
Word2Vec ile Konu Modelleme
Yayınlanan: 2022-05-02Bir kelime, tuttuğu şirket tarafından tanımlanır. Sözcükleri sayılara dönüştürme ve onları çok boyutlu bir alanda temsil etme yöntemi olan Word2Vec'in arkasındaki öncül budur. Bir belge koleksiyonunda (korpus) sıklıkla birbirine yakın bulunan kelimeler de bu alanda birbirine yakın görünecektir. Bağlamsal olarak ilişkili oldukları söylenir.
Word2Vec, bir bütünlük ve uygun eğitim gerektiren bir makine öğrenimi yöntemidir. Her ikisinin de kalitesi, bir konuyu doğru bir şekilde modelleme yeteneğini etkiler. Çok spesifik ve karmaşık konuların çıktıları incelenirken, bunlar tam olarak modellenmesi en zor olan konular olduğu için, herhangi bir eksiklik kolayca ortaya çıkar. Word2Vec, sınırlamalarını gidermek için sıklıkla diğer modelleme teknikleriyle birleştirilmesine rağmen, kendi başına kullanılabilir.
Bu makalenin geri kalanı Word2Vec, nasıl çalıştığı, konu modellemede nasıl kullanıldığı ve sunduğu bazı zorluklar hakkında ek arka plan sağlar.
Word2Vec nedir?
Eylül 2013'te Google araştırmacıları Tomas Mikolov, Kai Chen, Greg Corrado ve Jeffrey Dean, 'Vektör Uzayında Kelime Gösterimlerinin Verimli Tahmini' başlıklı makaleyi (pdf) yayınladılar. Şimdi Word2Vec olarak adlandırdığımız şey budur. Makalenin amacı, "milyarlarca kelime ve kelime dağarcığında milyonlarca kelime bulunan devasa veri kümelerinden yüksek kaliteli kelime vektörlerini öğrenmek için kullanılabilecek teknikleri tanıtmak" idi.
Bu noktadan önce, herhangi bir doğal dil işleme tekniği, kelimeleri tekil birimler olarak ele aldı. Sözcükler arasındaki benzerliği hesaba katmamışlardır. Bu yaklaşımın geçerli nedenleri olsa da, sınırlamaları vardı. Bu temel tekniklerin ölçeklendirilmesinin önemli bir gelişme sağlayamadığı durumlar vardı. Bu nedenle, ileri teknolojiler geliştirme ihtiyacı.
Makale, daha düşük hesaplama gereksinimlerine sahip basit modellerin yüksek kaliteli kelime vektörlerini eğitebileceğini gösterdi. Makalenin sonunda, “çok daha büyük bir veri setinden çok hassas yüksek boyutlu kelime vektörlerini hesaplamak mümkün”. Neredeyse sınırsız bir kelime hazinesi sağlayan bir trilyon kelimeye sahip belge koleksiyonlarından (corpora) bahsediyorlar.
Word2Vec, benzerliklerin matematiksel olarak keşfedilebilmesi için kelimeleri sayılara, bu durumda vektörlere dönüştürmenin bir yoludur. Buradaki fikir, benzer kelimelerin vektörlerinin vektör uzayı içinde gruplandırılmasıdır.
Bir haritadaki enlem ve boylamsal koordinatları düşünün. Bu iki boyutlu vektörü kullanarak, iki konumun birbirine nispeten yakın olup olmadığını hızlı bir şekilde belirleyebilirsiniz. Sözcüklerin bir vektör uzayında uygun şekilde temsil edilebilmesi için iki boyut yeterli değildir. Bu nedenle, vektörlerin birçok boyutu içermesi gerekir.
Word2Vec Nasıl Çalışır?
Word2Vec, girdi olarak büyük bir metin külliyatı alır ve sığ bir sinir ağı kullanarak onu vektörleştirir. Çıktı, her biri karşılık gelen bir vektöre sahip bir kelime listesidir (kelime hazinesi). Benzer anlamlara sahip kelimeler, yakın mesafede yer alır. Matematiksel olarak bu, kosinüs benzerliği ile ölçülür, burada toplam benzerlik 0 derecelik bir açı olarak ifade edilirken hiçbir benzerlik 90 derecelik bir açı olarak ifade edilmez.
Kelimeler, farklı modeller kullanılarak vektörler olarak kodlanabilir. Makalelerinde, Mikolov ve ark. iki mevcut modele baktı, ileri beslemeli sinir ağı dili modeli (NNLM) ve tekrarlayan sinir ağı dili modeli (RNNLM). Ek olarak, iki yeni log-lineer model, sürekli kelime çantası (CBOW) ve sürekli Skip-gram öneriyorlar.
Karşılaştırmalarında CBOW ve Skip-gram daha iyi performans gösterdi, bu yüzden bu iki modeli inceleyelim.
CBOW, NNLM'ye benzer ve bir hedef kelime belirlemek için bağlama dayanır. Kendisinden önce ve sonra gelen kelimelere göre hedef kelimeyi belirler. Mikolov, en iyi performansın dört gelecek ve dört tarihsel kelime ile gerçekleştiğini buldu. Buna 'kelime torbası' denir çünkü kelimelerin tarihteki sırası çıktıyı etkilemez. CBOW terimindeki 'sürekli', “bağlamın sürekli dağıtılmış temsili” kullanımına atıfta bulunur.
Skip-gram, CBOW'un tersidir. Bir kelime verildiğinde, belirli bir aralıktaki çevreleyen kelimeleri tahmin eder. Daha geniş bir aralık, daha kaliteli kelime vektörleri sağlar, ancak hesaplama karmaşıklığını arttırır. Uzak terimlere daha az ağırlık verilir, çünkü bunlar genellikle mevcut kelimeyle daha az ilişkilidir.
CBOW ile Skip-gram'ı karşılaştırırken, ikincisinin büyük veri setlerinde daha kaliteli sonuçlar sunduğu bulunmuştur. CBOW daha hızlı olmasına rağmen, Skip-gram nadiren kullanılan kelimeleri daha iyi işler.
Eğitim sırasında her kelimeye bir vektör atanır. Bu vektörün bileşenleri, benzer kelimeler (bağlamlarına göre) birbirine daha yakın olacak şekilde ayarlanır. Bunu, uzaya her yeni terim eklendiğinde bu çok boyutlu vektörde kelimelerin itilip kakıldığı bir halat çekme olarak düşünün.
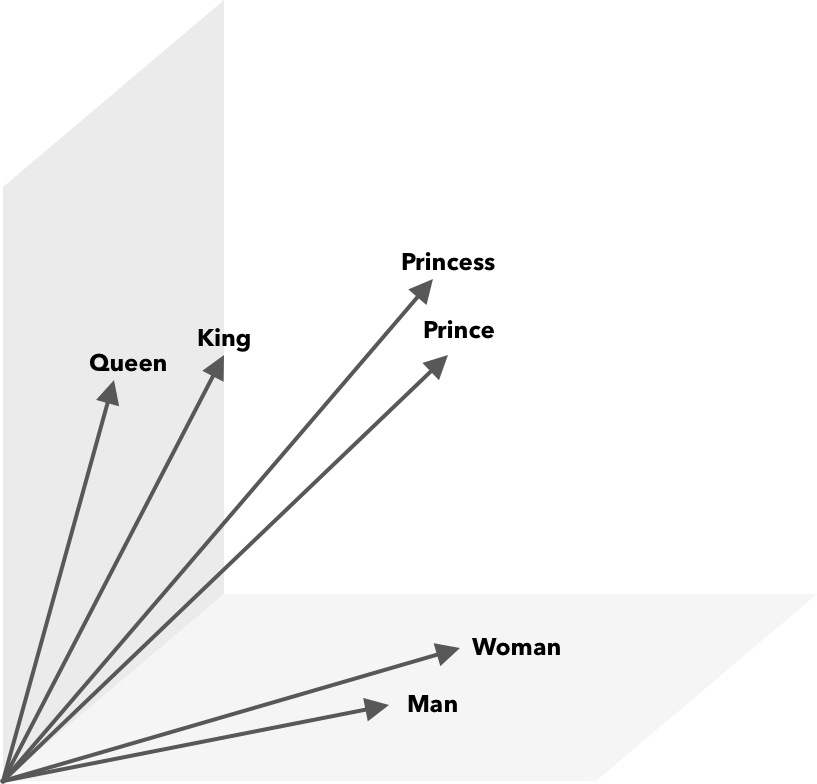
Kosinüs benzerliğine ek olarak matematiksel işlemler kelime vektörleri üzerinde gerçekleştirilebilir. Örneğin, vektör(”Kral”) – vektör(”Erkek”) + vektör(”Kadın”), Kraliçe kelimesini temsil edene en yakın vektörle sonuçlanır.
Konu Modelleme için Word2Vec
Word2Vec tarafından oluşturulan kelime dağarcığı, kelimeler arasındaki ilişkileri tespit etmek için doğrudan sorgulanabilir veya derin öğrenme sinir ağına beslenebilir. CBOW ve Skip-gram gibi Word2Vec algoritmalarıyla ilgili bir sorun, her bir kelimeyi eşit olarak ağırlıklandırmalarıdır. Belgelerle çalışırken ortaya çıkan sorun, kelimelerin bir cümlenin anlamını eşit olarak temsil etmemesidir.

Bazı kelimeler diğerlerinden daha önemlidir. Bu nedenle, durumla başa çıkmak için genellikle TF-IDF gibi farklı ağırlıklandırma stratejileri kullanılır. Bu aynı zamanda bir sonraki bölümde bahsedilen hubness sorununun çözülmesine de yardımcı olur. Searchmetrics ContentExperience, MarketMuse ile karşılaştırmamızda burada okuyabileceğiniz TF-IDF ve Word2Vec'in bir kombinasyonunu kullanır.
Word2Vec gibi sözcük yerleştirmeleri morfolojik, anlamsal ve sözdizimsel bilgileri yakalarken, konu modelleme bir bütüncedeki gizli anlamsal yapıyı veya konuları keşfetmeyi amaçlar.
Budhkar ve Rudzicz'e (PDF) göre, gizli Dirichlet tahsisini (LDA) Word2Vec ile birleştirmek, "bu modellerde gömülü bağlamsal bilgilerin yokluğundan kaynaklanan sorunu ele almak" için ayırt edici özellikler üretebilir. LDA2vec üzerinde daha kolay okuma bu DataCamp eğitiminde bulunabilir.
Word2Vec'in Zorlukları
Word2Vec de dahil olmak üzere, genel olarak kelime gömmeleriyle ilgili birkaç sorun vardır. Bunlardan bazılarına değineceğiz, daha ayrıntılı bir analiz için Amir Bakarov'un 'Kelime Gömme Değerlendirme Yöntemleri Anketi'ne (pdf) başvuracağız. Derlem ve boyutu ile eğitimin kendisi çıktı kalitesini önemli ölçüde etkileyecektir.
Çıktıyı nasıl değerlendiriyorsunuz?
Bakarov'un makalesinde açıkladığı gibi, bir NLP mühendisi tipik olarak yerleştirmelerin performansını bir hesaplamalı dilbilimciden veya bu konuda bir içerik pazarlamacısından farklı şekilde değerlendirecektir. İşte makalede belirtilen bazı ek sorunlar.
- Semantik belirsiz bir fikirdir. "İyi" bir sözcük yerleştirme, anlambilim anlayışımızı yansıtır. Ancak, anlayışımızın doğru olup olmadığının farkında olmayabiliriz. Ayrıca kelimelerin anlamsal ilişki ve anlamsal benzerlik gibi farklı türde ilişkileri vardır. Yerleştirme sözcüğü ne tür bir ilişkiyi yansıtmalıdır?
- Uygun eğitim verilerinin olmaması. Araştırmacılar, sözcük yerleştirmelerini eğitirken, sık sık onları verilere göre ayarlayarak kalitelerini artırırlar. Eğri uydurma olarak adlandırdığımız şey budur. Sonucu verilere uydurmak yerine, araştırmacılar kelimeler arasındaki ilişkileri yakalamaya çalışmalıdır.
- İçsel ve dışsal yöntemler arasında korelasyon olmaması, hangi yöntem sınıfının tercih edildiğinin belirsiz olduğu anlamına gelir. Dışsal değerlendirme, diğer doğal dil işleme görevlerinde daha aşağı akışta kullanım için çıktı kalitesini belirler. İçsel değerlendirme, kelime ilişkilerinin insan yargısına dayanır.
- Huysuzluk sorunu. Ortak kelimeleri temsil eden kelime vektörleri olan hub'lar, aşırı sayıda diğer kelime vektörlerine yakındır. Bu gürültü değerlendirmeyi saptırabilir.
Ek olarak, özellikle Word2Vec ile ilgili iki önemli zorluk vardır.
- Belirsizliklerle çok iyi başa çıkamaz. Sonuç olarak, birden çok anlama sahip bir kelimenin vektörü, idealden uzak olan ortalamayı yansıtır.
- Word2Vec, sözcük dağarcığı dışındaki (OOV) sözcükleri ve morfolojik olarak benzer sözcükleri işleyemez. Model yeni bir kavramla karşılaştığında, doğru bir temsil olmayan rastgele bir vektör kullanmaya başvurur.
Özet
Word2Vec veya başka bir kelime yerleştirmenin kullanılması başarı garantisi değildir. Kaliteli çıktı, uygun ve yeterince büyük bir bütünce kullanılarak uygun eğitime dayanır.
Çıktının kalitesini değerlendirmek zahmetli olsa da, içerik pazarlamacıları için basit bir çözüm burada. Bir dahaki sefere içerik optimize ediciyi değerlendirirken, çok özel bir konu kullanmayı deneyin. Bu şekilde test etme söz konusu olduğunda düşük kaliteli konu modelleri başarısız olur. Genel şartlar için uygundurlar ancak istek çok spesifik hale geldiğinde bozulurlar.
Bu nedenle, 'avokado nasıl yetiştirilir' konusunu kullanırsanız, önerilerin genel olarak avokado ile değil, bitkinin yetiştirilmesiyle ilgili olduğundan emin olun.
MarketMuse NLG Teknolojisi doğal dil oluşturma bu makalenin oluşturulmasına yardımcı oldu.
Şimdi ne yapmalısın
Hazır olduğunuzda… daha iyi içeriği daha hızlı yayınlamanıza yardımcı olabileceğimiz 3 yol:
- MarketMuse ile zaman ayırın MarketMuse'ın ekibinizin içerik hedeflerine ulaşmasına nasıl yardımcı olabileceğini görmek için stratejistlerimizden biriyle canlı bir demo planlayın.
- Daha iyi içeriği nasıl daha hızlı oluşturacağınızı öğrenmek istiyorsanız blogumuzu ziyaret edin. İçeriği ölçeklendirmeye yardımcı olacak kaynaklarla dolu.
- Bu sayfayı okumaktan zevk alacak başka bir pazarlamacı tanıyorsanız, e-posta, LinkedIn, Twitter veya Facebook aracılığıyla onlarla paylaşın.