
有效学习:人工智能的近期未来
已发表: 2017-11-09这些有效的学习技术不是新的深度学习/机器学习技术,而是将现有技术扩充为黑客
毫无疑问,人工智能的最终未来是达到并超越人类智能。 但这是一个牵强附会的壮举。 即使是我们当中最乐观的人也打赌,人类水平的人工智能(AGI 或 ASI)将在 10 到 15 年后出现,怀疑者甚至愿意打赌,如果可能的话,这将需要几个世纪的时间。 好吧,这不是这篇文章的内容。
在这里,我们将讨论一个更切实、更近的未来,并讨论新兴和强大的人工智能算法和技术,在我们看来,这些算法和技术将塑造人工智能的近期未来。
人工智能已经开始在一些选定的特定任务中超越人类。 例如,在诊断皮肤癌方面击败医生,在世界锦标赛上击败围棋选手。 但是,相同的系统和模型将无法执行与他们训练解决的任务不同的任务。 这就是为什么从长远来看,无需重新评估即可高效执行一组任务的通用智能系统被称为人工智能的未来。
但是,在不久的将来,在 AGI 出现之前,科学家们如何才能让 AI 驱动的算法克服他们今天面临的问题,走出实验室,成为日常使用的对象?
当你环顾四周时,人工智能一次只赢得一座城堡(阅读我们关于人工智能如何超越人类的帖子,第一部分和第二部分)。 在这样一场双赢的比赛中可能会出现什么问题? 随着时间的推移,人类正在产生越来越多的数据(这是人工智能消耗的饲料),我们的硬件能力也在变得越来越好。 毕竟,数据和更好的计算是 2012 年深度学习革命开始的原因,对吧? 事实是,人类期望的增长比数据和计算的增长更快。 数据科学家必须想出超出目前存在的解决方案来解决现实世界的问题。 例如,大多数人认为的图像分类在科学上是一个已解决的问题(如果我们抵制说 100% 准确率或 GTFO 的冲动)。
我们可以使用人工智能对匹配人类能力的图像(比如说猫图像或狗图像)进行分类。 但这可以用于现实世界的用例吗? 人工智能能否为人类面临的更多实际问题提供解决方案? 在某些情况下,是的,但在很多情况下,我们还没有做到。
我们将引导您完成挑战,这些挑战是使用 AI 开发现实世界解决方案的主要障碍。 假设您要对猫和狗的图像进行分类。 我们将在整个帖子中使用这个示例。

我们的示例算法:对猫和狗的图像进行分类
下图总结了挑战:

开发现实世界的人工智能所涉及的挑战
让我们详细讨论这些挑战:
用较少的数据学习
- 大多数成功的深度学习算法消耗的训练数据要求根据其包含的内容/特征对其进行标记。 这个过程称为注解。
- 算法不能使用你周围自然发现的数据。 几百个(或几千个数据点)的注释很容易,但我们的人类级图像分类算法需要一百万个带注释的图像才能很好地学习。
- 所以问题是,注释一百万张图像是否可能? 如果不是,那么人工智能如何使用较少数量的注释数据进行扩展?
解决不同的现实世界问题
- 虽然数据集是固定的,但现实世界的使用更加多样化(例如,在彩色图像上训练的算法可能在灰度图像上与人类不同)。
- 虽然我们改进了计算机视觉算法来检测物体以匹配人类。 但如前所述,与在许多意义上更通用的人类智能相比,这些算法解决了一个非常具体的问题。
- 我们的示例 AI 算法对猫和狗进行分类,如果不输入稀有狗的图像,将无法识别该物种。
调整增量数据
- 另一个主要挑战是增量数据。 在我们的示例中,如果我们试图识别猫和狗,我们可能会在首次部署时针对不同物种的许多猫和狗图像训练我们的 AI。 但是在完全发现一个新物种时,我们需要训练算法来识别“Kotpies”和以前的物种。
- 虽然新物种可能比我们想象的更类似于其他物种,并且可以很容易地训练以适应算法,但有些地方更难,需要完全重新训练和重新评估。
- 问题是我们能让人工智能至少适应这些小变化吗?
为了让 AI 立即可用,想法是通过一组称为 Effective Learning 的方法来解决上述挑战(请注意,这不是官方术语,我只是为了避免写 Meta-Learning、Transfer Learning、Few每次射击学习、对抗学习和多任务学习)。 在 ParallelDots,我们现在正在使用这些方法来解决 AI 的狭隘问题,赢得小型战斗,同时为更全面的 AI 征服更大的战争做准备。 让我们一次向您介绍这些技术。
值得注意的是,这些有效学习技术中的大多数都不是什么新鲜事物。 他们现在只是看到了复苏。 SVM(支持向量机)研究人员已经使用这些技术很长时间了。 另一方面,对抗性学习是 Goodfellow 最近在 GAN 方面的研究成果,而神经推理是一组新的技术,数据集最近才可用。 让我们深入探讨这些技术将如何帮助塑造人工智能的未来。
迁移学习
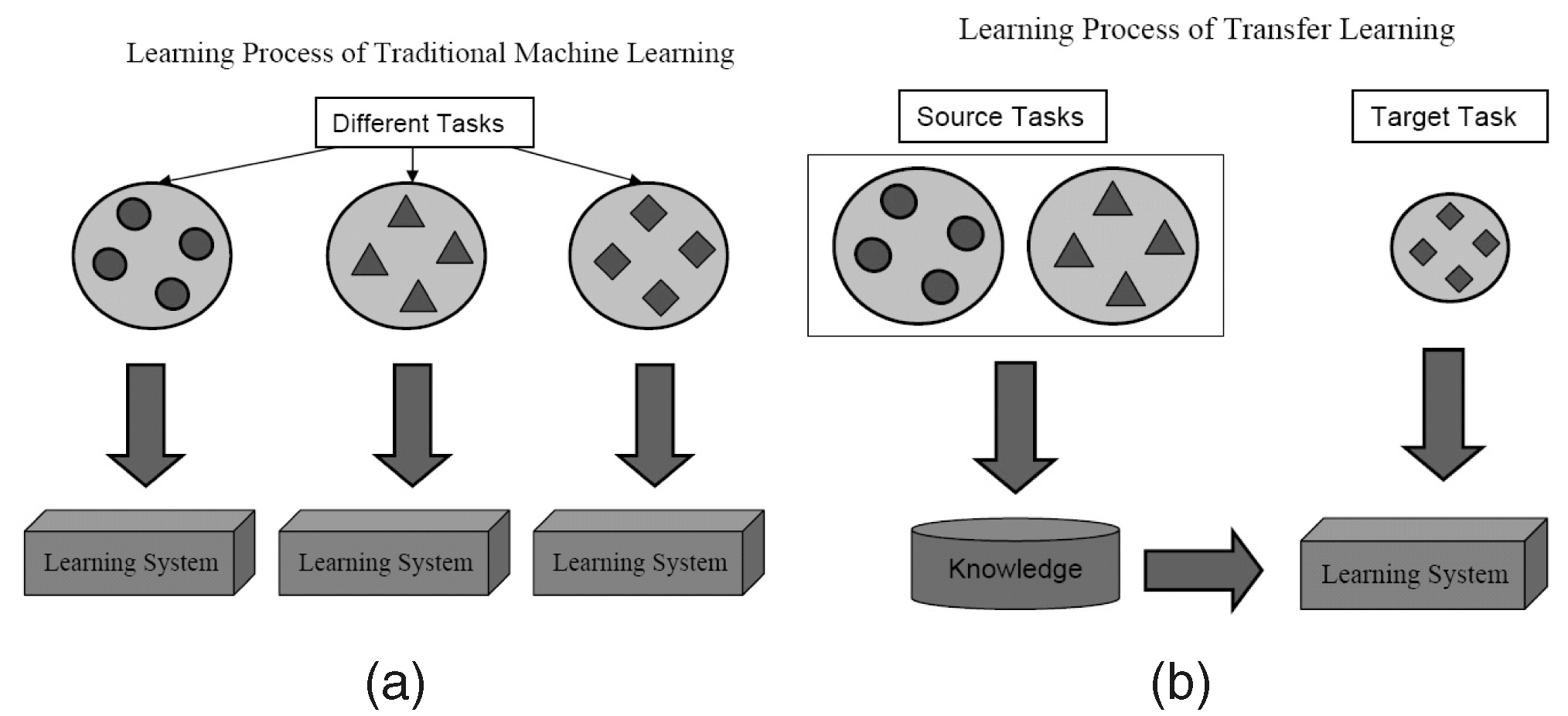
它是什么?
顾名思义,学习是在迁移学习的同一算法中从一个任务转移到另一个任务。 在具有较大数据集的一个任务(源任务)上训练的算法可以在有或没有修改的情况下作为算法的一部分进行传输,该算法试图在(相对)较小的数据集上学习不同的任务(目标任务)。
一些例子
在对象检测等不同任务中使用图像分类算法的参数作为特征提取器是迁移学习的一个简单应用。 相反,它也可以用于执行复杂的任务。 谷歌开发的算法比医生更好地对糖尿病视网膜病变进行分类,不久前是使用迁移学习制作的。 令人惊讶的是,糖尿病视网膜病变检测器实际上是一个真实世界的图像分类器(狗/猫图像分类器),用于对眼睛扫描进行分类的迁移学习。
告诉我更多!
在深度学习文献中,您会发现数据科学家将神经网络的这些从源任务转移到目标任务的部分称为预训练网络。 微调是指目标任务的错误被温和地反向传播到预训练网络中,而不是使用未经修改的预训练网络。 可以在这里看到计算机视觉中迁移学习的一个很好的技术介绍。 这个简单的迁移学习概念在我们的一套有效学习方法中非常重要。
为你推荐:

元界将如何改变印度汽车业

反暴利条款对印度初创企业意味着什么?

教育科技初创公司如何帮助印度的劳动力提高技能并为未来做好准备……

本周新时代科技股:Zomato 的麻烦仍在继续,EaseMyTrip 发布强...

印度初创公司走捷径寻求资金

数字营销平台 Logicserve 获得 80 卢比的资金,更名为 LS Dig...
多任务学习
它是什么?
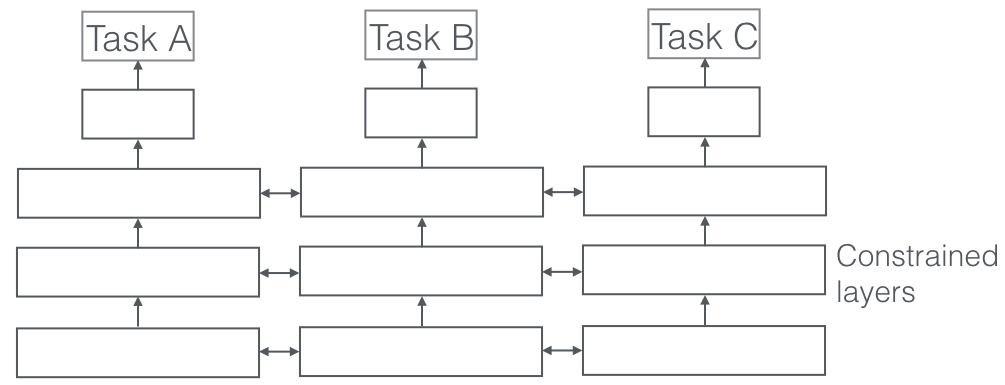

在多任务学习中,同时解决多个学习任务,同时利用任务之间的共性和差异。 令人惊讶的是,有时一起学习两个或多个任务(也称为主要任务和辅助任务)可以使任务的结果更好。 请注意,并非每一对、三重或四重任务都可以被视为辅助任务。 但是当它起作用时,它是准确度的自由增加。
一些例子
例如,在 ParallelDots,我们的 Sentiment、Intent 和 Emotion Detection 分类器被训练为多任务学习,与我们单独训练它们相比,这提高了它们的准确性。 我们所知道的 NLP 中最好的语义角色标签和 POS 标记系统是多任务学习系统,因此也是计算机视觉中用于语义和实例分割的最佳系统之一。 谷歌提出了多模式多任务学习者(一个模型来统治他们),可以在同一个镜头中从视觉和文本数据集中学习。
告诉我更多!
在现实世界的应用程序中看到的多任务学习的一个非常重要的方面是训练任何任务以防弹,我们需要尊重许多域数据来自(也称为域适应)。 我们的猫和狗用例中的一个例子是一种算法,它可以识别不同来源的图像(比如 VGA 摄像头和高清摄像头,甚至红外摄像头)。 在这种情况下,可以将域分类的辅助损失(图像来自哪里)添加到任何任务中,然后机器学习使得算法在主要任务(将图像分类为猫或狗图像)上不断提高,但是故意在辅助任务上变得更糟(这是通过从域分类任务反向传播反向误差梯度来完成的)。 这个想法是该算法学习主要任务的判别特征,但忘记了区分域的特征,这将使其变得更好。 多任务学习及其领域适应表亲是我们所知道的最成功的有效学习技术之一,并且在塑造人工智能的未来方面发挥着重要作用。
对抗学习
它是什么?
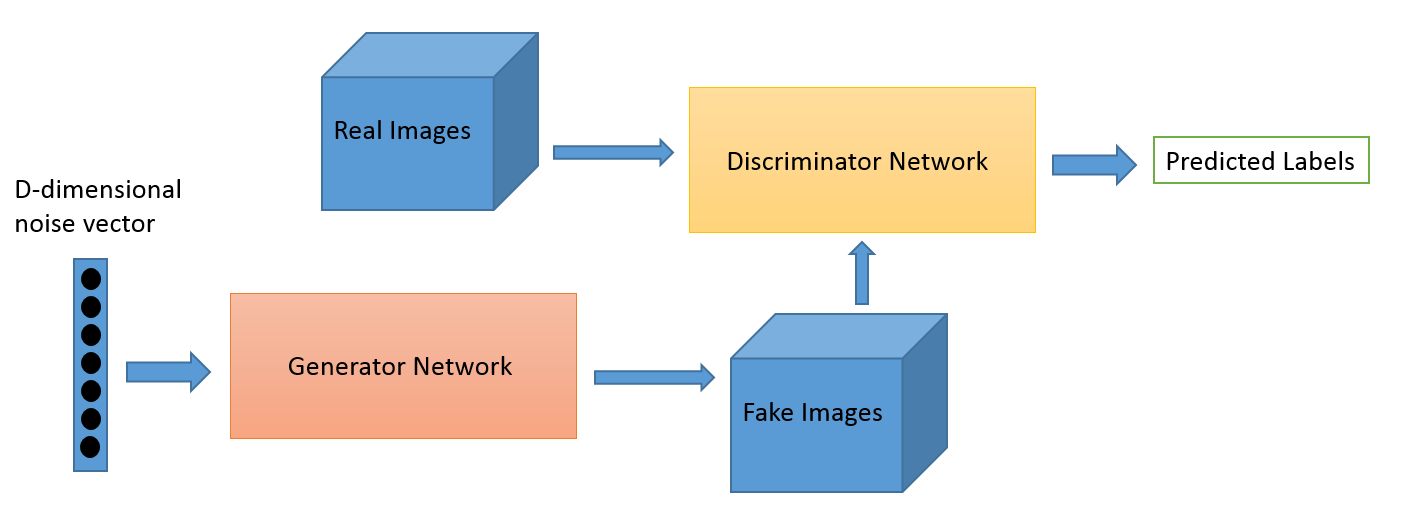
对抗性学习作为一个领域是从 Ian Goodfellow 的研究工作演变而来的。 虽然对抗学习最流行的应用无疑是生成对抗网络 (GAN),它可以用来生成令人惊叹的图像,但这套技术还有多种其他方式。 通常,这种受博弈论启发的技术有两种算法:生成器和鉴别器,其目的是在训练时互相欺骗。 正如我们所讨论的,生成器可用于生成新的新颖图像,但也可以生成任何其他数据的表示以隐藏鉴别器的细节。 后者是我们对这个概念如此感兴趣的原因。
一些例子
这是一个新领域,图像生成能力可能是天文学家等最感兴趣的人关注的焦点。 但我们相信,正如我们稍后所说的那样,这也会发展出新的用例。
告诉我更多!
使用 GAN 损失可以改善域适应游戏。 这里的辅助损失是 GAN 系统,而不是纯域分类,其中判别器试图对数据来自哪个域进行分类,而生成器组件试图通过将随机噪声呈现为数据来欺骗它。 根据我们的经验,这比普通的域适应(这对代码也更不稳定)更有效。
少镜头学习
它是什么?
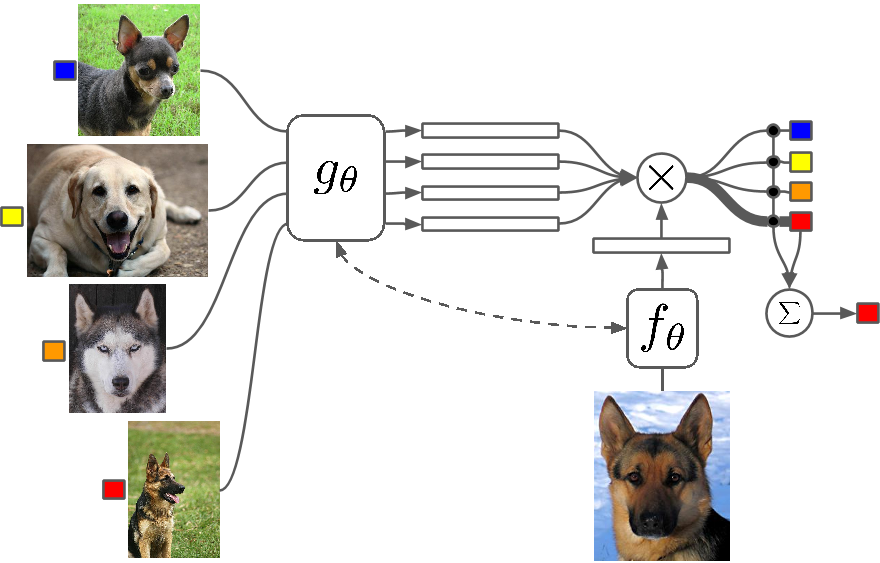
Few Shot Learning 是一项技术研究,与传统算法相比,深度学习(或任何机器学习算法)算法使用更少的示例进行学习。 One Shot Learning 基本上是使用一个类别的一个示例进行学习,归纳 k-shot 学习意味着使用每个类别的 k 个示例进行学习。
一些例子
很少有镜头学习作为一个领域在所有主要的深度学习会议上看到大量论文,现在有特定的数据集可以对结果进行基准测试,就像 MNIST 和 CIFAR 用于正常的机器学习一样。 One-shot Learning 在某些图像分类任务中看到了许多应用,例如特征检测和表示。
告诉我更多!
有多种方法可用于 Few Shot 学习,包括迁移学习、多任务学习以及作为算法的全部或部分的元学习。 还有其他方法,例如使用巧妙的损失函数、使用动态架构或使用优化技巧。 零镜头学习是一类声称可以预测算法甚至没有见过的类别的答案的算法,基本上是可以使用新型数据进行扩展的算法。
元学习
它是什么?

元学习正是它听起来的样子,一种经过训练的算法,在看到数据集时,它会为该特定数据集生成一个新的机器学习预测器。 如果您第一眼看到这个定义,它就非常具有未来感。 你会觉得“哇! 这就是数据科学家所做的”,它正在使“21 世纪最性感的工作”自动化,从某种意义上说,元学习者已经开始这样做了。
一些例子
元学习最近成为深度学习的热门话题,有很多研究论文问世,最常用的技术是超参数和神经网络优化、寻找好的网络架构、Few-Shot 图像识别和快速强化学习。
告诉我更多!
有些人将这种决定参数和超参数(如网络架构)的完全自动化称为 autoML,您可能会发现人们将元学习和 AutoML 称为不同的领域。 尽管围绕它们进行了大肆宣传,但事实是元学习者仍然是随着数据复杂性和多样性的增加而扩展机器学习的算法和途径。
大多数元学习论文都是聪明的黑客,根据维基百科,它们具有以下属性:
- 该系统必须包括一个学习子系统,它可以根据经验进行调整。
- 通过利用在单个数据集上的先前学习集中或从不同领域或问题中提取的元知识来获得经验。
- 学习偏差必须动态选择。
子系统基本上是一种设置,当域(或全新域)的元数据被引入它时会适应。 该元数据可以说明类别数量的增加、复杂性、颜色和纹理以及对象(在图像中)、样式、语言模式(自然语言)和其他类似特征的变化。 在这里查看一些超酷的论文:Meta-Learning Shared Hierarchies and Meta-Learning Using Temporal Convolutions。 您还可以使用元学习架构构建 Few Shot 或 Zero Shot 算法。 元学习是最有前途的技术之一,将有助于塑造人工智能的未来。
神经推理
它是什么?

神经推理是图像分类问题中的下一件大事。 神经推理是模式识别之上的一个步骤,其中算法正在超越简单地识别和分类文本或图像的想法。 神经推理正在解决文本分析或视觉分析中更通用的问题。 例如,下图表示神经推理可以从图像中回答的一组问题。
告诉我更多!
这套新技术是在 Facebook 的 bAbi 数据集或最近的 CLEVR 数据集发布之后出现的。 用于破译关系而不仅仅是模式的技术具有巨大的潜力,不仅可以解决神经推理,还可以解决包括 Few Shot 学习问题在内的多个其他难题。
回去
现在我们知道了这些技术是什么,让我们回过头来看看它们是如何解决我们开始的基本问题的。 下表概述了有效学习技术应对挑战的能力:
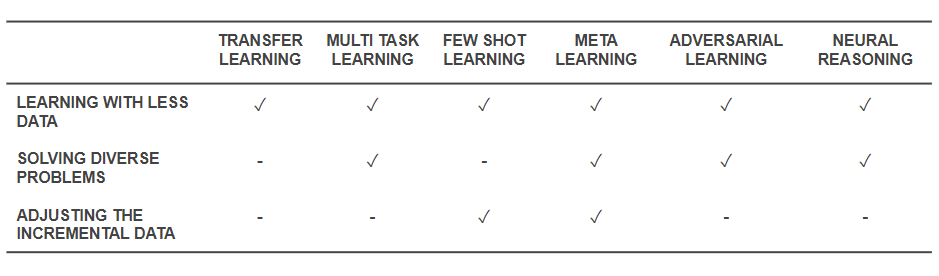
有效学习技术的能力
- 上面提到的所有技术都有助于以某种方式使用较少的数据来解决训练问题。 虽然元学习将提供仅与数据一起塑造的架构,但迁移学习正在使来自其他领域的知识变得有用,以弥补更少的数据。 很少有镜头学习致力于将问题作为一门科学学科。 对抗学习可以帮助增强数据集。
- 领域适应(一种多任务学习)、对抗性学习和(有时)元学习架构有助于解决数据多样性引起的问题。
- 元学习和少数镜头学习有助于解决增量数据的问题。
- 神经推理算法在合并为元学习者或少数镜头学习者时具有解决现实世界问题的巨大潜力。
请注意,这些有效学习技术不是新的深度学习/机器学习技术,而是将现有技术作为黑客技术进行扩充,使它们更加物有所值。 因此,您仍然会看到我们的常规工具(例如卷积神经网络和 LSTM)在运行,但添加了一些香料。 这些有效的学习技术可以使用更少的数据并一次执行许多任务,有助于更轻松地生产和商业化人工智能驱动的产品和服务。 在 ParallelDots,我们认识到高效学习的力量并将其作为我们研究理念的主要特征之一。
Parth Shrivastava 的这篇文章首次出现在 ParallelDots 博客上,经许可转载。