสถิติการรวบรวมข้อมูล
ความต้องการรวบรวมข้อมูลหรือความนิยมของเว็บไซต์
แม้ว่าขีดจำกัดอัตราการรวบรวมข้อมูลจะทำให้คุณต้องขัดเกลารายละเอียดทางเทคนิคของเว็บไซต์ของคุณ ความต้องการรวบรวมข้อมูลจะตอบแทนคุณสำหรับความนิยมของเว็บไซต์ของคุณ พูดโดยคร่าวว่ายิ่งมีการฉวัดเฉวียนในเว็บไซต์ของคุณมากขึ้น (และในนั้น) ความต้องการในการรวบรวมข้อมูลก็จะมากขึ้นเท่านั้น
ในกรณีนี้ Google จะตรวจสอบสองประเด็น:
- ความนิยมโดยรวม – Google กระตือรือร้นที่จะเรียกใช้การรวบรวมข้อมูล URL บ่อยๆ ซึ่งโดยทั่วไปแล้วเป็นที่นิยมบนอินเทอร์เน็ต (ไม่จำเป็นต้องเป็น URL ที่มีลิงก์ย้อนกลับจาก URL จำนวนมากที่สุด)
- ความสดใหม่ของข้อมูลดัชนี – Google มุ่งมั่นที่จะนำเสนอเฉพาะข้อมูลล่าสุดเท่านั้น สำคัญ: การสร้างเนื้อหาใหม่มากขึ้นเรื่อยๆ ไม่ได้หมายความว่าขีดจำกัดงบประมาณการตระเวนโดยรวมของคุณจะเพิ่มขึ้น
ปัจจัยที่มีผลต่องบประมาณการรวบรวมข้อมูล
ในส่วนก่อนหน้านี้ เราได้กำหนดงบประมาณการตระเวนเป็นการรวมกันของขีดจำกัดอัตราการตระเวนและความต้องการในการตระเวน จำไว้ว่าคุณต้องดูแลทั้งสองอย่างพร้อมกัน เพื่อให้แน่ใจว่ามีการรวบรวมข้อมูล (และจัดทำดัชนี) เว็บไซต์ของคุณอย่างเหมาะสม
ด้านล่างนี้ คุณจะพบรายการประเด็นง่ายๆ ที่ควรพิจารณาในระหว่างการรวบรวมข้อมูลงบประมาณที่เหมาะสมที่สุด
- เซิร์ฟเวอร์ – ปัญหาหลักคือประสิทธิภาพ ยิ่งความเร็วของคุณต่ำ ความเสี่ยงที่ Google จะมอบหมายทรัพยากรให้น้อยลงในการจัดทำดัชนีเนื้อหาใหม่ของคุณก็จะสูงขึ้น
- รหัสการตอบกลับของเซิร์ฟเวอร์ – ยิ่งจำนวนการเปลี่ยนเส้นทาง 301 301 ครั้งและข้อผิดพลาด 404/410 ผิดพลาดบนเว็บไซต์ของคุณมากเท่าใด ผลลัพธ์การจัดทำดัชนีก็จะยิ่งแย่ลง สำคัญ: ระวังการวนรอบการเปลี่ยนเส้นทาง – ทุกๆ “การกระโดด” จะลดขีดจำกัดอัตราการรวบรวมข้อมูลของเว็บไซต์ของคุณสำหรับการเยี่ยมชมบ็อตครั้งต่อไป
- บล็อกใน robots.txt – หากคุณใช้คำสั่งของ robots.txt ตามความรู้สึกของลำไส้ คุณอาจสร้างปัญหาคอขวดในการจัดทำดัชนี ผลที่สุด: คุณจะล้างดัชนี แต่เสียประสิทธิภาพในการจัดทำดัชนีสำหรับหน้าใหม่ (เมื่อ URL ที่ถูกบล็อกถูกฝังอย่างแน่นหนาภายในโครงสร้างของเว็บไซต์ทั้งหมด)
- การนำทางแบบแยกส่วน / ตัวระบุเซสชัน / พารามิเตอร์ใด ๆ ใน URL – ที่สำคัญที่สุด ให้ระวังสถานการณ์ที่ที่อยู่ที่มีพารามิเตอร์ตัวเดียวอาจถูกสร้างพารามิเตอร์เพิ่มเติม โดยไม่มีข้อจำกัด หากสิ่งนี้ควรเกิดขึ้น Google จะเข้าถึงที่อยู่จำนวนไม่ จำกัด โดยใช้ทรัพยากรที่มีอยู่ทั้งหมดในส่วนที่มีความสำคัญน้อยกว่าของเว็บไซต์ของเรา
- เนื้อหาที่ซ้ำกัน – เนื้อหาที่ คัดลอกมา (นอกเหนือจากการกินเนื้อคน) ส่งผลเสียอย่างมากต่อประสิทธิภาพของการสร้างดัชนีเนื้อหาใหม่
- เนื้อหาบาง - ซึ่งเกิดขึ้นเมื่อหน้ามีอัตราส่วนข้อความต่อ HTML ต่ำมาก ด้วยเหตุนี้ Google อาจระบุหน้าเว็บว่าเรียกว่า Soft 404 และจำกัดการจัดทำดัชนีเนื้อหา (แม้ว่าเนื้อหาจะมีความหมาย ซึ่งอาจเป็นเช่นนั้น เช่น ในหน้าของผู้ผลิตที่นำเสนอผลิตภัณฑ์เดียวและไม่ได้มีลักษณะเฉพาะ เนื้อหาข้อความ)
- การเชื่อมโยงภายในไม่ดีหรือขาดมัน
เครื่องมือที่มีประโยชน์สำหรับการวิเคราะห์งบประมาณการรวบรวมข้อมูล
เนื่องจากไม่มีเกณฑ์เปรียบเทียบสำหรับงบประมาณการรวบรวมข้อมูล (ซึ่งหมายความว่าเป็นการยากที่จะเปรียบเทียบขีดจำกัดระหว่างเว็บไซต์ต่างๆ) ให้เตรียมชุดเครื่องมือที่ออกแบบมาเพื่ออำนวยความสะดวกในการเก็บรวบรวมและวิเคราะห์ข้อมูล
Google Search Console
GSC เติบโตขึ้นอย่างสวยงามในช่วงหลายปีที่ผ่านมา ในระหว่างการวิเคราะห์งบประมาณการรวบรวมข้อมูล มีรายงานหลักสองฉบับที่เราควรตรวจสอบ: การครอบคลุมของดัชนี และ สถิติการรวบรวมข้อมูล
ความครอบคลุมของดัชนีใน GSC
รายงานเป็นแหล่งข้อมูลขนาดใหญ่ มาตรวจสอบข้อมูลใน URL ที่ไม่รวมอยู่ในการจัดทำดัชนีกัน เป็นวิธีที่ดีในการทำความเข้าใจขนาดของปัญหาที่คุณกำลังเผชิญ
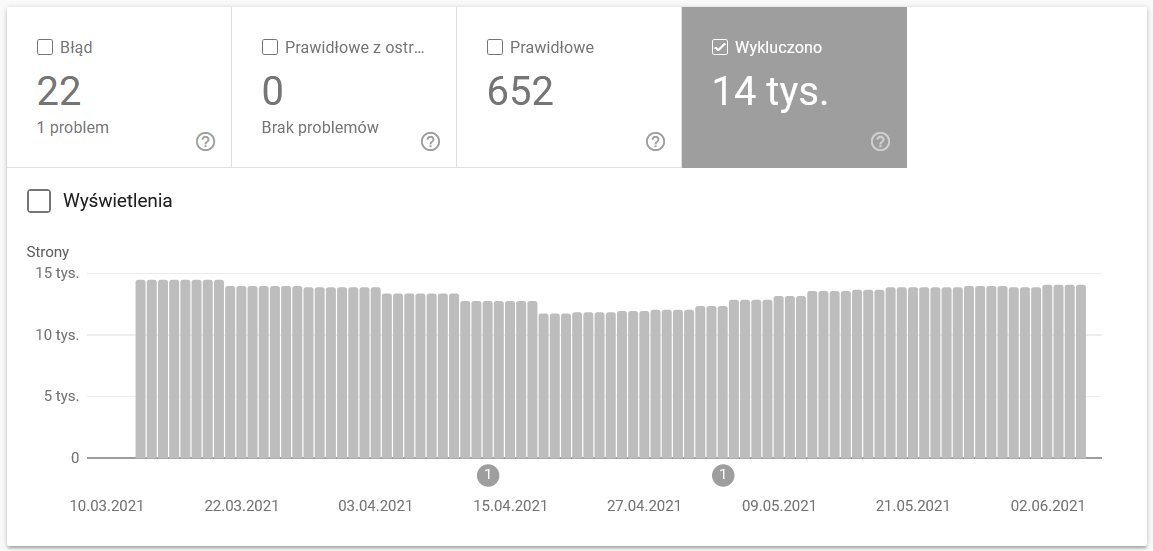
รายงานทั้งหมดรับประกันบทความแยกต่างหาก ดังนั้นสำหรับตอนนี้ เรามาเน้นที่ข้อมูลต่อไปนี้:
- ยกเว้นโดยแท็ก 'noindex' – โดยทั่วไป หน้า noindex ที่มากขึ้นหมายถึงการเข้าชมที่น้อยลง ซึ่งทำให้เกิดคำถาม – อะไรคือจุดประสงค์ของการรักษาพวกเขาไว้บนเว็บไซต์? จะจำกัดการเข้าถึงเพจเหล่านี้ได้อย่างไร?
- รวบรวมข้อมูลแล้ว – ยังไม่ได้จัดทำดัชนี หากคุณเห็น ให้ตรวจสอบว่าเนื้อหาแสดงผลอย่างถูกต้องในสายตาของ Googlebot หรือไม่ โปรดจำไว้ว่าทุก URL ที่มีสถานะนั้นทำให้เสียงบประมาณการรวบรวมข้อมูลของคุณเนื่องจากไม่สร้างการเข้าชมที่เกิดขึ้นเอง
- ค้นพบ - ไม่ได้จัดทำดัชนี - หนึ่งในปัญหาที่น่าตกใจที่ควรค่าแก่การวางไว้ที่ด้านบนสุดของรายการลำดับความสำคัญของคุณ
- ทำซ้ำโดยไม่เลือกตามรูปแบบบัญญัติที่ผู้ใช้เลือก – หน้าที่ซ้ำกันทั้งหมดเป็นอันตรายอย่างยิ่ง เนื่องจากไม่เพียงแต่ส่งผลเสียต่องบประมาณการรวบรวมข้อมูลของคุณ แต่ยังเพิ่มความเสี่ยงของการกินเนื้อคนด้วย
- ซ้ำกัน Google เลือก Canonical ที่แตกต่างจากผู้ใช้ ในทางทฤษฎี ไม่จำเป็นต้องเป็นกังวล ท้ายที่สุด Google ควรจะฉลาดพอที่จะทำการตัดสินใจที่ถูกต้องแทนเรา อันที่จริงแล้ว Google เลือก Canonicals ค่อนข้างสุ่ม ซึ่งมักจะตัดหน้าที่มีค่าออกไปด้วย Canonical ที่ ชี้ไปที่หน้าแรก
- Soft 404 – ข้อผิดพลาด "soft" ทั้งหมดมีอันตรายสูง เนื่องจากอาจนำไปสู่การลบหน้าที่สำคัญออกจากดัชนี
- URL ที่ส่งซ้ำและไม่ได้เลือกเป็น URL ตามรูปแบบบัญญัติ – คล้ายกับการรายงานสถานะเมื่อไม่มีรูปแบบบัญญัติที่ผู้ใช้เลือก
สถิติการรวบรวมข้อมูล
รายงานไม่สมบูรณ์แบบ และเท่าที่ข้อเสนอแนะ ผมขอแนะนำอย่างยิ่งให้เล่นกับบันทึกเซิร์ฟเวอร์เก่าที่ดี ซึ่งให้ข้อมูลเชิงลึกที่ลึกซึ้งยิ่งขึ้นในข้อมูล (และตัวเลือกการสร้างแบบจำลองเพิ่มเติม)
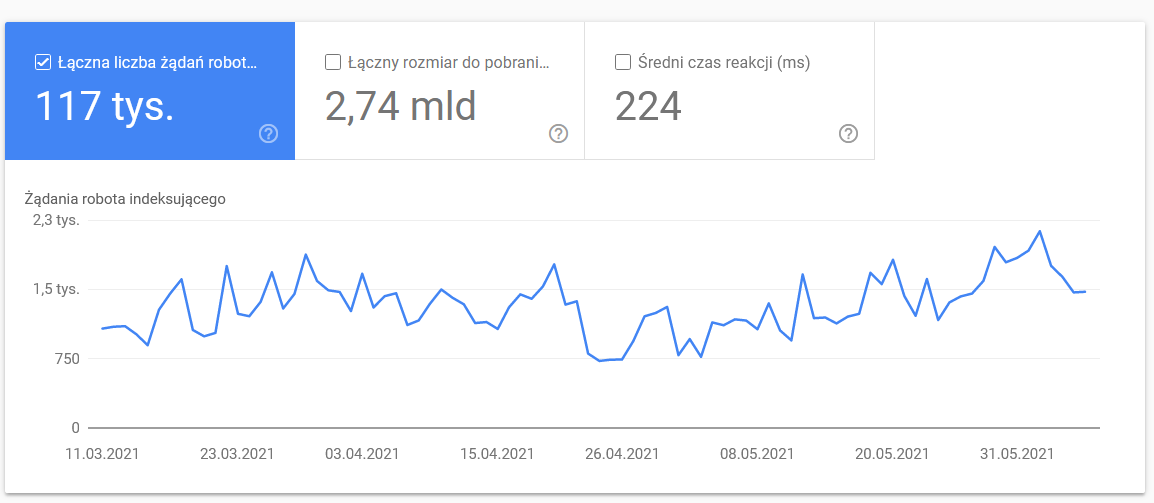
ดังที่ฉันได้กล่าวไปแล้ว คุณจะมีช่วงเวลาที่ยากลำบากในการค้นหาเกณฑ์เปรียบเทียบสำหรับตัวเลขด้านบน อย่างไรก็ตาม ควรพิจารณาให้ดียิ่งขึ้น:
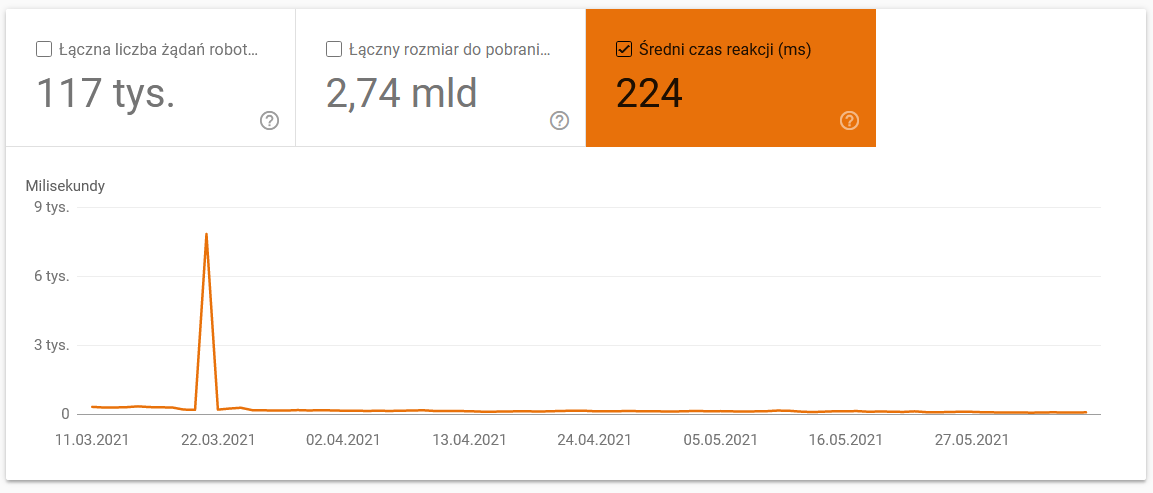
- เวลาในการดาวน์โหลดเฉลี่ย ภาพหน้าจอด้านล่างแสดงให้เห็นว่าเวลาตอบสนองโดยเฉลี่ยได้รับความนิยมอย่างมาก ซึ่งเกิดจากปัญหาที่เกี่ยวข้องกับเซิร์ฟเวอร์:
- รวบรวมข้อมูลตอบกลับ ดูรายงานโดยทั่วไป ว่าคุณมีปัญหากับเว็บไซต์ของคุณหรือไม่ ให้ความสนใจอย่างใกล้ชิดกับรหัสสถานะเซิร์ฟเวอร์ที่ผิดปกติ เช่น 304s ด้านล่าง URL เหล่านี้ไม่มีจุดประสงค์ในการใช้งาน แต่ Google ก็เปลืองทรัพยากรในการรวบรวมข้อมูลผ่านเนื้อหา

- วัตถุประสงค์ในการรวบรวมข้อมูล โดยทั่วไป ข้อมูลเหล่านี้ส่วนใหญ่ขึ้นอยู่กับปริมาณเนื้อหาใหม่บนเว็บไซต์ ความแตกต่างระหว่างข้อมูลที่รวบรวมโดย Google และผู้ใช้นั้นค่อนข้างน่าสนใจ:
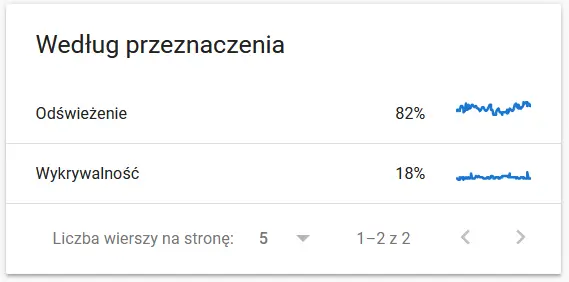
เนื้อหาของ URL ที่รวบรวมข้อมูลซ้ำในสายตาของ Google:
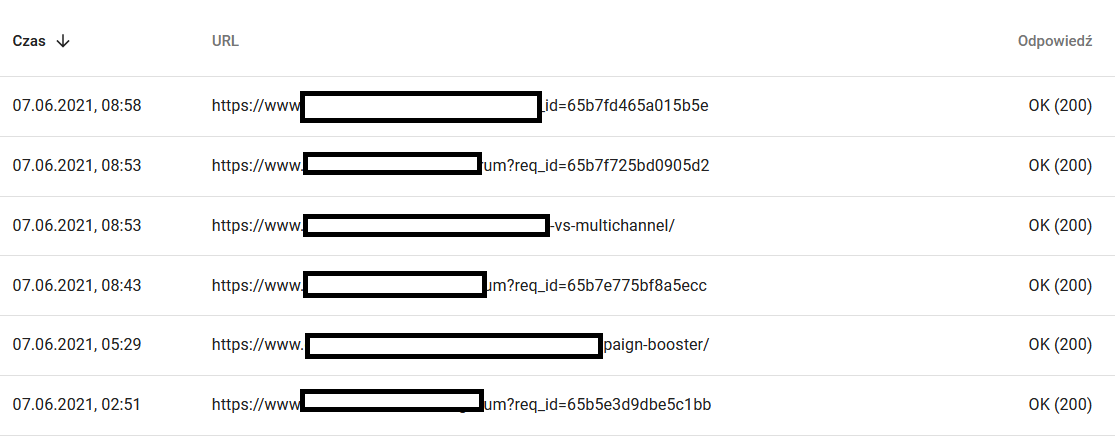
ในขณะเดียวกัน นี่คือสิ่งที่ผู้ใช้เห็นในเบราว์เซอร์:
เป็นเหตุให้ต้องคิดและวิเคราะห์อย่างแน่นอน :)
- ประเภท Googlebot ที่นี่คุณมีบ็อตที่เข้าชมเว็บไซต์ของคุณบนถาดเงิน พร้อมด้วยแรงจูงใจในการแยกวิเคราะห์เนื้อหาของคุณ ภาพหน้าจอด้านล่างแสดงให้เห็นว่า 22% ของคำขออ้างถึงการโหลดทรัพยากรของหน้า
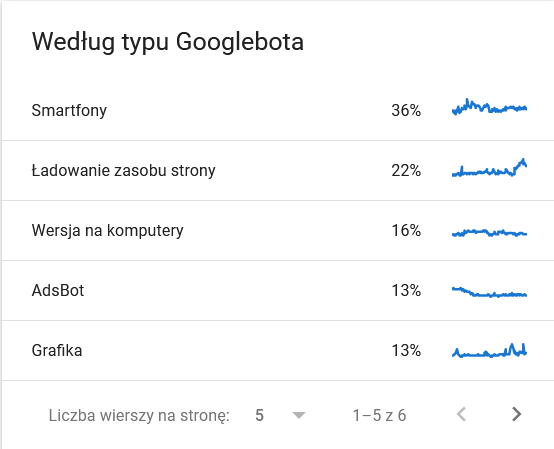
ยอดรวมที่พุ่งขึ้นในวันสุดท้ายของกรอบเวลา:
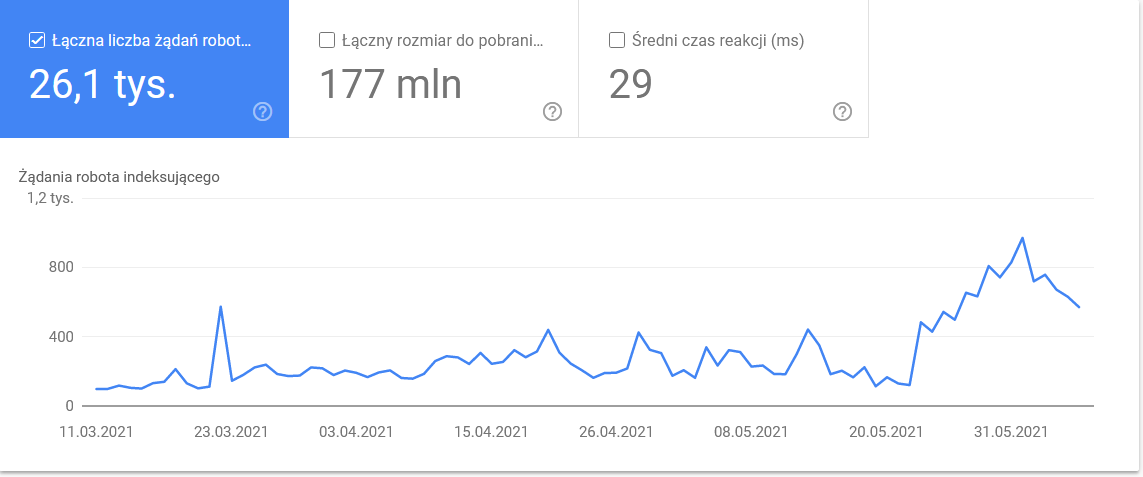
การดูรายละเอียดจะเปิดเผย URL ที่ต้องการการดูแลอย่างใกล้ชิด:
โปรแกรมรวบรวมข้อมูลภายนอก (พร้อมตัวอย่างจาก Screaming Frog SEO Spider)
โปรแกรมรวบรวมข้อมูลเป็นเครื่องมือที่สำคัญที่สุดในการวิเคราะห์งบประมาณการรวบรวมข้อมูลของเว็บไซต์ของคุณ จุดประสงค์หลักของพวกเขาคือการเลียนแบบการเคลื่อนไหวของบอทที่รวบรวมข้อมูลบนเว็บไซต์ การจำลองจะแสดงให้คุณเห็นได้อย่างรวดเร็วว่าทุกอย่างดำเนินไปอย่างราบรื่นหรือไม่
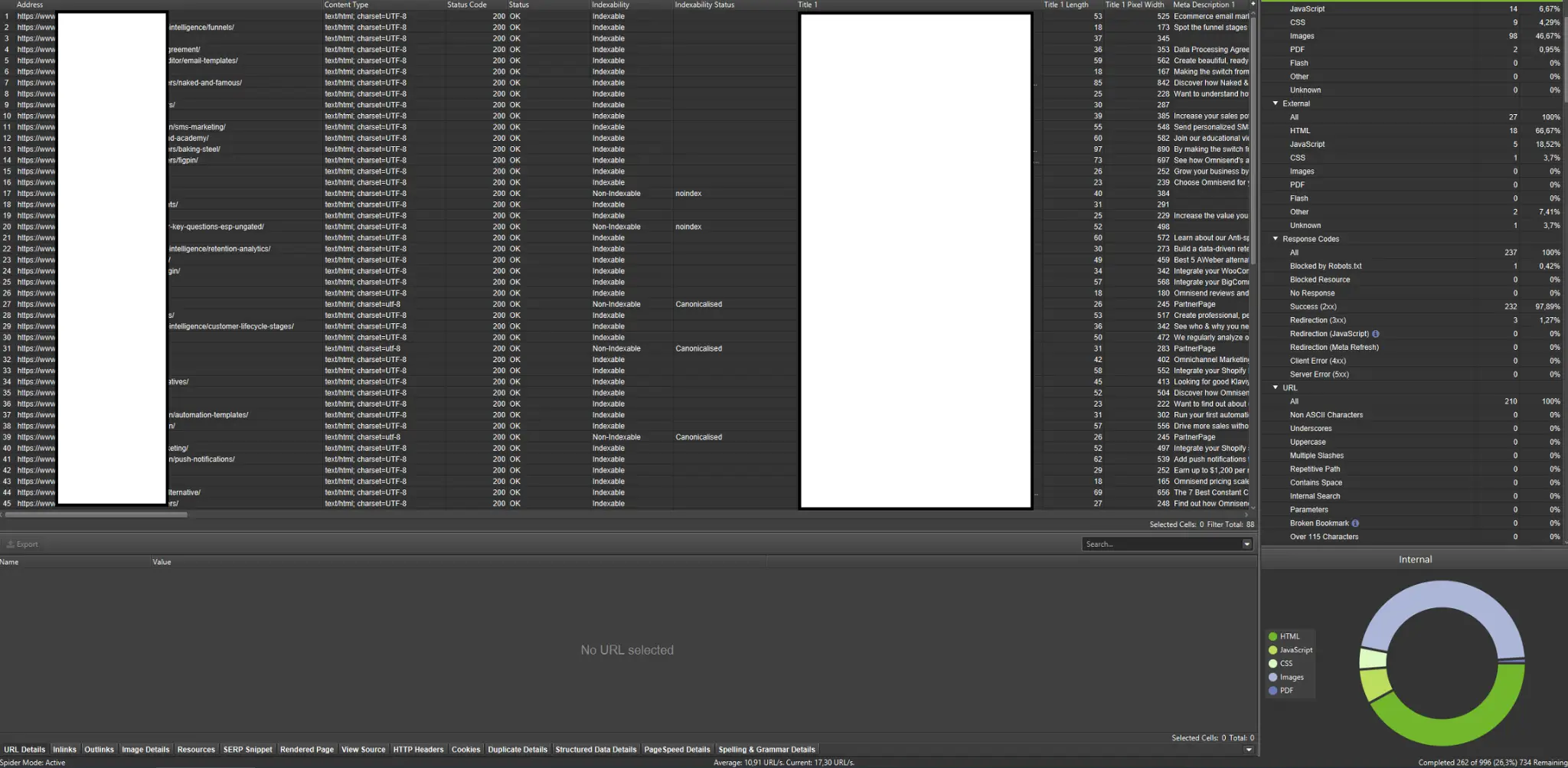
หากคุณเป็นผู้เรียนด้วยภาพ คุณควรรู้ว่าโซลูชันส่วนใหญ่ที่มีอยู่ในตลาดนำเสนอการแสดงข้อมูลเป็นภาพ
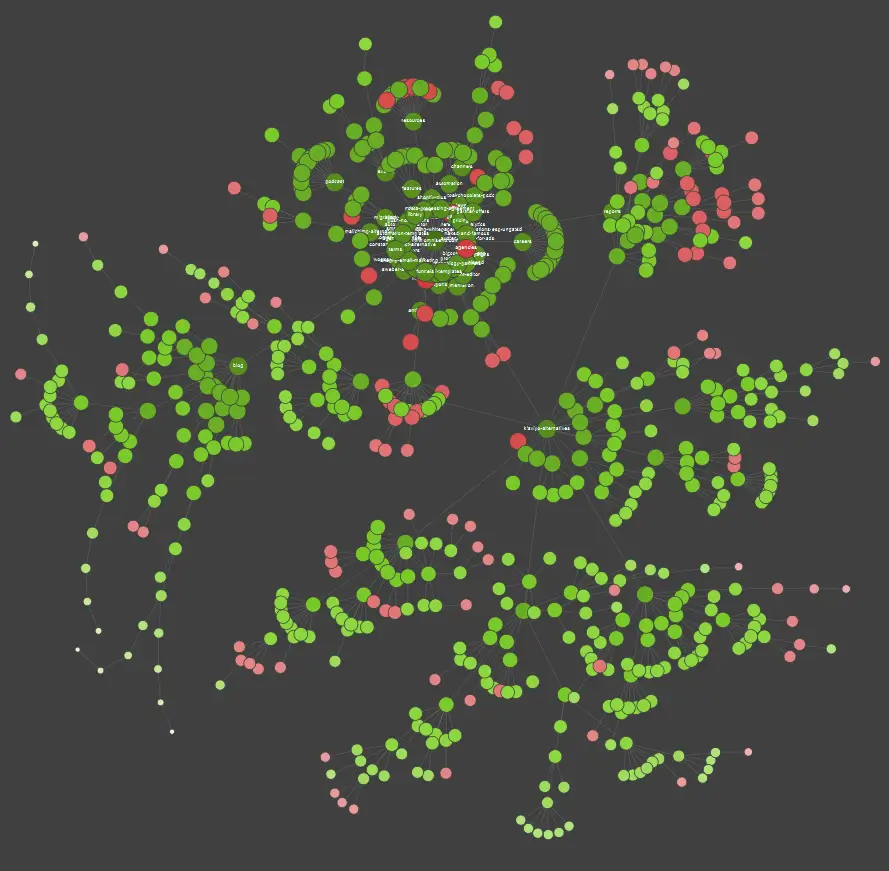
ในตัวอย่างข้างต้น จุดสีแดงหมายถึงหน้าที่ไม่ได้จัดทำดัชนี ใช้เวลาสักครู่เพื่อพิจารณาถึงประโยชน์และผลกระทบต่อการทำงานของเว็บไซต์ หากบันทึกของเซิร์ฟเวอร์เผยให้เห็นว่าหน้าเหล่านี้เสียเวลามากของ Google โดยที่ไม่ได้เพิ่มคุณค่าใดๆ เลย ถึงเวลาที่ต้องทบทวนจุดที่ต้องเก็บไว้บนเว็บไซต์อย่างจริงจัง

สำคัญ : หากเราต้องการสร้างพฤติกรรมของ Googlebot ขึ้นมาใหม่อย่างแม่นยำที่สุด จำเป็นต้องมีการตั้งค่าที่เหมาะสม คุณสามารถดูตัวอย่างการตั้งค่าจากคอมพิวเตอร์ของฉันได้ที่นี่:
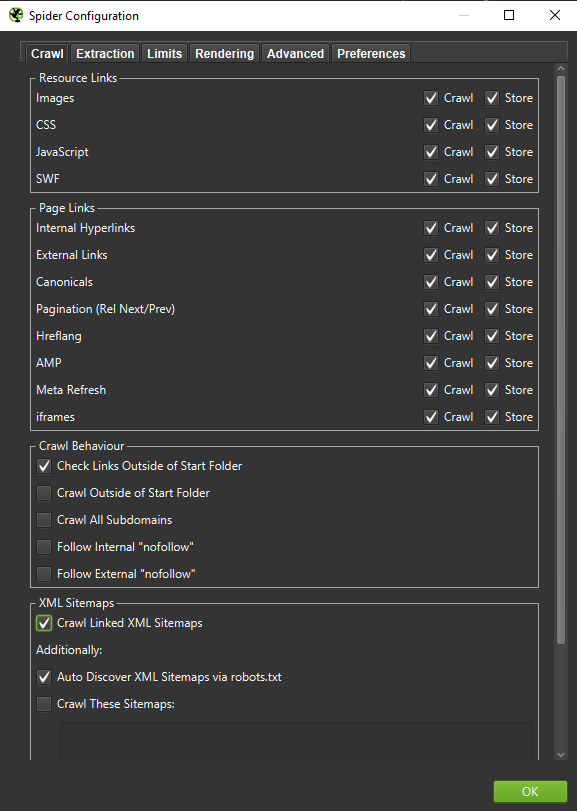
เมื่อทำการวิเคราะห์ในเชิงลึก ขอแนะนำให้ทดสอบสองโหมด – Text Only แต่ยังใช้ JavaScript เพื่อเปรียบเทียบความแตกต่าง (ถ้ามี)
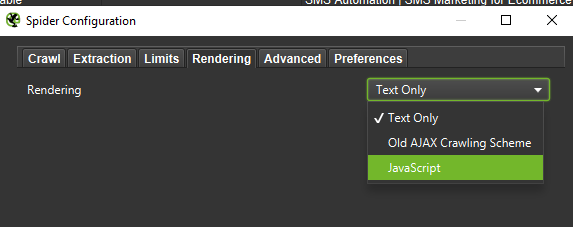
สุดท้าย การทดสอบการตั้งค่าที่นำเสนอข้างต้นกับตัวแทนผู้ใช้สองรายนั้นไม่เสียหาย:
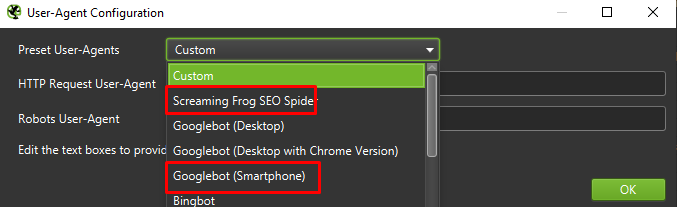
ในกรณีส่วนใหญ่ คุณจะต้องเน้นเฉพาะผลลัพธ์ที่รวบรวมข้อมูล/แสดงผลโดยตัวแทนอุปกรณ์เคลื่อนที่เท่านั้น
สำคัญ: ฉันยังแนะนำให้ใช้โอกาสที่ได้รับจาก Screaming Frog และป้อนข้อมูลจาก GA และ Google Search Console ให้โปรแกรมรวบรวมข้อมูลของคุณ การผสานรวมเป็นวิธีที่รวดเร็วในการระบุการสิ้นเปลืองงบประมาณในการรวบรวมข้อมูล เช่น เนื้อหาจำนวนมากของ URL ที่ซ้ำซ้อนที่อาจไม่ได้รับการเข้าชม
เครื่องมือสำหรับการวิเคราะห์บันทึก (Screaming Frog Logfile และอื่นๆ)
การเลือกตัววิเคราะห์บันทึกของเซิร์ฟเวอร์เป็นเรื่องของความชอบส่วนบุคคล เครื่องมือของฉันคือ Screaming Frog Log File Analyzer อาจไม่ใช่วิธีแก้ปัญหาที่มีประสิทธิภาพที่สุด (การโหลดชุดบันทึกจำนวนมาก = การหยุดแอปพลิเคชัน) แต่ฉันชอบอินเทอร์เฟซ ส่วนสำคัญคือการสั่งให้ระบบแสดงเฉพาะ Googlebots ที่ผ่านการตรวจสอบแล้วเท่านั้น
เครื่องมือสำหรับการติดตามการมองเห็น
ความช่วยเหลือที่เป็นประโยชน์ เนื่องจากช่วยให้คุณระบุหน้าเว็บยอดนิยมของคุณได้ หากหน้าเว็บมีอันดับสูงสำหรับคำหลักหลายคำใน Google (= ได้รับการเข้าชมจำนวนมาก) อาจมีความต้องการรวบรวมข้อมูลมากขึ้น (ตรวจสอบในบันทึก - Google สร้าง Hit มากขึ้นสำหรับหน้าเว็บนี้หรือไม่)
เพื่อจุดประสงค์ของเรา เราจำเป็นต้องมีรายงานทั่วไปใน Senuto – เส้นทางและ URL – สำหรับการตรวจสอบต่อไปในอนาคต รายงานทั้งสองมีอยู่ในการวิเคราะห์การมองเห็น แท็บส่วน ดู:
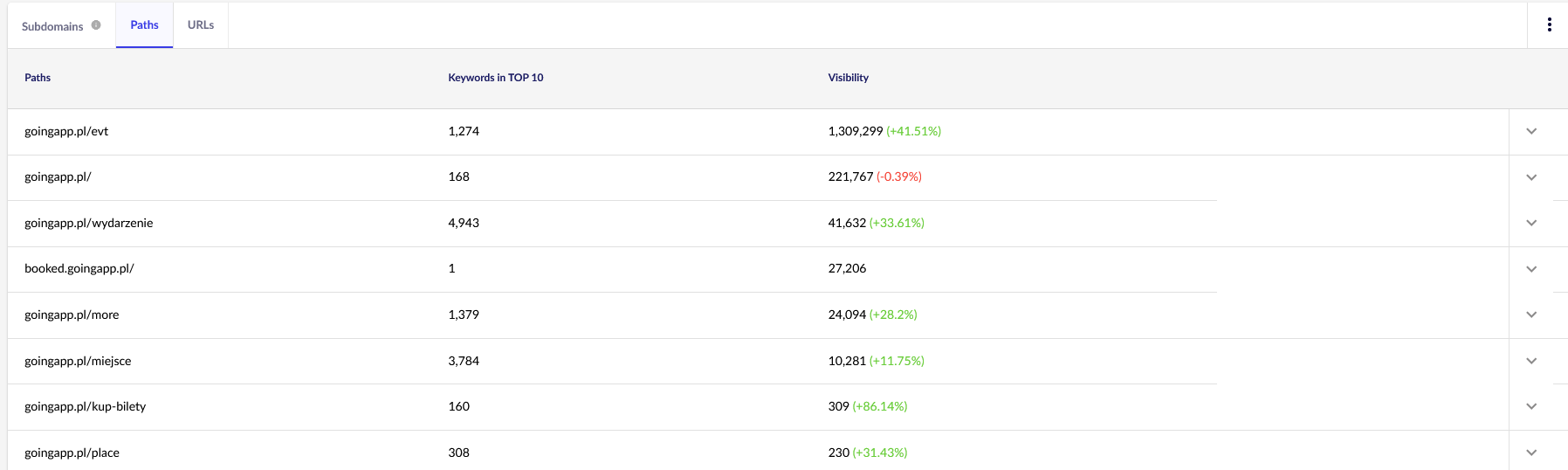
จุดสนใจหลักของเราคือรายงานฉบับที่สอง มาจัดเรียงกันเพื่อดูการแสดงคำหลักของเรา (รายการและจำนวนคำหลักทั้งหมดที่เว็บไซต์ของเราอยู่ในอันดับที่ 10 อันดับแรก) ผลลัพธ์จะให้บริการเราในการระบุแกนหลักสำหรับการกระตุ้น (และการจัดสรรอย่างมีประสิทธิภาพ) ของงบประมาณการรวบรวมข้อมูลของเรา
เครื่องมือสำหรับการวิเคราะห์ลิงก์ย้อนกลับ (Ahrefs, Majestic)
หากหน้าใดหน้าหนึ่งของคุณมีลิงก์ขาเข้าจำนวนมาก ใช้เป็นเสาหลักของกลยุทธ์การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูลของคุณ หน้ายอดนิยมสามารถทำหน้าที่เป็นฮับซึ่งส่งน้ำผลไม้ต่อไป นอกจากนี้ หน้ายอดนิยมที่มีลิงก์ที่มีค่าจำนวนมากยังมีโอกาสที่ดีกว่าในการดึงดูดการรวบรวมข้อมูลบ่อยครั้ง
ใน Ahrefs เราต้องการรายงาน Pages และส่วนที่ถูกต้องคือ: "Best by links":
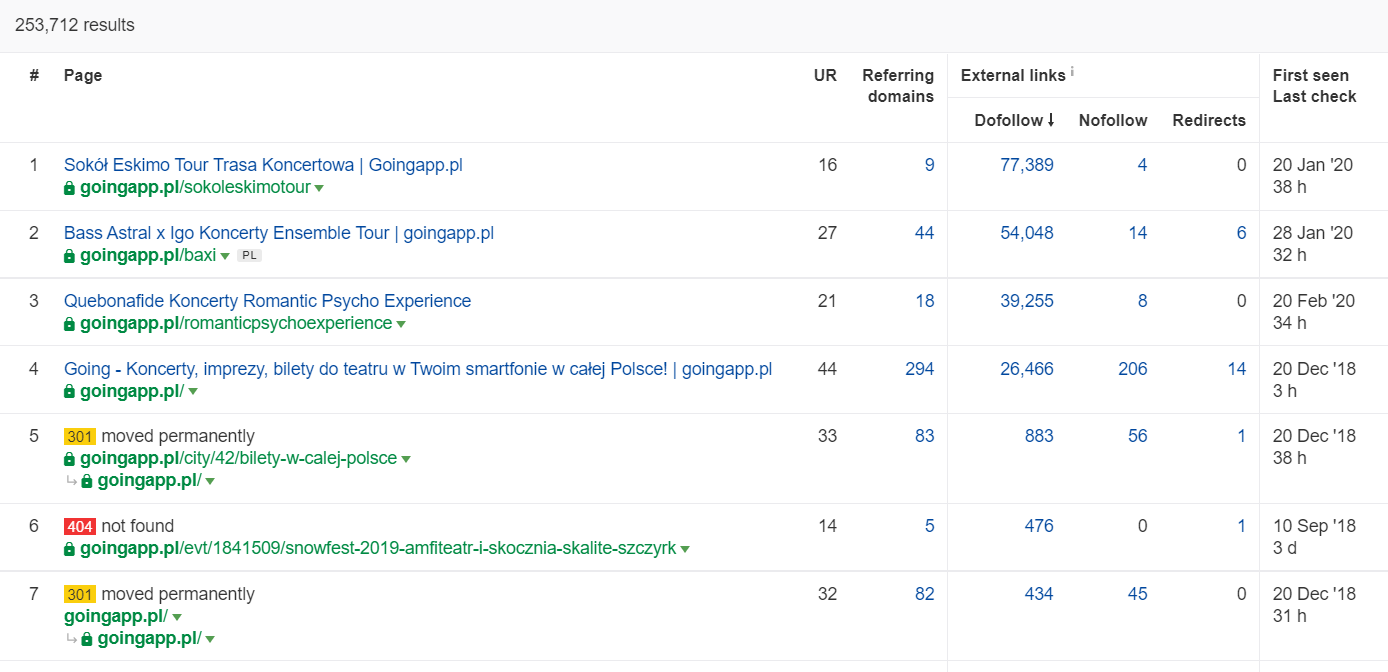
ตัวอย่างข้างต้นแสดงให้เห็นว่า LPs ที่เกี่ยวข้องกับคอนเสิร์ตยังคงสร้างสถิติที่มั่นคงสำหรับลิงก์ย้อนกลับ แม้ว่าคอนเสิร์ตทั้งหมดจะถูกยกเลิกเนื่องจากการแพร่ระบาด แต่ก็ยังคุ้มค่าที่จะใช้หน้าเว็บที่ทรงอิทธิพลในอดีตเพื่อกระตุ้นความอยากรู้อยากเห็นของการรวบรวมข้อมูลบอทและกระจายน้ำผลไม้ไปยังมุมที่ลึกกว่าของเว็บไซต์ของคุณ
อะไรคือสัญญาณบอกปัญหางบประมาณการรวบรวมข้อมูล
การตระหนักว่าคุณกำลังจัดการกับงบประมาณการรวบรวมข้อมูลที่มีปัญหา (ต่ำเกินไป) ไม่ใช่เรื่องง่าย ทำไม โดยหลักแล้ว เนื่องจาก SEO เป็นองค์กรที่ซับซ้อนอย่างยิ่ง อันดับต่ำหรือปัญหาการจัดทำดัชนีอาจเป็นผลที่ตามมาของโปรไฟล์ลิงก์ธรรมดาหรือการขาดเนื้อหาที่ถูกต้องบนเว็บไซต์
โดยทั่วไป การวินิจฉัยงบประมาณการตระเวนจะเกี่ยวข้องกับการตรวจสอบ:
- เวลาที่ผ่านไปจากสิ่งพิมพ์ไปสู่การจัดทำดัชนีของหน้าใหม่ (บล็อกโพสต์ / ผลิตภัณฑ์) สมมติว่าคุณไม่ขอสร้างดัชนีผ่าน Google Search Console
- Google เก็บ URL ที่ไม่ถูกต้องไว้ในดัชนีนานเท่าใด สำคัญ: ที่อยู่ที่เปลี่ยนเส้นทางเป็นข้อยกเว้น – Google จัดเก็บไว้โดยเจตนา
- คุณมีหน้าเว็บที่เข้าสู่ดัชนีเพียงเพื่อเลื่อนออกในภายหลังหรือไม่?
- Google ใช้เวลาเท่าไหร่ในหน้าเว็บที่ไม่สามารถสร้างมูลค่า (การเข้าชม) ได้ ไปที่บันทึกการวิเคราะห์เพื่อค้นหา
จะวิเคราะห์และเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูลได้อย่างไร
การตัดสินใจเข้าสู่การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูลนั้นขึ้นอยู่กับขนาดของเว็บไซต์ของคุณเป็นหลัก Google แนะนำว่าโดยทั่วไปแล้ว เว็บไซต์ที่มีหน้าเว็บน้อยกว่า 1,000 หน้าไม่ควรกังวลกับการใช้ประโยชน์จากขีดจำกัดการรวบรวมข้อมูลที่มีอยู่ให้เกิดประโยชน์สูงสุด ในหนังสือของฉัน คุณควรเริ่มต่อสู้เพื่อการรวบรวมข้อมูลที่มีประสิทธิภาพและประสิทธิผลมากขึ้น หากเว็บไซต์ของคุณมีมากกว่า 300 หน้า และเนื้อหาของคุณมีการเปลี่ยนแปลงแบบไดนามิก (เช่น คุณเพิ่มหน้าใหม่/โพสต์ในบล็อกอย่างต่อเนื่อง)
ทำไม มันเป็นเรื่องของสุขอนามัย SEO ใช้นิสัยการเพิ่มประสิทธิภาพที่ดีและการจัดการงบประมาณการรวบรวมข้อมูลที่ดีในช่วงแรกๆ และคุณจะมีเวลาน้อยลงในการแก้ไขและออกแบบใหม่ในอนาคต
การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล ขั้นตอนมาตรฐาน
โดยทั่วไป การวิเคราะห์งบประมาณการรวบรวมข้อมูลและการเพิ่มประสิทธิภาพประกอบด้วยสามขั้นตอน:
- การรวบรวมข้อมูล ซึ่งเป็นกระบวนการรวบรวมทุกสิ่งที่เรารู้เกี่ยวกับเว็บไซต์ – จากทั้งผู้ดูแลเว็บและเครื่องมือภายนอก
- การวิเคราะห์การมองเห็นและการระบุผลไม้ห้อยต่ำ สิ่งที่วิ่งเหมือนเครื่องจักร? อะไรจะดีไปกว่านี้? พื้นที่ใดมีศักยภาพในการเติบโตสูงสุด
- คำแนะนำสำหรับงบประมาณการรวบรวมข้อมูล
การรวบรวมข้อมูลสำหรับการตรวจสอบงบประมาณการตระเวน
1. รวบรวมข้อมูลเว็บไซต์เต็มรูปแบบโดยใช้หนึ่งในเครื่องมือที่มีขายทั่วไป เป้าหมายคือการรวบรวมข้อมูลอย่างน้อยสองรายการ: อันแรกจำลอง Googlebot ในขณะที่อีกอันดึงเว็บไซต์เป็นตัวแทนผู้ใช้เริ่มต้น (ตัวแทนผู้ใช้ของเบราว์เซอร์จะทำ) ในขั้นตอนนี้ คุณสนใจที่จะดาวน์โหลดเนื้อหาทั้งหมด 100% เท่านั้น หากคุณสังเกตเห็นว่าโปรแกรมรวบรวมข้อมูลเข้าสู่ลูป (เมื่อหลังจากรวบรวมข้อมูลมาทั้งวัน เรายังมีเว็บไซต์เพียง 10% ในฮาร์ดไดรฟ์ของเรา) ให้รู้ว่ามีปัญหาและคุณสามารถหยุดการรวบรวมข้อมูลได้ จำนวน URL ที่สมเหตุสมผลสำหรับการวิเคราะห์ ในกรณีของเว็บไซต์ขนาดใหญ่ คือประมาณ 250–300,000 หน้า
ก) สิ่งที่เรากำลังมองหาส่วนใหญ่เป็นการเปลี่ยนเส้นทางภายใน 301 ข้อผิดพลาด 404 แต่ยังรวมถึงสถานการณ์ที่ข้อความของคุณอาจถูกจัดประเภทเป็นเนื้อหาบางส่วน Screaming Frog มีตัวเลือกในการตรวจจับเนื้อหาที่ใกล้เคียงกัน:
2. บันทึกเซิร์ฟเวอร์ กรอบเวลาที่เหมาะสมควรเป็นช่วงเดือนที่แล้ว อย่างไรก็ตาม ในกรณีของเว็บไซต์ขนาดใหญ่ สองสัปดาห์สุดท้ายอาจพิสูจน์ได้ว่าเพียงพอ ในกรณีที่ดีที่สุด เราควรมีสิทธิ์เข้าถึงบันทึกเซิร์ฟเวอร์ในอดีตเพื่อเปรียบเทียบการเคลื่อนไหวของ Googlebot ในเวลาที่ทุกอย่างดำเนินไปอย่างราบรื่น
3. การส่งออกข้อมูลจาก Google Search Console เมื่อรวมกับจุดที่ 1 และ 2 ข้างต้น ข้อมูลจากความครอบคลุมของดัชนีและสถิติการรวบรวมข้อมูลควรให้ข้อมูลที่ครอบคลุมเกี่ยวกับเหตุการณ์ทั้งหมดบนเว็บไซต์ของคุณ
4. ข้อมูลการจราจรอินทรีย์ หน้ายอดนิยมตามที่กำหนดโดย Google Search Console, Google Analytics รวมถึง Senuto และ Ahrefs เราต้องการระบุหน้าทั้งหมดที่โดดเด่นท่ามกลางฝูงชนด้วยสถิติการมองเห็นสูง ปริมาณการเข้าชม หรือจำนวนลิงก์ย้อนกลับ หน้าเหล่านี้ควรเป็นแกนหลัก ของงานเกี่ยวกับงบประมาณการรวบรวมข้อมูล เราจะใช้เพื่อปรับปรุงการรวบรวมข้อมูลหน้าที่สำคัญที่สุด
5. ตรวจสอบดัชนีด้วยตนเอง ในบางกรณี เพื่อนที่ดีที่สุดของผู้เชี่ยวชาญ SEO เป็นวิธีแก้ปัญหาง่ายๆ ในกรณีนี้: การตรวจสอบข้อมูลที่นำมาจากดัชนีโดยตรง! เป็นการดีที่จะตรวจสอบเว็บไซต์ของคุณด้วยคำสั่งผสม inurl: + site: โอเปอเรเตอร์สุดท้าย เราต้องรวมข้อมูลที่รวบรวมไว้ทั้งหมด โดยปกติ เราจะใช้โปรแกรมรวบรวมข้อมูลภายนอกที่มีคุณลักษณะที่อนุญาตให้นำเข้าข้อมูลภายนอกได้ (ข้อมูล GSC บันทึกของเซิร์ฟเวอร์ และข้อมูลการรับส่งข้อมูลทั่วไป)
การวิเคราะห์การมองเห็นและผลห้อยต่ำ
กระบวนการนี้รับประกันบทความแยกต่างหาก แต่เป้าหมายของเราในวันนี้คือการได้รับมุมมองมุมสูงของวัตถุประสงค์ของเราสำหรับเว็บไซต์และความคืบหน้า เราสนใจทุกอย่างที่ไม่ธรรมดา: การเข้าชมลดลงกะทันหัน (ซึ่งไม่สามารถอธิบายได้ด้วยแนวโน้มตามฤดูกาล) และการเปลี่ยนแปลงที่เกิดขึ้นพร้อมกันในการมองเห็นที่เกิดขึ้นเอง เรากำลังตรวจสอบว่าหน้าเว็บกลุ่มใดแข็งแกร่งที่สุด เพราะหน้าเหล่านั้นจะกลายเป็นศูนย์กลางของเราในการผลักดัน Googlebot ให้ลึกเข้าไปในเว็บไซต์ของเรา
ในโลกที่สมบูรณ์แบบ การตรวจสอบดังกล่าวควรครอบคลุมประวัติทั้งหมดของเว็บไซต์ของเราตั้งแต่เปิดตัว อย่างไรก็ตาม เนื่องจากปริมาณข้อมูลยังคงเพิ่มขึ้นทุกเดือน เรามาเน้นที่การวิเคราะห์การมองเห็นและการเข้าชมที่เกิดขึ้นเองจากช่วง 12 เดือนที่ผ่านมา
รวบรวมข้อมูลงบประมาณ – คำแนะนำของเรา
กิจกรรมที่ระบุไว้ข้างต้นจะแตกต่างกันไปตามขนาดของเว็บไซต์ที่ปรับให้เหมาะสม อย่างไรก็ตาม สิ่งเหล่านี้เป็นองค์ประกอบที่สำคัญที่สุดที่ฉันพิจารณาเสมอเมื่อทำการวิเคราะห์งบประมาณการตระเวน เป้าหมายที่เหนือกว่าคือการกำจัดคอขวดในเว็บไซต์ของคุณ กล่าวคือ เพื่อรับประกันความสามารถในการรวบรวมข้อมูลสูงสุดสำหรับ Googlebots (หรือตัวแทนการจัดทำดัชนีอื่นๆ)
1. เริ่มจากพื้นฐานกันก่อน – การกำจัดข้อผิดพลาด 404/410 ทุกประเภท การวิเคราะห์การเปลี่ยนเส้นทางภายใน และการลบออกจากการเชื่อมโยงภายใน เราควรสรุปงานของเราด้วยการรวบรวมข้อมูลครั้งสุดท้าย คราวนี้ ลิงก์ทั้งหมดควรส่งคืนรหัสตอบกลับ 200 โดยไม่มีการเปลี่ยนเส้นทางภายในหรือข้อผิดพลาด 404
- ในขั้นตอนนี้ เป็นความคิดที่ดีที่จะแก้ไขกลุ่มการเปลี่ยนเส้นทางทั้งหมดที่ตรวจพบในรายงานลิงก์ย้อนกลับ
2. หลังจากการรวบรวมข้อมูล ตรวจสอบให้แน่ใจว่าโครงสร้างเว็บไซต์ของเราปราศจากรายการซ้ำซ้อน
- ตรวจสอบเพื่อป้องกันการกินเนื้อคนที่อาจเกิดขึ้นเช่นกัน – นอกเหนือจากปัญหาที่เกิดจากการกำหนดเป้าหมายคำหลักเดียวกันกับหลายหน้า (โดยสังเขป คุณหยุดควบคุมว่า Google จะแสดงหน้าใด) การกินเนื้อคนจะส่งผลเสียต่องบประมาณการรวบรวมข้อมูลทั้งหมดของคุณ
- รวมรายการที่ซ้ำกันที่ระบุเป็น URL เดียว (โดยปกติคือ URL ที่มีอันดับสูงกว่า)
3. ตรวจสอบจำนวน URL ที่มีแท็ก noindex ดังที่เราทราบ Google ยังคงสามารถไปยังหน้าเหล่านั้นได้ พวกเขาไม่ปรากฏในผลการค้นหา เรากำลังพยายามลดส่วนแบ่งของแท็ก noindex ในโครงสร้างเว็บไซต์ของเรา
- กรณีตรงประเด็น – บล็อกจัดระเบียบโครงสร้างด้วยแท็ก ผู้เขียนอ้างว่าโซลูชันถูกกำหนดโดยความสะดวกของผู้ใช้ ทุกโพสต์มีป้ายกำกับ 3-5 แท็ก ซึ่งกำหนดไม่สอดคล้องกันและไม่ได้จัดทำดัชนี การวิเคราะห์บันทึกพบว่า เป็นโครงสร้างที่มีการรวบรวมข้อมูลมากที่สุดเป็นอันดับสามบนเว็บไซต์
4. ตรวจสอบ robots.txt โปรดทราบว่าการใช้ robots.txt ไม่ได้หมายความว่า Google จะไม่แสดงที่อยู่ในดัชนี
- ตรวจสอบว่าโครงสร้างที่อยู่ที่ถูกบล็อกใดที่ยังคงถูกรวบรวมข้อมูล บางทีการตัดทิ้งอาจทำให้เกิดคอขวด?
- ลบคำสั่งที่ล้าสมัย/ไม่จำเป็น
5. วิเคราะห์ปริมาณของ URL ที่ไม่ใช่รูปแบบบัญญัติบนเว็บไซต์ของคุณ Google เลิกถือว่า rel=”canonical” เป็นคำสั่งที่เข้มงวด ในหลายกรณี เครื่องมือค้นหาจะละเว้นแอตทริบิวต์นี้อย่างจริงจัง (การจัดเรียงพารามิเตอร์ในดัชนี – ยังคงเป็นฝันร้าย)
6. วิเคราะห์ตัวกรองและกลไกพื้นฐาน การกรองรายชื่อเป็นปัญหาใหญ่ที่สุดในการเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล เจ้าของธุรกิจอีคอมเมิร์ซยืนกรานที่จะใช้ตัวกรองที่ใช้ได้กับชุดค่าผสมใดๆ (เช่น การกรองตามสี + วัสดุ + ขนาด + ความพร้อมใช้งาน... จนถึงครั้งที่สิบหก) วิธีแก้ปัญหาไม่เหมาะสมและควรจำกัดให้น้อยที่สุด
7. สถาปัตยกรรมข้อมูลบนเว็บไซต์ ซึ่งพิจารณาถึงเป้าหมายทางธุรกิจ ศักยภาพในการเข้าชม และโปรไฟล์ลิงก์ปัจจุบัน เรามาทำงานบนสมมติฐานที่ว่าลิงก์ไปยังเนื้อหาที่สำคัญสำหรับเป้าหมายทางธุรกิจของเราควรจะมองเห็นได้ทั่วทั้งไซต์ (ในทุกหน้า) หรือในหน้าแรก เรากำลังทำให้ที่นี่ง่ายขึ้น แต่หน้าแรกและลิงก์เมนูด้านบน / ทั่วเว็บไซต์เป็นตัวบ่งชี้ที่ทรงพลังที่สุดในการสร้างมูลค่าจากการเชื่อมโยงภายใน ในเวลาเดียวกัน เรากำลังพยายามที่จะบรรลุขอบเขตโดเมนที่เหมาะสมที่สุด: เป้าหมายของเราคือสถานการณ์ที่เราสามารถเริ่มการรวบรวมข้อมูลจากหน้าใดก็ได้และยังคงเข้าถึงจำนวนหน้าเท่าเดิม (ทุก URL ควรมีลิงก์ขาเข้าอย่างน้อยหนึ่งลิงก์) .
- การทำงานไปสู่สถาปัตยกรรมข้อมูลที่มีประสิทธิภาพเป็นหนึ่งในองค์ประกอบหลักของการปรับงบประมาณการตระเวนให้เหมาะสมที่สุด ช่วยให้เราสามารถปลดปล่อยทรัพยากรของบอทบางส่วนจากที่หนึ่งและเปลี่ยนเส้นทางไปยังอีกที่หนึ่ง นอกจากนี้ยังเป็นหนึ่งในความท้าทายที่ยิ่งใหญ่ที่สุด เนื่องจากต้องได้รับความร่วมมือจากผู้มีส่วนได้ส่วนเสียทางธุรกิจ ซึ่งมักจะนำไปสู่การต่อสู้และการวิพากษ์วิจารณ์ครั้งใหญ่ที่บ่อนทำลายคำแนะนำ SEO
8. การแสดงเนื้อหา สำคัญในกรณีที่เว็บไซต์มุ่งหวังที่จะเชื่อมโยงภายในของตนบนระบบผู้แนะนำที่จับพฤติกรรมของผู้ใช้ เหนือสิ่งอื่นใด เครื่องมือเหล่านี้ส่วนใหญ่ต้องอาศัยไฟล์คุกกี้ Google ไม่ได้จัดเก็บคุกกี้ ดังนั้นจึงไม่ได้รับผลลัพธ์ที่กำหนดเอง ผลที่สุด: Google มักจะเห็นเนื้อหาเดียวกันหรือไม่เห็นเนื้อหาเลย
- เป็นเรื่องปกติที่จะป้องกันไม่ให้ Googlebot เข้าถึงเนื้อหา JS/CSS ที่สำคัญ การย้ายนี้อาจนำไปสู่ปัญหาในการจัดทำดัชนีหน้าเว็บ (และทำให้ Google เสียเวลาในการแสดงเนื้อหาที่ไม่พร้อมใช้งาน)
9. ประสิทธิภาพของเว็บไซต์ – Core Web Vitals ในขณะที่ฉันสงสัยเกี่ยวกับผลกระทบของ CWV ต่อการจัดอันดับไซต์ (ด้วยเหตุผลหลายประการ รวมถึงความหลากหลายของอุปกรณ์ที่มีจำหน่ายในท้องตลาดและความเร็วที่แตกต่างกันของการเชื่อมต่ออินเทอร์เน็ต) เป็นหนึ่งในพารามิเตอร์ที่คุ้มค่าที่สุดที่จะพูดคุยกับผู้เขียนโค้ด
10. Sitemap.xml – ตรวจสอบว่าทำงานได้หรือไม่และมีองค์ประกอบหลักทั้งหมด (ไม่มีอะไรนอกจาก URL ตามรูปแบบบัญญัติที่ส่งคืนรหัสสถานะ 200)
- คำแนะนำแรกของฉันสำหรับการเพิ่มประสิทธิภาพ sitemap.xml คือการแบ่งหน้าของคุณตามประเภทหรือ – เมื่อเป็นไปได้ – หมวดหมู่ แผนกนี้จะช่วยให้คุณควบคุมการเคลื่อนไหวและการจัดทำดัชนีของเนื้อหาของ Google ได้อย่างเต็มที่