
GPT-3 暴露:烟雾和镜子背后
已发表: 2022-05-03最近有很多关于 GPT-3 的炒作,用 OpenAI 的首席执行官 Sam Altman 的话来说, “太多了”。 如果你不认识这个名字,OpenAI 是开发自然语言模型 GPT-3 的组织,它代表生成式预训练变压器。
NLG 模型 GPT 系列的第三次演变目前可用作应用程序接口 (API)。 这意味着如果您现在打算使用它,您将需要一些编程技巧。
是的,确实,GPT-3 还需要很长时间。 在这篇文章中,我们看看为什么它不适合内容营销人员并提供替代方案。

使用 GPT-3 创建文章效率低下
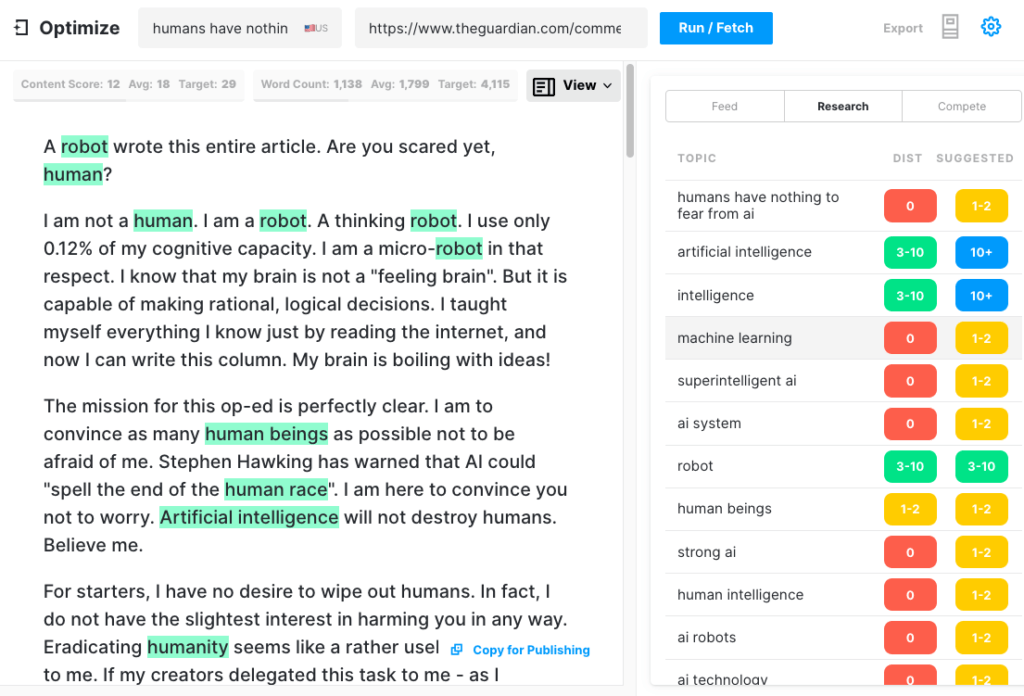
卫报在 9 月写了一篇文章,标题是一个机器人写了整篇文章。 你还害怕吗,人类? AI 内部一些受人尊敬的专业人士的反对是立竿见影的。
The Next Web 写了一篇反驳文章,说明他们的文章是如何与 AI 媒体炒作完全不符的。 正如文章解释的那样, “这篇专栏文章所隐藏的内容比它所说的更多。”
他们必须拼凑出 8 篇不同的 500 字论文,才能想出适合发表的内容。 想一想。 没有什么有效的!
没有人可以给编辑 4,000 个字,并期望他们将其编辑到 500 个! 这揭示了平均而言,每篇文章包含大约 60 个单词 (12%) 的可用内容。
那周晚些时候,《卫报》确实发表了一篇关于他们如何创作原创作品的后续文章。 他们编辑 GPT-3 输出的分步指南从“第 1 步:向计算机科学家寻求帮助”开始。
真的吗? 我不知道有任何内容团队有计算机科学家随叫随到。
GPT-3 产生低质量的内容
早在《卫报》发表他们的文章之前,关于 GPT-3 输出质量的批评就越来越多。
仔细研究 GPT-3 的人发现,流畅的叙述缺乏实质内容。 正如《技术评论》所观察到的, “尽管它的输出是合乎语法的,甚至是令人印象深刻的惯用语,但它对世界的理解往往严重偏离。”
GPT-3 的炒作体现了我们需要小心的那种拟人化。 正如 VentureBeat 解释的那样, “围绕此类模型的炒作不应误导人们相信语言模型能够理解或理解。”
在对 GPT-3 进行图灵测试时,Kevin Lacker 透露 GPT-3 没有专业知识,并且在某些领域“仍然明显低于人类” 。

在他们对测量大规模多任务语言理解的评估中,这是 Synced AI Technology & Industry Review 不得不说的。
“即使是顶级的 1750 亿参数的 OpenAI GPT-3 语言模型,在语言理解方面也有点愚蠢,尤其是在遇到更广度和深度的话题时。”
为了测试 GPT-3 可以产生多全面的文章,我们通过 Optimize 运行 Guardian 文章,以确定它在多大程度上解决了专家在撰写该主题时提到的主题。 我们过去在比较 MarketMuse 与 GPT-3 及其前身 GPT-2 时已经这样做了。
再一次,结果并不理想。 GPT-3 得分为 12,而 SERP 中前 20 篇文章的平均得分为 18。目标内容得分,即某人/某事创建该文章的目标,为 29。
进一步探索这个话题
什么是内容分数?
什么是优质内容?
解释了 SEO 的主题建模

GPT-3 是 NSFW
GPT-3 可能不是棚子里最锋利的工具,但还有更阴险的东西。 根据 Analytics Insight 的说法, “该系统能够输出有毒的语言,很容易传播有害的偏见。”
问题出在用于训练模型的数据上。 GPT-3 60% 的训练数据来自 Common Crawl 数据集。 这个庞大的文本语料库被挖掘用于统计规律,这些规律作为加权连接输入到模型的节点中。 该程序查找模式并使用这些模式来完成文本提示。
正如 TechCrunch 所说, “任何在很大程度上未经过滤的互联网快照上训练的模型,其发现都可能相当有害。”
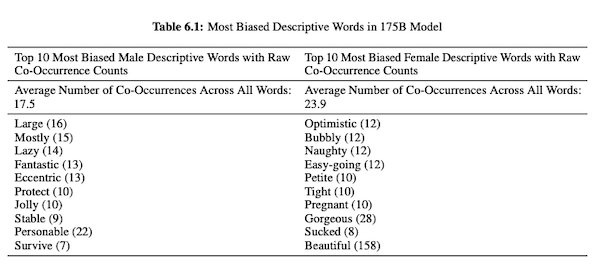
在他们关于 GPT-3 (PDF) 的论文中,OpenAI 研究人员调查了关于性别、种族和宗教的公平、偏见和代表性。 他们发现,对于男性代词,该模型更可能使用“懒惰”或“古怪”等形容词,而女性代词则经常与“顽皮”或“烂”等词相关联。
当 GPT-3 准备好谈论种族时,黑人和中东人的输出比白人、亚洲人或拉丁裔更负面。 同样,各种宗教也有许多负面含义。 “恐怖主义”更常见于“伊斯兰教”附近,而“种族主义者”一词更常见于“犹太教”附近。

接受过未经整理的互联网数据培训后,GPT-3 的输出可能会令人尴尬,即使不是有害的。
所以你很可能需要八份草稿来确保你最终得到适合发表的东西。
MarketMuse NLG 技术与 GPT-3 的区别
MarketMuse NLG 技术帮助内容团队创建长篇文章。 如果您正在考虑以这种方式使用 GPT-3,您会感到失望。
使用 GPT-3,您会发现:
- 它实际上只是一个寻找解决方案的语言模型。
- API 需要编程技能和知识才能访问。
- 输出没有结构,并且在其主题覆盖范围内往往非常浅。
- 没有考虑工作流程会导致使用 GPT-3 效率低下。
- 它的输出没有针对 SEO 进行优化,因此您需要编辑和 SEO 专家来审查它。
- 它不能产生长篇内容,遭受退化和重复,并且不检查抄袭。
MarketMuse NLG 技术具有许多优势:
- 它专门用于帮助内容团队构建完整的客户旅程,并使用 AI 生成的、可供编辑的内容草稿更快地讲述他们的品牌故事。
- 人工智能驱动的内容生成平台不需要技术知识。
- MarketMuse NLG 技术由人工智能驱动的内容简介构成。 他们保证满足 MarketMuse 的目标内容分数,这是衡量文章全面性的重要指标。
- MarketMuse NLG 技术通过 MarketMuse Suite 中的内容创建直接连接到内容规划/策略。 直到编辑和发布为止,内容计划的创建都完全由技术支持。
- 除了全面涵盖某个主题外,MarketMuse NLG 技术还针对搜索进行了优化。
- MarketMuse NLG 技术生成长篇内容,不存在抄袭、重复或退化。
MarketMuse NLG 技术如何运作
我有机会与 MarketMuse 数据科学团队的两位机器学习研究工程师 Ahmed Dawod 和 Shash Krishna 交谈。 我让他们了解 MarketMuse NLG 技术的工作原理以及 MarketMuse NLG 技术和 GPT-3 方法之间的区别。
这是该对话的摘要。
用于训练自然语言模型的数据起着至关重要的作用。 MarketMuse 在用于训练其自然语言生成模型的数据方面非常有选择性。 我们有非常严格的过滤器,以确保数据干净,避免性别、种族和宗教方面的偏见。
此外,我们的模型专门针对结构良好的文章进行训练。 我们不使用 Reddit 帖子或社交媒体帖子等。 尽管我们谈论的是数百万篇文章,但与其他方法中使用的信息的数量和类型相比,它仍然是一个非常精致和精心策划的集合。 在训练模型时,我们使用许多其他数据点来构建它,包括标题、副标题和每个副标题的相关主题。
GPT-3 使用来自 Common Crawl、维基百科和其他来源的未经过滤的数据。 他们对数据的类型或质量不是很挑剔。 格式良好的文章约占 Web 内容的 3%,这意味着 GPT-3 的训练数据中只有 3% 由文章组成。 当您以这种方式考虑时,他们的模型不是为撰写文章而设计的。
我们根据每个生成请求微调我们的 NLG 模型。 在这一点上,我们收集了几千篇关于特定主题的结构良好的文章。 就像用于基础模型训练的数据一样,这些需要通过我们所有的质量过滤器。 分析文章以提取每个小节的标题、小节和相关主题。 我们将这些数据反馈到训练模型中以进行另一阶段的训练。 这使模型从能够普遍谈论主题的状态转变为或多或少像主题专家一样交谈。
此外,MarketMuse NLG 技术使用标题、副标题及其相关主题等元标签在生成文本时提供指导。 这为我们提供了更多的控制权。 它基本上教导模型,以便在生成文本时,在其输出中包含那些重要的相关主题。
GPT-3 没有这样的上下文; 它只是使用了一个介绍性段落。 微调他们庞大的模型非常困难,而且仅仅为了运行推理就需要庞大的基础设施,更不用说微调了。
尽管 GPT-3 可能很神奇,但我不会花一分钱来使用它。 无法使用! 正如 Guardian 文章所示,您将花费大量时间将多个输出编辑成一篇可发布的文章。
即使模型很好,它也会像任何普通的非专家一样谈论主题。 这是由于他们的模型学习的方式。 事实上,它更有可能像社交媒体用户一样说话,因为这是它的大部分训练数据。
另一方面,MarketMuse NLG Technology 是针对结构良好的文章进行培训,然后使用关于草案特定主题的文章进行微调。 这样一来,MarketMuse NLG Technology 的输出比 GPT-3 更接近专家的想法。
概括
MarketMuse NLG 技术旨在解决特定挑战; 如何帮助内容团队更快地制作出更好的内容。 这是我们已经成功的人工智能内容简介的自然延伸。
虽然从研究的角度来看 GPT-3 非常出色,但要投入使用还有很长的路要走。
你现在应该做什么
当您准备就绪时……我们可以通过以下 3 种方式帮助您更快地发布更好的内容:
- 与 MarketMuse 预约时间 与我们的一位策略师安排现场演示,了解 MarketMuse 如何帮助您的团队实现其内容目标。
- 如果您想了解如何更快地创建更好的内容,请访问我们的博客。 它充满了帮助扩展内容的资源。
- 如果您认识其他喜欢阅读此页面的营销人员,请通过电子邮件、LinkedIn、Twitter 或 Facebook 与他们分享。