
使用队列实现弹性:构建一个永不跳过十亿节拍的系统
已发表: 2018-12-21Braze 代表其客户每天处理数十亿个事件,从而将数十亿条高度集中的个性化消息发送给其最终用户。 未能发送其中一条消息会产生后果,无论是错过收据,还是更糟糕的是,错过通知让用户知道他们的食物已准备好。 为了确保这些关键信息始终正确且始终准时,Braze 采用战略方法来利用工作队列。
什么是作业队列?
典型的作业队列是一种架构模式,其中进程将计算作业提交到队列,而其他进程实际执行这些作业。 这通常是一件好事——如果使用得当,它可以为您提供传统的请求-响应范例无法获得的并发度、可伸缩性和冗余度。 许多工作人员可以在多个进程、多台机器甚至多个数据中心同时执行不同的作业,以实现峰值并发。 您可以分配某些工作节点来处理某些队列并将特定作业发送到特定队列,从而允许您根据需要扩展资源。 如果工作进程崩溃或数据中心离线,其他工作人员可以执行剩余的作业。
虽然您当然可以应用这些原则并轻松地小规模运行作业排队系统,但当您处理数十亿个作业时,接缝开始显现(甚至破裂)。 让我们来看看 Braze 在每天处理数千个、数百万乃至现在数十亿个工作的过程中面临的一些问题。
缺乏一致性是一个弱点
如果我们发送一条消息,但在记录我们刚刚发送该消息的事实之前就崩溃了,会发生什么?
这里可能会出现几种不同的不良结果。 首先,您可能会重新安排失败的作业并再次发送消息。 那……不理想:没有人愿意两次收到相同的东西。 相反,请考虑根本不重新安排它。 在这种情况下,我们的内部会计将不正确,因此归因、转换和其他各种事情都不会正确向前发展。
我们如何解决这个问题? 在编写工作定义时,我们会认真考虑幂等性和重试行为。
当您谈论队列时,幂等性意味着单个作业可以在任意点终止,重新排队的作业将全部重新运行,最终结果将与我们成功运行该作业一样时间。 这与我们选择的重试行为密切相关——至少一次交付。 通过记住我们所有的作业将至少运行一次,甚至可能多次,我们可以编写幂等作业定义,即使在随机失败的情况下也能确保一致性。
回到我们的消息发送示例,我们如何使用这些概念来确保一致性? 在这种情况下,我们可能会将作业分成两部分,第一部分发送消息并将第二部分入队,第二部分写入数据库。 在这种情况下,我们可以根据需要重试任一作业——如果消息发送提供程序已关闭,或者内部会计数据库已关闭,我们将适当地重试,直到成功!
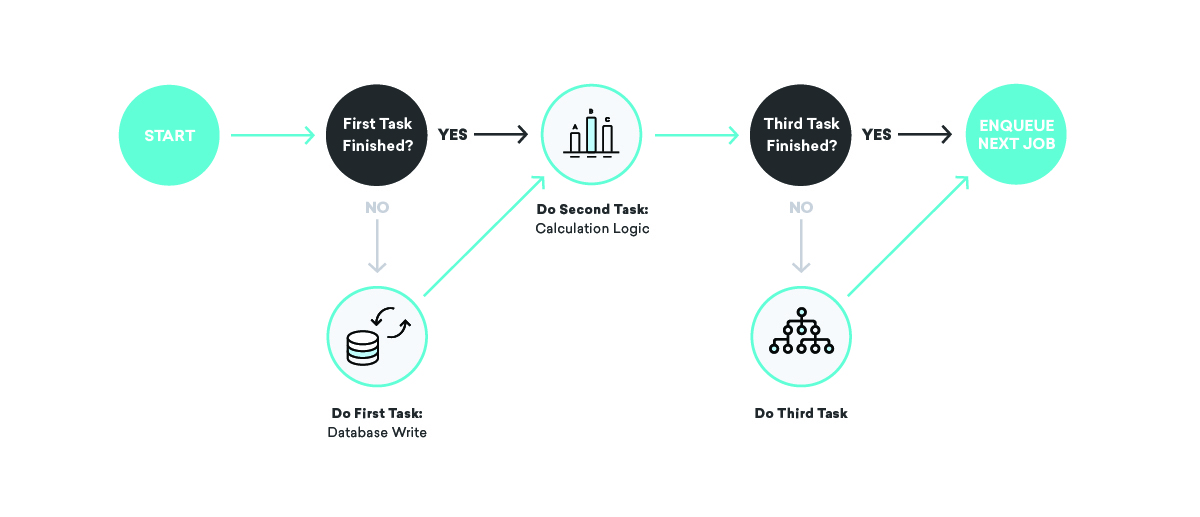
好栅栏造就好邻居
当 Global Gizmos 的数据库关闭时,我们的示例公司 Consolidated Widgets 的数据处理会发生什么情况?
在这种情况下,如果我们的至少一次交付策略正在发挥作用,我们预计 Global Gizmos 的所有数据处理作业都会一遍又一遍地重试,直到它们成功。 这很棒——即使他们的数据库关闭,我们也不会丢失任何数据。 然而,对于 Consolidated Widgets,它可能不是那么好:如果工作人员不断地重试和失败,他们可能太忙而无法及时处理 Consolidated Widgets 的工作。
我们可以通过使用精心选择的队列名称并根据需要暂停某些队列来解决此问题。 有了这个在我们的工具带中,我们可以以外科手术的方式减轻基础设施的压力。 在我们上面的场景中,一旦我们知道 Global Gizmos 的数据库已关闭,我们可以暂停他们的数据处理队列,直到我们知道它已备份,以确保一个特定的中断不会影响任何其他客户!
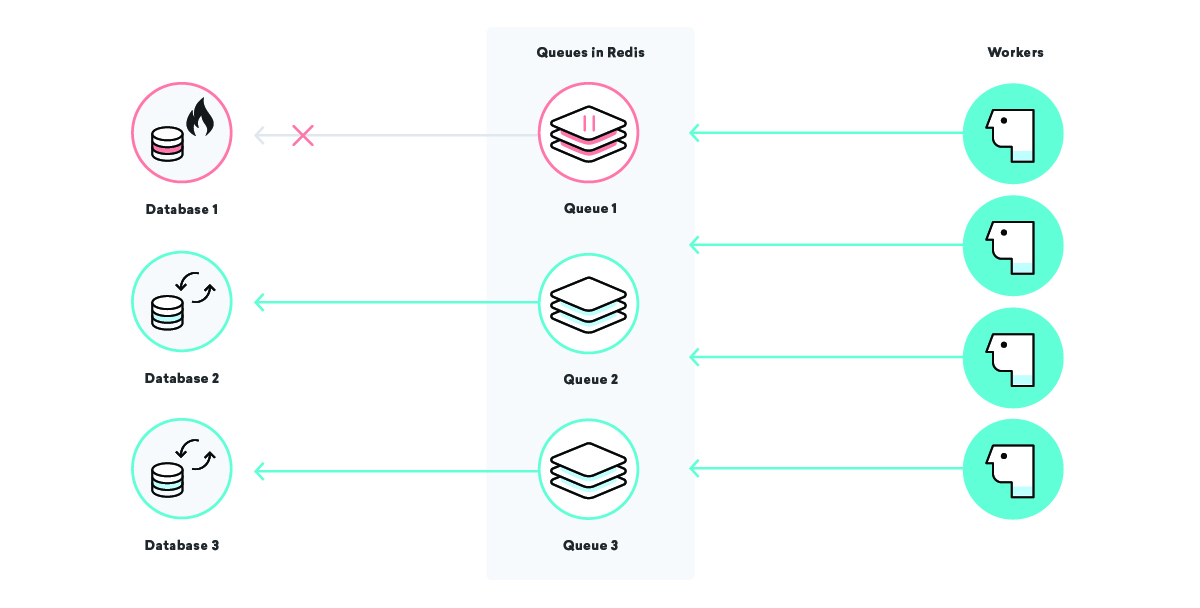
等待是痛苦的
如果 Consolidated Widgets 和 Global Gizmos 分别向 5000 万用户发送电子邮件活动,间隔 5 分钟会怎样? 谁先走?

简单的作业排队系统有一个简单的“工作”队列,工人从中提取作业。 一旦你有各种各样的不同作业和作业类型,你可能会继续拥有多种类型的队列,每个队列都有不同的优先级或从这些队列中拉出的工人类型。 在这种情况下,我们有各种简单的队列用于数据处理、消息传递和各种维护任务。
快进到当您每天发送数十亿条个性化消息时,一个“消息”队列不会减少它——当队列变得非常大时会发生什么,就像我们上面的例子一样? 我们是否优先考虑最先到达的工作?
我们的动态排队系统试图解决一种称为作业饥饿的现象,即准备执行的作业在执行之前等待很长时间,通常是因为某种优先级。 在一个简单的“消息”队列中,优先级只是作业进入队列的时间,这意味着添加到大队列末尾的作业最终可能会等待很长时间。
当我们对一个活动及其所有消息进行排队时,我们不是将作业添加到一个大的“消息传递”队列中,而是为这个活动创建一个全新的队列,并带有一个特殊的名称,以便我们知道它是什么并且如何找到它。 将作业添加到队列后,我们获取“动态队列”列表并将这个新队列名称添加到末尾。
通过采用这种策略,我们可以指示工作人员从“动态队列”列表中获取动态队列的名称,然后处理该特定队列上的所有作业。 这使我们能够确保尽可能快地发送消息,并确保我们所有的客户都得到同等的重视。
因此,这还有其他好处,例如更高的缓存命中率和更少的数据库连接,因为特定工作人员的工作位置增加了。 每个人都赢了!
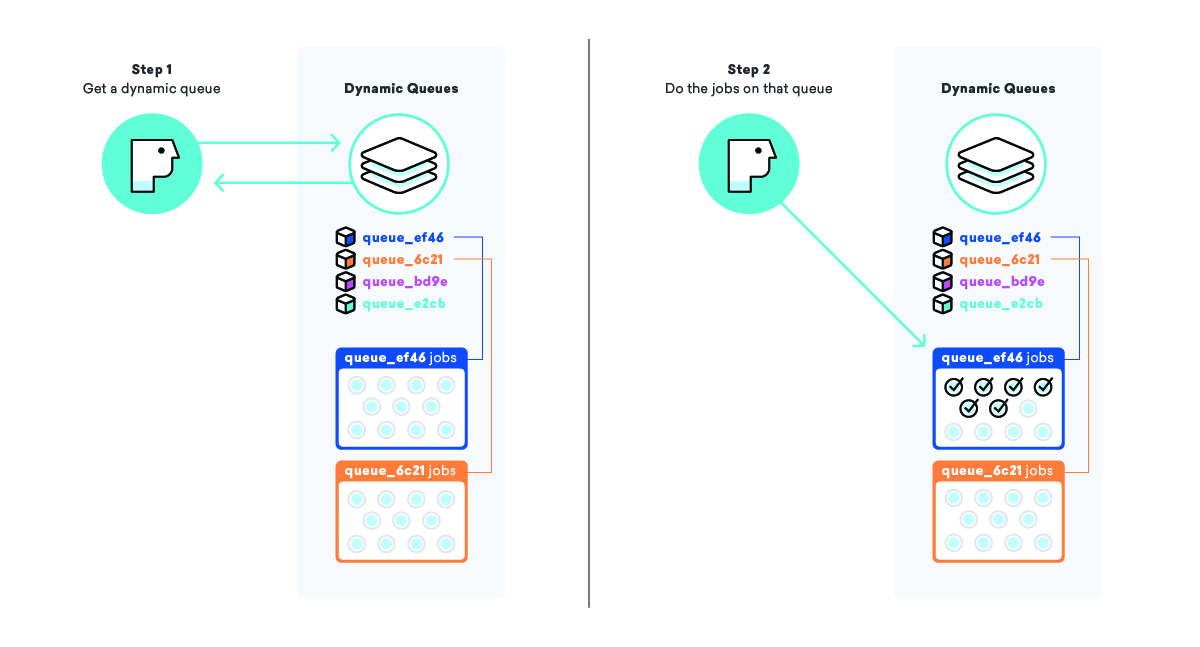
始终有一个备份计划
当数据库关闭、一些队列暂停并且作业队列开始填满时会发生什么?
有时,重要的基础设施只会在你身上死掉。 我们有备用设备和备份,但提升备份基础设施所需的时间几乎永远不会为零。 在整个应用程序基础架构中拥有多层队列对于减轻这些类型事件的影响非常有帮助。
我们采用的一种策略是在设备本身上排队。 数以百万计的设备具有使用 Braze SDK 的不同应用程序,在这些应用程序中,我们利用队列将数据发送到我们的 API。
当我们的 SDK 提交该数据并由于某种原因失败时,SDK 会使用指数退避算法排队重试,直到成功。 这种策略将基础设施或代码故障的影响降至最低,因为设备将简单地将自己的数据排队并在一切恢复在线时将其发送给 Braze。
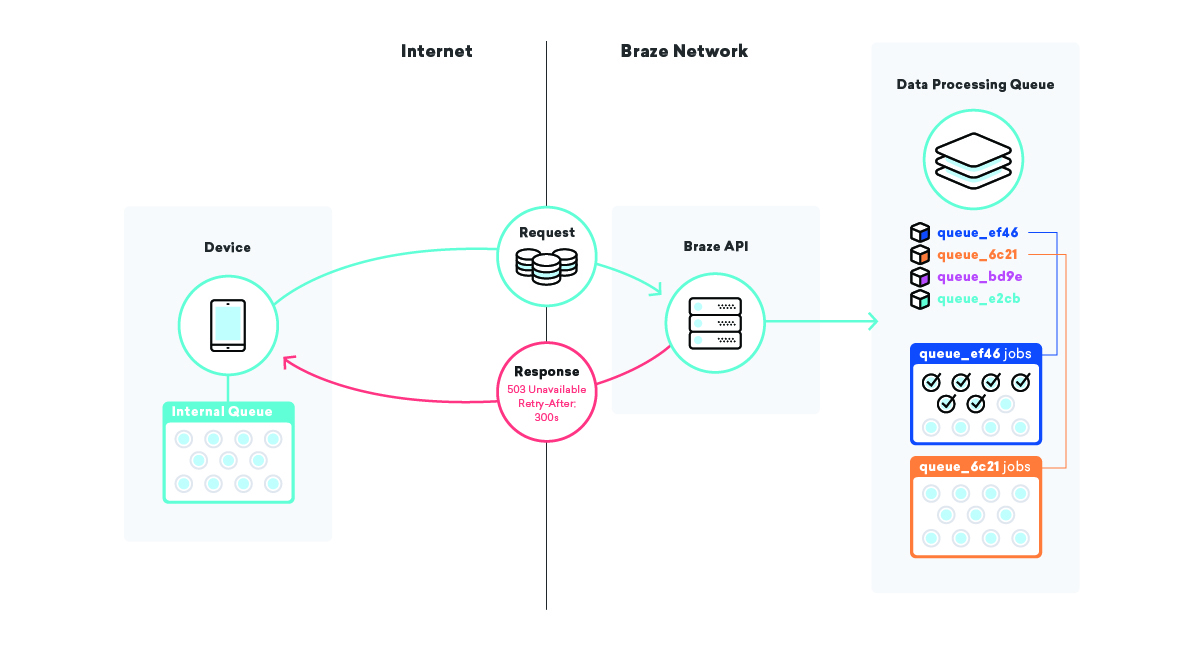
快速行动而不破坏事物
归根结底,我们的目标是比其他任何人都更好地发送高度专注的个性化信息,这包括快速行动、保持弹性和做好一切。 作业队列是 Braze 基础架构的核心,因此我们一直在关注我们的表现,采用最佳实践,并尝试新策略和先进技术,以成为游戏中的佼佼者。
如果营销自动化领域中这种类型的高性能、低延迟系统工程让您兴奋,那么您一定要查看我们的工作板!