
深度学习的状态:从开发人员和 VC 的角度
已发表: 2017-09-05Nikhil Kapur 讨论深度学习的状态,首先是作为一名学生开发人员,现在是一名 VC
一个星期六,我在 Unilever Foundry 和 Padang.co 巨大的 Level 3 办公室参加了深度学习和 TensorFlow 研讨会。 再次沉浸在开发世界中是有趣的一天,我很享受与我的同桌的所有对话,其中一个经营着家族企业并将学习 ML/深度学习作为一种爱好(他是一个编程爱好者),另一个来自Zalora 的营销部门希望在她的工作中应用一些人工智能。
我们开始在我们的机器上设置 TensorFlow 和 Keras(TensorFlow 的抽象),然后开始修补一些常见的深度学习问题和示例,例如使用 MNIST 数据集。 从一个简单的文本识别小 NLP 模型开始,我们深入研究了卷积神经网络,结果证明它非常有趣。
我们使用的是现成的预训练模型,例如 Inception V3,但正在使用我们自己的数据集并重新训练模型以解决不同的问题,例如“这是猫还是狗?” 该课程的目标是了解深度学习的基础知识并尝试参数和特征。 如果您现在感到嫉妒,那么我建议您去 Playground.tensorflow.org 玩,这是工作坊中最容易获得的部分!
非常感谢 Sam Witteveen 和 Martin Andrews 组织了这次活动。 我在这里讲述了我得出的一些观点,以及我认为深度学习和人工智能的总体方向,尤其是从 VC 的角度来看。
从开发人员的角度进行深度学习
为了提供一些背景知识,我对“人工智能”有相当多的了解。 大学二年级时,我在德勤的技术咨询部门实习。 我和我的朋友 Ujjwal Dasgupta 一起,他后来最终获得了 ML 硕士学位,现在在谷歌工作,我花了几个月的时间在 IBM Datastage(一个数据仓库软件)上制作了一个改进的 ETL(Extract-Transform-Load)流程。 当时,总是比我更有远见的 Ujjwal 向我介绍了数据挖掘,我开始关注 Andrew Ng 的讲座和在线课程。
明年夏天,我在这个主题上花费的时间很感兴趣,我想更深入地研究 ML。 我很幸运被分配到 Mozilla 的一个项目,使用基于机器学习的编译器 — Milespot GCC 来提高 Firefox 的性能。 使用这个 ML 编译器,我能够编译 Mozilla Firefox 的代码,从而将程序加载时间缩短约 10%。
然后在我的期末论文中,我无法放弃 ML。 我与德国人工智能研究所 DFKI 合作开展了一个极具挑战性的项目,使用一个简单的网络摄像头进行眼动追踪。 DFKI 的团队将其用于特定应用程序 Text 2.0。 他们使用特殊的高清摄像头来跟踪您的眼睛,并相应地通过自动滚动、自动翻译、弹出词典等超酷功能来增强文本。
我们决定用一个简单的网络摄像头做同样的事情,因为印度没有人有钱购买那个特殊的高清摄像头。 准确地说,我们在这方面失败了,在我们的跟踪中只达到了大约 70% 的准确率。 但这是我参与过的最激动人心的项目之一。
为你推荐:

元界将如何改变印度汽车业

反暴利条款对印度初创企业意味着什么?

教育科技初创公司如何帮助印度的劳动力提高技能并为未来做好准备……

本周新时代科技股:Zomato 的麻烦仍在继续,EaseMyTrip 发布强...

印度初创公司走捷径寻求资金

数字营销平台 Logicserve 获得 80 卢比的资金,更名为 LS Dig...
那么,为什么我要让你厌烦这些细节呢? 主要是为了让你了解一下我在研究工程时人工智能所处的位置。 甚至几十年前,深度学习和机器学习就已经存在,但直到最近 10 年,该领域才开始成熟。 过去几年到底发生了什么变化?

嗯,首先,摩尔定律将我们带到了这样一个地步,即存储和处理成本对于在家中实施机器学习的人来说变得最小。 你现在可以在自己的机器上运行几乎所有的基本模型,如果你购买了一个好的 GPU(不再那么昂贵),它可以将你的计算时间优化近 10 倍,以便能够运行复杂的模型。
《连线》杂志对这一变化有很好的报道。
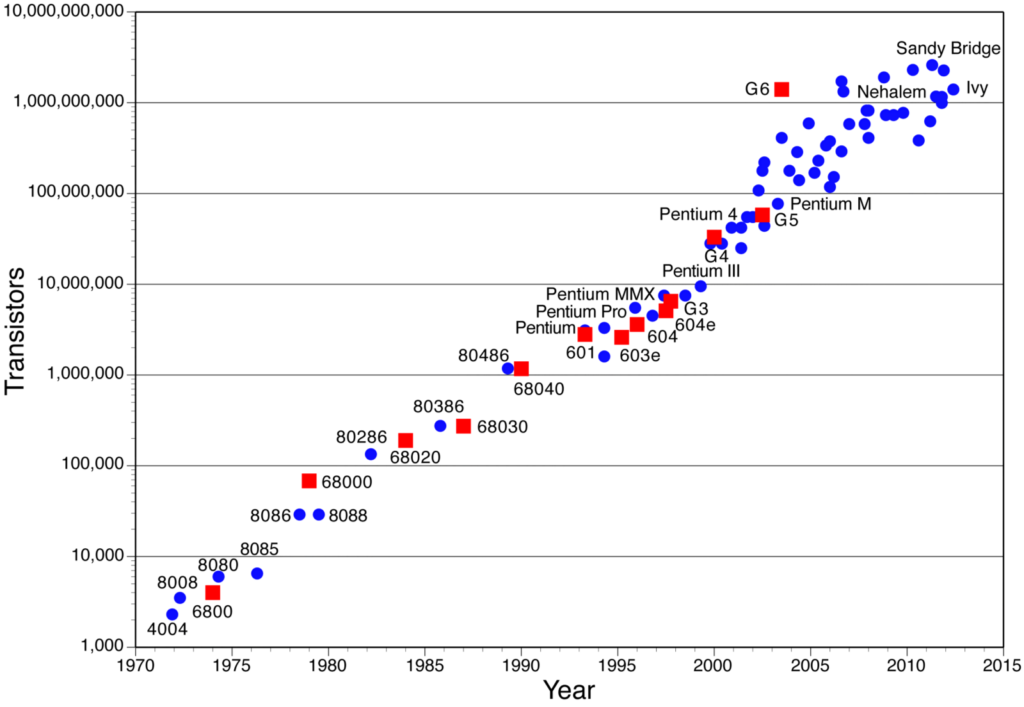
一年中芯片中的晶体管数量(注意 Y 轴是对数刻度!)。 资料来源:Assured-Systems
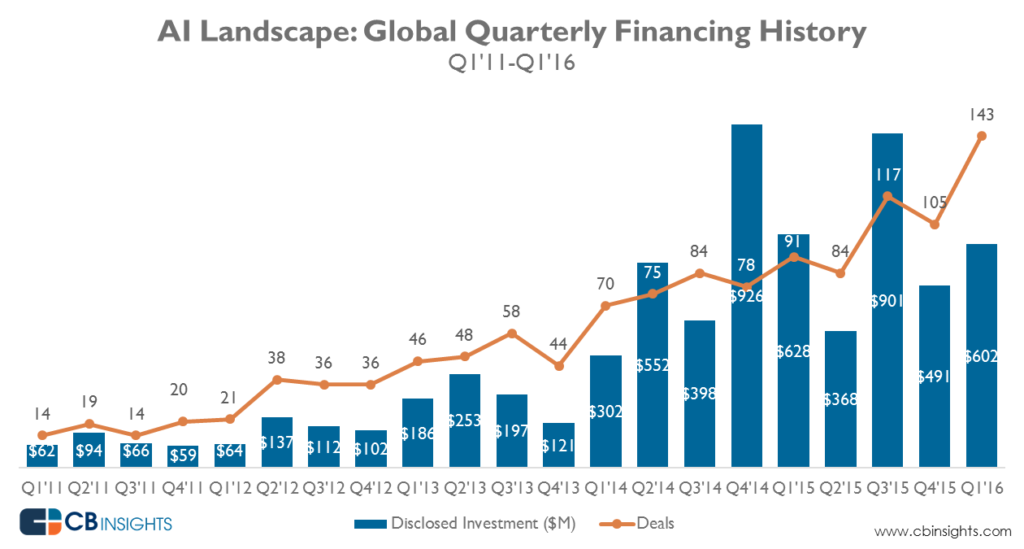
改变的另一件事是企业已经意识到自动化的必要性。 因此,虽然该领域的并购活动大幅增加,但在过去 5 年中,风投们一直在向该领域投入大量资金。
投资者对深度学习的展望
那么,我们现在的立场是什么?投资者或初创公司应该如何看待这种极端的 AI 嗡嗡声? 在我看来,人工智能初创公司有四个关键方面,所有这些方面都需要结合起来才能形成一家强大的公司。
- 人才:一切从这里开始。 在初创公司中,团队显然是最重要的方面,而在 AI 初创公司中,它是公司真正的引擎。 获得强大的数据科学和计算机工程人才来微调这些预先构建的模型将是人工智能初创公司的关键,这就是为什么美国和中国的初创公司可能在其他地区处于领先地位。 新加坡确实有一小部分数据科学人才,很可能是建立人工智能公司的好地方。 也就是说,最优秀的人才最终可能会有机地或无机地进入科技巨头。 谷歌收购 DeepMind 正是为了获得深度学习领域的一些最优秀人才。
- 数据:如果团队是引擎,那么数据就是人工智能初创公司的汽油。 如果没有大量干净和结构化的数据,您不太可能从阻碍业务应用程序的训练有素的系统中获得任何准确性。 由于模型的预测能力对输入数据的核心依赖性,与小型初创公司相比,大型公司在提出更好、更准确的系统方面可能具有显着优势。 这是一个令人不安的想法,打破常规的唯一方法是生成和利用您自己的专有数据。 像 Salesforce 这样的记录系统在这方面将非常重要。
- 模型:所有大型科技巨头目前都在推出自己的人工智能系统(开发平台、库、训练模型),为未来的人工智能开发创建平台。 尚未确定谁将赢得这场战争,但从头开始创建模型的需求迟早会结束。 只有对于真正复杂的系统,才需要从基础开始构建模型,但在大多数情况下,您的数据科学家将能够重用现成的模型并使用自己的数据重新训练它们。 你怎么知道你已经达到了最好的模型呢? 由 Union Square Ventures 支持的 Numerai 正在以一种非常聪明的方式解决这个问题,通过众包给 ML 专家并在财务上激励他们建立更好的模型。
- 业务问题:这就是事情变得有趣的地方。 首先,用户并不关心您的系统是否是自动化的。 人工智能系统旨在优化您自己的组织,让机器执行人类的任务,而不是让用户惊叹。 因此,解决特定的业务问题是提供良好用户体验并因此增加粘性的关键。
其次,大多数科技巨头将限制自己建立一个广泛而通用的平台。 虽然 Salesforce、Hubspot 等科技公司正在涉足人工智能,但它们很可能会成为一条收购路线。 Salesforce 已经宣布了爱因斯坦(尽管尚未正确执行其声明),并且 Hubspot 每周都会在其博客上撰写有关 AI 的文章。 它只显示了他们对该领域的兴趣,以及他们针对特定问题的难度。 这就是初创公司可以利用的差距所在,而我们的投资组合公司 Saleswhale 正是在走这条路。
在我看来,如果一家初创公司通过自动化解决了一个非常有针对性的问题,该问题会影响使用其系统在途中收集的专有数据的足够多的人,那么它很可能是一项非常有利可图的业务,并且进入门槛很高。 然而,据我所知,这在该地区不太可能是一个独角兽规模的机会,而不是在科技巨头还活着的时候。
[Nikhil Kapur 的这篇文章首次出现在 Medium 上,经许可转载。]